Quando ottimizzi il rendimento di un'applicazione, prendi in considerazione l'utilizzo di NDB. Ad esempio, se un'applicazione legge un valore che non è nella cache, la lettura richiede un po' di tempo. Potresti essere in grado di velocizzare la tua applicazione eseguendo le azioni Datastore in parallelo con altre operazioni o eseguendo alcune azioni Datastore in parallelo tra loro.
La libreria client NDB fornisce molte funzioni asincrone ("async").
Ciascuna di queste funzioni
consente a un'applicazione di inviare una richiesta a Datastore. La funzione restituisce
immediatamente un
oggetto Future. L'applicazione può svolgere altre attività mentre Datastore gestisce
la richiesta.
Dopo che Datastore gestisce la richiesta, l'applicazione può ottenere i risultati
dall'oggetto Future.
Introduzione
Supponiamo che uno dei gestori delle richieste della tua applicazione debba utilizzare NDB per scrivere qualcosa, ad esempio per registrare la richiesta. Deve anche eseguire altre operazioni NDB, ad esempio per recuperare alcuni dati.
Sostituendo la chiamata a put() con una chiamata al suo
equivalente asincrono put_async(), l'applicazione
può fare altre cose immediatamente anziché bloccarsi su put().
In questo modo, le altre funzioni NDB e il rendering dei modelli possono avvenire mentre Datastore scrive i dati. L'applicazione non si blocca su Datastore finché non riceve dati da Datastore.
In questo esempio, è un po' sciocco chiamare future.get_result:
l'applicazione non utilizza mai il risultato di NDB. Questo codice
serve solo per assicurarsi che il gestore delle richieste non esca prima
che NDB put finisca; se il gestore delle richieste esce troppo presto,
l'inserimento potrebbe non avvenire mai. Per comodità, puoi decorare il gestore delle richieste
con @ndb.toplevel. Questo indica al gestore di non uscire finché le richieste asincrone non sono state completate. In questo modo puoi
inviare la richiesta e non preoccuparti del risultato.
Puoi specificare un intero WSGIApplication come
ndb.toplevel. In questo modo, ogni gestore di
WSGIApplication attende tutte le richieste
asincrone prima di restituire.
Non esegue "toplevel" di tutti i gestori di WSGIApplication.
L'utilizzo di un'applicazione toplevel è più comodo di tutte le sue funzioni di gestione. Tuttavia, se un metodo di gestione utilizza yield,
deve comunque essere racchiuso in un altro decoratore,
@ndb.synctasklet; altrimenti, l'esecuzione si interromperà in corrispondenza di
yield e non verrà completata.
Utilizzo di API asincrone e Futures
Quasi tutte le funzioni NDB sincrone hanno una controparte _async. Ad esempio, put() ha put_async().
Gli argomenti della funzione asincrona sono sempre gli stessi della versione sincrona.
Il valore restituito di un metodo asincrono è sempre un
Future o (per le funzioni "multi") un elenco di
Future.
Un Future è un oggetto che mantiene lo stato di un'operazione
che è stata avviata ma potrebbe non essere ancora stata completata; tutte le API
asincrone restituiscono uno o più Futures.
Puoi chiamare la funzione Future's get_result()
per chiedere il risultato dell'operazione;
Future si blocca, se necessario, finché il risultato non è disponibile,
e poi te lo fornisce.
get_result() restituisce il valore che verrebbe restituito
dalla versione sincrona dell'API.
Nota:se hai utilizzato Futures in altri linguaggi di programmazione, potresti pensare
di poter utilizzare un Future direttamente come risultato. Non funziona qui.
Queste lingue utilizzano
futuri impliciti, mentre NDB utilizza futuri espliciti.
Chiama il numero get_result() per ottenere il risultato
dell'NDB Future.
Cosa succede se l'operazione genera un'eccezione? Dipende da quando si verifica l'eccezione. Se NDB rileva un problema durante l'esecuzione di una richiesta
(ad esempio un argomento di tipo errato), il metodo _async()
genera un'eccezione. Se l'eccezione viene rilevata, ad esempio, dal server Datastore, il metodo _async() restituisce un Future e l'eccezione verrà generata quando l'applicazione chiama il relativo get_result(). Non preoccuparti troppo di questo, tutto
finisce per comportarsi in modo abbastanza naturale; forse la differenza più grande è
che se viene stampata una traccia dello stack, vedrai alcune parti del meccanismo
asincrono di basso livello esposte.
Ad esempio, supponiamo che tu stia scrivendo un'applicazione guestbook. Se l'utente ha eseguito l'accesso, vuoi presentare una pagina che mostri i post più recenti del guestbook. In questa pagina dovrebbe essere visualizzato anche il nickname dell'utente. L'applicazione ha bisogno di due tipi di informazioni: i dati dell'account dell'utente che ha eseguito l'accesso e i contenuti dei post del guestbook. La versione "sincrona" di questa applicazione potrebbe avere il seguente aspetto:
Qui sono presenti due azioni di I/O indipendenti: recupero dell'entità
Account e recupero delle entità Guestbook
recenti. Utilizzando l'API sincrona, queste operazioni vengono eseguite una dopo l'altra;
attendiamo di ricevere i dati dell'account prima di recuperare le
entità del guestbook. Tuttavia, l'applicazione non ha bisogno
immediatamente dei dati dell'account. Possiamo sfruttare questa opportunità e utilizzare le API asincrone:
Questa versione del codice crea prima due Futures
(acct_future e recent_entries_future)
e poi le attende. Il server elabora entrambe le richieste in parallelo.
Ogni chiamata alla funzione _async() crea un oggetto Future
e invia una richiesta al server Datastore. Il server può iniziare
a elaborare la richiesta immediatamente. Le risposte del server potrebbero essere restituite
in qualsiasi ordine arbitrario; l'oggetto Future collega le risposte alle
richieste corrispondenti.
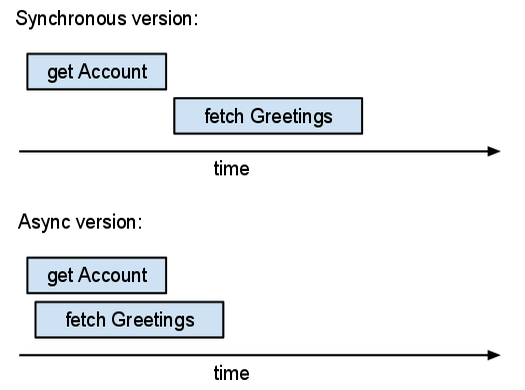
Il tempo totale (reale) trascorso nella versione asincrona è approssimativamente uguale al tempo massimo tra le operazioni. Il tempo totale trascorso nella versione sincrona supera la somma dei tempi di operazione. Se puoi eseguire più operazioni in parallelo, le operazioni asincrone sono più utili.
Per vedere quanto tempo impiegano le query della tua applicazione o quante operazioni di I/O esegue per richiesta, valuta la possibilità di utilizzare Appstats. Questo strumento può mostrare grafici simili al disegno riportato sopra in base all'instrumentazione di un'app live.
Utilizzo dei tasklet
Un tasklet NDB è una parte di codice che potrebbe essere eseguita contemporaneamente ad altro codice. Se scrivi un tasklet, la tua applicazione può utilizzarlo in modo simile a una funzione NDB asincrona: chiama il tasklet, che restituisce un Future; in un secondo momento, la chiamata al metodo get_result() di Future ottiene il risultato.
I tasklet sono un modo per scrivere funzioni simultanee senza
thread; i tasklet vengono eseguiti da un ciclo di eventi e possono sospendersi
bloccandosi per I/O o per qualche altra operazione utilizzando un'istruzione
yield. Il concetto di operazione di blocco viene astratto nella classe
Future, ma un tasklet può anche yield un
RPC per attendere il completamento.
Quando il tasklet ha un risultato, raise un'eccezione ndb.Return; NDB associa quindi il risultato al Future yield in precedenza.
Quando scrivi un tasklet NDB, utilizzi yield e
raise in modo insolito. Pertanto, se cerchi esempi di
come utilizzarli, probabilmente non troverai codice come un tasklet NDB.
Per trasformare una funzione in un tasklet NDB:
- decora la funzione con
@ndb.tasklet, - sostituisci tutte le chiamate al datastore sincrono con
yields di chiamate al datastore asincrono, - fai in modo che la funzione "restituisca" il suo valore di ritorno con
raise ndb.Return(retval)(non necessario se la funzione non restituisce nulla).
Un'applicazione può utilizzare i tasklet per un controllo più preciso delle API asincrone. Ad esempio, considera lo schema seguente:
...
Quando viene visualizzato un messaggio, è opportuno mostrare il nickname dell'autore. Il modo "sincrono" per recuperare i dati per mostrare un elenco di messaggi potrebbe essere il seguente:
Purtroppo, questo approccio è inefficiente. Se lo avessi esaminato in Appstats, vedresti che le richieste "Get" sono in serie. Potresti vedere il seguente pattern "a scala".
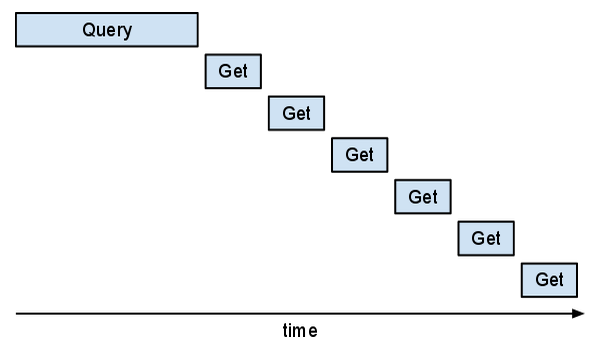
Questa parte del programma sarebbe più veloce se le "Gets" potessero sovrapporsi.
Potresti riscrivere il codice per utilizzare get_async, ma è
difficile tenere traccia di quali richieste e messaggi asincroni appartengono insieme.
L'applicazione può definire la propria funzione "async" rendendola un tasklet. In questo modo, puoi organizzare il codice in modo meno confuso.
Inoltre, anziché utilizzare
acct = key.get() o
acct = key.get_async().get_result(),
la funzione deve utilizzare
acct = yield key.get_async().
Questo yield indica a NDB che questo è un buon punto per sospendere questo
tasklet e consentire l'esecuzione di altri tasklet.
Se decori una funzione generatore con @ndb.tasklet,
la funzione restituisce un Future anziché un
oggetto generatore. All'interno del tasklet, qualsiasi yield di un
Future attende e restituisce il risultato di Future.
Ad esempio:
Tieni presente che, sebbene get_async() restituisca un
Future, il framework tasklet fa sì che l'espressione yield
restituisca il risultato di Future alla variabile
acct.
map() chiama callback() più volte.
Tuttavia, yield ..._async() in callback()
consente allo scheduler di NDB di inviare molte richieste asincrone prima di attendere
il completamento di una qualsiasi di queste.
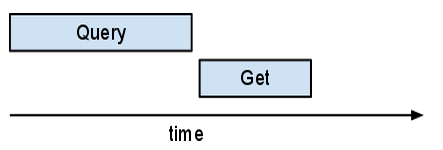
Se esamini questo aspetto in Appstats, potresti notare con sorpresa che queste richieste multiple non si sovrappongono, ma vengono tutte eseguite nella stessa richiesta. NDB implementa un "autobatcher". Il batcher automatico raggruppa più richieste in un singolo batch RPC al server; lo fa in modo tale che, finché c'è altro lavoro da fare (potrebbe essere eseguito un altro callback), raccoglie le chiavi. Non appena è necessario uno dei risultati, l'autobatcher invia la RPC batch. A differenza della maggior parte delle richieste, le query non vengono "raggruppate".
Quando viene eseguito un tasklet, il suo spazio dei nomi predefinito viene recuperato da quello che era il valore predefinito quando è stato generato il tasklet o da quello a cui è stato modificato durante l'esecuzione. In altre parole, lo spazio dei nomi predefinito non è associato o archiviato nel contesto e la modifica dello spazio dei nomi predefinito in un tasklet non influisce sullo spazio dei nomi predefinito in altri tasklet, ad eccezione di quelli generati.
Tasklet, query parallele, yield parallelo
Puoi utilizzare i tasklet in modo che più query recuperino i record contemporaneamente. Ad esempio, supponiamo che la tua applicazione abbia una pagina che mostra i contenuti di un carrello degli acquisti e un elenco di offerte speciali. Lo schema potrebbe avere il seguente aspetto:
Una funzione "sincrona" che recupera gli articoli del carrello e le offerte speciali potrebbe avere il seguente aspetto:
Questo esempio utilizza le query per recuperare elenchi di articoli del carrello e offerte, quindi
recupera i dettagli sugli articoli dell'inventario con get_multi().
(Questa funzione non utilizza
direttamente il valore restituito di get_multi(). Chiama
get_multi() per recuperare tutti i dettagli dell'inventario nella
cache in modo che possano essere letti rapidamente in un secondo momento. get_multi
combina molti Get in un'unica richiesta. ma i recuperi delle query avvengono uno dopo l'altro. Per fare in modo che i recuperi avvengano contemporaneamente, sovrapponi le due query:
La chiamata get_multi()
è ancora separata: dipende dai risultati della query, quindi
non puoi combinarla con le query.
Supponiamo che questa applicazione a volte abbia bisogno del carrello, a volte delle offerte e a volte di entrambi. Vuoi organizzare il codice in modo che ci sia una funzione per ottenere il carrello e una funzione per ottenere le offerte. Se la tua applicazione chiama queste funzioni insieme, idealmente le loro query potrebbero "sovrapporsi". Per farlo, trasforma queste funzioni in tasklet:
Questo yield x, y è importante,
ma facile da trascurare. Se fossero due istruzioni yield
separate, si verificherebbero in serie. Ma yield una tupla
di tasklet è un yield parallelo: le tasklet possono essere eseguite in parallelo
e yield attende che tutte terminino e restituisce
i risultati. In alcuni linguaggi di programmazione, questo è noto come
barriera.
Se trasformi un pezzo di codice in un tasklet, probabilmente vorrai
farne altri a breve. Se noti codice "sincrono" che potrebbe essere eseguito in parallelo
con un tasklet, probabilmente è una buona idea di trasformarlo in un tasklet.
Poi puoi parallelizzarlo con un yield parallelo.
Se scrivi una funzione di richiesta (una funzione di richiesta webapp2, una funzione di visualizzazione Django e così via) da utilizzare come tasklet, non otterrai il risultato desiderato: la funzione viene eseguita, ma poi si interrompe. In questa situazione, vuoi decorare la funzione con
@ndb.synctasklet.
@ndb.synctasklet è simile a @ndb.tasklet, ma
modificato per chiamare get_result() nel tasklet.
In questo modo la tasklet diventa una funzione
che restituisce il risultato nel solito modo.
Iteratori di query nei tasklet
Per scorrere i risultati della query in un tasklet, utilizza il seguente pattern:
Si tratta dell'equivalente compatibile con i tasklet di quanto segue:
Le tre righe in grassetto nella prima versione sono l'equivalente
compatibile con i tasklet della singola riga in grassetto nella seconda versione.
I tasklet possono essere sospesi solo con una parola chiave yield.
Il ciclo for senza yield non consente l'esecuzione di altri tasklet.
Ti starai chiedendo perché questo codice utilizza un iteratore di query anziché
recuperare tutte le entità utilizzando qry.fetch_async().
L'applicazione potrebbe avere così tante entità da non rientrare nella RAM.
Forse stai cercando un'entità e puoi interrompere l'iterazione una volta
trovata, ma non puoi esprimere i tuoi criteri di ricerca solo con il linguaggio
della query. Potresti utilizzare un iteratore per caricare le entità da controllare, quindi
uscire dal ciclo quando trovi ciò che ti serve.
Async Urlfetch con NDB
Un Context NDB ha una funzione
urlfetch() asincrona che viene parallelizzata in modo ottimale con i tasklet NDB, ad esempio:
Il servizio di recupero URL ha una propria API di richiesta asincrona. Va bene, ma non è sempre facile da usare con i tasklet NDB.
Utilizzo di transazioni asincrone
Le transazioni possono essere eseguite anche in modo asincrono. Puoi passare una funzione esistente
a ndb.transaction_async() o utilizzare il
decoratore @ndb.transactional_async.
Come le altre funzioni asincrone, questa restituirà un Future NDB:
Le transazioni funzionano anche con i tasklet. Ad esempio, potremmo modificare il nostro codice
update_counter in yield mentre attendiamo le RPC
di blocco:
Utilizzo di Future.wait_any()
A volte vuoi effettuare più richieste asincrone
e restituire il risultato quando la prima viene completata.
Puoi farlo utilizzando il metodo della classe ndb.Future.wait_any():
Purtroppo, non esiste un modo semplice per trasformarlo in un tasklet;
un yield parallelo attende il completamento di tutti i Future, inclusi quelli per cui non vuoi attendere.