本教程介绍如何连接 BigQuery 表或视图以从 Dataricks 笔记本读取和写入数据。其中使用Google Cloud 控制台和 Databricks 工作区介绍了相应步骤。虽然您也可以使用 gcloud 和 databricks 命令行工具执行这些步骤,但该指南不在本教程的介绍范围内。
Databricks on Google Cloud 是 Google Cloud上托管的 Databricks 环境,它在 Google Kubernetes Engine (GKE) 上运行,并提供与 BigQuery 和其他 Google Cloud 技术的内置集成。如果您刚开始接触 Databricks,请观看 Databricks 统一数据平台简介视频,大致了解 Databricks 湖仓一体平台。
目标
- 配置 Google Cloud 以与 Databricks 连接。
- 部署 Databricks on Google Cloud。
- 从 Databricks 查询 BigQuery。
费用
本教程使用 Google Cloud 控制台的收费组件,包括 BigQuery 和 GKE。系统会按照 BigQuery 价格和 GKE 价格收取费用。如需了解与在 Google Cloud上运行的 Databricks 账号关联的费用,请参阅 Databricks 文档中的设置您的账号并创建工作区部分。
准备工作
在将 Databricks 连接到 BigQuery 之前,请完成以下步骤:
- 启用 BigQuery Storage API。
- 为 Databricks 创建服务账号。
- 创建 Cloud Storage 存储桶以进行临时存储。
启用 BigQuery Storage API
默认情况下,系统会为使用 BigQuery 的所有新项目启用 BigQuery Storage API。对于未启用 API 的现有项目,请按照以下说明操作:
在 Google Cloud 控制台中,前往 BigQuery Storage API 页面。
确认 BigQuery Storage API 已启用。
为 Databricks 创建服务账号
接下来,创建 Identity and Access Management (IAM) 服务账号以允许 Dataricks 集群针对 BigQuery 执行查询。我们建议您为此服务账号授予执行其任务所需的最低权限。请参阅 BigQuery 角色和权限。
在 Google Cloud 控制台中,前往服务账号页面。
点击创建服务账号,将服务账号命名为
databricks-bigquery,输入简短说明(如Databricks tutorial service account),然后点击创建并继续。在向此服务账号授予对项目的访问权限下,指定该服务账号的角色。如需授予服务账号使用同一项目中的 Databricks 工作区和 BigQuery 表读取数据的权限,特别是不引用具体化视图,请授予以下角色:
- BigQuery Read Session User
- BigQuery 数据查看者
如需提供写入数据的权限,请授予以下角色:
- BigQuery 作业用户
- BigQuery Data Editor
记录新服务账号的电子邮件地址,以便在后续步骤中引用。
点击完成。
创建 Cloud Storage 存储桶
如需将数据写入 BigQuery,Databricks 集群需要有权访问 Cloud Storage 存储桶来缓冲写入的数据。
在 Google Cloud 控制台中,前往 Cloud Storage 浏览器。
点击创建存储桶,打开创建存储桶对话框。
为用于将数据写入 BigQuery 的存储桶指定名称。存储桶名称必须是全局唯一名称。如果您指定的存储桶名称已存在,则 Cloud Storage 会返回错误消息。如果发生这种情况,请为存储桶指定其他名称。
在本教程中,使用存储位置、存储类别、访问权限控制和高级设置的默认设置。
点击创建以创建您的 Cloud Storage 存储桶。
依次点击权限和添加,然后指定您在“服务账号”页面上为访问 Databricks 创建的服务账号的电子邮件地址。
点击选择角色,然后添加 Storage Admin 角色。
点击保存。
部署 Databricks on Google Cloud
完成以下步骤即可为部署 Databricks on Google Cloud做好准备。
- 如需设置 Databoards 账号,请按照 Databricks 文档设置 Databricks on Google Cloud账号中的说明操作。
- 注册后,详细了解如何管理 Databricks 账号。
创建 Databrick 工作区、集群和笔记本
以下步骤介绍了如何创建 Dataricks 工作区、集群和 Python 笔记本,以编写代码访问 BigQuery。
确认 Datastone 前提条件。
创建您的第一个工作区。在 Datastones 账号控制台上,点击创建工作区。
为工作区名称指定
gcp-bq,然后选择您的区域。
如需确定您的 Google Cloud 项目 ID,请访问 Google Cloud 控制台,然后将值复制到Google Cloud 项目 ID 字段。
点击保存创建 Dataricks 工作区。
如需创建使用 Databricks 运行时 7.6 或更高版本的 Databricks 集群,请在左侧菜单栏中选择集群,然后点击顶部的创建集群。
指定集群名称及其大小,然后点击高级选项并指定 Google Cloud服务账号的邮箱。

点击创建集群。
如需为 Dataricks 创建 Python 笔记本,请按照创建笔记本中的说明操作。
从 Databricks 查询 BigQuery
使用上述配置时,您可以安全地将 Databricks 连接到 BigQuery。Databricks 使用开源 Google Spark 适配器的分支来访问 BigQuery。
Datastones 通过自动下推某些查询谓词(例如,过滤嵌套到 BigQuery 的列),可减少数据转移并加快查询速度。此外,增加了使用 query() API 在 BigQuery 上首次运行 SQL 查询的功能,可减小生成的数据集的传输大小。
以下步骤介绍了如何访问 BigQuery 中的数据集,以及如何将您自己的数据写入 BigQuery。
访问 BigQuery 上的公共数据集
BigQuery 提供了可用的公共数据集列表。如需查询属于公共数据集的 BigQuery 莎士比亚数据集,请按照以下步骤操作:
如需读取 BigQuery 表,请在 Databricks 笔记本中使用以下代码段。
table = "bigquery-public-data.samples.shakespeare" df = spark.read.format("bigquery").option("table",table).load() df.createOrReplaceTempView("shakespeare")按
Shift+Return执行该代码。现在,您可以通过 Spark DataFrame (
df) 查询 BigQuery 表。例如,使用以下命令可显示数据帧的前三行:df.show(3)如需查询其他表,请更新
table变量。Databricks 笔记本的一个重要特征是,您可以在单个笔记本中混合不同语言(如 Scala、Python 和 SQL)的单元。
以下 SQL 查询允许您在运行先前创建临时视图的单元后直观呈现莎士比亚中的字数统计。
%sql SELECT word, SUM(word_count) AS word_count FROM words GROUP BY word ORDER BY word_count DESC LIMIT 12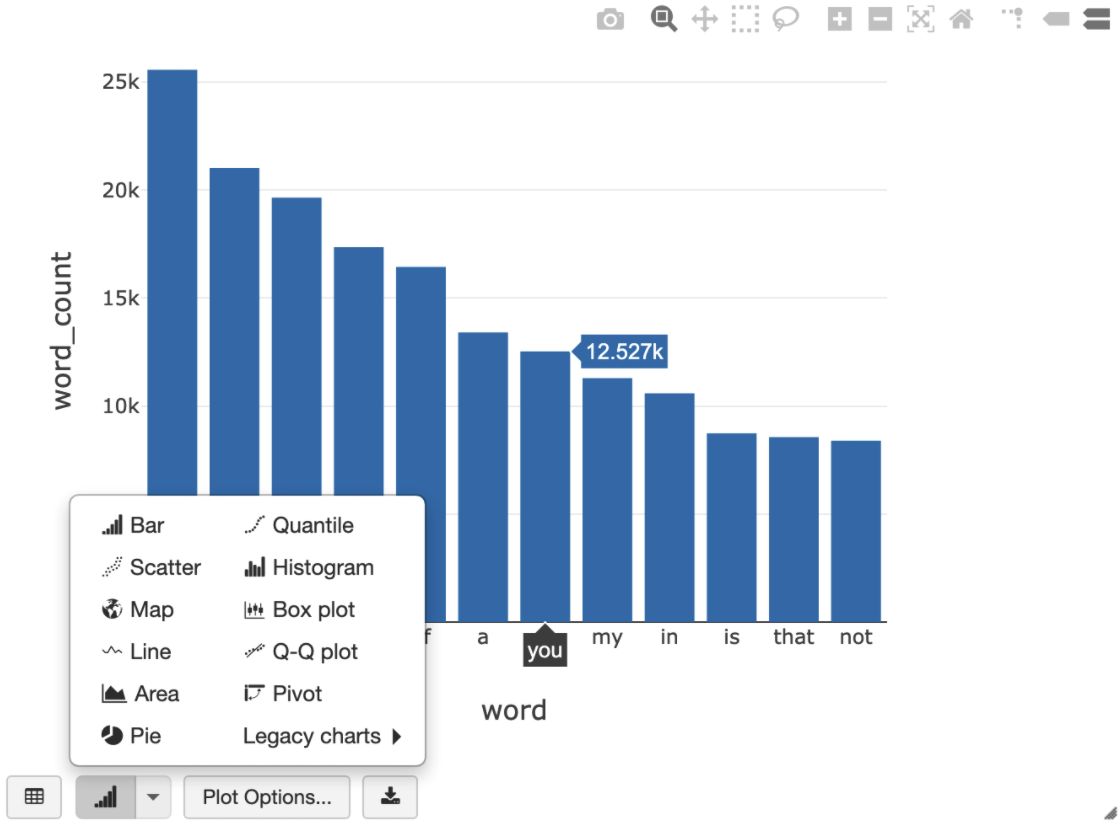
上面的单元会对 Databricks 集群(而不是 BigQuery)中的数据帧运行 Spark SQL 查询。这种方法的优势在于,数据分析在 Spark 级层进行,系统不会发出进一步的 BigQuery API 调用,因此不会产生额外的 BigQuery 费用。
作为替代方案,您可以使用
query()API 将 SQL 查询的执行委托给 BigQuery 并进行优化,以减小生成的数据帧的传输大小。与上述示例(在 Spark 中完成处理)不同,如果使用此方法,则价格和查询优化适用于在 BigQuery 上执行查询。以下示例使用 Scala、
query()API 以及 BigQuery 中的公共莎士比亚数据集来计算莎士比亚作品中五个最常见的字词。在运行代码之前,您必须先在 BigQuery 中创建一个名为mdataset的空数据集,代码可引用该数据集。如需了解详情,请参阅将数据写入 BigQuery。%scala // public dataset val table = "bigquery-public-data.samples.shakespeare" // existing dataset where the Google Cloud user has table creation permission val tempLocation = "mdataset" // query string val q = s"""SELECT word, SUM(word_count) AS word_count FROM ${table} GROUP BY word ORDER BY word_count DESC LIMIT 10 """ // read the result of a GoogleSQL query into a DataFrame val df2 = spark.read.format("bigquery") .option("query", q) .option("materializationDataset", tempLocation) .load() // show the top 5 common words in Shakespeare df2.show(5)如需查看更多代码示例,请参阅 Dataricks BigQuery 示例笔记本。
将数据写入 BigQuery
BigQuery 表位于数据集中。 在将数据写入 BigQuery 表之前,您必须在 BigQuery 中创建新数据集。如需为 Databricks Python 笔记本创建数据集,请按以下步骤操作:
前往 Google Cloud 控制台中的 BigQuery 页面。
展开 操作选项,点击创建数据集,然后将其命名为
together。在 Databricks Python 笔记本中,使用以下代码段根据包含三个字符串条目的 Python 列表创建一个简单的 Spark 数据帧。
from pyspark.sql.types import StringType mylist = ["Google", "Databricks", "better together"] df = spark.createDataFrame(mylist, StringType())在笔记本中添加另一个单元,以便将上一步中的 Spark 数据帧写入数据集
together中的 BigQuery 表myTable。系统会创建或覆盖该表。使用您之前指定的存储桶名称。bucket = YOUR_BUCKET_NAME table = "together.myTable" df.write .format("bigquery") .option("temporaryGcsBucket", bucket) .option("table", table) .mode("overwrite").save()如需验证是否已成功写入数据,请通过 Spark DataFrame (
df) 查询并显示 BigQuery 表:display(spark.read.format("bigquery").option("table", table).load)
清理
为避免因本教程中使用的资源导致您的 Google Cloud 账号产生费用,请删除包含这些资源的项目,或者保留项目但删除各个资源。
移除 Databrick 之前,请务必备份您的数据和笔记本。如需清理和完全移除 Databricks,请在Google Cloud 控制台中取消 Databricks 订阅,并从Google Cloud 控制台中移除您创建的所有相关资源。
如果您删除 Databrick 工作区,则由 Databricks 创建 的 databricks-WORKSPACE_ID 和 databricks-WORKSPACE_ID-system 这两个 Cloud Storage 存储桶可能不会删除(如果 Cloud Storage 存储桶不为空)。删除工作区后,您可以在Google Cloud 控制台中为项目手动删除这些对象。
后续步骤
本部分提供了一系列其他文档和教程:
- 了解 Dataricks 免费试用详情。
- 了解 Databricks on Google Cloud。
- 了解 Dataricks BigQuery。
- 阅读 BigQuery 对 Dataricks 的支持博客公告。
- 了解 BigQuery 示例笔记本。
- 了解适用于 Databricks on Google Cloud的 Terraform 提供程序。
- 阅读 Databricks 博客,其中包含有关数据科学主题和数据集的详细信息。