리전 ID
REGION_ID는 앱을 만들 때 선택한 리전을 기준으로 Google에서 할당하는 축약된 코드입니다. 일부 리전 ID는 일반적으로 사용되는 국가 및 주/도 코드와 비슷하게 표시될 수 있지만 코드는 국가 또는 주/도와 일치하지 않습니다. 2020년 2월 이후에 생성된 앱의 경우 REGION_ID.r이 App Engine URL에 포함됩니다. 이 날짜 이전에 만든 기존 앱의 경우 URL에서 리전 ID는 선택사항입니다.
리전 ID에 대해 자세히 알아보세요.
소프트웨어를 개발할 때는 항상 절충점을 찾아야 하며, 마이크로서비스도 예외가 아닙니다. 코드 배포 및 운영 독립성을 얻기 위해서는 성능 오버헤드에서 대가를 치뤄야 합니다. 이 섹션에서는 이러한 영향을 최소화하는 단계에 대한 권장사항을 제공합니다.
CRUD 작업을 마이크로서비스로 전환
마이크로서비스는 CRUD(만들기, 검색, 업데이트, 삭제) 패턴으로 이용되는 항목에 특히 적합합니다. 이러한 항목을 작업할 때는 보통 항목을 한 번에 하나만 사용하며(예: 한 명의 사용자), CRUD 작업 역시 한 번에 하나만 수행합니다. 따라서 작업을 위해 마이크로서비스를 한 번만 호출하면 됩니다. CRUD 작업과 애플리케이션의 여러 부분에서 활용될 수 있는 비즈니스 방식이 포함된 항목들을 찾아보세요. 이러한 항목들이 마이크로서비스에 적합할 수 있습니다.
일괄 API 제공
CRUD 스타일의 API 외에도 일괄 API를 제공하여 항목 그룹에 뛰어난 마이크로서비스 성능을 제공할 수 있습니다. 예를 들어 단일 사용자를 검색하는 GET API 메소드만 사용하기 보다는 사용자 ID 집합을 가져와서 해당하는 사용자들로 이루어진 사전을 반환하는 API를 제공할 수 있습니다.
요청:
/user-service/v1/?userId=ABC123&userId=DEF456&userId=GHI789응답:
{
"ABC123": {
"userId": "ABC123",
"firstName": "Jake",
… },
"DEF456": {
"userId": "DEF456",
"firstName": "Sue",
… },
"GHI789": {
"userId": "GHI789",
"firstName": "Ted",
… }
}
App Engine SDK는 Cloud Datastore에서 단일 RPC를 통해 여러 항목을 가져오는 기능 등 여러 가지 일괄 API를 지원하므로, 이러한 유형의 일괄 API를 매우 효율적으로 사용할 수 있습니다.
비동기식 요청 사용
응답을 작성하기 위해서는 여러 마이크로서비스와의 상호작용이 필요한 경우가 종종 있습니다.
예를 들어 로그인한 사용자의 환경 설정과 회사 세부정보를 가져와야 할 수 있습니다. 주로 이러한 정보는 서로 종속되지 않으므로 병렬로 가져올 수 있습니다. App Engine SDK의 Urlfetch 라이브러리는 비동기식 요청을 지원하여 마이크로서비스를 병렬로 호출할 수 있게 해줍니다.
from google.appengine.api import urlfetch
preferences_rpc = urlfetch.create_rpc()
urlfetch.make_fetch_call(preferences_rpc,
'https://preferences-service-dot-my-app.uc.r.appspot.com/preferences-service/v1/?userId=ABC123')
company_rpc = urlfetch.create_rpc()
urlfetch.make_fetch_call(company_rpc,
'https://company-service-dot-my-app.uc.r.appspot.com/company-service/v3/?companyId=ACME')
### microservice requests are now occurring in parallel
try:
preferences_response = preferences_rpc.get_result() # blocks until response
if preferences_response.status_code == 200:
# deserialize JSON, or whatever is appropriate
else:
# handle error
except urlfetch.DownloadError:
# timeout, or other transient error
try:
company_response = company_rpc.get_result() # blocks until response
if company_response.status_code == 200:
# deserialize JSON, or whatever is appropriate
else:
# handle error
except urlfetch.DownloadError:
# timeout, or other transient error
병렬 작업 수행은 올바른 코드 구조에 배치될 수 있습니다. 실제 시나리오에서는 환경설정 메서드를 캡슐화하기 위해 하나의 클래스를 사용하고 회사 메서드를 캡슐화하기 위해 다른 클래스를 사용하는 경우가 많기 때문입니다. 이 캡슐화를 중단하지 않고는 비동기 Urlfetch 호출을 활용하기 어렵습니다. 올바른 해결 방법은 App Engine Python SDK의 NDB 패키지인 Tasklet에 있습니다.
Tasklet을 사용하면 병렬 마이크로서비스 호출을 달성하기 위한 메커니즘을 제공하면서도 코드에서 적합한 캡슐화를 유지할 수 있게 해줍니다. tasklet은 RPC 대신 future를 사용하지만, 아이디어는 비슷합니다.
최단 경로 사용
Urlfetch 호출 방법에 따라 다양한 인프라 및 경로를 사용할 수 있습니다. 최적의 경로를 사용하기 위해서는 다음 권장사항을 고려하는 것이 좋습니다.
- 커스텀 도메인이 아닌
REGION_ID.r.appspot.com사용 - 커스텀 도메인에서는 Google 인프라를 통해 라우팅할 때 다른 경로가 사용됩니다. 마이크로서비스는 내부에서 호출되므로
https://PROJECT_ID.REGION_ID.r.appspot.com을 사용하면 호출이 쉽고 성능이 개선될 수 있습니다. follow_redirects를False로 설정Urlfetch를 호출할 때follow_redirects=False를 명시적으로 설정합니다. 그러면 리디렉션을 수행하도록 설계된 복잡한 서비스를 피할 수 있습니다. API 엔드포인트는 사용자의 마이크로서비스이므로 클라이언트를 리디렉션할 필요가 없어야 하며 엔드포인트는 HTTP 200-, 400-, 500-시리즈 응답만 반환해야 합니다.- 여러 프로젝트보다 단일 프로젝트 내의 서비스 선호
- 마이크로서비스 기반 애플리케이션을 빌드할 때 여러 프로젝트를 사용해야 적합한 경우도 있지만 성능이 가장 중요하다면 단일 프로젝트 내의 서비스를 사용하는 것이 좋습니다. 프로젝트의 서비스는 동일한 데이터 센터에서 호스팅되며 Google의 데이터 센터 간 네트워크 처리량이 우수해도 로컬 호출이 속도는 더 빠릅니다.
보안 적용 중 과도한 통신 방지
호출 API 인증을 위해 많은 통신을 주고 받아야 하는 보안 메커니즘을 사용하면 성능이 저하됩니다. 예를 들어 애플리케이션의 티켓을 검증하기 위해 마이크로서비스에서 애플리케이션으로 다시 호출해야 하는 경우 데이터를 얻기 위해 여러 번의 왕복이 발생합니다.
OAuth2 구현 시 갱신 토큰을 사용하고 Urlfetch 호출 간에 액세스 토큰을 캐시하여 이러한 비용이 지속적으로 분할 상환됩니다. 하지만 캐시된 액세스 토큰이 Memcache에 저장된 경우, 이를 가져올 때 Memcache에서 오버헤드가 발생할 수밖에 없습니다. 이러한 오버헤드를 피하기 위해 액세스 토큰을 인스턴스 메모리에 캐시할 수 있지만, 새로운 인스턴스마다 액세스 토큰 협상이 수행되므로 OAuth2 작업이 자주 수행됩니다. App Engine 인스턴스는 작동과 중지가 빈번하게 발생합니다. Memcache와 인스턴스 캐시를 혼합해서 사용하면 이러한 문제를 완화하는 데 일부 도움이 될 수 있지만, 솔루션이 더 복잡해집니다.
이를 위한 또 다른 방법은 커스텀 HTTP 헤더로 전송되는 것과 같이 마이크로서비스 간의 보안 토큰을 공유하는 것입니다. 이 방법의 경우 각 마이크로서비스가 각 호출자에 대해 고유한 토큰을 가질 수 있습니다. 일반적으로 공유 비밀번호는 보안 구현을 위해 선택하기엔 문제가 있지만, 모든 마이크로서비스가 동일한 애플리케이션 내에 있으므로, 성능상의 이점을 고려하면 중요한 문제가 되지 않을 수 있습니다. 공유 비밀번호를 사용하면 마이크로서비스는 아마도 메모리 내에 있는 사전에 따라 새로 추가되는 보안 비밀의 문자열만 비교하면 되므로, 보안 적용을 매우 간단히 처리할 수 있습니다.
마이크로서비스가 모두 App Engine에 있다면 새로 추가되는 X-Appengine-Inbound-Appid 헤더를 검사할 수도 있습니다.
이 헤더는 다른 App Engine 프로젝트에 요청을 수행할 때 Urlfetch 인프라에서 추가되며, 외부 요소가 설정할 수 없습니다. 보안 요구사항에 따라 마이크로서비스가 새로 추가되는 헤더를 조사하여 보안 정책을 적용할 수도 있습니다.
마이크로서비스 요청 추적
마이크로서비스 기반 애플리케이션을 빌드하면 연속적인 Urlfetch 호출로 인해 오버헤드가 누적되기 시작합니다. 이 경우 Cloud Trace를 사용하여 수행 중인 호출 및 오버헤드 위치를 파악할 수 있습니다. 특히 Cloud Trace는 독립적인 마이크로서비스가 직렬로 호출되는 위치를 파악하는 데 유용하며 이를 통해 이러한 가져오기 작업이 동시에 수행되도록 코드를 리팩터링할 수 있습니다.
Cloud Trace의 유용성은 단일 프로젝트 내에서 여러 서비스를 사용할 때 나타납니다. 프로젝트에서 마이크로서비스 간에 호출이 수행될 때 Cloud Trace는 모든 호출을 단일 호출 그래프로 압축하여 전체 엔드 투 엔드 요청을 단일 추적으로 시각화할 수 있게 해줍니다.
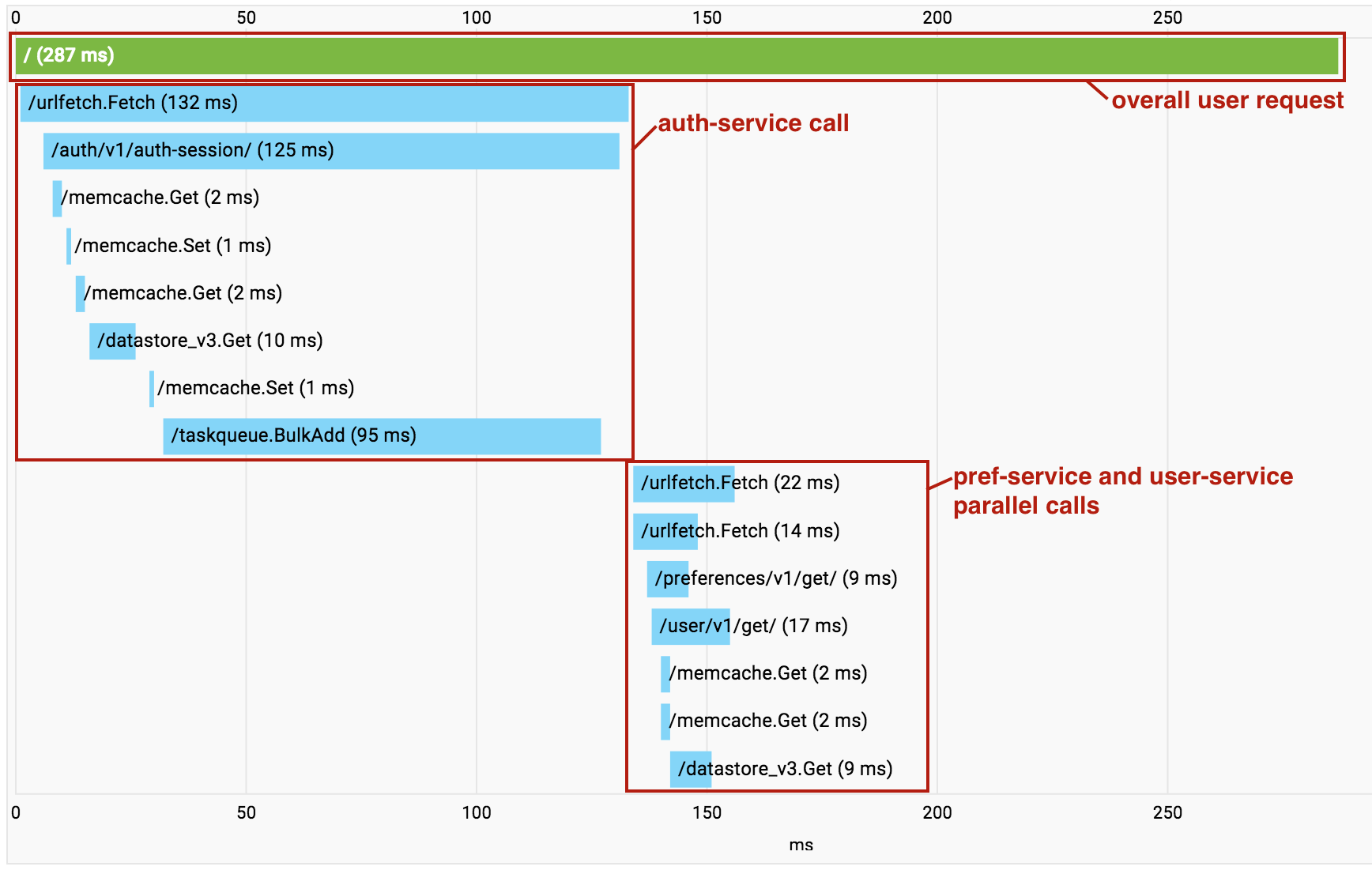
위의 예시에서 pref-service 및 user-service 호출은 비동기식 Urlfetch를 통해 동시에 수행되므로 그림에서 RPC가 섞여 있는 것처럼 보입니다.
하지만 여전히 지연 시간을 진단하기 위한 중요한 도구임은 변함이 없습니다.
다음 단계
- App Engine의 마이크로서비스 아키텍처 개요를 확인합니다.
- App Engine에서 마이크로 서비스를 사용하여 개발, 테스트, 품질보증, 스테이징, 프로덕션 환경을 만들고 이름을 지정하는 방법을 이해합니다.
- 마이크로 서비스 간 통신을 위한 API 설계 권장사항을 알아봅니다.
- 기존 모놀리식 애플리케이션을 마이크로서비스를 사용하는 애플리케이션으로 마이그레이션하는 방법을 알아봅니다.