Cette page décrit les métriques OpenTelemetry disponibles pour surveiller vos ressources Config Sync.
Tarifs
Les métriques Config Sync utilisent Google Cloud Managed Service pour Prometheus pour charger des métriques dans Cloud Monitoring. Les frais liés à l'ingestion de ces métriques sont calculés par Cloud Monitoring en fonction du nombre d'échantillons ingérés.
Pour en savoir plus, consultez la tarification Cloud Monitoring.
Comment Config Sync collecte les métriques
Config Sync utilise OpenCensus pour créer et enregistrer des métriques et OpenTelemetry pour exporter ses métriques vers Prometheus et Cloud Monitoring. Les guides suivants expliquent comment exporter des métriques :
- Cloud Monitoring
- Prometheus
- Système de surveillance personnalisé (déconseillé)
Pour configurer le collecteur OpenTelemetry, Config Sync crée par défaut un fichier ConfigMap nommé otel-collector. Le déploiement otel-collector s'exécute dans l'espace de noms config-management-monitoring.
La création de la ConfigMap otel-collector configure l'exportateur prometheus, qui expose un point de terminaison de métriques que Prometheus peut analyser.
Lorsque vous exécutez Config Sync sur GKE ou dans un autre environnement Kubernetes configuré avec des identifiants Google Cloud , Config Sync crée un ConfigMap nommé otel-collector-google-cloud. otel-collector-google-cloud remplace la configuration dans le ConfigMap otel-collector. Config Sync rétablit les modifications apportées aux ConfigMaps otel-collector ou otel-collector-google-cloud.
La création de la ConfigMap otel-collector-google-cloud ajoute également l'exportateur cloudmonitoring, qui exporte les données vers Cloud Monitoring, et l'exportateur kubernetes, qui les exporte vers le service de métriques interne de Google. L'exportateur kubernetes envoie à Google des métriques sélectionnées et anonymisées pour nous aider à améliorer Config Sync.
Cloud Monitoring stocke les métriques que vous lui envoyez dans votre projetGoogle Cloud . Les exportateurs cloudmonitoring et kubernetes utilisent le même compte de serviceGoogle Cloud , qui a besoin d'une autorisation IAM pour écrire dans Cloud Monitoring. Pour configurer ces autorisations, consultez Accorder l'autorisation d'écriture de métriques pour Cloud Monitoring.
Métriques OpenTelemetry
Config Sync et le contrôleur de groupe de ressources collectent les métriques suivantes avec OpenCensus et les mettent à disposition via le collecteur OpenTelemetry . La colonne Tags répertorie les tags spécifiques à Config Sync qui s'appliquent à chaque métrique. Les métriques avec des tags représentent plusieurs mesures, une pour chaque combinaison de valeurs de tags.
Métriques Config Sync
| Nom | Type | Tags | Description |
|---|---|---|---|
| api_duration_seconds | Distribution | État de l'opération | Distribution de la latence des appels de serveur d'API |
| apply_duration_seconds | Distribution | état | Distribution de la latence d'application des ressources déclarées de la source de vérité à un cluster. |
| apply_operations_total | Nombre | opération, état, contrôleur | Nombre total d'opérations effectuées pour synchroniser les ressources de la source de vérité avec un cluster. |
| declared_resources | Dernière valeur | Nombre de ressources déclarées analysées à partir de Git | |
| internal_errors_total | Nombre | source | Nombre total d'erreurs internes rencontrées par Config Sync La métrique peut ne pas apparaître dans les résultats de la requête si aucune erreur interne ne s'est produite. |
| last_sync_timestamp | Dernière valeur | état | Horodatage de la dernière synchronisation à partir de Git |
| parser_duration_seconds | Distribution | état, déclencheur, source | Distribution de la latence des différentes étapes impliquées dans la synchronisation de la source de vérité vers un cluster. |
| pipeline_error_observed | Dernière valeur | name, reconciler, component | État des ressources personnalisées RootSync et RepoSync. Une valeur de 1 indique un échec. |
| reconcile_duration_seconds | Distribution | état | Distribution de la latence des événements de rapprochement gérés par le gestionnaire de rapprochement. |
| reconciler_errors | Dernière valeur | component, errorclass | Nombre d'erreurs rencontrées lors de la synchronisation des ressources de la source de vérité avec un cluster. |
| remediate_duration_seconds | Distribution | état | Distribution de la latence des événements de rapprochement de correction |
| resource_conflicts_total | Nombre | Nombre total de conflits de ressources résultant d'une différence entre les ressources mises en cache et les ressources du cluster La métrique peut ne pas apparaître dans les résultats de la requête si aucun conflit de ressources ne s'est produit. | |
| resource_fights_total | Nombre | Nombre total de ressources synchronisées trop fréquemment. Tout résultat supérieur à zéro indique un problème. Pour en savoir plus, consultez la page KNV2005 : ResourceFightWarning. La métrique peut ne pas apparaître dans les résultats de la requête si aucun conflit de ressources ne s'est produit. |
Métriques de contrôleur de groupe de ressources
Le contrôleur de groupe de ressources est un composant de Config Sync qui effectue le suivi des ressources gérées et vérifie si chacune d'elles est prête ou rapprochée. Les métriques suivantes sont disponibles.
| Nom | Type | Tags | Description |
|---|---|---|---|
| rg_reconcile_duration_seconds | Distribution | stallreason | Répartition du temps nécessaire au rapprochement d'une RS ResourceGroup |
| resource_group_total | Dernière valeur | Nombre actuel de RS ResourceGroup | |
| resource_count | Dernière valeur | resourcegroup | Nombre total de ressources suivies par une RS ResourceGroup |
| ready_resource_count | Dernière valeur | resourcegroup | Nombre total de ressources prêtes dans une RS ResourceGroup |
| resource_ns_count | Dernière valeur | resourcegroup | Nombre d'espaces de noms utilisés par les ressources dans une RS ResourceGroup |
| cluster_scoped_resource_count | Dernière valeur | resourcegroup | Nombre de ressources à l'échelle du cluster dans une RS ResourceGroup |
| crd_count | Dernière valeur | resourcegroup | Nombre de CRD dans une RS ResourceGroup |
| kcc_resource_count | Dernière valeur | resourcegroup | Nombre total de ressources KCC dans un ResourceGroup |
| pipeline_error_observed | Dernière valeur | name, reconciler, component | État des ressources personnalisées RootSync et RepoSync. Une valeur de 1 indique un échec. |
Libellés de métriques Config Sync
Les libellés de métriques peuvent être utilisés pour agréger les données de métriques dans Cloud Monitoring et Prometheus. Ils peuvent être sélectionnés dans la liste déroulante "Grouper par" de la console Monitoring.
Pour en savoir plus sur les libellés Cloud Monitoring et les libellés de métriques Prometheus, consultez les pages Composants du modèle de métrique et Modèle de données Prometheus.
Étiquettes de métriques
Les libellés suivants sont utilisés par les métriques de Config Sync et du contrôleur de groupe de ressources, disponibles lors de la surveillance avec Cloud Monitoring et Prometheus.
| Nom | Valeurs | Description |
|---|---|---|
operation |
création, correction, mise à jour, suppression | Le type d'opération effectuée |
status |
réussite, erreur | État de l'exécution d'une opération |
reconciler |
rootsync, reposync | Type de rapprochement |
source |
analyseur, différence, outil de résolution | Source de l'erreur interne. |
trigger |
réessayez, watchUpdate, managementConflict, resync, reimport | Déclencheur d'un événement de rapprochement |
name |
Nom du rapprochement | Nom du rapprochement |
component |
analyse, source, synchronisation, rendu, aptitude | Le nom du composant / de l'étape actuelle du rapprochement |
container |
rapprochement, git-sync | Nom du conteneur |
resource |
Processeur, mémoire | Le type de la ressource |
controller |
applicateur, outil de résolution | Nom du contrôleur dans un rapprochement racine ou de l'espace de noms |
type |
Toute ressource Kubernetes, par exemple ClusterRole, Namespace, NetworkPolicy, Role, etc. | Type d'API Kubernetes |
commit |
---- | Hachage du dernier commit synchronisé |
Étiquettes de ressource
Les métriques Config Sync envoyées à Prometheus et à Cloud Monitoring comportent les libellés de métriques suivants définis pour identifier le pod source :
| Nom | Description |
|---|---|
k8s.node.name |
Nom du nœud hébergeant un pod Kubernetes |
k8s.pod.namespace |
Espace de noms du pod |
k8s.pod.uid |
UID du pod |
k8s.pod.ip |
Adresse IP du pod |
k8s.deployment.name |
Nom du déploiement propriétaire du pod |
Les métriques Config Sync envoyées à Prometheus et à Cloud Monitoring à partir de pods reconciler possèdent également les libellés de métriques suivants définis pour identifier l'objet RootSync ou RepoSync utilisé pour configurer le rapprochement :
| Nom | Description |
|---|---|
configsync.sync.kind |
Type de ressource qui configure ce rapprochement : RootSync ou RepoSync |
configsync.sync.name |
Nom de l'RootSync ou de l'RepoSync qui configure ce rapprochement |
configsync.sync.namespace |
Espace de noms de RootSync ou RepoSync qui configure ce rapprochement |
Étiquettes de ressources Cloud Monitoring
Les libellés de ressources Cloud Monitoring sont utilisés pour indexer les métriques dans le stockage, ce qui signifie qu'ils ont un effet négligeable sur la cardinalité, contrairement aux libellés de métriques, où la cardinalité est un problème de performances important. Pour en savoir plus, consultez Types de ressources surveillées.
Le type de ressource k8s_container définit les libellés de ressource suivants pour identifier le conteneur source :
| Nom | Description |
|---|---|
container_name |
Nom du conteneur |
pod_name |
Nom du pod |
namespace_name |
Espace de noms du pod |
location |
Région ou zone du cluster hébergeant le nœud |
cluster_name |
Nom du cluster hébergeant le nœud |
project |
ID du projet hébergeant le cluster |
Configurer le filtrage des métriques personnalisées
Vous pouvez ajuster les métriques personnalisées que Config Sync exporte vers Prometheus, Cloud Monitoring et le service de surveillance interne de Google. Ajustez les métriques personnalisées pour affiner les métriques incluses ou configurer différents backends.
Pour modifier des métriques personnalisées, créez un ConfigMap nommé otel-collector-custom, puis modifiez-le. L'utilisation de ce ConfigMap garantit que Config Sync n'annule aucune des modifications que vous apportez. Si vous modifiez les ConfigMaps otel-collector ou otel-collector-google-cloud, Config Sync rétablit les modifications.
Pour obtenir des exemples d'ajustement de cette ConfigMap, consultez la section Filtrage personnalisé des métriques dans la documentation Open Source de Config Sync.
Comprendre la métrique pipeline_error_observed
La métrique pipeline_error_observed est une métrique qui peut vous aider à identifier rapidement les RS RepoSync ou RootSync qui ne sont pas synchronisées ou qui contiennent des ressources qui ne sont pas rapprochées de l'état souhaité.
Pour une synchronisation réussie par RootSync ou RepoSync, les métriques avec tous les composants (
rendering,source,sync,readiness) sont observées avec la valeur 0.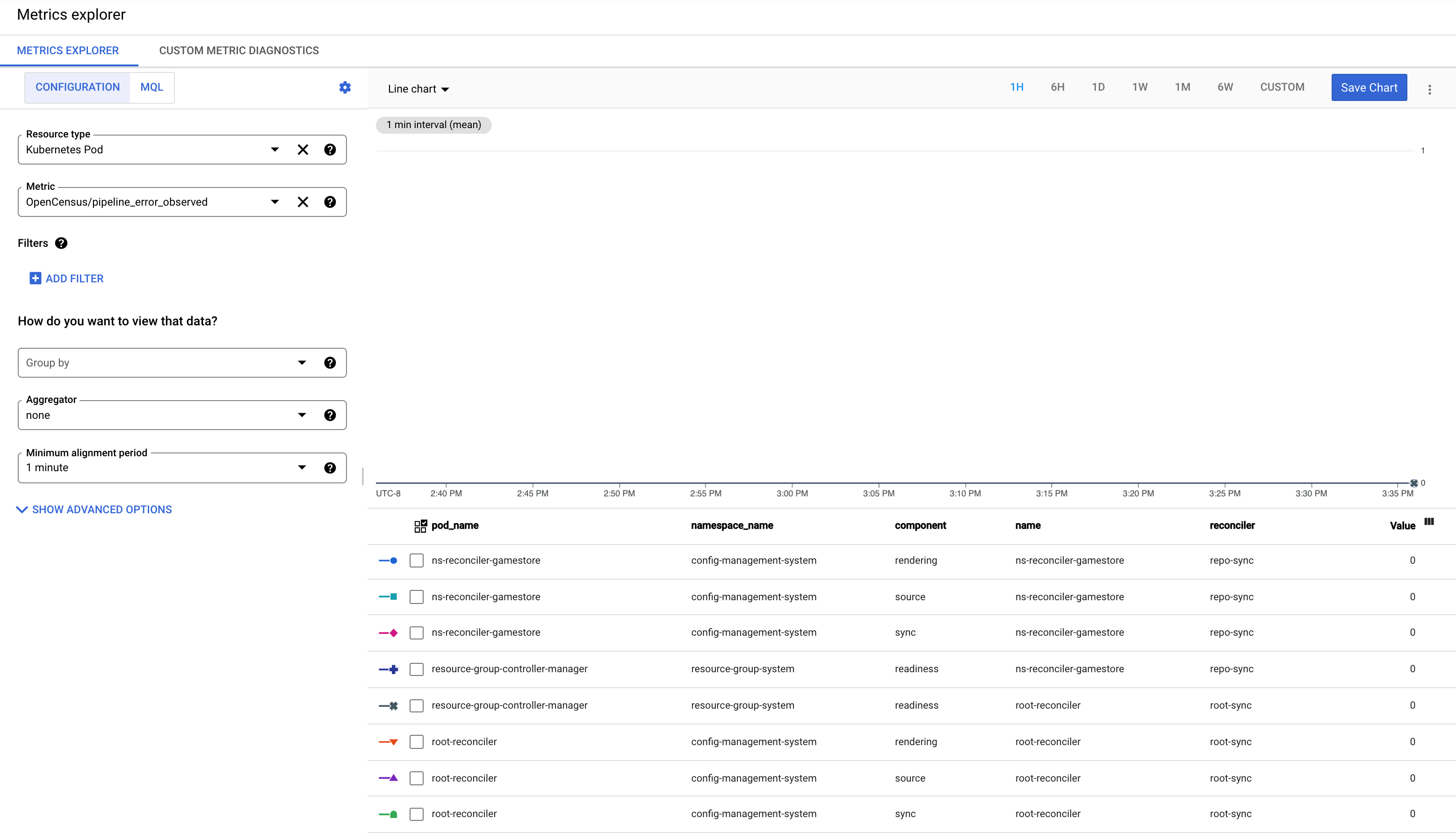
Lorsque le dernier commit échoue l'affichage automatisé, la métrique avec le composant
renderingest observée avec la valeur 1.En cas d'erreur lors du dernier commit ou si le dernier commit contient une configuration non valide, la métrique du composant
sourceest observée avec la valeur 1.Lorsqu'une ressource ne peut pas être appliquée au cluster, la métrique avec le composant
syncest observée avec la valeur 1.Lorsqu'une ressource est appliquée, mais ne parvient pas à atteindre son état souhaité, la métrique avec le composant
readinessest observée avec la valeur 1. Par exemple, un déploiement est appliqué au cluster, mais les pods correspondants ne sont pas créés correctement.
Étapes suivantes
- Découvrez comment surveiller les objets RootSync et RepoSync.
- Découvrez comment utiliser les SLI Config Sync.