GKE on Bare Metal bietet mehrere Optionen für das Cluster-Logging und -Monitoring, einschließlich cloudbasierter verwalteter Dienste, Open-Source-Tools und validierter Kompatibilität mit kommerziellen Lösungen von Drittanbietern. Auf dieser Seite werden diese Optionen beschrieben. Außerdem erhalten Sie grundlegende Informationen zur Auswahl der richtigen Lösung für Ihre Umgebung.
Optionen für GKE on Bare Metal
Für GKE on Bare Metal stehen Ihnen mehrere Logging- und Monitoring-Optionen zur Verfügung:
- Cloud Logging und Cloud Monitoring sind standardmäßig für Bare-Metal-Systemkomponenten aktiviert.
- Prometheus und Grafana sind im Cloud Marketplace verfügbar.
- Validierte Konfigurationen mit Lösungen von Drittanbietern
Cloud Logging und Cloud Monitoring
Google Cloud Observability ist die integrierte Beobachtbarkeitslösung für Google Cloud. Sie bietet eine vollständig verwaltete Logging-Lösung, Messwerterfassung, Monitoring, Dashboards und Benachrichtigungen. Cloud Monitoring überwacht GKE on Bare-Metal-Cluster ähnlich wie cloudbasierte GKE-Cluster.
Die Agents können so konfiguriert werden, dass sie den Umfang von Logging und Monitoring sowie die Ebene der erfassten Messwerte ändern:
- Der Umfang des Loggings und Monitorings kann auf nur Systemkomponenten (Standardeinstellung) oder auf Systemkomponenten und Anwendungen festgelegt werden.
- Die Ebene der erfassten Messwerte kann für einen optimierten Satz von Messwerten (Standardeinstellung) oder für alle Messwerte konfiguriert werden.
Weitere Informationen finden Sie in diesem Dokument unter Stackdriver-Agents für GKE on Bare Metal konfigurieren.
Logging und Monitoring bieten eine einzige, einfach zu konfigurierende und leistungsstarke cloudbasierte Beobachtbarkeitslösung. Wir empfehlen Logging und Monitoring dringend, wenn Sie Arbeitslasten nur in GKE on Bare Metal oder Arbeitslasten in GKE und GKE on Bare Metal ausführen. Für Anwendungen mit Komponenten, die in GKE in Bare Metal und in der standardmäßigen lokalen Infrastruktur ausgeführt werden, können Sie andere Lösungen für eine End-to-End-Ansicht dieser Anwendungen in Betracht ziehen.
Weitere Informationen zur Architektur, zur Konfiguration und dazu, welche Daten standardmäßig in Ihrem Google Cloud-Projekt repliziert werden, finden Sie unter Funktionsweise von Logging und Monitoring für GKE on Bare Metal.
Weitere Informationen zu Logging erhalten Sie in der Dokumentation zu Cloud Logging.
Weitere Informationen zu Monitoring finden Sie in der Dokumentation zu Cloud Monitoring.
Informationen zum Ansehen und Verwenden von Cloud Monitoring-Ressourcenauslastungsmesswerten von GKE on Bare Metal auf Flottenebene finden Sie unter Übersicht über die Google Kubernetes Engine (GKE) Enterprise-Version.
Prometheus und Grafana
Prometheus und Grafana sind zwei beliebte Open-Source-Monitoring-Produkte im Cloud Marketplace:
Prometheus erfasst Anwendungs- und Systemmesswerte.
Alertmanager sendet Benachrichtigungen über verschiedene Mechanismen.
Grafana ist ein Dashboard-Tool.
Prometheus und Grafana können in jedem Administrator- und Nutzercluster aktiviert werden. Prometheus und Grafana werden für Anwendungsteams empfohlen, die bereits Erfahrung mit diesen Produkten haben. Diese Produkte werden auch für operative Teams empfohlen, die Anwendungsmesswerte innerhalb des Clusters beibehalten möchten, und zur Behebung von Problemen verwenden, wenn die Netzwerkverbindung unterbrochen wird.
Drittanbieterlösungen
Google hat mit mehreren Logging- und Monitoring-Drittanbietern zusammengearbeitet, damit ihre Produkte gut mit GKE on Bare Metal funktionieren. Dazu gehören Datadog, Elastic und Splunk. Weitere validierte Drittanbieter werden in Zukunft hinzugefügt.
Die folgenden Lösungsleitfäden stehen für die Verwendung von Drittanbieterlösungen mit GKE on Bare Metal zur Verfügung:
- GKE on Bare Metal mit dem Elastic-Stack überwachen
- Logs in GKE on Bare Metal mit Splunk Connect erfassen
Funktionsweise von Logging und Monitoring für GKE on Bare Metal
Cloud Logging und Cloud Monitoring werden in jedem Cluster installiert und aktiviert, wenn Sie einen neuen Administrator- oder Nutzercluster erstellen.
Die Stackdriver-Agents enthalten mehrere Komponenten in jedem Cluster:
Stackdriver-Operator (
stackdriver-operator-*). Verwaltet den Lebenszyklus aller anderen auf dem Cluster bereitgestellten Stackdriver-Agents.Benutzerdefinierte Stackdriver-Ressource. Eine Ressource, die im Rahmen der Installation von GKE on Bare Metal automatisch erstellt wird.
GKE-Messwert-Agent (
gke-metrics-agent-*). Ein DaemonSet, das auf OpenTelemetry-Collector basiert und Messwerte von jedem Knoten für Cloud Monitoring extrahiert. Einnode-exporter-DaemonSet und einkube-state-metrics-Deployment sind ebenfalls enthalten, um weitere Messwerte zum Cluster bereitzustellen.Stackdriver Log Forwarder (
stackdriver-log-forwarder-*). Ein Fluent Bit-DaemonSet, das Logs von jeder Maschine an Cloud Logging weiterleitet. Der Log-Forwarder puffert die Logeinträge auf dem Knoten lokal und sendet sie bis zu vier Stunden lang noch einmal. Wenn der Zwischenspeicher voll ist oder der Log Forwarder die Cloud Logging API mehr als vier Stunden lang nicht erreichen kann, werden Logs gelöscht.Anthos-Metadaten-Agent (
stackdriver-metadata-agent-). Ein Deployment, das Metadaten für Kubernetes-Ressourcen wie Pods, Deployments oder Knoten an die Config Monitoring for Ops API sendet. Diese Daten werden zur Anreicherung von Messwertabfragen verwendet, indem Sie Abfragen nach Bereitstellungsname, Knotenname oder sogar Kubernetes-Dienstnamen ausführen können.
Mit dem folgenden Befehl können Sie die von Stackdriver installierten Agents aufrufen:
kubectl -n kube-system get pods -l "managed-by=stackdriver"
Die Ausgabe dieses Befehls sieht wie folgt aus:
kube-system gke-metrics-agent-4th8r 1/1 Running 1 (40h ago) 40h
kube-system gke-metrics-agent-8lt4s 1/1 Running 1 (40h ago) 40h
kube-system gke-metrics-agent-dhxld 1/1 Running 1 (40h ago) 40h
kube-system gke-metrics-agent-lbkl2 1/1 Running 1 (40h ago) 40h
kube-system gke-metrics-agent-pblfk 1/1 Running 1 (40h ago) 40h
kube-system gke-metrics-agent-qfwft 1/1 Running 1 (40h ago) 40h
kube-system kube-state-metrics-9948b86dd-6chhh 1/1 Running 1 (40h ago) 40h
kube-system node-exporter-5s4pg 1/1 Running 1 (40h ago) 40h
kube-system node-exporter-d9gwv 1/1 Running 2 (40h ago) 40h
kube-system node-exporter-fhbql 1/1 Running 1 (40h ago) 40h
kube-system node-exporter-gzf8t 1/1 Running 1 (40h ago) 40h
kube-system node-exporter-tsrpp 1/1 Running 1 (40h ago) 40h
kube-system node-exporter-xzww7 1/1 Running 1 (40h ago) 40h
kube-system stackdriver-log-forwarder-8lwxh 1/1 Running 1 (40h ago) 40h
kube-system stackdriver-log-forwarder-f7cgf 1/1 Running 2 (40h ago) 40h
kube-system stackdriver-log-forwarder-fl5gf 1/1 Running 1 (40h ago) 40h
kube-system stackdriver-log-forwarder-q5lq8 1/1 Running 2 (40h ago) 40h
kube-system stackdriver-log-forwarder-www4b 1/1 Running 1 (40h ago) 40h
kube-system stackdriver-log-forwarder-xqgjc 1/1 Running 1 (40h ago) 40h
kube-system stackdriver-metadata-agent-cluster-level-5bb5b6d6bc-z9rx7 1/1 Running 1 (40h ago) 40h
Cloud Monitoring-Messwerte
Eine Liste der von Cloud Monitoring erfassten Messwerte finden Sie unter GKE on Bare-Metal-Messwerte ansehen.
Stackdriver-Agents für GKE on Bare Metal konfigurieren
Die mit GKE on Bare Metal installierten Stackdriver-Agents erfassen Daten zu Systemkomponenten, um Probleme in Ihren Clustern zu warten und zu beheben. In den folgenden Abschnitten werden die Stackdriver-Konfigurations- und Betriebsmodi beschrieben.
Nur Systemkomponenten (Standardmodus)
Bei der Installation werden Stackdriver-Agents standardmäßig so konfiguriert, dass sie Logs und Messwerte erfassen, einschließlich Leistungsdetails (z. B. CPU- und Arbeitsspeicherauslastung) und vergleichbarer Metadaten für von Google bereitgestellte Systemkomponenten. Dazu gehören alle Arbeitslasten im Administratorcluster und in Nutzerclustern Arbeitslasten in den Namespaces kube-system, gke-system, gke-connect, istio-system und config-management-system.
Systemkomponenten und Anwendungen
Führen Sie die Schritte unter Anwendungs-Logging und -Monitoring aktivieren aus, um das Logging und Monitoring von Anwendungen zusätzlich zum Standardmodus zu aktivieren.
Optimierte Messwerte (Standardmesswerte)
Standardmäßig erfassen die im Cluster ausgeführten kube-state-metrics-Deployments einen optimierten Satz von Kube-Messwerten und melden sie an Google Cloud-Beobachtbarkeit (früher Stackdriver).
Es sind weniger Ressourcen erforderlich, um diese optimierten Messwerte zu erfassen, was die Gesamtleistung und die Skalierbarkeit verbessert.
Wenn Sie optimierte Messwerte deaktivieren möchten (nicht empfohlen), überschreiben Sie die Standardeinstellung in Ihrer benutzerdefinierten Stackdriver-Ressource.
Managed Service for Prometheus für ausgewählte Systemkomponenten verwenden
Google Cloud Managed Service for Prometheus ist Teil von Cloud Monitoring und ist als Option für Systemkomponenten verfügbar. Managed Service for Prometheus bietet unter anderem folgende Vorteile:
Sie können Ihr vorhandenes Prometheus-basiertes Monitoring weiterhin verwenden, ohne Ihre Benachrichtigungen und Grafana-Dashboards zu ändern.
Wenn Sie sowohl GKE als auch GKE on Bare Metal verwenden, können Sie dieselbe Prometheus Query Language (PromQL) für Messwerte in allen Clustern verwenden. Sie können auch den Tab PromQL im Metrics Explorer in der Google Cloud Console verwenden.
Managed Service for Prometheus aktivieren und deaktivieren
Managed Service for Prometheus ist in GKE on Bare Metal standardmäßig aktiviert.
So deaktivieren Sie Managed Service for Prometheus:
Öffnen Sie das Stackdriver-Objekt
stackdriverzur Bearbeitung:kubectl --kubeconfig CLUSTER_KUBECONFIG --namespace kube-system \ edit stackdriver stackdriverFügen Sie das Feature-Gate
enableGMPForSystemMetricshinzu und legen Sie es auffalsefest:apiVersion: addons.gke.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: featureGates: enableGMPForSystemMetrics: falseSchließen Sie die Bearbeitungssitzung.
Messwertdaten ansehen
Wenn enableGMPForSystemMetrics auf true gesetzt ist, haben Messwerte für die folgenden Komponenten ein anderes Format dafür, wie sie in Cloud Monitoring gespeichert und abgefragt werden:
- kube-apiserver
- kube-scheduler
- kube-controller-manager
- Kubelet und cAdvisor
- kube-state-metrics
- node-exporter
Im neuen Format können Sie die vorherigen Messwerte entweder mit PromQL oder mit Monitoring Query Language (MQL) abfragen:
PromQL
Beispiel für eine PromQL-Abfrage:
histogram_quantile(0.95, sum(rate(apiserver_request_duration_seconds_bucket[5m])) by (le))
MQL
Wenn Sie MQL verwenden möchten, legen Sie die überwachte Ressource auf prometheus_target fest, verwenden Sie den Messwertnamen mit dem Präfix kubernetes.io/anthos und fügen Sie dem Messwertnamen den Prometheus-Typ als Suffix hinzu.
fetch prometheus_target
| metric 'kubernetes.io/anthos/apiserver_request_duration_seconds/histogram'
| align delta(5m)
| every 5m
| group_by [], [value_histogram_percentile: percentile(value.histogram, 95)]
Grafana-Dashboards mit Managed Service for Prometheus konfigurieren
Wenn Sie Grafana mit Messwertdaten aus Managed Service for Prometheus verwenden möchten, führen Sie die Schritte unter Mit Grafana abfragen aus, um eine Grafana-Datenquelle zu authentifizieren und zu konfigurieren, um Daten von Managed Service for Prometheus abzufragen.
Im Repository anthos-samples auf GitHub finden Sie eine Reihe von Grafana-Beispiel-Dashboards. So installieren Sie die Beispiel-Dashboards:
Laden Sie die JSON-Beispieldateien herunter:
git clone https://github.com/GoogleCloudPlatform/anthos-samples.git cd anthos-samples/gmp-grafana-dashboards
Wenn Ihre Grafana-Datenquelle mit einem anderen Namen als
Managed Service for Prometheuserstellt wurde, ändern Sie das Felddatasourcein allen JSON-Dateien:sed -i "s/Managed Service for Prometheus/[DATASOURCE_NAME]/g" ./*.json
Ersetzen Sie [DATASOURCE_NAME] durch den Namen der Datenquelle in Grafana, die auf den Prometheus-Dienst
frontendverweist.Rufen Sie die Grafana-UI in Ihrem Browser auf und wählen Sie im Menü Dashboards die Option + Import (+ Importieren) aus.
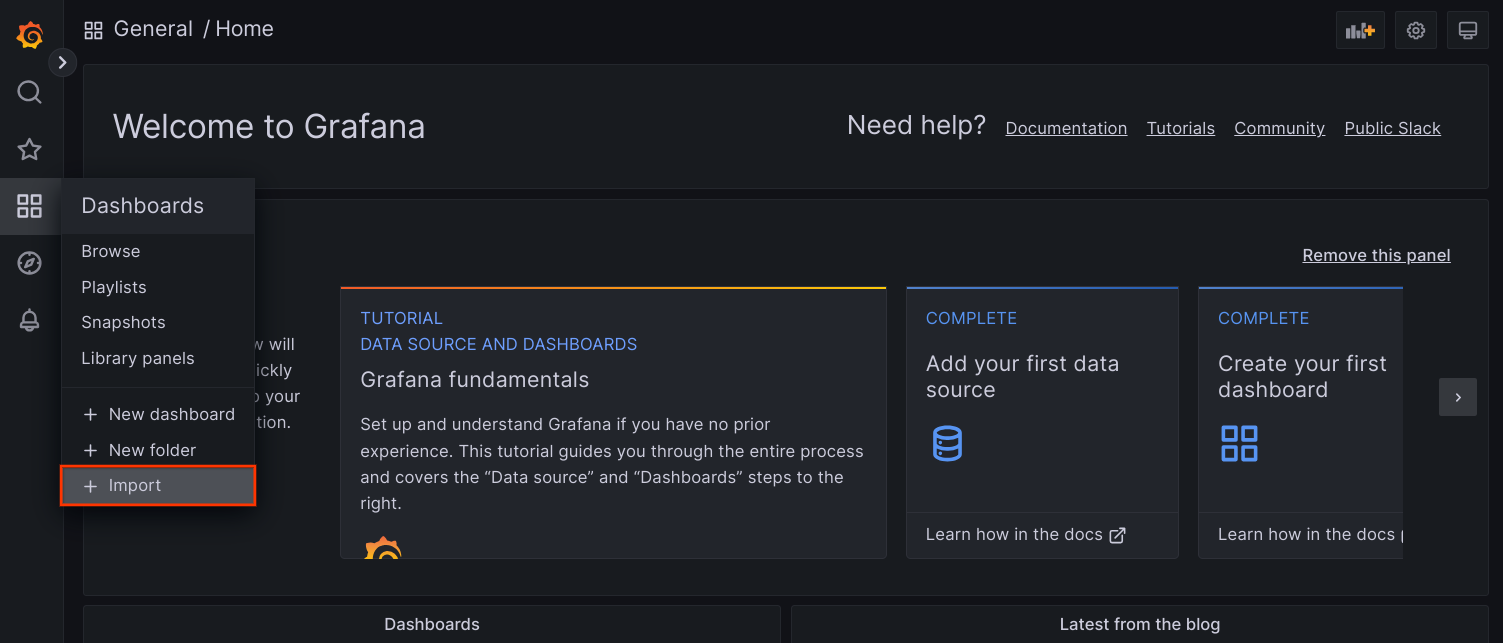
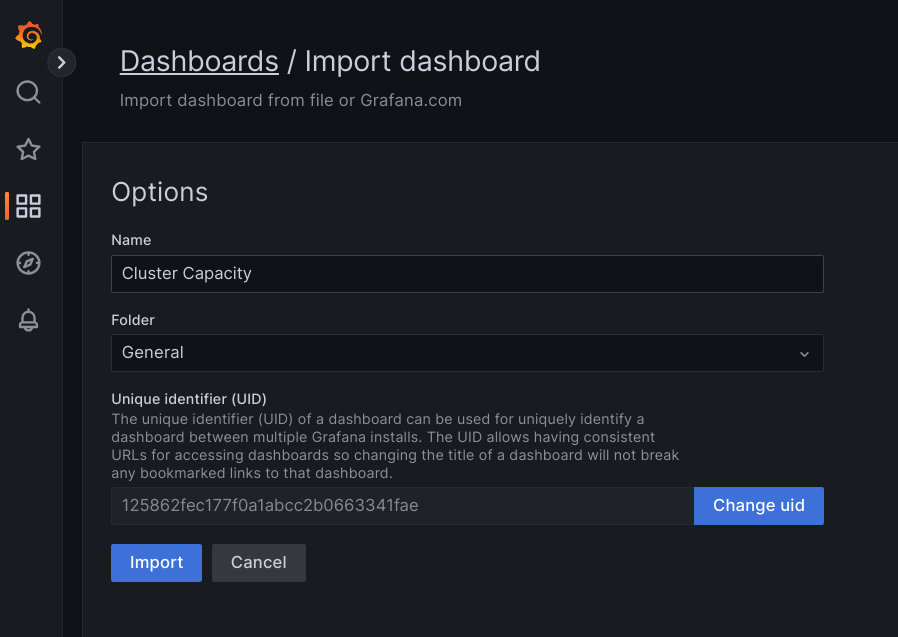
Laden Sie entweder die JSON-Datei hoch oder kopieren Sie den Dateiinhalt, fügen Sie ihn ein und wählen Sie Laden aus. Nachdem der Inhalt der Datei geladen wurde, wählen Sie Importieren aus. Optional können Sie vor dem Import auch den Namen und die UID des Dashboards ändern.
Das importierte Dashboard sollte erfolgreich geladen werden, wenn GKE on Bare Metal und die Datenquelle richtig konfiguriert sind. Der folgende Screenshot zeigt beispielsweise das von
cluster-capacity.jsonkonfigurierte Dashboard.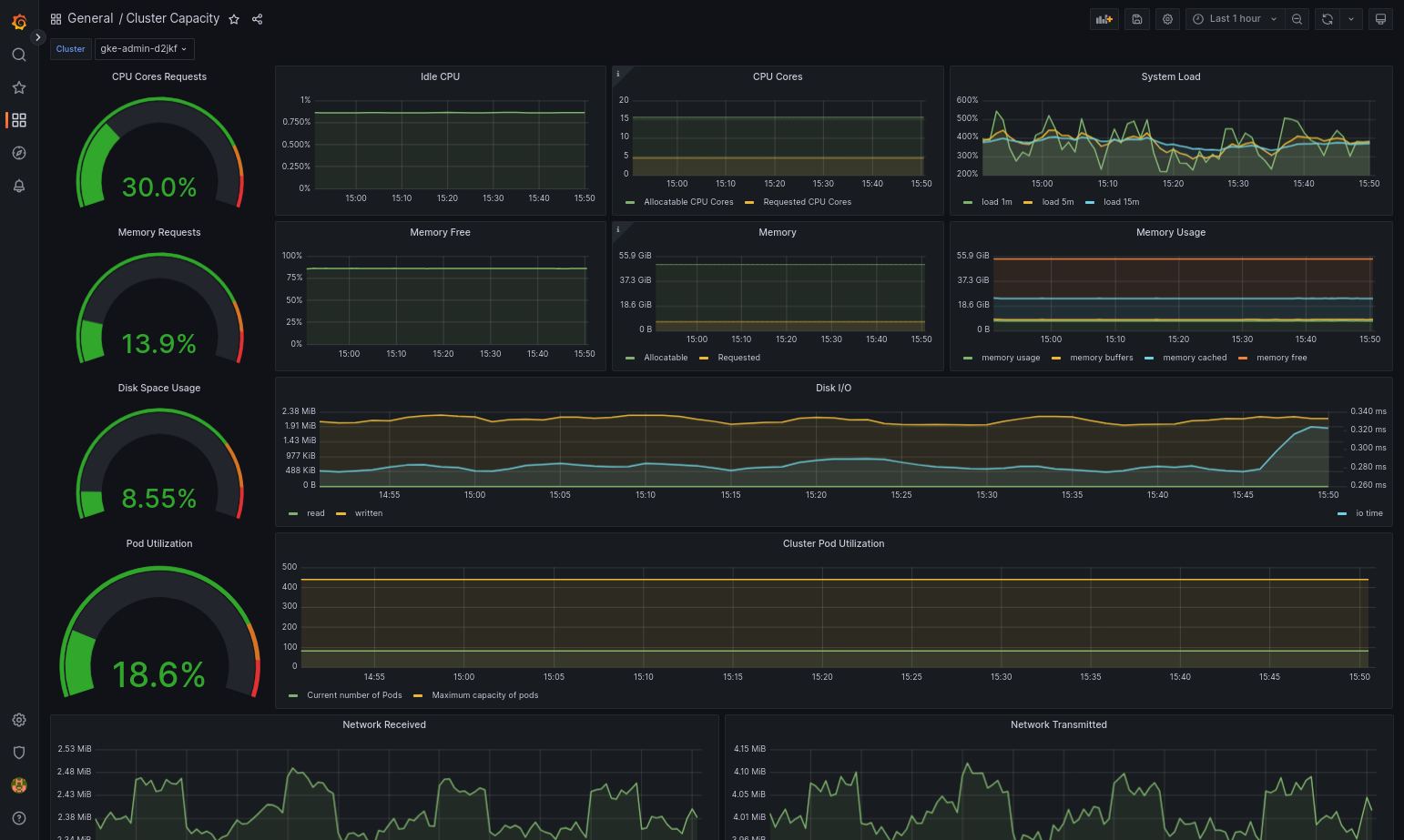
Weitere Ressourcen
Weitere Informationen zu Managed Service for Prometheus finden Sie hier:
Messwerte der GKE-Steuerungsebene sind mit PromQL kompatibel
Managed Service for Prometheus für Nutzeranwendungen in GKE on Bare Metal verwenden
Stackdriver-Komponentenressourcen konfigurieren
Wenn Sie einen Cluster erstellen, wird von GKE on Bare Metal automatisch eine benutzerdefinierte Stackdriver-Ressource erstellt. Sie können die Spezifikation in der benutzerdefinierten Ressource bearbeiten, um die Standardwerte für CPU- und Arbeitsspeicheranfragen und -limits für eine Stackdriver-Komponente zu überschreiben. Sie können die Standardeinstellung für optimierte Messwerte separat überschreiben.
Standardmäßige CPU- und Speicheranforderungen und Limits für eine Stackdriver-Komponente überschreiben
Cluster mit einer hohen Pod-Dichte führen zu einem höheren Logging und Monitoring. In extremen Fällen melden Stackdriver-Komponenten möglicherweise das Limit für die CPU- und Speicherauslastung oder wegen kontinuierlicher Neustarts aufgrund von Ressourcenlimits. Führen Sie in diesem Fall die folgenden Schritte aus, um die Standardwerte für CPU- und Speicheranforderungen und Limits für eine Stackdriver-Komponente zu überschreiben:
Führen Sie den folgenden Befehl aus, um Ihre benutzerdefinierte Stackdriver-Ressource in einem Befehlszeileneditor zu öffnen:
kubectl -n kube-system edit stackdriver stackdriver
Fügen Sie in der benutzerdefinierten Stackdriver-Ressource den Abschnitt
resourceAttrOverrideunter dem Feldspechinzu:resourceAttrOverride: DAEMONSET_OR_DEPLOYMENT_NAME/CONTAINER_NAME: LIMITS_OR_REQUESTS: RESOURCE: RESOURCE_QUANTITYBeachten Sie, dass der Abschnitt
resourceAttrOverridealle vorhandenen Standardlimits und -anfragen für die angegebene Komponente überschreibt. Die folgenden Komponenten werden vonresourceAttrOverrideunterstützt:gke-metrics-agent/gke-metrics-agentstackdriver-log-forwarder/stackdriver-log-forwarderstackdriver-metadata-agent-cluster-level/metadata-agentnode-exporter/node-exporterkube-state-metrics/kube-state-metrics
Eine Beispieldatei sieht so aus:
apiVersion: addons.gke.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: anthosDistribution: baremetal projectID: my-project clusterName: my-cluster clusterLocation: us-west-1a resourceAttrOverride: gke-metrics-agent/gke-metrics-agent: requests: cpu: 110m memory: 240Mi limits: cpu: 200m memory: 4.5GiSpeichern und schließen Sie den Befehlszeileneditor, um Änderungen an der benutzerdefinierten Stackdriver-Ressource zu speichern.
Prüfen Sie den Status Ihres Pods:
kubectl -n kube-system get pods -l "managed-by=stackdriver"
Eine Antwort für einen fehlerfreien Pod sieht so aus:
gke-metrics-agent-4th8r 1/1 Running 1 40h
Sehen Sie in der Pod-Spezifikation der Komponente nach, ob die Ressourcen richtig festgelegt sind.
kubectl -n kube-system describe pod POD_NAME
Ersetzen Sie
POD_NAMEdurch den Namen des Pods, den Sie gerade geändert haben. Beispiel:gke-metrics-agent-4th8r.Die Antwort sieht in etwa so aus:
Name: gke-metrics-agent-4th8r Namespace: kube-system ... Containers: gke-metrics-agent: Limits: cpu: 200m memory: 4.5Gi Requests: cpu: 110m memory: 240Mi ...
Optimierte Messwerte deaktivieren
Standardmäßig erfassen die im Cluster ausgeführten kube-state-metrics-Deployments einen optimierten Satz von Kube-Messwerten und melden sie an Stackdriver. Wenn Sie zusätzliche Messwerte benötigen, empfehlen wir Ihnen, einen Ersatz aus der Liste der GKE on Bare Metal-Messwerte zu finden.
Hier sind einige Beispiele für mögliche Ersetzungen:
| Deaktivierter Messwert | Ersatzprodukte |
|---|---|
kube_pod_start_time |
container/uptime |
kube_pod_container_resource_requests |
container/cpu/request_cores container/memory/request_bytes |
kube_pod_container_resource_limits |
container/cpu/limit_cores container/memory/limit_bytes |
So deaktivieren Sie die Standardeinstellung für optimierte Messwerte (nicht empfohlen):
Öffnen Sie die benutzerdefinierte Stackdriver-Ressource in einem Befehlszeileneditor:
kubectl -n kube-system edit stackdriver stackdriver
Setzen Sie das Feld
optimizedMetricsauffalse:apiVersion: addons.gke.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: anthosDistribution: baremetal projectID: my-project clusterName: my-cluster clusterLocation: us-west-1a optimizedMetrics: false
Speichern Sie die Änderungen und schließen Sie den Befehlszeilen-Editor.
Metrics Server
Der Metrics Server ist die Quelle der Containerressourcenmesswerte für verschiedene Autoscaling-Pipelines. Metrics Server ruft Messwerte aus kubelets ab und stellt sie über die Metrics API von Kubernetes bereit. HPA und VPA bestimmen dann anhand dieser Messwerte, wann das Autoscaling ausgelöst werden soll. Der Messwertserver wird mit Add-on-Resizer skaliert.
In extremen Fällen, in denen eine hohe Pod-Dichte zu viel Logging und Monitoring verursacht, wird Metrics Server unter Umständen aufgrund von Ressourcenbeschränkungen gestoppt und neu gestartet. In diesem Fall können Sie dem Messwertserver mehr Ressourcen zuweisen. Dazu bearbeiten Sie die Konfigurationsdatei metrics-server-config im Namespace „gke-managed-metrics-server“ und ändern den Wert für cpuPerNode und memoryPerNode.
kubectl edit cm metrics-server-config -n gke-managed-metrics-server
Der Beispielinhalt der ConfigMap lautet:
apiVersion: v1
data:
NannyConfiguration: |-
apiVersion: nannyconfig/v1alpha1
kind: NannyConfiguration
cpuPerNode: 3m
memoryPerNode: 20Mi
kind: ConfigMap
Nachdem Sie die ConfigMap aktualisiert haben, erstellen Sie die Messwertserver-Pods mit dem folgenden Befehl neu:
kubectl delete pod -l k8s-app=metrics-server -n gke-managed-metrics-server
Konfigurationsanforderungen für Logging und Monitoring
Es gibt verschiedene Konfigurationsanforderungen, um Cloud Logging und Cloud Monitoring mit GKE on Bare Metal zu aktivieren. Diese Schritte sind auf der Seite "Google-Dienste aktivieren" unter Dienstkonto für die Verwendung mit Logging und Monitoring konfigurieren und in der folgenden Liste aufgeführt:
- Ein Cloud Monitoring-Arbeitsbereich muss innerhalb des Google Cloud-Projekts erstellt werden. Klicken Sie dazu auf Monitoring in der Google Cloud Console und folgen Sie dem Workflow.
Sie müssen die folgenden Stackdriver APIs aktivieren:
Sie müssen dem Dienstkonto, das von den Stackdriver-Agents verwendet wird, die folgenden IAM-Rollen zuweisen:
logging.logWritermonitoring.metricWriterstackdriver.resourceMetadata.writermonitoring.dashboardEditoropsconfigmonitoring.resourceMetadata.writer
Preise
Die Systemlogs und -messwerte der Google Kubernetes Engine (GKE) Enterprise-Version sind kostenlos.
In einem GKE on Bare Metal-Cluster umfassen die Systemlogs und Messwerte der Google Kubernetes Engine (GKE) Enterprise-Version Folgendes:
- Logs und Messwerte aus allen Komponenten in einem Administratorcluster
- Logs und Messwerte aus Komponenten in diesen Namespaces in einem Nutzercluster:
kube-system,gke-system,gke-connect,knative-serving,istio-system,monitoring-system,config-management-system,gatekeeper-system,cnrm-system
Weitere Informationen finden Sie unter Preise für die Google Cloud-Beobachtbarkeit.
Wenn Sie weitere Informationen wünschen und mehr über Guthaben für Cloud Logging-Messwerte wissen möchten, wenden Sie sich an den Vertrieb.