Questa pagina fornisce un punto di partenza per aiutarti a pianificare e progettare le pipeline CI/CD GitOps per Kubernetes. GitOps, insieme a strumenti come Config Sync, offre vantaggi come una maggiore stabilità del codice, una migliore leggibilità e l'automazione.
GitOps è un approccio in rapida crescita per la gestione della configurazione di Kubernetes su larga scala. A seconda dei requisiti della pipeline CI/CD, sono disponibili molte opzioni per progettare e organizzare il codice dell'applicazione e di configurazione. Se conosci alcune best practice di GitOps, puoi creare un'architettura stabile, ben organizzata e sicura.
Questa pagina è rivolta ad amministratori, architetti e operatori che vogliono implementare GitOps nel proprio ambiente. Per scoprire di più sui ruoli comuni e sulle attività di esempio a cui facciamo riferimento nei Google Cloud contenuti, consulta Ruoli e attività utente comuni di GKE Enterprise.
Organizzare i repository
Quando configuri l'architettura GitOps, separa i repository in base ai tipi di file di configurazione archiviati in ciascun repository. A livello generale, potresti prendere in considerazione almeno quattro tipi di repository:
- Un repository di pacchetti per gruppi di configurazioni correlate.
- Un repository della piattaforma per la configurazione a livello di parco risorse per cluster e spazi dei nomi.
- Un repository di configurazione dell'applicazione.
- Un repository di codice dell'applicazione.
Il seguente diagramma mostra il layout di questi repository:
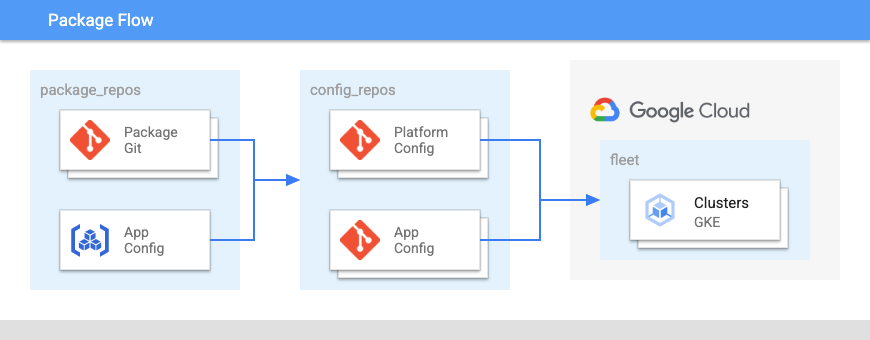
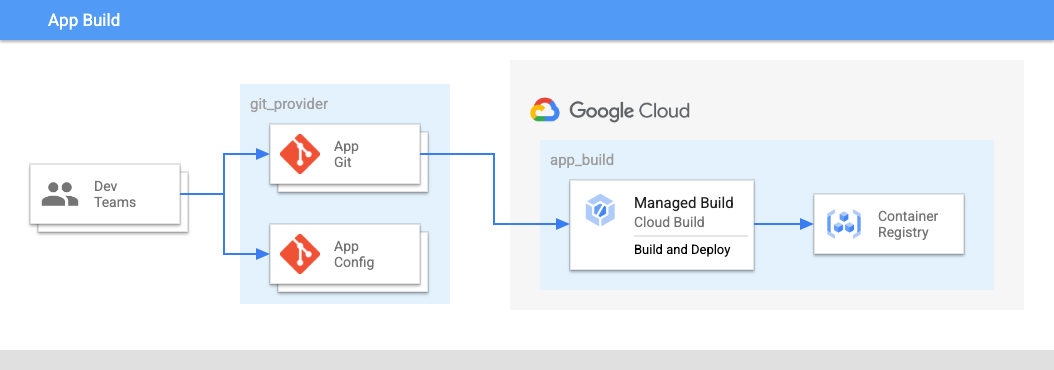
Nella Figura 2:
- I team di sviluppo eseguono il push del codice per le applicazioni e le relative configurazioni in un repository.
- Il codice di app e configurazioni viene archiviato nello stesso luogo e i team di applicazioni hanno il controllo su questi repository.
- I team di applicazioni eseguono il push del codice in una build.
Utilizzare un repository di pacchetti privato e centralizzato
Utilizza un repository centrale per i pacchetti pubblici o interni, ad esempio i grafici Helm,per aiutare i team a trovare i pacchetti. Ad esempio, se il repository è strutturato in modo logico o contiene un readme, l'utilizzo di repository di pacchetti privati e centralizzati può aiutare i team a trovare rapidamente le informazioni. Puoi utilizzare servizi come Artifact Registry o repository Git per organizzare il tuo repository centrale.
Ad esempio, il team della piattaforma della tua organizzazione può implementare criteri in base ai quali i team di applicazioni possono utilizzare i pacchetti solo dal repository centrale.
Puoi limitare le autorizzazioni di scrittura al repository a un numero ridotto di sviluppatori. Il resto dell'organizzazione può avere accesso in lettura. Ti consigliamo di implementare una procedura per promuovere i pacchetti nel repository centrale e di trasmettere gli aggiornamenti.
Sebbene la gestione di un repository centrale possa comportare un sovraccarico aggiuntivo, poiché qualcuno deve occuparsi della manutenzione del repository centrale e aggiunge un'ulteriore procedura per i team di applicazioni, questo approccio presenta molti vantaggi:
- Un team centrale può scegliere di aggiungere pacchetti pubblici con una cadenza definita, il che consente di evitare interruzioni a causa della connettività o del tasso di abbandono a monte.
- Una combinazione di revisori automatici e umani può verificare la presenza di problemi nei pacchetti prima di renderli disponibili a livello generale.
- Il repository centrale consente ai team di scoprire cosa è in uso e supportato. Ad esempio, i team possono trovare il deployment Redis standard memorizzato nel repository centrale.
- Puoi automatizzare le modifiche ai pacchetti a monte per assicurarti che soddisfino gli standard interni, come i valori predefiniti, l'aggiunta di etichette e i repository di immagini dei contenitori.
Creare repository WET
WET sta per "Write Everything Twice" (Scrivi tutto due volte). È in contrasto con DRY, che sta per "Don't Repeat Yourself" (Non ripeterti). Questi approcci rappresentano due diversi tipi di file di configurazione:
- Configurazioni DRY, in cui un singolo file di configurazione viene sottoposto a un'azione di trasformazione per compilare i campi con valori diversi per ambienti diversi. Ad esempio, potresti avere una configurazione del cluster condivisa che viene compilata con una regione diversa o impostazioni di sicurezza diverse per diversi ambienti.
- Configurazioni WET (o a volte "completamente idratate"), in cui ogni file di configurazione rappresenta lo stato finale.
Sebbene i repository WET possano portare a alcuni file di configurazione ripetuti, hanno i seguenti vantaggi per un flusso di lavoro GitOps:
- È più facile per i membri del team esaminare le modifiche.
- Non è richiesta alcuna elaborazione per visualizzare lo stato previsto di un file di configurazione.
Esegui test in precedenza durante la convalida delle configurazioni
Attendere che Config Sync inizi la sincronizzazione per verificare la presenza di problemi può creare commit Git non necessari e un lungo ciclo di feedback. È possibile trovare molti problemi
prima che una configurazione venga applicata a un cluster utilizzando le funzioni di convalida kpt.
Anche se devi aggiungere strumenti e logica aggiuntivi alla procedura di commit, i test prima di applicare le configurazioni hanno i seguenti vantaggi:
- La visualizzazione delle modifiche alla configurazione in una richiesta di modifica può contribuire a evitare che gli errori vengano inseriti in un repository.
- Riduce l'impatto dei problemi nelle configurazioni condivise.
Utilizza le cartelle anziché i rami
Utilizza le cartelle per le varianti dei file di configurazione anziché i rami. Con le directory, puoi utilizzare il comando tree per visualizzare le varianti. Con i branch, non puoi capire se il delta tra un branch di produzione e uno di sviluppo è una
modifica imminente della configurazione o una differenza permanente tra ciò che dovrebbero essere gli ambienti
prod e dev.
Lo svantaggio principale di questo approccio è che l'utilizzo delle cartelle non ti consente di promuovere modifiche alla configurazione utilizzando una richiesta di modifica per gli stessi file. Tuttavia, l'utilizzo di cartelle invece di branch presenta i seguenti vantaggi:
- La scoperta delle cartelle è più facile rispetto ai rami.
- Eseguire un confronto tra cartelle è possibile con molti strumenti a riga di comando e GUI, mentre la differenza tra i branch è meno comune al di fuori dei fornitori di Git.
- Distinguere tra differenze permanenti e differenze non promosse è più facile con le cartelle.
- Puoi implementare le modifiche in più cluster e spazi dei nomi in una sola richiesta di modifica, mentre i branch richiedono più richieste di modifica per branch diversi.
Riduci al minimo l'utilizzo di ClusterSelectors
ClusterSelectors ti consente di applicare determinate parti di una configurazione a un sottoinsieme di cluster. Invece di configurare un oggetto RootSync o RepoSync,
puoi modificare la risorsa applicata o aggiungere etichette ai cluster. Sebbene si tratti di un modo semplice per aggiungere tratti a un cluster, poiché il numero di ClusterSelectors aumenta nel tempo, può diventare complicato comprendere lo stato finale del cluster.
Poiché Config Sync ti consente di sincronizzare più oggetti RootSync e RepoSync contemporaneamente, puoi aggiungere la configurazione pertinente a un repository separato e poi sincronizzarla con i cluster che preferisci. In questo modo è più facile comprendere lo stato finale del cluster e puoi assemblare le configurazioni per il cluster in una cartella anziché applicare queste decisioni di configurazione direttamente sul cluster.
Evitare di gestire i job con Config Sync
Nella maggior parte dei casi, i job e altre attività situazionali devono essere gestiti da un servizio che si occupa della loro gestione del ciclo di vita. A questo punto puoi gestire il servizio con Config Sync anziché con i job stessi.
Sebbene Config Sync possa applicare i job per te, questi non sono adatti per le distribuzioni GitOps per i seguenti motivi:
Campi immutabili: molti campi Job sono immutabili. Per modificare un campo immutabile, l'oggetto deve essere eliminato e ricreato. Tuttavia, Config Sync non elimina l'oggetto, a meno che non lo rimuovi dall'origine.
Esecuzione involontaria dei job: se sincronizzi un job con Config Sync e poi il job viene eliminato dal cluster, Config Sync considera che si sia verificato un allontanamento dallo stato scelto e lo ricrea. Se specifichi un TTL (time to live) del job, Config Sync elimina automaticamente il job, lo ricrea e lo riavvia finché non lo elimini dall'origine attendibile.
Problemi di riconciliazione: in genere, Config Sync attende che gli oggetti vengano riconciliati dopo l'applicazione. Tuttavia, i job vengono considerati riconciliati quando hanno iniziato a essere eseguiti. Ciò significa che Config Sync non attende il completamento del job prima di continuare ad applicare altri oggetti. Tuttavia, se il job non va a buon fine in un secondo momento, viene considerata una mancata riconciliazione. In alcuni casi, questo può bloccare la sincronizzazione di altre risorse e causare errori fino a quando non risolvi il problema. In altri casi, la sincronizzazione potrebbe riuscire e solo la riconciliazione potrebbe non andare a buon fine.
Per questi motivi, non consigliamo di sincronizzare i job con Config Sync.
Utilizzare repository non strutturati
Config Sync supporta due strutture per organizzare un repository: non strutturata e gerarchica.
L'approccio non strutturato è consigliato perché consente di organizzare un repository nel modo più pratico per te.
I repository gerarchici, invece, applicano una struttura specifica come le definizioni di risorse personalizzate (CRD) in una directory cluster.
Ciò può causare problemi quando devi condividere le configurazioni. Ad esempio, se un team pubblica un pacchetto contenente un CRD, un altro team che deve utilizzare quel pacchetto dovrà spostare il CRD in una directory cluster, aggiungendo ulteriore overhead al processo.
L'utilizzo di un repository non strutturato semplifica notevolmente la condivisione e il riutilizzo dei pacchetti di configurazione. Tuttavia, senza una procedura o linee guida definite per l'organizzazione dei repository, le strutture dei repository possono variare da un team all'altro, il che può complicare l'implementazione di strumenti per l'intero parco.
Per scoprire come convertire un repository gerarchico, consulta Convertire un repository gerarchico in un repository non strutturato.
Repository di codice e configurazione separati
Quando esegui l'upgrade di un monorepo, è necessaria una build specifica per ogni cartella. Le autorizzazioni e le preoccupazioni per le persone che lavorano al codice e alla configurazione del cluster sono in genere diverse.
La separazione dei repository di codice e configurazione presenta i seguenti vantaggi:
- Evita i commit "a ciclo continuo". Ad esempio, l'esecuzione di commit in un repository di codice potrebbe attivare una richiesta di CI, che potrebbe produrre un'immagine, che a sua volta richiede un commit del codice.
- Il numero di commit richiesti può diventare un onere per i membri del team che contribuiscono.
- Puoi utilizzare autorizzazioni diverse per gli utenti che lavorano al codice dell'applicazione e alla configurazione del cluster.
La separazione dei repository di codice e configurazione presenta i seguenti svantaggi:
- Riduce il rilevamento della configurazione dell'applicazione perché non si trova nello stesso repository del codice dell'applicazione.
- La gestione di molti repository può richiedere molto tempo.
Utilizza repository separati per isolare le modifiche
Quando esegui l'upgrade di un monorepo, sono necessarie autorizzazioni diverse per le varie cartelle. Per questo motivo, la separazione dei repository consente di definire confini di sicurezza tra sicurezza, piattaforma e configurazione dell'applicazione. È inoltre consigliabile separare i repository di produzione e non di produzione.
Anche se la gestione di molti repository può essere un'attività impegnativa, isolare diversi tipi di configurazione in repository diversi presenta i seguenti vantaggi:
- In un'organizzazione con team di piattaforma, sicurezza e applicazioni, la frequenza delle modifiche e delle autorizzazioni è diversa.
- Le autorizzazioni rimangono a livello di repository. I file
CODEOWNERSconsentono alle organizzazioni di limitare l'autorizzazione di scrittura, consentendo al contempo l'autorizzazione di lettura. - Config Sync supporta più sincronizzazioni per spazio dei nomi, il che può avere un effetto simile all'utilizzo di file di origine da più repository.
Bloccare le versioni dei pacchetti
Indipendentemente dall'utilizzo di Helm o Git, devi bloccare la versione del pacchetto di configurazione su un valore che non venga spostato accidentalmente in avanti senza un rollout esplicito.
Sebbene questo aggiunga ulteriori controlli ai rollout quando viene aggiornata una configurazione condivisa, riduce il rischio che gli aggiornamenti condivisi abbiano un impatto maggiore del previsto.
Utilizzare Workload Identity Federation per GKE
Puoi attivare Workload Identity Federation for GKE sui cluster GKE, in modo che i carichi di lavoro Kubernetes possano accedere ai servizi Google in modo sicuro e gestibile.
Sebbene alcuni servizi nonGoogle Cloud , come GitHub e GitLab, non supportino la federazione delle identità per i carichi di lavoro per GKE, ti consigliamo di utilizzare la federazione delle identità per i carichi di lavoro per GKE ogni volta che è possibile, grazie all'aumento della sicurezza e alla riduzione della complessità della gestione di segreti e password.