파티션 관리 및 클러스터 권장사항
이 문서에서는 파티션 및 클러스터 추천자의 작동 방식, 권장사항 및 통계를 보는 방법, 파티션 및 클러스터 권장사항을 적용하는 방법을 설명합니다.
추천자 작동 방식
BigQuery 파티셔닝 및 클러스터링 추천자는 BigQuery 테이블이 최적화되도록 파티션 또는 클러스터 권장사항을 생성합니다. 추천자는 BigQuery 테이블의 워크플로를 분석하고 테이블 파티셔닝 또는 테이블 클러스터링을 사용하여 워크플로 및 쿼리 비용을 효율적으로 최적화하기 위한 권장사항을 제공합니다.
추천자 서비스에 대한 자세한 내용은 추천자 개요를 참조하세요.
파티셔닝 및 클러스터링 추천자는 지난 30일 동안의 프로젝트 워크로드 실행 데이터를 사용하여 최적화되지 않은 파티셔닝 및 클러스터링 구성에 대해 각 BigQuery 테이블을 분석합니다. 또한 추천자는 머신러닝을 사용하여 다양한 파티셔닝 또는 클러스터링 구성으로 워크로드 실행을 최적화할 수 있는 정도를 예측합니다. 추천자가 테이블의 파티셔닝 또는 클러스터링을 통해 상당한 비용을 절감하는 것으로 확인되면 추천자는 권장사항을 생성합니다. 파티셔닝 및 클러스터링 추천자는 다음 유형의 권장사항을 생성합니다.
| 기존 테이블 유형 | 권장사항 하위유형 | 권장사항 예시 |
|---|---|---|
| 파티셔닝되지 않음, 클러스터링되지 않음 | 파티션 | 'column_C에서 일별로 파티션을 나누어 월별 약 64 슬롯 시간 절약' |
| 파티셔닝되지 않음, 클러스터링되지 않음 | 클러스터 | 'column_C에서 클러스터링하여 월 약 64 슬롯 시간 절약' |
| 파티셔닝, 클러스터링되지 않음 | 클러스터 | 'column_C에서 클러스터링하여 월 약 64 슬롯 시간 절약' |
각 권장사항은 다음 세 가지 부분으로 구성됩니다.
- 특정 테이블의 파티션 또는 클러스터링에 대한 안내
- 파티션을 나누거나 클러스터링할 테이블의 특정 열
- 권장사항 적용 시 예상되는 월별 절감액
잠재적인 워크로드 절감을 계산하기 위해 추천자는 지난 30일 동안의 이전 실행 워크로드 데이터가 향후 워크로드를 나타내는 것으로 가정합니다.
Recommender API는 테이블 워크로드 정보도 통계 형식으로 반환합니다. 통계는 프로젝트 워크로드를 이해하는 데 도움이 되는 발견 항목으로, 파티션 또는 클러스터 권장사항으로 워크로드 비용을 개선하는 방법에 대한 추가 컨텍스트를 제공합니다.
제한사항
파티셔닝 및 클러스터링 추천자는 legacy SQL을 사용하는 BigQuery 테이블을 지원하지 않습니다. 권장사항을 생성할 때 추천자는 모든 legacy SQL 쿼리를 분석에서 제외합니다. 또한 legacy SQL을 사용하여 BigQuery 테이블에 파티션 권장사항을 적용하면 해당 테이블의 legacy SQL 워크플로가 중단됩니다.
파티션 권장사항을 적용하기 전에 legacy SQL 워크플로를 GoogleSQL로 마이그레이션합니다.
BigQuery는 테이블의 파티셔닝 스키마 변경을 지원하지 않습니다. 테이블 사본에서만 테이블의 파티셔닝을 변경할 수 있습니다. 자세한 내용은 파티션 권장사항 적용을 참고하세요.
위치
파티셔닝 및 클러스터링 추천자는 다음 처리 위치에서 사용할 수 있습니다.
| 리전 설명 | 리전 이름 | 세부정보 | |
|---|---|---|---|
| 아시아 태평양 | |||
| 델리 | asia-south2 |
||
| 홍콩 | asia-east2 |
||
| 자카르타 | asia-southeast2 |
||
| 뭄바이 | asia-south1 |
||
| 오사카 | asia-northeast2 |
||
| 서울 | asia-northeast3 |
||
| 싱가포르 | asia-southeast1 |
||
| 시드니 | australia-southeast1 |
||
| 타이완 | asia-east1 |
||
| 도쿄 | asia-northeast1 |
||
| 유럽 | |||
| 벨기에 | europe-west1 |
|
|
| 베를린 | europe-west10 |
|
|
| EU 멀티 리전 | eu |
||
| 프랑크푸르트 | europe-west3 |
|
|
| 런던 | europe-west2 |
|
|
| 네덜란드 | europe-west4 |
|
|
| 취리히 | europe-west6 |
|
|
| 미주 | |||
| 아이오와 | us-central1 |
|
|
| 라스베이거스 | us-west4 |
||
| 로스앤젤레스 | us-west2 |
||
| 몬트리올 | northamerica-northeast1 |
|
|
| 북버지니아 | us-east4 |
||
| 오리건 | us-west1 |
|
|
| 솔트레이크시티 | us-west3 |
||
| 상파울루 | southamerica-east1 |
|
|
| 토론토 | northamerica-northeast2 |
|
|
| 미국 멀티 리전 | us |
||
시작하기 전에
필수 권한
파티션 및 클러스터 권장사항에 액세스하는 데 필요한 권한을 얻으려면 관리자에게 BigQuery 파티셔닝 클러스터링 추천자 뷰어(roles/recommender.bigqueryPartitionClusterViewer) IAM 역할을 부여해 달라고 요청하세요.
역할 부여에 대한 자세한 내용은 액세스 관리를 참조하세요.
이 사전 정의된 역할에는 파티션 및 클러스터 권장사항에 액세스하는 데 필요한 권한이 포함되어 있습니다. 필요한 정확한 권한을 보려면 필수 권한 섹션을 펼치세요.
필수 권한
파티션 및 클러스터 권장사항에 액세스하려면 다음 권한이 필요합니다.
-
recommender.bigqueryPartitionClusterRecommendations.get -
recommender.bigqueryPartitionClusterRecommendations.list
커스텀 역할이나 다른 사전 정의된 역할을 사용하여 이 권한을 부여받을 수도 있습니다.
BigQuery에서 IAM 역할 및 권한에 대한 자세한 내용은 IAM 소개를 참조하세요.
권장사항 보기
이 섹션에서는 Google Cloud 콘솔, Google Cloud CLI, Recommender API를 사용하여 파티션 및 클러스터 권장사항과 통계를 보는 방법을 설명합니다.
다음 옵션 중 하나를 선택합니다.
콘솔
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
권장사항 탭을 열려면 권장사항 > 모든 권장사항 보기를 클릭합니다.
권장사항 탭에는 프로젝트에 사용할 수 있는 모든 권장사항이 나열됩니다.
BigQuery 워크로드 비용 최적화 패널에서 모두 보기를 클릭합니다.
비용 권장사항 테이블에는 현재 프로젝트에 생성된 모든 권장사항이 나와 있습니다. 예를 들어 다음 스크린샷은 추천자가
example_table테이블을 분석한 다음 대략적인 양의 바이트와 슬롯을 저장하기 위해example_column열의 클러스터링을 추천하는 방법을 보여줍니다.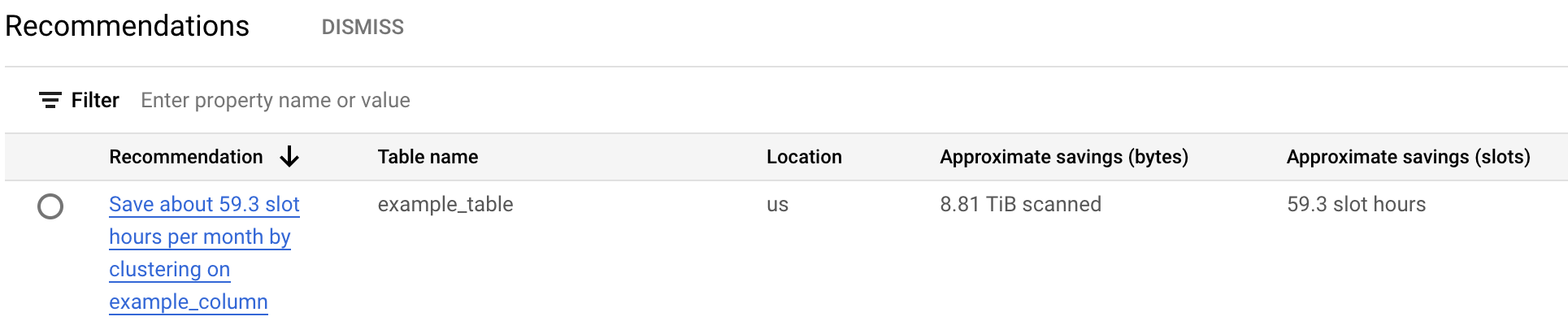
테이블 통계 및 권장사항에 대한 자세한 내용을 보려면 권장사항을 클릭합니다.
gcloud
특정 프로젝트에 대한 파티션 또는 클러스터 권장사항을 보려면 gcloud recommender recommendations list 명령어를 사용합니다.
gcloud recommender recommendations list \
--project=PROJECT_NAME \
--location=REGION_NAME \
--recommender=google.bigquery.table.PartitionClusterRecommender \
--format=FORMAT_TYPE \
다음을 바꿉니다.
PROJECT_NAME: BigQuery 테이블이 포함된 프로젝트의 이름REGION_NAME: 프로젝트가 있는 리전FORMAT_TYPE: 지원되는 gcloud CLI 출력 형식(예: JSON)
| 속성 | 하위유형 관련성 | 설명 |
|---|---|---|
recommenderSubtype |
파티션 또는 클러스터 | 권장사항 유형을 나타냅니다. |
content.overview.partitionColumn |
파티션 | 권장되는 파티셔닝 열 이름입니다. |
content.overview.partitionTimeUnit |
파티션 | 권장되는 파티셔닝 시간 단위입니다. 예를 들어 DAY는 권장 열에 일별 파티션을 포함하는 것이 좋다는 것을 의미합니다. |
content.overview.clusterColumns |
클러스터 | 권장되는 클러스터링 열 이름입니다. |
- 추천자 응답의 다른 필드에 대한 자세한 내용은 REST 리소스:
projects.locations.recommendersrecommendation을 참조하세요. - Recommender API 사용 방법에 대한 자세한 내용은 API 사용 - 권장사항을 참조하세요.
gcloud CLI를 사용하여 테이블 통계를 보려면 gcloud recommender insights list 명령어를 사용합니다.
gcloud recommender insights list \
--project=PROJECT_NAME \
--location=REGION_NAME \
--insight-type=google.bigquery.table.StatsInsight \
--format=FORMAT_TYPE \
다음을 바꿉니다.
PROJECT_NAME: BigQuery 테이블이 포함된 프로젝트의 이름REGION_NAME: 프로젝트가 있는 리전FORMAT_TYPE: 지원되는 gcloud CLI 출력 형식(예: JSON)
| 속성 | 하위유형 관련성 | 설명 |
|---|---|---|
content.existingPartitionColumn |
클러스터 | 기존 파티셔닝 열(있는 경우) |
content.tableSizeTb |
전체 | 테이블 크기(테라바이트 단위) |
content.bytesReadMonthly |
전체 | 테이블에서 읽은 월별 바이트 수 |
content.slotMsConsumedMonthly |
전체 | 테이블에서 실행되는 워크로드에서 소비한 월별 슬롯 밀리초 |
content.queryJobsCountMonthly |
전체 | 테이블에서 실행되는 월별 작업 수 |
- 통계 응답의 다른 필드에 대한 자세한 내용은 REST 리소스:
projects.locations.insightTypes.insights을 참조하세요. - 통계 사용에 대한 자세한 내용은 API 사용 - 통계를 참조하세요.
REST API
특정 프로젝트에 대한 파티션 또는 클러스터 권장사항을 보려면 REST API를 사용합니다. 각 명령어에 gcloud CLI를 사용하여 가져올 수 있는 인증 토큰을 제공해야 합니다. 인증 토큰을 가져오는 방법에 대한 자세한 내용은 ID 토큰을 가져오는 방법을 참조하세요.
curl list 요청을 사용하여 특정 프로젝트에 대한 모든 권장사항을 볼 수 있습니다.
curl
-H "Authorization: Bearer $GCLOUD_AUTH_TOKEN"
-H "x-goog-user-project: PROJECT_NAME" https://recommender.googleapis.com/v1/projects/my-project/locations/us/recommenders/google.bigquery.table.PartitionClusterRecommender/recommendations
다음을 바꿉니다.
GCLOUD_AUTH_TOKEN: 유효한 gcloud CLI 액세스 토큰 이름PROJECT_NAME: BigQuery 테이블이 포함된 프로젝트의 이름
| 속성 | 하위유형 관련성 | 설명 |
|---|---|---|
recommenderSubtype |
파티션 또는 클러스터 | 권장사항 유형을 나타냅니다. |
content.overview.partitionColumn |
파티션 | 권장되는 파티셔닝 열 이름입니다. |
content.overview.partitionTimeUnit |
파티션 | 권장되는 파티셔닝 시간 단위입니다. 예를 들어 DAY는 권장 열에 일별 파티션을 포함하는 것이 좋다는 것을 의미합니다. |
content.overview.clusterColumns |
클러스터 | 권장되는 클러스터링 열 이름입니다. |
- 추천자 응답의 다른 필드에 대한 자세한 내용은 REST 리소스:
projects.locations.recommendersrecommendation을 참조하세요. - Recommender API 사용 방법에 대한 자세한 내용은 API 사용 - 권장사항을 참조하세요.
REST API를 사용하여 테이블 통계를 보려면 다음 명령어를 실행합니다.
curl -H "Authorization: Bearer $GCLOUD_AUTH_TOKEN" -H "x-goog-user-project: PROJECT_NAME" https://recommender.googleapis.com/v1/projects/my-project/locations/us/insightTypes/google.bigquery.table.StatsInsight/insights
다음을 바꿉니다.
GCLOUD_AUTH_TOKEN: 유효한 gcloud CLI 액세스 토큰 이름PROJECT_NAME: BigQuery 테이블이 포함된 프로젝트의 이름
| 속성 | 하위유형 관련성 | 설명 |
|---|---|---|
content.existingPartitionColumn |
클러스터 | 기존 파티셔닝 열(있는 경우) |
content.tableSizeTb |
전체 | 테이블 크기(테라바이트 단위) |
content.bytesReadMonthly |
전체 | 테이블에서 읽은 월별 바이트 수 |
content.slotMsConsumedMonthly |
전체 | 테이블에서 실행되는 워크로드에서 소비한 월별 슬롯 밀리초 |
content.queryJobsCountMonthly |
전체 | 테이블에서 실행되는 월별 작업 수 |
- 통계 응답의 다른 필드에 대한 자세한 내용은 REST 리소스:
projects.locations.insightTypes.insights을 참조하세요. - 통계 사용에 대한 자세한 내용은 API 사용 - 통계를 참조하세요.
클러스터 권장사항 적용
클러스터 권장사항을 적용하려면 다음 중 하나를 수행합니다.
원본 테이블에 클러스터를 직접 적용
기존 BigQuery 테이블에 클러스터 권장사항을 직접 적용할 수 있습니다. 이 방법은 복사된 테이블에 권장사항을 적용하는 것보다 빠르지만 백업 테이블을 보존하지 않습니다.
파티션을 나누지 않았거나 파티션을 나눈 테이블에 새 클러스터링 사양을 적용하려면 다음 단계를 수행합니다.
bq 도구에서 새 클러스터링과 일치하도록 테이블의 클러스터링 사양을 업데이트합니다.
bq update --clustering_fields=CLUSTER_COLUMN DATASET.ORIGINAL_TABLE
다음을 바꿉니다.
CLUSTER_COLUMN: 클러스터링된 열(예:mycolumn)DATASET: 테이블이 포함된 데이터 세트의 이름(예:mydataset)ORIGINAL_TABLE: 원본 테이블 이름입니다(예:mytable).
tables.update또는tables.patchAPI 메서드를 호출하여 클러스터링 사양을 수정할 수도 있습니다.새 클러스터링 사양에 따라 모든 행을 클러스터링하려면 다음
UPDATE문을 실행합니다.UPDATE DATASET.ORIGINAL_TABLE SET CLUSTER_COLUMN=CLUSTER_COLUMN WHERE true
복사된 테이블에 클러스터 적용
BigQuery 테이블에 클러스터 권장사항을 적용할 때 먼저 원본 테이블을 복사한 다음 복사된 테이블에 권장사항을 적용할 수 있습니다. 이 방법을 사용하면 클러스터링 구성 변경사항을 롤백해야 하는 경우 원래 데이터가 보존됩니다.
이 방법을 사용하여 파티션을 나누지 않은 테이블과 파티션을 나눈 테이블 모두에 클러스터 권장사항을 적용할 수 있습니다.
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
쿼리 편집기에서
LIKE연산자를 사용하여 원본 테이블의 동일한 메타데이터(클러스터링 사양 포함)로 빈 테이블을 만듭니다.CREATE TABLE DATASET.COPIED_TABLE LIKE DATASET.ORIGINAL_TABLE
다음을 바꿉니다.
DATASET: 테이블이 포함된 데이터 세트의 이름(예:mydataset)COPIED_TABLE: 복사된 테이블의 이름(예:copy_mytable)ORIGINAL_TABLE: 원본 테이블의 이름(예:mytable)
Google Cloud 콘솔에서 Cloud Shell 편집기를 엽니다.
Cloud Shell 편집기에서
bq update명령어를 사용하여 복사된 테이블의 클러스터링 사양을 권장 클러스터링과 일치하도록 업데이트합니다.bq update --clustering_fields=CLUSTER_COLUMN DATASET.COPIED_TABLE
CLUSTER_COLUMN을 클러스터링할 열로 바꿉니다(예:mycolumn)tables.update또는tables.patchAPI 메서드를 호출하여 클러스터링 사양을 수정할 수도 있습니다.쿼리 편집기에서 파티셔닝 또는 클러스터링이 있는 경우 원본 테이블의 파티셔닝 및 클러스터링 구성을 사용하여 테이블 스키마를 검색합니다. 원본 테이블의
INFORMATION_SCHEMA.TABLES뷰를 확인하여 스키마를 검색할 수 있습니다.SELECT ddl FROM DATASET.INFORMATION_SCHEMA.TABLES WHERE table_name = 'DATASET.ORIGINAL_TABLE;'
출력은
PARTITION BY절을 포함한 ORIGINAL_TABLE의 전체 데이터 정의 언어(DDL) 문입니다. DDL 출력의 인수에 대한 자세한 내용은CREATE TABLE문을 참조하세요.DDL 출력은 원본 테이블의 파티셔닝 유형을 나타냅니다.
파티셔닝 유형 결과 예시 파티션을 나누지 않음 PARTITION BY절이 없습니다.테이블 열로 파티셔닝 PARTITION BY c0PARTITION BY DATE(c0)PARTITION BY DATETIME_TRUNC(c0, MONTH)수집 시간으로 파티셔닝 PARTITION BY _PARTITIONDATEPARTITION BY DATETIME_TRUNC(_PARTITIONTIME, MONTH)복사된 테이블에 데이터를 수집합니다. 사용하는 프로세스는 파티션 유형을 기반으로 합니다.
- 원본 테이블에서 테이블 열로 파티션을 나누지 않거나 파티션을 나눈 경우 원본 테이블의 데이터를 복사된 테이블로 수집합니다.
INSERT INTO DATASET.COPIED_TABLE SELECT * FROM DATASET.ORIGINAL_TABLE
원본 테이블이 수집 시간으로 파티션을 나눈 경우 다음 단계를 따르세요.
INFORMATION_SCHEMA.COLUMNS뷰를 사용하여 데이터 수집 표현식을 형성하는 열 목록을 검색합니다.SELECT ARRAY_TO_STRING(( SELECT ARRAY( SELECT column_name FROM DATASET.INFORMATION_SCHEMA.COLUMNS WHERE table_name = 'ORIGINAL_TABLE')), ", ")
출력은 쉼표로 구분된 열 이름 목록입니다.
원본 테이블에서 복사 테이블로 데이터를 수집합니다.
INSERT DATASET.COPIED_TABLE (COLUMN_NAMES, _PARTITIONTIME) SELECT *, _PARTITIONTIME FROM DATASET.ORIGINAL_TABLE
COLUMN_NAMES를 쉼표로 구분된 이전 단계에서 출력된 열 목록(예:col1, col2, col3)으로 바꿉니다.
이제 원본 테이블과 동일한 데이터가 포함된 클러스터링된 복사 테이블이 있습니다. 다음 단계에서는 원본 테이블을 새로 클러스터링된 테이블로 바꿉니다.
- 원본 테이블에서 테이블 열로 파티션을 나누지 않거나 파티션을 나눈 경우 원본 테이블의 데이터를 복사된 테이블로 수집합니다.
원본 테이블의 이름을 백업 테이블로 바꿉니다.
ALTER TABLE DATASET.ORIGINAL_TABLE RENAME TO DATASET.BACKUP_TABLE
BACKUP_TABLE을 백업 테이블 이름(예:backup_mytable)으로 바꿉니다.복사 테이블의 이름을 원본 테이블로 바꿉니다.
ALTER TABLE DATASET.COPIED_TABLE RENAME TO DATASET.ORIGINAL_TABLE
이제 원본 테이블이 클러스터 권장사항에 따라 클러스터링되었습니다.
- 액세스 및 권한(예: IAM 권한, 행 수준 액세스 또는 열 수준 액세스)
- 테이블 아티팩트(예:테이블 클론, 테이블 스냅샷, 검색 색인)
- 구체화된 뷰 또는 테이블을 복사할 때 실행된 모든 작업 등 진행 중인 테이블 프로세스 상태
- 시간 이동을 사용하여 이전 테이블 데이터에 액세스하는 기능
- 원본 테이블과 연결된 모든 메타데이터입니다(예:
table_option_list또는column_option_list). 자세한 내용은 데이터 정의 언어 문을 참조하세요.
문제가 발생하면 영향을 받는 아티팩트를 새 테이블로 수동으로 이전해야 합니다.
클러스터링된 테이블을 검토한 후 선택적으로 명령어를 사용하여 백업 테이블을 삭제할 수 있습니다.DROP TABLE DATASET.BACKUP_TABLE
구체화된 뷰에 클러스터 적용
테이블의 구체화된 뷰를 만들어 권장사항이 적용된 원본 테이블의 데이터를 저장할 수 있습니다. 권장사항을 적용할 때 구체화된 뷰를 사용하면 자동 새로고침으로 클러스터링된 데이터를 최신 상태로 유지할 수 있습니다. 구체화된 뷰를 쿼리, 유지보수 및 저장할 때는 가격 책정 고려사항이 있습니다. 클러스터링된 구체화된 뷰를 만드는 방법은 클러스터링된 구체화된 뷰를 참조하세요.파티션 권장사항 적용
파티션 권장사항을 적용하려면 원본 테이블의 복사본에 적용해야 합니다. BigQuery는 파티션을 나누지 않은 테이블을 파티션을 나눈 테이블로 변경하거나 테이블의 파티셔닝 스키마를 변경하거나, 기본 테이블과 다른 파티셔닝 스티마로 구체화된 뷰를 만드는 것 등, 적용 중인 테이블의 파티셔닝 스키마를 변경하는 것을 지원하지 않습니다. 테이블 파티셔닝를 변경하는 것은 테이블 사본에서만 가능합니다.
복사된 테이블에 파티션 권장사항 적용
BigQuery 테이블에 파티션 권장사항을 적용할 때 먼저 원본 테이블을 복사한 다음 복사된 테이블에 권장사항을 적용해야 합니다. 파티션을 롤백해야 하는 경우 이 방식을 사용하면 원본 데이터가 보존됩니다.
다음 절차에서는 예시 권장사항을 사용하여 파티션 시간 단위 DAY로 테이블 파티션을 나눕니다.
파티션 권장사항을 사용하여 복사된 테이블을 만듭니다.
CREATE TABLE DATASET.COPIED_TABLE PARTITION BY DATE_TRUNC(PARTITION_COLUMN, DAY) AS SELECT * FROM DATASET.ORIGINAL_TABLE
다음을 바꿉니다.
DATASET: 테이블이 포함된 데이터 세트의 이름(예:mydataset)COPIED_TABLE: 복사된 테이블의 이름(예:copy_mytable)PARTITION_COLUMN: 파티션을 나눌 열(예:mycolumn)
파티션을 나눈 테이블 만들기에 대한 자세한 내용은 파티션을 나눈 테이블 만들기를 참조하세요.
원본 테이블의 이름을 백업 테이블로 바꿉니다.
ALTER TABLE DATASET.ORIGINAL_TABLE RENAME TO DATASET.BACKUP_TABLE
BACKUP_TABLE을 백업 테이블 이름(예:backup_mytable)으로 바꿉니다.복사 테이블의 이름을 원본 테이블로 바꿉니다.
ALTER TABLE DATASET.COPIED_TABLE RENAME TO DATASET.ORIGINAL_TABLE
이제 파티션 권장사항에 따라 원본 테이블의 파티션이 나뉩니다.
- 액세스 및 권한(예: IAM 권한, 행 수준 액세스 또는 열 수준 액세스)
- 테이블 아티팩트(예:테이블 클론, 테이블 스냅샷, 검색 색인)
- 구체화된 뷰 또는 테이블을 복사할 때 실행된 모든 작업 등 진행 중인 테이블 프로세스 상태
- 시간 이동을 사용하여 이전 테이블 데이터에 액세스하는 기능
- 원본 테이블과 연결된 모든 메타데이터입니다(예:
table_option_list또는column_option_list). 자세한 내용은 데이터 정의 언어 문을 참조하세요. - legacy SQL을 사용하여 쿼리 결과를 파티션을 나눈 테이블에 쓰는 기능. 파티션을 나눈 테이블에서는 legacy SQL 사용이 완전히 지원되지 않습니다. 한 가지 해결 방법은 파티션 권장사항을 적용하기 전에 legacy SQL 워크플로를 GoogleSQL로 마이그레이션하는 것입니다.
문제가 발생하면 영향을 받는 아티팩트를 새 테이블로 수동으로 이전해야 합니다.
파티션을 나눈 테이블을 검토한 후 선택적으로 명령어를 사용하여 백업 테이블을 삭제할 수 있습니다.DROP TABLE DATASET.BACKUP_TABLE
가격 책정
이 기능의 가격 책정에 대한 자세한 내용은 BigQuery의 Gemini 가격 책정 개요를 참조하세요.
권장사항을 테이블에 적용할 때 다음과 같은 비용이 발생할 수 있습니다.- 처리 비용. 권장사항을 적용할 때 BigQuery 프로젝트에 데이터 정의 언어(DDL) 또는 데이터 조작 언어(DML) 쿼리를 실행합니다.
- 스토리지 비용. 테이블 복사 방법을 사용하면 복사된(또는 백업) 테이블에 추가 스토리지를 사용합니다.
프로젝트와 연결된 결제 계정에 따라 표준 처리 및 스토리지 요금이 적용됩니다. 자세한 내용은 BigQuery 가격 책정을 참조하세요.
할당량 및 한도
이 기능의 할당량 및 한도에 대한 자세한 내용은 BigQuery의 Gemini 할당량을 참조하세요.
문제 해결
문제: 특정 테이블에 대한 권장사항이 표시되지 않음.
다음과 같은 경우 파티션 및 클러스터 권장사항이 표시되지 않을 수 있습니다.
- 테이블이 10GB 미만인 경우
- 테이블의 DML 작업에 대한 쓰기 비용이 높은 경우
- 지난 30일 동안 테이블을 읽지 않은 경우
- 월별 예상 절감액이 너무 미미한 경우(슬롯 시간 1시간 미만 절감)
- 테이블이 이미 클러스터링된 경우