Document AI、ドキュメント処理を効率的に自動化する新しいカスタム ドキュメント分類器を発表
Google Cloud Japan Team
※この投稿は米国時間 2023 年 3 月 22 日に、Google Cloud blog に投稿されたものの抄訳です。
プロセスの推進や意思決定を行うために、企業は大量のドキュメントに依存しています。流れ込んでくるドキュメントの中には種類が適切に分類されていないものも多く、企業での大規模な管理を難しくしています。
Google Cloud では、ドキュメントの処理と分析のための最先端 ML プロダクト、Document AI Workbench に継続的に投資して、これらの課題解決に取り組んでいます。このプロダクトは、特定のユースケースに合わせてトレーニングされた世界クラスの精度のモデルを、ユーザーが迅速に構築できるようにするものです。2023 年 2 月、Google はカスタム ドキュメント エクストラクタ(CDE)の一般提供を開始し、ユーザーが本番環境のユースケースでドキュメントから構造化データを抽出できるようにしました。そしてこのたび、ドキュメント処理の自動化を支援する最新のモデルタイプのカスタム ドキュメント分類器(CDC)を発表いたします。CDC を使用することで、ユーザーは高精度の ML モデルをトレーニングして、ドキュメントの種類を自動的に分類できます。
CDC は、具体的なビジネス価値をお客様に提供します。たとえば、ユーザーがアプリケーション内で適切なドキュメントを提出したかどうかを検証することで、確認に要する時間と費用を削減できます。また、正確な分類により、下流のプロセスを適切に自動化できるようになります。これには、適切な保管、分析、処理のステップを選択することが含まれます。
このブログ投稿では、カスタム ドキュメント分類器の概要と、この機能のメリットをすでに享受しているお客様の事例をご紹介します。
Document AI Workbench における分類モデルのメリット
Google のお客様は Document AI Workbench を活用することで、従来の開発手法で要した期間のごくわずかな時間で最先端の精度のモデルを構築し、最終的に時間と資金の節約を実現しています。つまり、CDC によって企業は、費用を削減しながら、より高い自動化率を達成してプロセスをスケーリングできるようになるということです。
Deloitte Consulting LLP の AI &データ部門マネージング ディレクターを務める Chris Jangareddy 氏は、次のように述べています。「Google Cloud Document AI は、豊富な機能を備えた最先端のドキュメント処理ソリューションです。具体的には、多段階分類やテキスト抽出の機能によって、並べ替え、分類、抽出、品質保証を自動化することができます。Document AI と Workbench を組み合わせることで先進的かつパワフルな AI Platform が生み出され、そのインテリジェントなドキュメント処理を通じて、エンタープライズ規模のプロセス変革、結果の予測性の向上など、ビジネスにメリットがもたらされています。」
TCS で BFSI 向け Google 事業部門 VP を務める Rajnish Palande 氏は次のように語ります。「Document AI Workbench では、AI によって非構造化データに含まれるインサイトを管理、収集することができます。分類、自動アノテーション、ページ番号識別、多言語サポートなどの機能により、組織の情報抽出における正確性、処理効率、信頼性を瞬く間に向上させ、ROI の増加をもたらします。」
Zencore のデリバリー サービス部門 VP を務める Sean Earley 氏はこう語ります。「Document AI Workbench を使えば、非常に正確なドキュメント解析モデルをわずか数日で作成できます。当社の顧客は、大部分を人手に頼っていたタスクを自動化しました。具体的には、2 人の担当者が Document AI Workbench を使って、15 種類のドキュメントからデータを分割、分類、抽出するモデルをトレーニングし、住宅ローン情報開示法(HDMA)に基づいたレポート作成を自動化しました。トレーニング済みモデルは平均精度が 94% もあるので、顧客のコンプライアンス レポート作成作業に関わる運用費用を大幅に削減できました。」
カスタム ドキュメント分類器の使い方
ユーザーは、Google Cloud コンソールのシンプルなインターフェースを使用して、トレーニング データの準備、モデルの作成と評価、本番環境へのモデルのデプロイを行えます。デプロイ後は、モデルを呼び出すだけでドキュメントの種類を分類できます。モデルを作成、トレーニング、評価、デプロイする方法、およびモデルを使用して予測を実行する方法については、こちらのドキュメントをご参照ください。
トレーニング データのインポートと準備
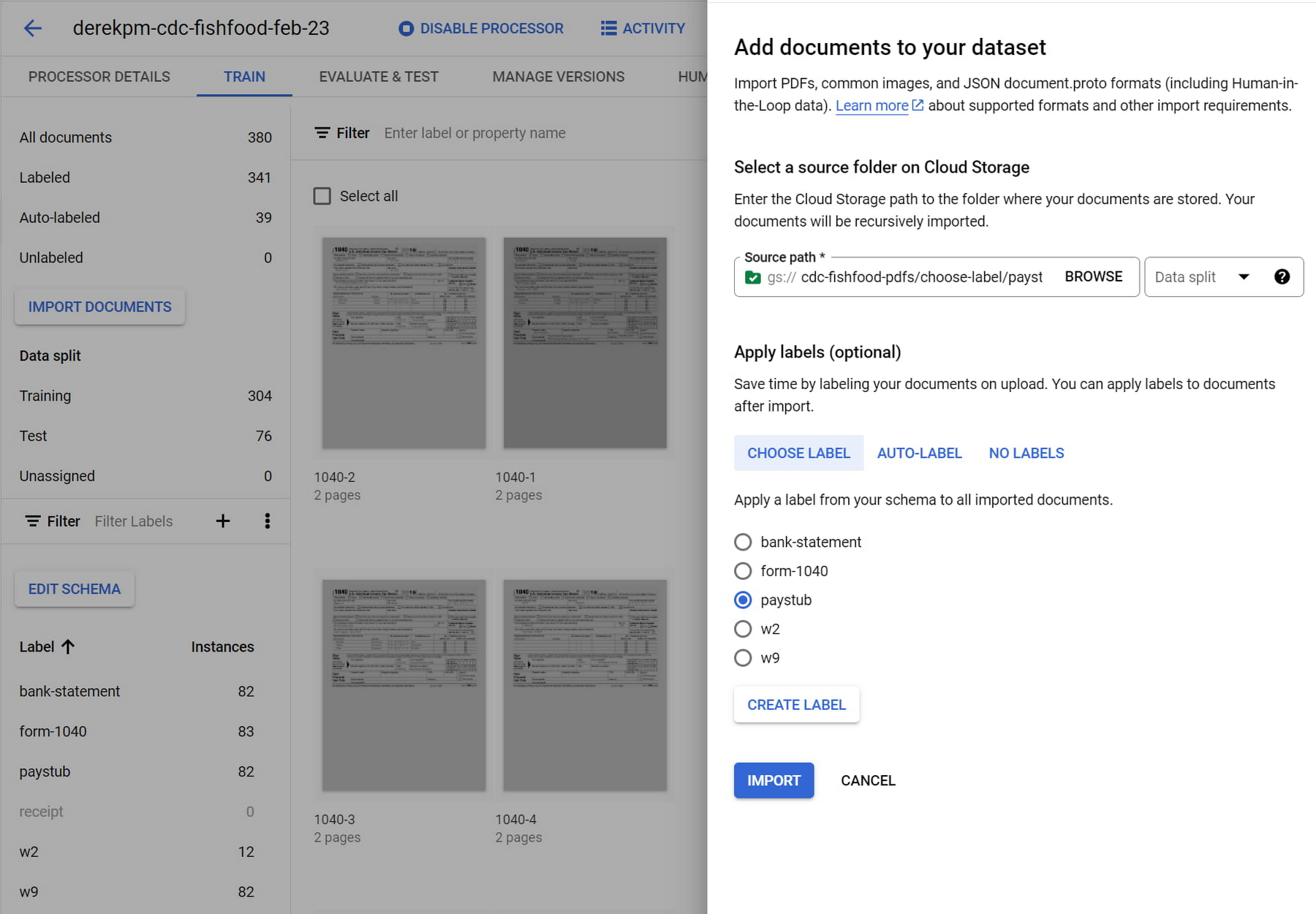
最初にユーザーが行うことは、ML モデルをトレーニングするためのドキュメントをインポートしてラベルを付けることです。インポート時に一括してラベルを付けることで、本番環境ワークロードに対応できる精度のモデルを数時間で構築するために必要な、トレーニングおよびテスト用のデータセットを作成できます。他のツールを使用してドキュメントにラベルが付けられている場合は、JSON 形式の Document でラベルをインポートします。ユーザーは、ボタンをクリックするだけでトレーニングを開始できます。一度モデルをトレーニングすれば、ドキュメントに自動的にラベルを付けて、より堅牢なトレーニング データセットを構築し、モデルのパフォーマンスを向上させることができます。
モデルの評価と反復処理
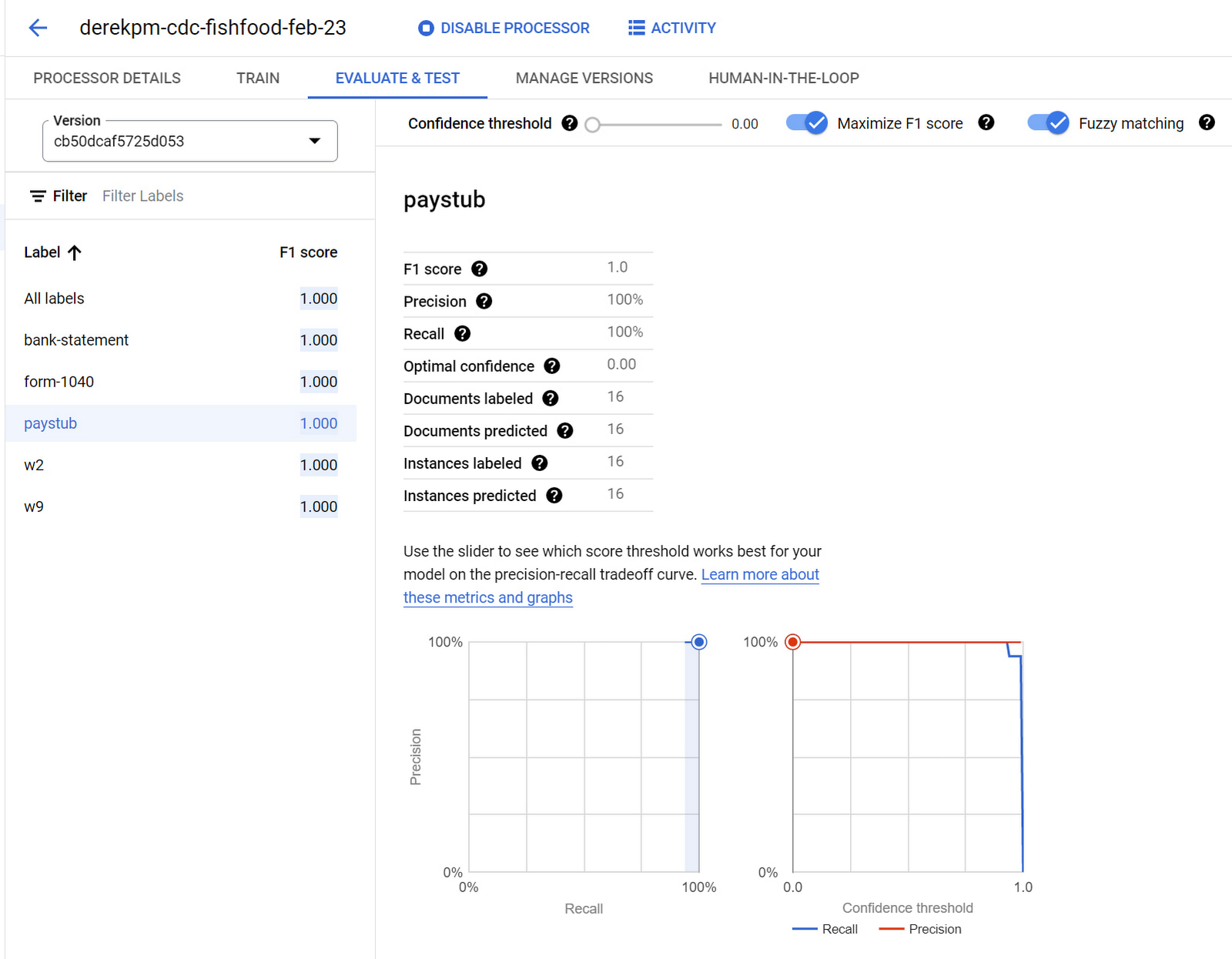
モデルをトレーニングしたら、次は、パフォーマンス指標(F1 スコア、適合率、再現率など)を調査することによってモデルを評価します。ユーザーは、モデルがエラーを予測した特定のインスタンスを掘り下げて、将来のパフォーマンスを向上させるための新たなトレーニング データを提供できます。
本番環境への移行
モデルが精度目標を満たしたら、次は本番環境にデプロイします。デプロイ後は、モデルのエンドポイントを呼び出してドキュメントの種類を分類できます。
Document AI Workbench を使ってみる
カスタム ドキュメント分類器は一般提供を開始しており、ドキュメントの分類を自動化するために今すぐお役立ていただけます。Document AI Workbench のウェブページや、Document AI Workbench のドキュメントで詳細をご覧いただくか、Google Cloud コンソールでお試しください。
謝辞: ソフトウェア エンジニアリング マネージャー Lukas Rutishauser、ソフトウェア エンジニアリング マネージャー Michael Kwong、ソフトウェア エンジニアリング マネージャー Rajagopal Janani、UX デザイナー Michael Lanning、プロダクト マーケティング マネージャー Shagun Lal、アウトバウンド プロダクト マネージャー Tomas Moreno、デベロッパー アドボケイト Holt Skinner。
- プロダクト マネージャー Derek Egan



