En esta página, se describen las prácticas recomendadas que debes usar cuando desarrollas tus canalizaciones de Dataflow. El uso de estas prácticas recomendadas tiene los siguientes beneficios:
- Mejora la observabilidad y el rendimiento de la canalización
- Mejora de la productividad de los desarrolladores
- Mejora la capacidad de prueba de la canalización
En los ejemplos de código de Apache Beam de esta página, se usa Java, pero el contenido se aplica a los SDK de Java, Python y Go de Apache Beam.
Preguntas que debes tener en cuenta
Cuando diseñes tu canalización, ten en cuenta las siguientes preguntas:
- ¿Dónde se almacenan los datos de entrada de tu canalización? ¿Cuántos conjuntos de datos de entrada tienes?
- ¿Cómo se ven tus datos?
- ¿Qué quieres hacer con tus datos?
- ¿Dónde deben ir los datos de salida de tu canalización?
- ¿Tu trabajo de Dataflow usa Assured Workloads?
Usa plantillas
Para acelerar el desarrollo de la canalización, en lugar de compilar una canalización mediante la escritura de código de Apache Beam, usa una plantilla de Dataflow cuando sea posible. Las plantillas tienen los siguientes beneficios:
- Las plantillas se pueden reutilizar.
- Las plantillas te permiten personalizar cada trabajo cambiando parámetros de canalización específicos.
- Cualquier persona a la que le otorgues permisos podrá usar la plantilla para implementar la canalización. Por ejemplo, un desarrollador puede crear un trabajo a partir de una plantilla, y un científico de datos de la organización puede implementar esa plantilla más adelante.
Puedes usar una plantilla que proporciona Google o crear la tuya. Algunas plantillas proporcionadas por Google te permiten agregar lógica personalizada como un paso de la canalización. Por ejemplo, la plantilla de suscripción a Pub/Sub a BigQuery proporciona un parámetro para ejecutar una función definida por el usuario (UDF) de JavaScript que se almacena en Cloud Storage.
Las plantillas que proporciona Google son plantillas de código abierto según la licencia Apache 2.0, por lo que puedes usarlas como base para las canalizaciones nuevas. Las plantillas también son útiles como ejemplos de código. Consulta el código de la plantilla en el repositorio de GitHub.
Assured Workloads
Assured Workloads ayuda a aplicar los requisitos de seguridad y cumplimiento para los clientes de Google Cloud. Por ejemplo, las Regiones de la UE y la asistencia con controles de soberanía ayudan a aplicar las garantías de residencia de datos y soberanía de los datos para los clientes ubicados en la UE. Para proporcionar estas características, algunas características de Dataflow están restringidas o limitadas. Si usas Assured Workloads con Dataflow, todos los recursos a los que accede tu canalización deben estar ubicados en el proyecto o carpeta de Assured Workloads de tu organización. Entre estos recursos, se incluyen los siguientes:
- Buckets de Cloud Storage
- Conjuntos de datos de BigQuery
- Temas y suscripciones de Pub/Sub
- Conjuntos de datos de Firestore
- Conectores de E/S
En Dataflow, para los trabajos de transmisión creados después del 7 de marzo de 2024, todos los datos del usuario se encriptan con CMEK.
En los trabajos de transmisión creados antes del 7 de marzo de 2024, las claves de datos que se usan en las operaciones basadas en claves, como la renderización en ventanas, la agrupación y la unión, no están protegidas por la encriptación de CMEK. Para habilitar esta encriptación para tus trabajos, desvía o cancela el trabajo y, luego, reinícialo. Para obtener más información, consulta Encriptación de artefactos de estado de canalización.
Comparte datos entre canalizaciones
No existe un mecanismo de comunicación de canalización cruzada específico de Dataflow para compartir datos o procesar el contexto entre las canalizaciones. Puedes usar un almacenamiento duradero, como Cloud Storage, o un almacenamiento en caché en memoria, como App Engine, para compartir datos entre las instancias de canalización.
Programar trabajos
Puedes automatizar la ejecución de canalizaciones de las siguientes maneras:
- Usa Cloud Scheduler.
- Usa Dataflow Operator de Apache Airflow, uno de los varios operadores de Google Cloud en un flujo de trabajo de Cloud Composer.
- Ejecuta procesos de trabajo personalizados (cron) en Compute Engine
Prácticas recomendadas para escribir código de canalización
En las siguientes secciones, se proporcionan prácticas recomendadas para crear canalizaciones con el código de Apache Beam.
Estructura tu código de Apache Beam
Para crear canalizaciones, es común usar la transformación genérica de procesamiento paralelo de ParDo de Apache Beam.
Cuando aplicas una transformación ParDo, proporcionas el código en forma de un objeto DoFn. DoFn es una clase del SDK de Apache Beam que define una función de procesamiento distribuido.
Puedes pensar en tu código DoFn como pequeñas entidades independientes: podría haber muchas instancias en ejecución en diferentes máquinas, cada una sin conocimiento de las otras. Por lo tanto, te recomendamos que crees funciones puras, que son ideales para la naturaleza paralela y distribuida de los elementos DoFn.
Las funciones puras tienen las siguientes características:
- Las funciones puras no dependen de un estado oculto o externo.
- No tienen efectos secundarios observables.
- Son determinísticas.
El modelo de función pura no es estrictamente rígido. Cuando tu código no depende de elementos que el servicio de Dataflow no garantiza, la información de estado o los datos de inicialización externa pueden ser válidos para DoFn y otros objetos de función.
Cuando organices tus transformaciones ParDo y crees tus elementos DoFn, ten en cuenta los siguientes lineamientos:
- Cuando usas procesamiento del tipo “exactamente una vez”, el servicio de Dataflow garantiza que cada elemento de tu entrada
PCollectionse procesa mediante una instanciaDoFnexactamente una vez. - El servicio de Dataflow no garantiza cuántas veces se invoca un
DoFn. - El servicio de Dataflow no garantiza con exactitud cómo se agrupan los elementos distribuidos. No garantiza qué elementos (si los hay) se procesan juntos.
- El servicio de Dataflow no garantiza la cantidad exacta de instancias de
DoFnque se crean en el transcurso de una canalización. - El servicio de Dataflow es tolerante a errores y puede que vuelva a probar el código varias veces si los trabajadores encuentran problemas.
- Es posible que el servicio de Dataflow cree copias de seguridad de tu código. Es posible que se produzcan problemas con los efectos secundarios manuales, por ejemplo, si tu código crea archivos temporales con nombres no únicos o se basa en ellos.
- El servicio de Dataflow serializa el procesamiento de elementos por instancia de
DoFn. Tu código no necesita ser seguro para subprocesos de forma estricta, pero cualquier estado compartido entre varias instancias deDoFndebe ser seguro para subprocesos.
Crea bibliotecas de transformaciones reutilizables
El modelo de programación de Apache Beam te permite volver a usar transformaciones. Si creas una biblioteca compartida de transformaciones comunes, puedes mejorar la reutilización, la capacidad de prueba y la propiedad de código por parte de diferentes equipos.
Considera los siguientes dos ejemplos de código Java, que leen eventos de pago. Si suponemos que ambas canalizaciones realizan el mismo procesamiento, pueden usar las mismas transformaciones a través de una biblioteca compartida para los pasos de procesamiento restantes.
El primer ejemplo es de una fuente ilimitada de Pub/Sub:
PipelineOptions options = PipelineOptionsFactory.create();
Pipeline p = Pipeline.create(options)
// Initial read transform
PCollection<PaymentEvent> payments =
p.apply("Read from topic",
PubSubIO.readStrings().withTimestampAttribute(...).fromTopic(...))
.apply("Parse strings into payment events",
ParDo.of(new ParsePaymentEventFn()));
El segundo ejemplo proviene de una fuente de base de datos relacional limitada:
PipelineOptions options = PipelineOptionsFactory.create();
Pipeline p = Pipeline.create(options);
PCollection<PaymentEvent> payments =
p.apply(
"Read from database table",
JdbcIO.<PaymentEvent>read()
.withDataSourceConfiguration(...)
.withQuery(...)
.withRowMapper(new RowMapper<PaymentEvent>() {
...
}));
La forma en que implementas las prácticas recomendadas de reutilización de código varía según el lenguaje de programación y la herramienta de compilación. Por ejemplo, si usas Maven, puedes separar el código de transformación en su propio módulo. Luego, puedes incluir el módulo como un submódulo en proyectos con varios módulos más grandes para canalizaciones diferentes, como se muestra en el siguiente ejemplo de código:
// Reuse transforms across both pipelines
payments
.apply("ValidatePayments", new PaymentTransforms.ValidatePayments(...))
.apply("ProcessPayments", new PaymentTransforms.ProcessPayments(...))
...
Para obtener más información, consulta las siguientes páginas de documentación de Apache Beam:
- Requisitos para escribir código de usuario en las transformaciones de Apache Beam
- Guía de estilo de
PTransform: guía de estilo para escritores de nuevas colecciones reutilizables dePTransform
Usa colas de mensajes no entregados para el manejo de errores
A veces, la canalización no puede procesar elementos. Los problemas de datos son una causa común. Por ejemplo, un elemento que contiene JSON con formato erróneo puede causar fallas en los análisis.
Aunque puedes detectar excepciones dentro del método DoFn.ProcessElement, registrar el error y descartar el elemento, este enfoque pierde los datos y evita que estos sean inspeccionados más tarde para manejarlos de forma manual o solucionar problemas.
En su lugar, usa un patrón llamado cola de mensajes no entregados (cola de mensajes sin procesar).
Captura excepciones en el método DoFn.ProcessElement y registra los errores. En lugar de descartar el elemento con errores, usa los resultados de la ramificación para escribir elementos con errores en un objeto PCollection separado. Luego, estos elementos se escriben en un receptor de datos para su posterior inspección y control mediante una transformación distinta.
En el siguiente ejemplo de código Java, se muestra cómo implementar el patrón de cola de mensajes no entregados.
TupleTag<Output> successTag = new TupleTag<>() {};
TupleTag<Input> deadLetterTag = new TupleTag<>() {};
PCollection<Input> input = /* ... */;
PCollectionTuple outputTuple =
input.apply(ParDo.of(new DoFn<Input, Output>() {
@Override
void processElement(ProcessContext c) {
try {
c.output(process(c.element()));
} catch (Exception e) {
LOG.severe("Failed to process input {} -- adding to dead-letter file",
c.element(), e);
c.sideOutput(deadLetterTag, c.element());
}
}).withOutputTags(successTag, TupleTagList.of(deadLetterTag)));
// Write the dead-letter inputs to a BigQuery table for later analysis
outputTuple.get(deadLetterTag)
.apply(BigQueryIO.write(...));
// Retrieve the successful elements...
PCollection<Output> success = outputTuple.get(successTag);
// and continue processing ...
Usa Cloud Monitoring a fin de aplicar diferentes políticas de supervisión y alertas para la cola de mensajes no entregados de la canalización. Por ejemplo, puedes visualizar la cantidad y el tamaño de los elementos procesados por la transformación de mensajes no entregados y configurar alertas para activarse si se cumplen ciertas condiciones de umbral.
Administra las mutaciones del esquema
Puedes controlar los datos que tienen esquemas inesperados (pero válidos) mediante un patrón de mensajes no entregados, que solo escribe elementos con errores en un objeto PCollection separado.
En algunos casos, querrás controlar automáticamente los elementos que reflejan un esquema mutado como elementos válidos. Por ejemplo, si el esquema de un elemento refleja una mutación como la adición de campos nuevos, puedes adaptar el esquema del receptor de datos a las mutaciones.
La mutación automática de esquemas se basa en el enfoque de ramificación de salida que se usa en el patrón de mensajes no entregados. Sin embargo, en este caso, se activa una transformación que muta el esquema de destino cada vez que se encuentran esquemas aditivos. Para ver un ejemplo de este enfoque, consulta Cómo manejar mutaciones de esquemas JSON en una canalización de transmisión con Square Enix en el blog de Google Cloud.
Decide cómo unir conjuntos de datos
Unir conjuntos de datos es un caso de uso común para las canalizaciones de datos. Puedes usar entradas laterales o la transformación CoGroupByKey para realizar uniones en tu canalización.
Cada uno tiene ventajas y desventajas.
Las entradas complementarias proporcionan una manera flexible de resolver problemas comunes de procesamiento de datos, como el enriquecimiento de datos y las búsquedas con claves. A diferencia de los objetos PCollection, las entradas complementarias son mutables y se pueden determinar en el entorno de ejecución. Por ejemplo, los valores en una entrada complementaria se pueden calcular mediante otra rama en la canalización o se pueden determinar por medio de una llamada a un servicio remoto.
Dataflow admite entradas complementarias mediante la persistencia de los datos en almacenamiento continuo, similar a un disco compartido. Esta configuración hace que la entrada complementaria completa esté disponible para todos los trabajadores.
Sin embargo, los tamaños de entradas complementarias pueden ser muy grandes y es posible que no quepan en la memoria del trabajador. La lectura de una entrada complementaria grande puede causar problemas de rendimiento si los trabajadores necesitan leer de manera constante desde el almacenamiento continuo.
La transformación CoGroupByKey es una transformación central de Apache Beam que combina (fusiona) varios objetos y grupos PCollection con una clave común. A diferencia de una entrada complementaria, que permite que todos los datos de entrada complementaria estén disponibles para cada trabajador, CoGroupByKey realiza una operación aleatoria (agrupación) a fin de distribuir datos entre los trabajadores. Por lo tanto, CoGroupByKey es ideal cuando los objetos PCollection que deseas unir son muy grandes y no se ajustan a la memoria del trabajador.
Sigue estos lineamientos para decidir si quieres usar entradas complementarias o CoGroupByKey:
- Usa entradas complementarias cuando uno de los objetos
PCollectionque unes es mucho más pequeño que el otro, y si el objetoPCollectionmás pequeño se ajusta a la memoria del trabajador. Almacenar las entradas complementarias en la memoria por completo permite que sea más rápido y eficiente recuperar elementos. - Usa entradas complementarias cuando tengas un objeto
PCollectionque se deba unir muchas veces en la canalización. En lugar de usar varias transformacionesCoGroupByKey, crea una única entrada complementaria que pueda reutilizarse en varias transformacionesParDo. - Usa
CoGroupByKeysi necesitas recuperar una gran proporción de un objetoPCollectionque exceda de forma considerable la memoria del trabajador.
Para obtener más información, consulta Cómo solucionar problemas de errores de memoria en Dataflow.
Minimiza las costosas operaciones por elemento
Una instancia DoFn procesa lotes de elementos llamados conjuntos, que son unidades atómicas de trabajo que constan de cero o más elementos. Luego, el método DoFn.ProcessElement procesa los elementos individuales, que se ejecuta para cada elemento. Debido a que se llama al método DoFn.ProcessElement para cada elemento, cualquier operación que requiera mucho tiempo o cuyo procesamiento sea costoso, y que se invoque por ese método, se ejecuta para cada elemento que procesa el método.
Si necesitas realizar operaciones costosas solo una vez para un lote de elementos, incluye esas operaciones en el método DoFn.Setup o en el método DoFn.StartBundle, y no en el elemento DoFn.ProcessElement. Estos son algunos ejemplos de operaciones:
Analizar un archivo de configuración que controla algún aspecto del comportamiento de la instancia
DoFn. Invoca esta acción solo una vez, cuando se inicializa la instanciaDoFn, con el métodoDoFn.Setup.Crear una instancia de un cliente de corta duración que se vuelve a usar en todos los elementos de un paquete, por ejemplo, cuando todos los elementos del paquete se envían a través de una sola conexión de red. Invoca esta acción una vez por paquete con el método
DoFn.StartBundle.
Limita los tamaños de los lotes y las llamadas simultáneas a servicios externos
Cuando llamas a servicios externos, puedes reducir las sobrecargas por llamada mediante la transformación GroupIntoBatches. Esta transformación crea lotes de elementos de un tamaño especificado.
El procesamiento por lotes envía elementos a un servicio externo como una carga útil, en lugar de hacerlo de forma individual.
En combinación con el procesamiento por lotes, puedes limitar la cantidad máxima de llamadas paralelas (en simultáneo) al servicio externo. Para ello, elige las claves adecuadas a fin de particionar los datos entrantes. La cantidad de particiones determina la paralelización máxima. Por ejemplo, si cada elemento recibe la misma clave, una transformación descendente para llamar al servicio externo no se ejecuta en paralelo.
Considera uno de los siguientes enfoques con el fin de producir claves para elementos:
- Elige un atributo del conjunto de datos para usarlo como claves de datos, como los IDs del usuario.
- Genera claves de datos para dividir los elementos de forma aleatoria en una cantidad fija de particiones, en la que la cantidad de valores de claves posibles determina la cantidad de particiones. Debes crear particiones suficientes para el paralelismo.
Cada partición debe tener suficientes elementos para que la transformación
GroupIntoBatchessea útil.
En la siguiente muestra de código de Java, se muestra cómo dividir elementos de forma aleatoria en más de diez particiones:
// PII or classified data which needs redaction.
PCollection<String> sensitiveData = ...;
int numPartitions = 10; // Number of parallel batches to create.
PCollection<KV<Long, Iterable<String>>> batchedData =
sensitiveData
.apply("Assign data into partitions",
ParDo.of(new DoFn<String, KV<Long, String>>() {
Random random = new Random();
@ProcessElement
public void assignRandomPartition(ProcessContext context) {
context.output(
KV.of(randomPartitionNumber(), context.element()));
}
private static int randomPartitionNumber() {
return random.nextInt(numPartitions);
}
}))
.apply("Create batches of sensitive data",
GroupIntoBatches.<Long, String>ofSize(100L));
// Use batched sensitive data to fully utilize Redaction API,
// which has a rate limit but allows large payloads.
batchedData
.apply("Call Redaction API in batches", callRedactionApiOnBatch());
Identifica problemas de rendimiento que provocan los pasos fusionados
Dataflow compila un gráfico de pasos que representa la canalización, en función de las transformaciones y los datos que usaste para construirla. Este gráfico se conoce como el gráfico de ejecución de la canalización.
Cuando implementas la canalización, Dataflow puede modificar su gráfico de ejecución para mejorar el rendimiento. Por ejemplo, Dataflow podría fusionar algunas operaciones, un proceso conocido como optimización de fusiones, para evitar el rendimiento y el impacto en el costo de escribir cada objeto PCollection intermedio en tu canalización.
En algunos casos, Dataflow podría determinar de manera incorrecta la forma óptima de fusionar operaciones en la canalización, lo que puede limitar la capacidad de tu trabajo para usar todos los trabajadores disponibles. En esos casos, puedes evitar que las operaciones se combinen.
Considera el siguiente código de ejemplo de Apache Beam. Una transformación GenerateSequence crea un objeto PCollection delimitado pequeño, que luego se procesa con dos transformaciones ParDo descendentes.
La transformación Find Primes Less-than-N puede ser costosa en términos de procesamiento y es probable que se ejecute con lentitud para números grandes. Por el contrario, es probable que la transformación Increment Number se complete con rapidez.
import com.google.common.math.LongMath;
...
public class FusedStepsPipeline {
final class FindLowerPrimesFn extends DoFn<Long, String> {
@ProcessElement
public void processElement(ProcessContext c) {
Long n = c.element();
if (n > 1) {
for (long i = 2; i < n; i++) {
if (LongMath.isPrime(i)) {
c.output(Long.toString(i));
}
}
}
}
}
public static void main(String[] args) {
Pipeline p = Pipeline.create(options);
PCollection<Long> sequence = p.apply("Generate Sequence",
GenerateSequence
.from(0)
.to(1000000));
// Pipeline branch 1
sequence.apply("Find Primes Less-than-N",
ParDo.of(new FindLowerPrimesFn()));
// Pipeline branch 2
sequence.apply("Increment Number",
MapElements.via(new SimpleFunction<Long, Long>() {
public Long apply(Long n) {
return ++n;
}
}));
p.run().waitUntilFinish();
}
}
En el siguiente diagrama, se muestra una representación gráfica de la canalización en la interfaz de supervisión de Dataflow.
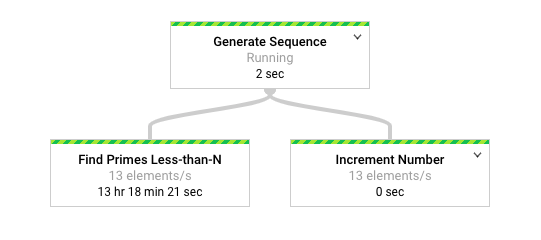
La interfaz de supervisión de Dataflow muestra que se produce la misma velocidad de procesamiento lenta para ambas transformaciones, específicamente 13 elementos por segundo. Es posible que la transformación Increment Number procese los elementos con rapidez, pero parece que está vinculada a la misma tasa de procesamiento que Find Primes Less-than-N.
El motivo es que Dataflow fusiona los pasos en una sola etapa, lo que evita que se ejecuten de forma independiente. Puedes usar el comando gcloud dataflow jobs describe para obtener más información:
gcloud dataflow jobs describe --full job-id --format json
En el resultado que se obtiene, los pasos fusionados se describen en el objeto ExecutionStageSummary en el array ComponentTransform:
...
"executionPipelineStage": [
{
"componentSource": [
...
],
"componentTransform": [
{
"name": "s1",
"originalTransform": "Generate Sequence/Read(BoundedCountingSource)",
"userName": "Generate Sequence/Read(BoundedCountingSource)"
},
{
"name": "s2",
"originalTransform": "Find Primes Less-than-N",
"userName": "Find Primes Less-than-N"
},
{
"name": "s3",
"originalTransform": "Increment Number/Map",
"userName": "Increment Number/Map"
}
],
"id": "S01",
"kind": "PAR_DO_KIND",
"name": "F0"
}
...
En este caso, la transformación Find Primes Less-than-N es el paso lento, por lo que dividir la fusión antes de ese paso es una estrategia adecuada. Un método para separar los pasos es insertar una transformación GroupByKey y desagrupar antes del paso, como se observa en la siguiente muestra de código de Java.
sequence
.apply("Map Elements", MapElements.via(new SimpleFunction<Long, KV<Long, Void>>() {
public KV<Long, Void> apply(Long n) {
return KV.of(n, null);
}
}))
.apply("Group By Key", GroupByKey.<Long, Void>create())
.apply("Emit Keys", Keys.<Long>create())
.apply("Find Primes Less-than-N", ParDo.of(new FindLowerPrimesFn()));
También puedes combinar estos pasos innecesarios en una transformación compuesta reutilizable.
Después de separar los pasos, cuando ejecutes la canalización, Increment Number se completa en cuestión de segundos y la transformación Find Primes Less-than-N de larga ejecución se ejecuta en una etapa separada.
En este ejemplo, se aplica una operación de agrupación y desagrupación para separar los pasos.
Puedes usar otros enfoques en otras circunstancias. En este caso, controlar el resultado duplicado no es un problema, dada la salida consecutiva de la transformación GenerateSequence.
A los objetos KV con claves duplicadas se les anula el duplicado y pasan a tener una sola clave en las transformaciones agrupadas (GroupByKey) y desagrupadas (Keys). Si deseas conservar duplicados después de las operaciones de agrupación y desagrupación, crea pares clave-valor con los siguientes pasos:
- Usa una clave aleatoria y la entrada original como valor.
- Agrupa con la clave aleatoria.
- Emite los valores de cada clave como resultado.
También puedes usar una transformación Reshuffle para evitar la fusión de transformaciones circundantes. Sin embargo, los efectos secundarios de la transformación Reshuffle no se pueden transferir a través de diferentes ejecutores de Apache Beam.
Para obtener más información sobre el paralelismo y la optimización de fusiones, consulta Ciclo de vida de la canalización.
Usa las métricas de Apache Beam para recopilar estadísticas de canalización
Las métricas de Apache Beam son una clase de utilidad que produce métricas para informar las propiedades de una canalización en ejecución. Cuando usas Cloud Monitoring, las métricas de Apache Beam están disponibles como métricas personalizadas de Cloud Monitoring.
En el siguiente ejemplo, se muestran las métricas de Counter de Apache Beam que se usan en una subclase DoFn.
En el código de ejemplo, se usan dos contadores. Un contador realiza un seguimiento de las fallas de análisis de JSON (malformedCounter) y el otro realiza un seguimiento de si el mensaje JSON es válido, pero contiene una carga útil vacía (emptyCounter). En Cloud Monitoring, los nombres de las métricas personalizadas son custom.googleapis.com/dataflow/malformedJson y custom.googleapis.com/dataflow/emptyPayload. Puedes usar las métricas personalizadas para crear visualizaciones y políticas de alertas en Cloud Monitoring.
final TupleTag<String> errorTag = new TupleTag<String>(){};
final TupleTag<MockObject> successTag = new TupleTag<MockObject>(){};
final class ParseEventFn extends DoFn<String, MyObject> {
private final Counter malformedCounter = Metrics.counter(ParseEventFn.class, "malformedJson");
private final Counter emptyCounter = Metrics.counter(ParseEventFn.class, "emptyPayload");
private Gson gsonParser;
@Setup
public setup() {
gsonParser = new Gson();
}
@ProcessElement
public void processElement(ProcessContext c) {
try {
MyObject myObj = gsonParser.fromJson(c.element(), MyObject.class);
if (myObj.getPayload() != null) {
// Output the element if non-empty payload
c.output(successTag, myObj);
}
else {
// Increment empty payload counter
emptyCounter.inc();
}
}
catch (JsonParseException e) {
// Increment malformed JSON counter
malformedCounter.inc();
// Output the element to dead-letter queue
c.output(errorTag, c.element());
}
}
}
Más información
En las siguientes páginas, se proporciona más información para estructurar tu canalización, elegir qué transformaciones aplicar a tus datos y qué tener en cuenta para elegir los métodos de entrada y salida de tu canalización.
Para obtener más información sobre cómo compilar tu código de usuario, consulta los requisitos para las funciones que proporciona el usuario.