ID da região
O REGION_ID é um código abreviado que o Google atribui
com base na região que você selecionou ao criar o aplicativo. O código não
corresponde a um país ou estado, ainda que alguns IDs de região sejam semelhantes
aos códigos de país e estado geralmente usados. Para apps criados após
fevereiro de 2020, o REGION_ID.r está incluído nos
URLs do App Engine. Para apps existentes criados antes dessa data, o
ID da região é opcional no URL.
Saiba mais sobre IDs de região.
O desenvolvimento de software gira em torno de compensações, e os microsserviços não são exceção. O que você ganha na implantação do código e na independência da operação é compensado pelas despesas gerais de desempenho. Nesta seção, são apresentadas algumas recomendações para as medidas a serem tomadas para minimizar esse impacto.
Transforme as operações do padrão CRUD em microsserviços
Os microsserviços são particularmente adequados para entidades que são acessadas com o padrão "criar, recuperar, atualizar, excluir" (CRUD, na sigla em inglês). Ao trabalhar com essas entidades, você normalmente usa apenas uma por vez, como um usuário, e executa apenas uma das ações CRUD da mesma maneira. Portanto, você só precisa de uma única chamada de microsserviço para a operação. Procure entidades que tenham operações CRUD mais um conjunto de métodos comerciais que possam ser utilizados em muitas partes do aplicativo. Essas entidades são bons candidatos a microsserviços.
Ofereça APIs em lote
Além das APIs de estilo CRUD, você ainda pode oferecer um bom desempenho de microsserviço para grupos de entidades por meio do fornecimento de APIs em lote. Por exemplo, em vez de apenas expor um método GET de API que recupera um único usuário, forneça uma API que toma um conjunto de códigos de usuários e retorna um dicionário de usuários correspondentes:
Solicitação:
/user-service/v1/?userId=ABC123&userId=DEF456&userId=GHI789Resposta:
{
"ABC123": {
"userId": "ABC123",
"firstName": "Jake",
… },
"DEF456": {
"userId": "DEF456",
"firstName": "Sue",
… },
"GHI789": {
"userId": "GHI789",
"firstName": "Ted",
… }
}
O SDK do App Engine é compatível com muitas APIs em lote, como a capacidade de buscar muitas entidades do Cloud Datastore por meio de uma única RPC, assim, a manutenção desses tipos de APIs em lote pode ser muito eficiente.
Use solicitações assíncronas
Muitas vezes, você precisará interagir com muitos microsserviços para compor uma resposta.
Por exemplo, talvez seja necessário buscar as preferências do usuário conectado, bem como os detalhes da empresa. Geralmente, essas informações não dependem umas das outras, e é possível buscá-las em paralelo. A biblioteca Urlfetch no
SDK do App Engine é compatível com solicitações assíncronas,
permitindo que você chame microsserviços em paralelo.
from google.appengine.api import urlfetch
preferences_rpc = urlfetch.create_rpc()
urlfetch.make_fetch_call(preferences_rpc,
'https://preferences-service-dot-my-app.uc.r.appspot.com/preferences-service/v1/?userId=ABC123')
company_rpc = urlfetch.create_rpc()
urlfetch.make_fetch_call(company_rpc,
'https://company-service-dot-my-app.uc.r.appspot.com/company-service/v3/?companyId=ACME')
### microservice requests are now occurring in parallel
try:
preferences_response = preferences_rpc.get_result() # blocks until response
if preferences_response.status_code == 200:
# deserialize JSON, or whatever is appropriate
else:
# handle error
except urlfetch.DownloadError:
# timeout, or other transient error
try:
company_response = company_rpc.get_result() # blocks until response
if company_response.status_code == 200:
# deserialize JSON, or whatever is appropriate
else:
# handle error
except urlfetch.DownloadError:
# timeout, or other transient error
Fazer o trabalho em paralelo normalmente vai contra uma boa estrutura de código porque, em um
cenário real, você costuma usar uma classe para encapsular os métodos de preferências e outra para encapsular métodos da empresa. É difícil aproveitar
chamadas Urlfetch assíncronas sem interromper esse encapsulamento. Uma boa
solução existe no pacote NDB do SDK do Python do App Engine:
Tasklets.
Eles permitem manter um bom encapsulamento no código ainda oferecendo um mecanismo para atingir chamadas de microsserviço paralelas. Os tasklets usam
futuros em vez de RPCs, mas a ideia é semelhante.
Use a rota mais curta
Dependendo de como você invoca Urlfetch, é possível causar o uso de diferentes infraestruturas e rotas. Para usar a rota de melhor desempenho, considere as seguintes recomendações:
- Use
REGION_ID.r.appspot.com, e não um domínio personalizado - Um domínio personalizado faz com que uma rota diferente seja usada ao rotear por meio da infraestrutura do Google. Como suas chamadas de microsserviço são internas, fica fácil e mais eficiente se você usar
https://PROJECT_ID.REGION_ID.r.appspot.com. - Defina
follow_redirectscomoFalse. - Defina
follow_redirects=Falseexplicitamente ao chamarUrlfetch, porque isso evita um serviço mais pesado projetado para seguir os redirecionamentos. Os endpoints da API não precisam redirecionar os clientes, porque eles são os seus próprios microsserviços, e endpoints só devem retornar as respostas HTTP das séries 200, 400 e 500. - Prefira serviços dentro de um projeto em vez de vários projetos
- Existem bons motivos para usar vários projetos ao criar um aplicativo com base em microsserviços, mas, se o desempenho é o objetivo principal, use serviços dentro de um único projeto. Os serviços de um projeto são hospedados no mesmo data center e, embora a capacidade na rede de data center do Google seja excelente, as chamadas locais são mais rápidas.
Evite o chatter durante a aplicação da segurança
Não é bom para o desempenho usar mecanismos de segurança que envolvam muita comunicação desnecessária para autenticar a API de chamada. Por exemplo, se o microsserviço precisar validar um tíquete do aplicativo por meio de outra chamada ao aplicativo, você terá feito muitas chamadas para conseguir os dados.
Uma implementação OAuth2 pode amortizar esse custo ao longo do tempo usando tokens de atualização e armazenando em cache um token de acesso entre invocações de Urlfetch. No entanto, se o token de acesso em cache for armazenado no Memcache, o Memcache será sobrecarregado para buscá-lo. Para evitar essa sobrecarga, é possível armazenar o token de acesso no cache da memória da instância. No entanto, você ainda verá a atividade do OAuth2 com frequência, uma vez que cada nova instância negocia um token de acesso. Lembre-se de que as instâncias do App Engine são adicionadas e encerradas constantemente. Um híbrido de cache de instância e Memcache ajudará a mitigar esse problema, mas a solução começa a ficar mais complexa.
Outra abordagem que funciona bem é compartilhar um token secreto entre microsserviços, por exemplo, transmitido como um cabeçalho HTTP personalizado. Nessa abordagem, cada microsserviço pode ter um token exclusivo para cada autor da chamada. Normalmente, os segredos compartilhados são uma opção questionável para implementações de segurança, mas, como todos os microsserviços estão no mesmo aplicativo, torna-se um problema menor por causa dos ganhos de desempenho. O secret compartilhado permite que o microsserviço realize uma comparação da string do secret recebido com um dicionário supostamente na memória. A aplicação da segurança é bastante leve.
Se todos os seus microsserviços estiverem no App Engine, também será possível inspecionar o
cabeçalho X-Appengine-Inbound-Appid
de entrada.
Esse cabeçalho é adicionado pela infraestrutura Urlfetch ao fazer uma solicitação para outro projeto do App Engine. Ele não pode ser definido por uma parte externa. Dependendo do requisito de segurança, os microsserviços podem inspecionar esse cabeçalho recebido para impor a política de segurança.
Acompanhe solicitações de microsserviços
À medida que você cria o aplicativo com base em microsserviços, começa a acumular
uma sobrecarga de chamadas sucessivas de Urlfetch. Quando isso acontece, é possível usar o Cloud Trace para entender quais chamadas estão sendo feitas e onde a sobrecarga está. O Cloud Trace também ajuda a identificar onde os microsserviços independentes estão sendo chamados em série, possibilitando refatorar o código para executar essas buscas em paralelo.
Um recurso útil do Cloud Trace é iniciado quando são usados vários serviços em um único projeto. À medida que as chamadas são feitas entre os serviços de microsserviço no projeto, o Cloud Trace recolhe todas as chamadas em um único gráfico de chamadas para permitir que você visualize toda a solicitação de ponta a ponta como um único rastreamento.
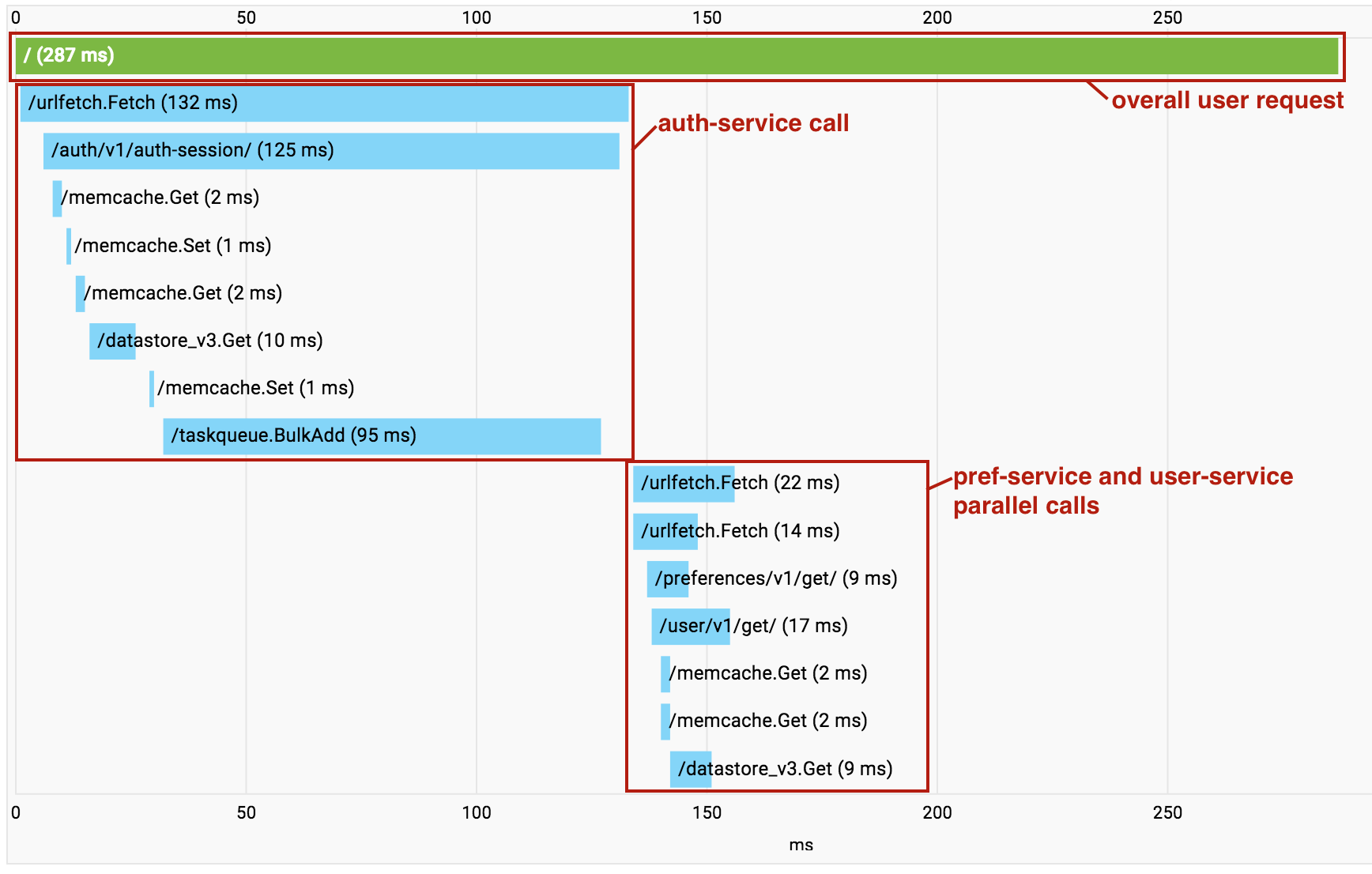
Observe que, no exemplo acima, as chamadas para o pref-service e o user-service são realizadas em paralelo usando um Urlfetch assíncrono, e assim os RPCs aparecem misturados na visualização.
No entanto, essa ainda é uma ferramenta valiosa para diagnosticar latência.
A seguir
- Veja um panorama da arquitetura de microsserviços no App Engine.
- Saiba como criar e nomear os ambientes de desenvolvimento, teste, controle de qualidade, preparação e produção com microsserviços no App Engine.
- Conheça as práticas recomendadas para projetar APIs para comunicação entre microsserviços.
- Aprenda a migrar de um aplicativo monolítico para um com microsserviços