Regions-ID
REGION_ID ist ein abgekürzter Code, den Google anhand der Region zuweist, die Sie beim Erstellen Ihrer Anwendung ausgewählt haben. Der Code bezieht sich nicht auf ein Land oder eine Provinz, auch wenn einige Regions-IDs häufig verwendeten Länder- und Provinzcodes ähneln können. Bei Anwendungen, die nach Februar 2020 erstellt wurden, ist REGION_ID.r in den App Engine-URLs enthalten. Bei Anwendungen, die vor diesem Datum erstellt wurden, ist die Regions-ID in der URL optional.
Bei der Softwareentwicklung geht es oft um Kompromisse. Mikrodienste sind da keine Ausnahme. Eine bessere Codebereitstellung und Betriebsunabhängigkeit gehen mit Leistungseinbußen einher. Dieser Abschnitt enthält einige Empfehlungen, wie Sie diese Auswirkungen minimieren können.
CRUD-Vorgänge in Mikrodienste umwandeln
Mikrodienste eignen sich besonders für Entitäten, auf die nach dem CRUD-Muster (Create (erstellen), Retrieve (abrufen), Update (aktualisieren), Delete (löschen)) zugegriffen wird. Wenn Sie mit solchen Entitäten arbeiten, verwenden Sie in der Regel jeweils immer nur eine Entität, z. B. einen Nutzer, und führen immer nur eine der CRUD-Aktionen aus. Daher benötigen Sie für den Vorgang nur einen Mikrodienstaufruf. Suchen Sie nach Entitäten mit CRUD-Vorgängen und einer Reihe von Geschäftsmethoden, die in vielen Teilen Ihrer Anwendung verwendet werden können. Diese Entitäten eignen sich gut für Mikrodienste.
Batch-APIs bereitstellen
Neben APIs für CRUD-Vorgänge können Sie leistungsfähige Mikrodienste für Gruppen von Entitäten erzielen, indem Sie Batch-APIs bereitstellen. Anstatt beispielsweise nur eine get-API-Methode zur Verfügung zu stellen, die einen einzelnen Nutzer abruft, können Sie eine API bereitstellen, die eine Gruppe von Nutzer-IDs erfasst und ein Wörterbuch mit entsprechenden Nutzern zurückgibt:
Anfrage
/user-service/v1/?userId=ABC123&userId=DEF456&userId=GHI789Antwort
{
"ABC123": {
"userId": "ABC123",
"firstName": "Jake",
… },
"DEF456": {
"userId": "DEF456",
"firstName": "Sue",
… },
"GHI789": {
"userId": "GHI789",
"firstName": "Ted",
… }
}
Das App Engine SDK unterstützt viele Batch-APIs, z. B. die Möglichkeit, viele Entitäten aus Cloud Datastore über einen einzelnen RPC abzurufen, sodass die Verarbeitung dieser Arten von Batch-APIs sehr effizient sein kann.
Asynchrone Anfragen verwenden
Oft müssen Sie mit vielen Mikrodiensten interagieren, um eine Antwort zu erstellen.
Es kann möglicherweise erforderlich sein, die Einstellungen des angemeldeten Nutzers sowie Unternehmensdetails abzurufen. Häufig hängen diese Informationen nicht voneinander ab und können parallel abgerufen werden. Die Bibliothek Urlfetch im App Engine SDK unterstützt asynchrone Anfragen, sodass Sie Mikrodienste parallel aufrufen können.
from google.appengine.api import urlfetch
preferences_rpc = urlfetch.create_rpc()
urlfetch.make_fetch_call(preferences_rpc,
'https://preferences-service-dot-my-app.uc.r.appspot.com/preferences-service/v1/?userId=ABC123')
company_rpc = urlfetch.create_rpc()
urlfetch.make_fetch_call(company_rpc,
'https://company-service-dot-my-app.uc.r.appspot.com/company-service/v3/?companyId=ACME')
### microservice requests are now occurring in parallel
try:
preferences_response = preferences_rpc.get_result() # blocks until response
if preferences_response.status_code == 200:
# deserialize JSON, or whatever is appropriate
else:
# handle error
except urlfetch.DownloadError:
# timeout, or other transient error
try:
company_response = company_rpc.get_result() # blocks until response
if company_response.status_code == 200:
# deserialize JSON, or whatever is appropriate
else:
# handle error
except urlfetch.DownloadError:
# timeout, or other transient error
Parallele Vorgänge widersprechen oft einer guten Codestruktur, da Sie in einem realen Szenario häufig eine Klasse verwenden, um Verfahrensweisen für Einstellungen zu kapseln, und eine andere Klasse, um Unternehmensmethoden zu kapseln. Es ist schwierig, asynchrone Urlfetch-Aufrufe zu nutzen, ohne diese Kapselung zu unterbrechen. Das NDB-Paket des App Engine Python SDK enthält eine gute Lösung: Tasklets.
Tasklets ermöglichen eine gute Kapselung in Ihrem Code und bieten gleichzeitig einen Mechanismus für parallele Microdienstaufrufe. Tasklets verwenden Futures anstelle von RPCs, aber die Idee ist ähnlich.
Die kürzeste Route verwenden
Je nachdem, wie Sie Urlfetch aufrufen, können unterschiedliche Infrastrukturen und Routen verwendet werden. Beachten Sie die folgenden Empfehlungen, um die Route mit der jeweils besten Leistung zu wählen:
- Verwenden Sie
REGION_ID.r.appspot.comund keine benutzerdefinierte Domain. - Eine benutzerdefinierte Domain bewirkt, dass beim Routing durch die Infrastruktur von Google eine andere Route verwendet wird. Da Sie die Mikrodienste intern aufrufen, ist es einfacher und effizienter, wenn Sie
https://PROJECT_ID.REGION_ID.r.appspot.comverwenden. - Setzen Sie
follow_redirectsaufFalse. - Stellen Sie explizit
follow_redirects=Falseein, wenn SieUrlfetchaufrufen. Dies vermeidet die Nutzung eines komplexeren Dienstes, der in der Lage ist, Weiterleitungen zu folgen. Ihre API-Endpunkte sollten die Clients nicht umleiten müssen, da es sich um Ihre eigenen Mikrodienste handelt. Endpunkte sollten außerdem nur Antworten der HTTP-Serien 200, 400 und 500 zurückgeben. - Ziehen Sie Dienste vor, die nur innerhalb eines Projekts und nicht projektübergreifend genutzt werden.
- Es gibt gute Gründe, mehrere Projekte beim Erstellen einer auf Mikrodiensten basierenden Anwendung zu verwenden. Falls jedoch Leistung Ihr primäres Ziel ist, sollten Sie Dienste in einem einzelnen Projekt verwenden. Die Dienste eines Projekts werden im selben Rechenzentrum gehostet und lokale Aufrufe sind schneller, obwohl der Durchsatz im Rechenzentren-übergreifenden Netzwerk von Google hervorragend ist.
Überflüssige Kommunikation während der Sicherheitsdurchsetzung vermeiden
Die Leistung wird beeinträchtigt, wenn Sie Sicherheitsmechanismen verwenden, die viel Kommunikation in beide Richtungen auslösen, um die aufrufende API zu authentifizieren. Wenn der Mikrodienst beispielsweise ein Ticket von Ihrer Anwendung validieren muss, indem er einen Rückruf zur Anwendung durchführt, gelangen die Daten über erhebliche Umwege zu Ihnen.
Eine OAuth2-Implementierung kann diese Kosten im Laufe der Zeit ausgleichen, indem sie Aktualisierungstokens verwendet und zwischen Urlfetch-Aufrufen ein Zugriffstoken im Cache speichert. Wenn das Zugriffstoken jedoch in Memcache zwischengespeichert wird, entsteht für dessen Abruf ein Leistungsmehraufwand in Memcache. Wenn Sie dies vermeiden möchten, können Sie das Zugriffstoken im Instanzspeicher zwischenspeichern. Dennoch wird es weiterhin viel OAuth2-Aktivität geben, da jede neue Instanz ein Zugriffstoken aushandelt. Beachten Sie, dass App Engine-Instanzen häufig hoch- und heruntergefahren werden. Dieses Problem kann durch eine Kombination aus Memcache und Instanzcache behoben werden, Ihre Lösung wird jedoch komplexer.
Eine weitere, gut funktionierende Methode ist die gemeinsame Nutzung eines geheimen Tokens durch Mikrodienste, das beispielsweise als benutzerdefinierter HTTP-Header übertragen wird. Bei dieser Methode kann jeder Mikrodienst ein eindeutiges Token für jeden Aufrufer haben. Gemeinsame Secrets sind in der Regel ungeeignet für Sicherheitsimplementierungen. Da sich alle Mikrodienste jedoch in derselben Anwendung befinden, ist dies angesichts der Leistungssteigerungen weniger problematisch. Mit einem gemeinsamen Secret muss der Mikrodienst nur einen Stringvergleich des eingehenden Secrets mit einem vermutlich im Speicher befindlichen Wörterbuch vornehmen und die Sicherheitsdurchsetzung hat eine geringe Gewichtung.
Befinden sich Ihre gesamten Mikrodienste in App Engine, können Sie auch den eingehenden Header X-Appengine-Inbound-Appid prüfen.
Dieser Header wird von der Urlfetch-Infrastruktur hinzugefügt, wenn eine Anfrage an ein anderes App Engine-Projekt gesendet wird, und kann nicht von externen Nutzern festgelegt werden. Je nach den Sicherheitsanforderungen können Ihre Mikrodienste diesen eingehenden Header überprüfen, um Ihre Sicherheitsrichtlinie durchzusetzen.
Mikrodienstanfragen verfolgen
Bei der Erstellung einer auf Mikrodiensten basierten Anwendung steigt mit aufeinanderfolgenden Urlfetch-Aufrufen der Leistungsaufwand. In diesem Fall können Sie mit Cloud Trace ermitteln, welche Aufrufe erfolgen und wo der Leistungsaufwand anfällt. Vor allem können Sie mit Cloud Trace auch ermitteln, wo unabhängige Mikrodienste nacheinander aufgerufen werden, sodass Sie Ihren Code so umgestalten können, dass diese Abrufe parallel ausgeführt werden.
Wenn Sie mehrere Dienste in einem einzelnen Projekt verwenden, bietet Cloud Trace eine weitere hilfreiche Funktion. Wenn Aufrufe zwischen Mikrodiensten in Ihrem Projekt erfolgen, fasst Cloud Trace diese in einer einzigen Aufrufgrafik zusammen, sodass Sie die gesamte End-to-End-Anfrage als einheitlichen Trace verfolgen können.
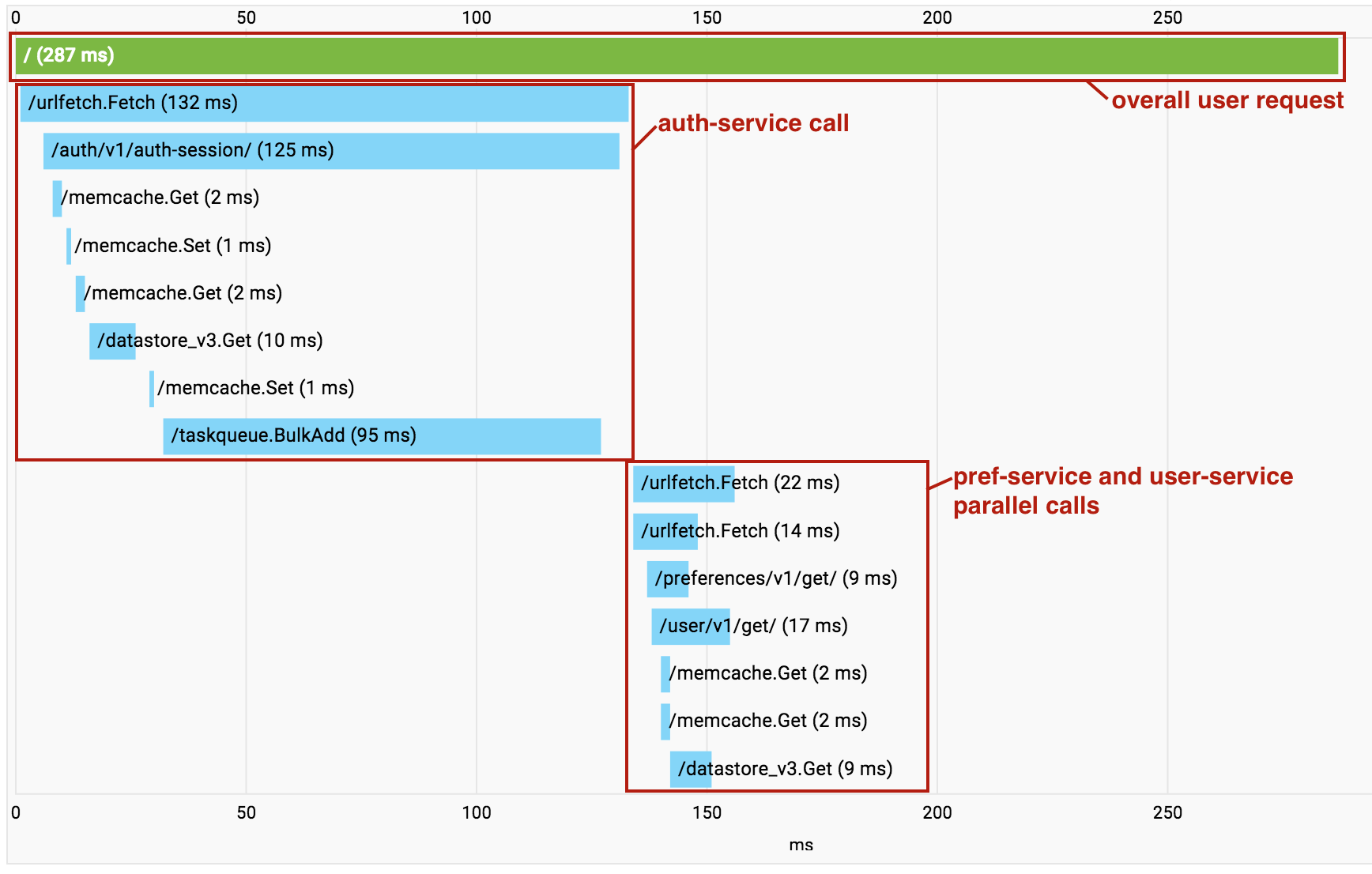
Im obigen Beispiel erfolgen die Aufrufe an den pref-service und den user-service mit einem asynchronen Urlfetch parallel, sodass die RPCs in der Visualisierung nicht deutlich werden.
Dennoch ist dies ein wertvolles Werkzeug zum Diagnostizieren der Latenz.
Weitere Informationen
- Überblick über die Microservice-Architektur in App Engine
- Mit Mikrodiensten in App Engine Entwicklungs-, Test-, QA-, Staging- und Produktionsumgebungen erstellen und benennen
- Best Practices für den Entwurf von APIs zur Kommunikation zwischen Mikrodiensten
- Von einer monolithischen Anwendung auf Mikrodienste migrieren