이 문서에서는 VMware용 Google Distributed Cloud(소프트웨어 전용)에서 시스템 구성요소에 대한 로깅 및 모니터링을 구성하는 방법을 보여줍니다.
기본적으로 Cloud Logging, Cloud Monitoring, Google Cloud Managed Service for Prometheus가 사용 설정되어 있습니다.
옵션에 대한 자세한 내용은 로깅 및 모니터링 개요를 참조하세요.
모니터링 리소스
모니터링 리소스는 Google이 클러스터, 노드, 포드, 컨테이너와 같은 리소스를 나타내는 방식입니다. 자세한 내용은 Cloud Monitoring의 모니터링 리소스 유형 문서를 참조하세요.
로그와 측정항목을 쿼리하려면 최소한 다음 리소스 라벨을 알아야 합니다.
project_id: 클러스터 로깅-모니터링 프로젝트의 프로젝트 ID입니다. 이 값은 클러스터 구성 파일의stackdriver.projectID필드에 제공했습니다.location: Cloud Logging 로그와 Cloud Monitoring 측정항목을 저장할 Google Cloud 리전입니다. 온프레미스 데이터센터 근처에 있는 리전을 선택하는 것이 좋습니다. 설치 중에 클러스터 구성 파일의stackdriver.clusterLocation필드에 이 값을 제공했습니다.cluster_name: 클러스터를 만들 때 선택한 클러스터 이름Stackdriver 커스텀 리소스를 검사하여 관리자 클러스터나 사용자 클러스터의
cluster_name값을 검색할 수 있습니다.kubectl get stackdriver stackdriver --namespace kube-system \ --kubeconfig CLUSTER_KUBECONFIG --output yaml | grep 'clusterName:'
각 항목의 의미는 다음과 같습니다.
CLUSTER_KUBECONFIG는 클러스터 이름이 필요한 관리자 클러스터 또는 사용자 클러스터의 kubeconfig 파일 경로입니다.
Cloud Logging 사용
클러스터에 Cloud Logging을 사용 설정하기 위해 별도의 조치를 취할 필요가 없습니다.
그러나 로그를 보려는 Google Cloud 프로젝트를 지정해야 합니다. 클러스터 구성 파일의 stackdriver 섹션에서 Google Cloud 프로젝트를 지정합니다.
Google Cloud 콘솔의 로그 탐색기를 사용하여 로그에 액세스할 수 있습니다. 예를 들어 컨테이너의 로그에 액세스하려면 다음 안내를 따르세요.
- Google Cloud 콘솔에서 프로젝트의 로그 탐색기를 엽니다.
- 컨테이너 로그를 찾는 방법은 다음과 같습니다.
- 왼쪽 상단의 로그 카탈로그 드롭다운 메뉴를 클릭하고 Kubernetes 컨테이너를 선택합니다.
- 계층 구조에서 클러스터 이름, 네임스페이스, 컨테이너를 차례대로 선택합니다.
부트스트랩 클러스터의 컨트롤러에 대한 로그 보기
onprem-admin-cluster-controller/clusterapi-controllers 포드 이름 찾기
기본적으로 kind 클러스터 이름은
gkectl-bootstrap-cluster입니다."ADMIN_CLUSTER_NAME" resource.type="k8s_container" resource.labels.cluster_name="gkectl-bootstrap-cluster"
찾은 포드 이름을 사용하여 쿼리를 수정하고 로그를 가져옵니다.
resource.type="k8s_container" resource.labels.cluster_name="gkectl-bootstrap-cluster" resource.labels.pod_name="POD_NAME"
Cloud Monitoring 사용
클러스터에 Cloud Monitoring을 사용 설정하기 위해 별도의 조치를 취할 필요는 없습니다.
그러나 측정항목을 보려는 Google Cloud 프로젝트를 지정해야 합니다.
클러스터 구성 파일의 stackdriver 섹션에서 Google Cloud 프로젝트를 지정합니다.
측정항목 탐색기를 사용하여 1,500개가 넘는 측정항목 중에서 선택할 수 있습니다. 측정항목 탐색기에 액세스하려면 다음을 수행합니다.
Google Cloud 콘솔에서 Monitoring을 선택하거나 다음 버튼을 사용합니다.
리소스 > 측정항목 탐색기를 선택합니다.
Google Cloud 콘솔의 대시보드에서 측정항목을 볼 수도 있습니다. 대시보드 만들기 및 측정항목 보기에 대한 자세한 내용은 대시보드 만들기를 참조하세요.
Fleet 수준 모니터링 데이터 보기
Google Distributed Cloud 클러스터를 포함한 Cloud Monitoring 데이터를 사용하는 Fleet의 리소스 사용률을 전반적으로 확인하려면 Google Cloud 콘솔에서 Google Kubernetes Engine 개요를 사용하면 됩니다. 자세한 내용은 Google Cloud 콘솔에서 클러스터 관리를 참고하세요.
기본 Cloud Monitoring 할당량 한도
Google Distributed Cloud 모니터링의 기본 API 호출 한도는 프로젝트별로 분당 6,000회입니다. 이 한도를 초과하면 측정항목이 표시되지 않을 수 있습니다. 모니터링 한도를 늘려야 하면 Google Cloud 콘솔을 통해 요청합니다.
Managed Service for Prometheus 사용
Google Cloud Managed Service for Prometheus는 Cloud Monitoring의 일부이며 기본적으로 사용할 수 있습니다. Managed Service for Prometheus의 이점은 다음과 같습니다.
알림 및 Grafana 대시보드를 변경하지 않고도 기존 Prometheus 기반 모니터링을 계속 사용할 수 있습니다.
GKE와 Google Distributed Cloud를 모두 사용하는 경우 모든 클러스터의 측정항목에 같은 PromQL을 사용할 수 있습니다. Google Cloud 콘솔의 측정항목 탐색기에 있는 PROMQL 탭을 사용할 수도 있습니다.
Managed Service for Prometheus 사용 설정 및 중지
Managed Service for Prometheus는 Google Distributed Cloud에서 기본적으로 사용 설정됩니다.
클러스터에서 Managed Service for Prometheus를 사용 중지하려면 다음 안내를 따르세요.
stackdriver라는 수정할 Stackdriver 객체를 엽니다.kubectl --kubeconfig CLUSTER_KUBECONFIG --namespace kube-system \ edit stackdriver stackdriverenableGMPForSystemMetrics기능 게이트를 추가하고false로 설정합니다.apiVersion: addons.gke.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: featureGates: enableGMPForSystemMetrics: false수정 세션을 닫습니다.
측정항목 데이터 보기
Managed Service for Prometheus가 사용 설정되면 다음 구성요소의 측정항목 형식이 Cloud Monitoring에서 저장 및 쿼리되는 방법과 다릅니다.
- kube-apiserver
- kube-scheduler
- kube-controller-manager
- kubelet 및 cadvisor
- kube-state-metrics
- node-exporter
새 형식에서는 PromQL 또는 Monitoring 쿼리 언어(MQL)를 사용하여 이전 측정항목을 쿼리할 수 있습니다.
다음은 PromQL 예시입니다.
histogram_quantile(0.95, sum(rate(apiserver_request_duration_seconds_bucket[5m])) by (le))
MQL을 사용하려면 모니터링 리소스를 prometheus_target으로 설정하고 Prometheus 유형을 측정항목에 서픽스로 추가합니다.
다음은 MQL 예시입니다.
fetch prometheus_target | metric 'kubernetes.io/anthos/apiserver_request_duration_seconds/histogram' | align delta(5m) | every 5m | group_by [], [value_histogram_percentile: percentile(value.histogram, 95)]
Managed Service for Prometheus로 Grafana 대시보드 구성
Managed Service for Prometheus의 측정항목 데이터와 함께 Grafana를 사용하려면 Grafana를 사용하여 쿼리의 단계를 수행하여 Managed Service for Prometheus의 데이터를 쿼리하도록 Grafana 데이터 소스를 인증하고 구성합니다.
샘플 Grafana 대시보드 집합은 GitHub의 anthos-samples 저장소에서 제공됩니다. 샘플 대시보드를 설치하려면 다음을 수행합니다.
샘플
.json파일을 다운로드합니다.git clone https://github.com/GoogleCloudPlatform/anthos-samples.git cd anthos-samples/gmp-grafana-dashboards
Grafana 데이터 소스가
Managed Service for Prometheus와 다른 이름으로 생성된 경우 모든.json파일에서datasource필드를 변경합니다.sed -i "s/Managed Service for Prometheus/[DATASOURCE_NAME]/g" ./*.json
[DATASOURCE_NAME]을 Prometheus
frontend서비스를 가리키는 Grafana의 데이터 소스 이름으로 바꿉니다.브라우저에서 Grafana UI에 액세스하고 대시보드 메뉴에서 + 가져오기를 선택합니다.
.json파일을 업로드하거나 파일 콘텐츠를 복사하여 붙여넣고 로드를 선택합니다. 파일 콘텐츠가 성공적으로 로드되면 가져오기를 선택합니다. 가져오기 전에 대시보드 이름과 UID를 변경할 수도 있습니다(선택사항).
Google Distributed Cloud 및 데이터 소스가 올바르게 구성되면 가져온 대시보드가 성공적으로 로드됩니다. 예를 들어 다음 스크린샷에서는
cluster-capacity.json으로 구성된 대시보드를 보여줍니다.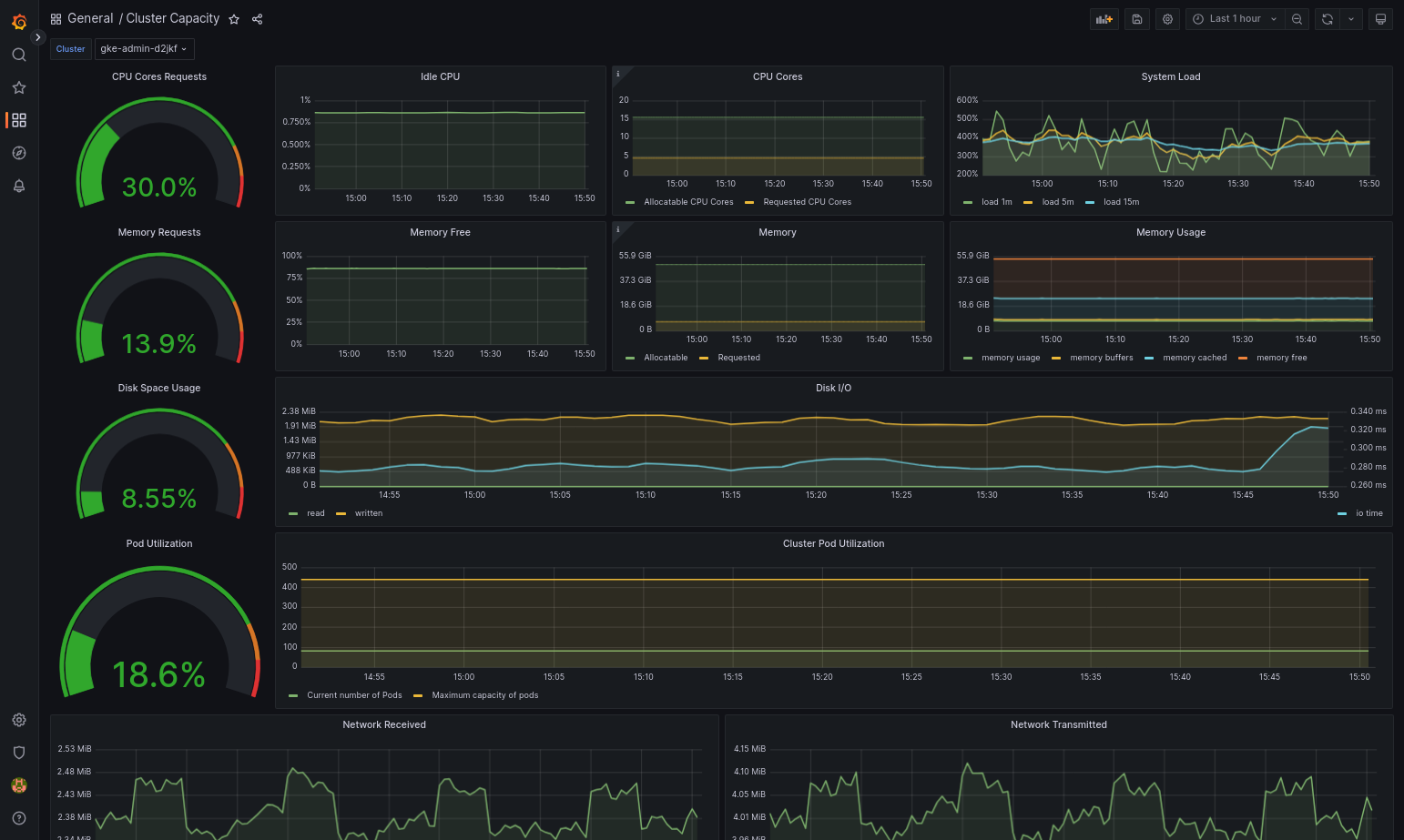
추가 리소스
Managed Service for Prometheus에 대한 자세한 내용은 다음을 참조하세요.
Prometheus 및 Grafana 사용
버전 1.16부터 새로 만들어진 클러스터에서 Prometheus 및 Grafana를 사용할 수 없습니다. 클러스터 내 모니터링의 대안으로 Managed Service for Prometheus를 사용하는 것이 좋습니다.
Prometheus와 Grafana가 사용 설정된 1.15 클러스터를 1.16으로 업그레이드하면 Prometheus와 Grafana는 계속해서 그대로 작동하지만 업데이트되거나 보안 패치가 제공되지는 않습니다.
1.16으로 업그레이드한 후 모든 Prometheus 및 Grafana 리소스를 삭제하려면 다음 명령어를 실행하세요.
kubectl --kubeconfig KUBECONFIG delete -n kube-system \
statefulsets,services,configmaps,secrets,serviceaccounts,clusterroles,clusterrolebindings,certificates,deployments \
-l addons.gke.io/legacy-pg=true
이전 버전의 Google Distributed Cloud에 포함된 Prometheus 및 Grafana 구성요소를 사용하는 대신 Prometheus 및 Grafana의 오픈소스 커뮤니티 버전으로 전환할 수 있습니다.
알려진 문제
사용자 클러스터에서는 업그레이드 중에 Prometheus와 Grafana의 사용이 자동으로 중지됩니다. 하지만 구성과 측정항목 데이터는 손실되지 않습니다.
이 문제를 해결하려면 업그레이드 후 수정할 monitoring-sample을 열고 enablePrometheus를 true로 설정합니다.
Grafana 대시보드에서 모니터링 측정항목에 액세스
Grafana는 클러스터에서 수집한 측정항목을 표시합니다. 이러한 측정항목을 보려면 Grafana 대시보드에 액세스해야 합니다.
사용자 클러스터의
kube-system네임스페이스에서 실행 중인 Grafana 포드의 이름을 가져옵니다.kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] -n kube-system get pods
여기서 [USER_CLUSTER_KUBECONFIG]는 사용자 클러스터의 kubeconfig 파일입니다.
Grafana 포드는 TCP localhost 포트 3000에서 리슨하는 HTTP 서버를 갖습니다. 포드에서 로컬 포트를 포트 3000에 전달하면 웹브라우저에서 Grafana 대시보드를 볼 수 있습니다.
예를 들어 포드 이름이
grafana-0이라고 가정합니다. 포드에서 포트 50000을 포트 3000에 전달하려면 다음 명령어를 입력합니다.kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] -n kube-system port-forward grafana-0 50000:3000
웹브라우저에서
http://localhost:50000으로 이동합니다.로그인 페이지에서 사용자 이름 및 비밀번호에
admin을 입력합니다.로그인이 성공하면 비밀번호를 변경하라는 메시지가 표시됩니다. 기본 비밀번호를 변경하면 사용자 클러스터의 Grafana 홈 대시보드가 로드됩니다.
다른 대시보드에 액세스하려면 페이지 왼쪽 상단에 있는 홈 드롭다운 메뉴를 클릭합니다.
Grafana 사용 예시는 Grafana 대시보드 만들기를 참조하세요.
알림에 액세스
Prometheus Alertmanager는 Prometheus 서버에서 알림을 수집합니다. Grafana 대시보드에서 이러한 알림을 볼 수 있습니다. 알림을 보려면 대시보드에 액세스해야 합니다.
alertmanager-0포드의 컨테이너는 TCP 포트 9093에서 리슨합니다. 포드에서 로컬 포트를 포트 9093에 전달합니다.kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] port-forward \ -n kube-system alertmanager-0 50001:9093
웹브라우저에서
http://localhost:50001으로 이동합니다.
Prometheus Alertmanager 구성 변경
사용자 클러스터의 monitoring.yaml 파일을 수정하여 Prometheus Alertmanager의 기본 구성을 변경할 수 있습니다. 대시보드에 알림을 유지하는 대신 특정 대상에 알림을 보내려면 이 작업을 수행해야 합니다. Alertmanager를 구성하는 방법은 Prometheus의 구성 문서를 참조하세요.
Alertmanager 구성을 변경하려면 다음 단계를 수행합니다.
사용자 클러스터의
monitoring.yaml매니페스트 파일 복사본을 만듭니다.kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] -n kube-system \ get monitoring monitoring-sample -o yaml > monitoring.yaml
Alertmanager를 구성하려면
spec.alertmanager.yml아래의 필드를 변경합니다. 완료되면 변경된 매니페스트를 저장합니다.매니페스트를 클러스터에 적용합니다.
kubectl apply --kubeconfig [USER_CLUSTER_KUBECONIFG] -f monitoring.yaml
Grafana 대시보드 만들기
측정항목을 노출하는 애플리케이션을 배포했고, 측정항목이 노출되었음을 확인했으며, Prometheus가 측정항목을 스크랩했음을 확인했습니다. 이제 애플리케이션 수준 측정항목을 커스텀 Grafana 대시보드에 추가할 수 있습니다.
Grafana 대시보드를 만들려면 다음 단계를 수행합니다.
- 필요한 경우 Grafana에 액세스합니다.
- 홈 대시보드에서 페이지 왼쪽 상단에 있는 Home(홈) 드롭다운 메뉴를 클릭합니다.
- 오른쪽 메뉴에서 New dashboard(새 대시보드)를 클릭합니다.
- New panel(새 패널) 섹션에서 Graph(그래프)를 클릭합니다. 빈 그래프 대시보드가 표시됩니다.
- Panel title(패널 제목)을 클릭한 후 Edit(수정)를 클릭합니다. 하단의 Graph(그래프) 패널이 Metrics(측정항목) 탭으로 열립니다.
- Data Source(데이터 소스) 드롭다운 메뉴에서 user(사용자)를 선택합니다. Add query(쿼리 추가)를 클릭하고 search(검색) 필드에
foo를 입력합니다. - 화면 오른쪽 상단에 있는 Back to dashboard(대시보드로 돌아가기) 버튼을 클릭합니다. 대시보드가 표시됩니다.
- 대시보드를 저장하려면 화면 오른쪽 상단에 있는 Save dashboard(대시보드 저장)를 클릭합니다. 대시보드의 이름을 선택한 후 Save(저장)를 클릭합니다.
Prometheus 및 Grafana 사용 중지
버전 1.16부터 Prometheus와 Grafana는 더 이상 monitoring-sample 객체의 enablePrometheus 필드로 제어되지 않습니다.
자세한 내용은 Prometheus 및 Grafana 사용을 참조하세요.
예시: Grafana 대시보드에 애플리케이션 수준 측정항목 추가
다음 섹션에서는 애플리케이션의 측정항목을 추가하는 과정을 설명합니다. 이 섹션에서는 다음 태스크를 완료합니다.
foo라는 측정항목을 노출하는 애플리케이션 예시를 배포합니다.- Prometheus가 측정항목을 노출하고 스크래핑하는지 확인합니다.
- 커스텀 Grafana 대시보드를 만듭니다.
예시 애플리케이션 배포
예시 애플리케이션은 단일 포드에서 실행됩니다. 포드의 컨테이너는 측정항목인 foo를 노출하며 상수 값은 40입니다.
다음 포드 매니페스트 pro-pod.yaml을 만듭니다.
apiVersion: v1
kind: Pod
metadata:
name: prometheus-example
annotations:
prometheus.io/scrape: 'true'
prometheus.io/port: '8080'
prometheus.io/path: '/metrics'
spec:
containers:
- image: registry.k8s.io/prometheus-dummy-exporter:v0.1.0
name: prometheus-example
command:
- /bin/sh
- -c
- ./prometheus_dummy_exporter --metric-name=foo --metric-value=40 --port=8080
그런 다음 포드 매니페스트를 사용자 클러스터에 적용합니다.
kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] apply -f pro-pod.yaml
측정항목이 노출되고 스크레이핑되었는지 확인
prometheus-example포드의 컨테이너는 TCP 포트 8080에서 리슨합니다. 포드에서 로컬 포트를 포트 8080에 전달합니다.kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] port-forward prometheus-example 50002:8080
애플리케이션이 측정항목을 노출하는지 확인하려면 다음 명령어를 실행합니다.
curl localhost:50002/metrics | grep foo이 명령어는 다음 출력을 반환합니다.
# HELP foo Custom metric # TYPE foo gauge foo 40
prometheus-0포드의 컨테이너는 TCP 포트 9090에서 리슨합니다. 포드에서 로컬 포트를 포트 9090에 전달합니다.kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] port-forward prometheus-0 50003:9090
Prometheus가 측정항목을 스크래핑하고 있는지 확인하려면 http://localhost:50003/targets으로 이동합니다. 그러면
prometheus-io-pods대상 그룹의prometheus-0포드로 이동할 수 있습니다.Prometheus에서 측정항목을 보려면 http://localhost:50003/graph로 이동합니다. search(검색) 필드에서
foo를 입력한 후 Execute(실행)를 클릭합니다. 페이지에 측정항목이 표시됩니다.
Stackdriver 커스텀 리소스 구성
클러스터를 만들면 Google Distributed Cloud에서 Stackdriver 커스텀 리소스를 자동으로 만듭니다. Stacktdriver 구성요소에 대한 CPU 및 메모리 요청과 한도의 기본값을 재정의하도록 커스텀 리소스의 사양을 수정할 수 있습니다. 그리고 기본 스토리지 크기와 스토리지 클래스를 개별적으로 재정의할 수 있습니다.
CPU 및 메모리에 대한 요청 및 제한의 기본값 재정의
이러한 기본값을 재정의하려면 다음을 수행합니다.
명령줄 편집기에서 Stackdriver 커스텀 리소스를 엽니다.
kubectl --kubeconfig=KUBECONFIG -n kube-system edit stackdriver stackdriver
여기서 KUBECONFIG는 클러스터의 kubeconfig 파일 경로입니다. 관리자 클러스터 또는 사용자 클러스터일 수 있습니다.
Stackdriver 커스텀 리소스의
resourceAttrOverride섹션에spec섹션을 추가합니다.resourceAttrOverride: POD_NAME_WITHOUT_RANDOM_SUFFIX/CONTAINER_NAME: LIMITS_OR_REQUESTS: RESOURCE: RESOURCE_QUANTITYresourceAttrOverride필드는 지정한 구성요소의 모든 기존 기본 한도와 요청을 재정의합니다.resourceAttrOverride에서 지원하는 구성요소는 다음과 같습니다.- gke-metrics-agent/gke-metrics-agent
- stackdriver-log-forwarder/stackdriver-log-forwarder
- stackdriver-metadata-agent-cluster-level/metadata-agent
- node-exporter/node-exporter
- kube-state-metrics/kube-state-metrics
예시 파일은 다음과 같습니다.
apiVersion: addons.gke.io/v1alpha1
kind: Stackdriver
metadata:
name: stackdriver
namespace: kube-system
spec:
projectID: my-project
clusterName: my-cluster
clusterLocation: us-west-1a
resourceAttrOverride:
gke-metrics-agent/gke-metrics-agent:
requests:
cpu: 110m
memory: 240Mi
limits:
cpu: 200m
memory: 4.5Gi변경사항을 저장하고 명령줄 편집기를 종료합니다.
포드 상태를 확인합니다.
kubectl --kubeconfig=KUBECONFIG -n kube-system get pods | grep gke-metrics-agent
예를 들어 정상 상태의 포드는 다음과 같습니다.
gke-metrics-agent-4th8r 1/1 Running 0 5d19h
구성요소의 포드 사양을 확인하여 리소스가 올바르게 설정되었는지 확인합니다.
kubectl --kubeconfig=KUBECONFIG -n kube-system describe pod POD_NAME
여기서
POD_NAME은 방금 변경한 포드의 이름입니다. 예를 들면stackdriver-prometheus-k8s-0입니다.응답은 다음과 같습니다.
Name: gke-metrics-agent-4th8r Namespace: kube-system ... Containers: gke-metrics-agent: Limits: cpu: 200m memory: 4.5Gi Requests: cpu: 110m memory: 240Mi ...
스토리지 크기 기본값 재정의
이러한 기본값을 재정의하려면 다음을 수행합니다.
명령줄 편집기에서 Stackdriver 커스텀 리소스를 엽니다.
kubectl --kubeconfig=KUBECONFIG -n kube-system edit stackdriver stackdriver
spec섹션 아래에storageSizeOverride필드를 추가합니다. 구성요소stackdriver-prometheus-k8s또는stackdriver-prometheus-app을 사용할 수 있습니다. 이 섹션에는 다음 형식이 사용됩니다.storageSizeOverride: STATEFULSET_NAME: SIZE
이 예시에는 statefulset
stackdriver-prometheus-k8s및120Gi크기가 사용됩니다.apiVersion: addons.gke.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: projectID: my-project clusterName: my-cluster clusterLocation: us-west-1a storageSizeOverride: stackdriver-prometheus-k8s: 120Gi변경사항을 저장하고 명령줄 편집기를 종료합니다.
포드 상태를 확인합니다.
kubectl --kubeconfig=KUBECONFIG -n kube-system get pods | grep stackdriver
stackdriver-prometheus-k8s-0 2/2 Running 0 5d19h
구성요소의 포드 사양을 확인하여 스토리지 크기가 올바르게 재정의되었는지 확인합니다.
kubectl --kubeconfig=KUBECONFIG -n kube-system describe statefulset STATEFULSET_NAME
응답은 다음과 같습니다.
Volume Claims: Name: my-statefulset-persistent-volume-claim StorageClass: my-storage-class Labels: Annotations: Capacity: 120Gi Access Modes: [ReadWriteOnce]
스토리지 클래스 기본값 재정의
선행 조건
먼저 사용할 StorageClass를 만들어야 합니다.
로깅 및 모니터링 구성요소에서 클레임하는 영구 볼륨의 기본 스토리지 클래스를 재정의하려면 다음 안내를 따르세요.
명령줄 편집기에서 Stackdriver 커스텀 리소스를 엽니다.
kubectl --kubeconfig=KUBECONFIG -n kube-system edit stackdriver stackdriver
여기서 KUBECONFIG는 클러스터의 kubeconfig 파일 경로입니다. 관리자 클러스터 또는 사용자 클러스터일 수 있습니다.
spec섹션 아래에storageClassName필드를 추가합니다.storageClassName: STORAGECLASS_NAME
storageClassName필드는 기존 기본 스토리지 클래스를 재정의하며 영구 볼륨이 클레임된 모든 로깅 및 모니터링 구성요소에 적용됩니다. 예시 파일은 다음과 같습니다.apiVersion: addons.gke.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: projectID: my-project clusterName: my-cluster clusterLocation: us-west-1a proxyConfigSecretName: my-secret-name enableVPC:
optimizedMetrics: true storageClassName: my-storage-class 변경사항을 저장합니다.
포드 상태를 확인합니다.
kubectl --kubeconfig=KUBECONFIG -n kube-system get pods | grep stackdriver
예를 들어 정상 상태의 포드는 다음과 같습니다.
stackdriver-prometheus-k8s-0 1/1 Running 0 5d19h
구성요소의 포드 사양을 확인하여 스토리지 클래스가 올바르게 설정되었는지 확인합니다.
kubectl --kubeconfig=KUBECONFIG -n kube-system describe statefulset STATEFULSET_NAME
예를 들어 스테이트풀(Stateful) 세트
stackdriver-prometheus-k8s를 사용하면 응답은 다음과 같습니다.Volume Claims: Name: stackdriver-prometheus-data StorageClass: my-storage-class Labels: Annotations: Capacity: 120Gi Access Modes: [ReadWriteOnce]
최적화된 측정항목 사용 중지
기본적으로 클러스터에서 실행되는 측정항목 에이전트는 최적화된 컨테이너 및 kubelet 및 kube-state-metrics 측정항목 집합을 수집하고 Stackdriver에 보고합니다. 추가 측정항목이 필요한 경우 GKE Enterprise 측정항목 목록에서 대체 항목을 찾는 것이 좋습니다.
사용할 수 있는 교체 예시는 다음과 같습니다.
| 사용 중지된 측정항목 | 교체 |
|---|---|
kube_pod_start_time |
container/uptime |
kube_pod_container_resource_requests |
container/cpu/request_cores container/memory/request_bytes |
kube_pod_container_resource_limits |
container/cpu/limit_cores container/memory/limit_bytes |
최적화된 kube 상태 측정항목 기본 설정을 사용 중지하려면(권장하지 않음) 다음을 수행합니다.
명령줄 편집기에서 Stackdriver 커스텀 리소스를 엽니다.
kubectl --kubeconfig=KUBECONFIG -n kube-system edit stackdriver stackdriver
여기서 KUBECONFIG는 클러스터의 kubeconfig 파일 경로입니다. 관리자 클러스터 또는 사용자 클러스터일 수 있습니다.
optimizedMetrics필드를false로 설정합니다.apiVersion: addons.gke.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: projectID: my-project clusterName: my-cluster clusterLocation: us-west-1a proxyConfigSecretName: my-secret-name enableVPC:
optimizedMetrics: false storageClassName: my-storage-class 변경사항을 저장하고 명령줄 편집기를 종료합니다.
알려진 문제: Cloud Monitoring 오류 조건
(문제 ID 159761921)
특정 조건에서는 각 새 클러스터에 기본적으로 배포된 기본 Cloud Monitoring 포드가 응답하지 않을 수 있습니다.
예를 들어 클러스터를 업그레이드하면 statefulset/prometheus-stackdriver-k8s의 포드가 다시 시작될 때 스토리지 데이터가 손상될 수 있습니다.
구체적으로 손상된 데이터가 prometheus-stackdriver-sidecar가 클러스터 스토리지 PersistentVolume에 작성하는 것을 방지할 경우 모니터링 포드 stackdriver-prometheus-k8s-0가 루프에 빠질 수 있습니다.
아래 단계에 따라 오류를 수동으로 진단하고 복구할 수 있습니다.
Cloud Monitoring 오류 진단
모니터링 포드가 실패하면 로그에 다음 항목이 보고됩니다.
{"log":"level=warn ts=2020-04-08T22:15:44.557Z caller=queue_manager.go:534 component=queue_manager msg=\"Unrecoverable error sending samples to remote storage\" err=\"rpc error: code = InvalidArgument desc = One or more TimeSeries could not be written: One or more points were written more frequently than the maximum sampling period configured for the metric.: timeSeries[0-114]; Unknown metric: kubernetes.io/anthos/scheduler_pending_pods: timeSeries[196-198]\"\n","stream":"stderr","time":"2020-04-08T22:15:44.558246866Z"}
{"log":"level=info ts=2020-04-08T22:15:44.656Z caller=queue_manager.go:229 component=queue_manager msg=\"Remote storage stopped.\"\n","stream":"stderr","time":"2020-04-08T22:15:44.656798666Z"}
{"log":"level=error ts=2020-04-08T22:15:44.663Z caller=main.go:603 err=\"corruption after 29032448 bytes: unexpected non-zero byte in padded page\"\n","stream":"stderr","time":"2020-04-08T22:15:44.663707748Z"}
{"log":"level=info ts=2020-04-08T22:15:44.663Z caller=main.go:605 msg=\"See you next time!\"\n","stream":"stderr","time":"2020-04-08T22:15:44.664000941Z"}
Cloud Monitoring 오류에서 복구
Cloud Monitoring을 수동으로 복구하려면 다음 안내를 따르세요.
클러스터 모니터링을 중지합니다.
stackdriver연산자를 축소하여 모니터링 조정을 방지합니다.kubectl --kubeconfig /ADMIN_CLUSTER_KUBCONFIG --namespace kube-system scale deployment stackdriver-operator --replicas 0
모니터링 파이프라인 워크로드를 삭제합니다.
kubectl --kubeconfig /ADMIN_CLUSTER_KUBCONFIG --namespace kube-system delete statefulset stackdriver-prometheus-k8s
모니터링 파이프라인 PersistentVolumeClaims(PVC)를 삭제합니다.
kubectl --kubeconfig /ADMIN_CLUSTER_KUBCONFIG --namespace kube-system delete pvc -l app=stackdriver-prometheus-k8s
클러스터 모니터링을 다시 시작합니다. Stackdriver 연산자를 확장하여 새 모니터링 파이프라인을 다시 설치하고 조정을 재개합니다.
kubectl --kubeconfig /ADMIN_CLUSTER_KUBCONFIG --namespace kube-system scale deployment stackdriver-operator --replicas=1