Exemplos de utilização
Esta arquitetura de referência de disponibilidade é adequada para os seguintes exemplos de utilização:
- Aplicações críticas para a empresa que requerem um RTO e um RPO mais baixos.
- Quer implementar uma réplica noutra zona ou nó que ofereça elevada disponibilidade para as suas bases de dados e proteja contra falhas de instâncias, servidores e zonas.
- Quer proteção contra erros do utilizador e danos nos dados (através de cópias de segurança).
Como funciona a arquitetura de referência
A disponibilidade melhorada adiciona-se à disponibilidade padrão adicionando instâncias de réplica de leitura na região para ativar a alta disponibilidade (HA) que reduz o objetivo de tempo de recuperação (RTO). Esta abordagem também reduz o objetivo de ponto de recuperação (RPO) ao permitir a transmissão em fluxo de alterações transacionais para a réplica.
A alta disponibilidade no AlloyDB Omni usa, pelo menos, duas instâncias da base de dados. Uma instância funciona como a base de dados principal, suportando operações de leitura e escrita. As restantes instâncias funcionam como réplicas de leitura, operando num modo só de leitura.
Seguem-se conceitos importantes de HA:
- A comutação por falha é o procedimento durante uma interrupção não planeada em que a instância principal falha ou fica indisponível, e a réplica em espera é ativada para assumir o modo principal (leitura/escrita). Este processo chama-se promoção. Normalmente, nestes cenários, quando o servidor ou a base de dados principal volta a ficar online, a base de dados tem de ser reconstruída e, em seguida, tem de atuar como um servidor em espera. Para oferecer um tempo de atividade elevado, existem mecanismos para tornar as comutações por falha automáticas.
- Uma mudança, também conhecida como inversão de funções, é um procedimento usado para mudar os modos entre a base de dados principal e uma das bases de dados de reserva, de modo que a principal se torna a de reserva e a de reserva se torna a principal. As comutações ocorrem normalmente de forma controlada e gradual, e podem ser iniciadas por vários motivos, por exemplo, para permitir o tempo de inatividade e a aplicação de patches na antiga base de dados principal. As comutações suaves têm de permitir uma futura comutação de volta sem necessidade de voltar a instanciar a nova espera ou outros aspetos da configuração de replicação.
Opções de alta disponibilidade
Em ambientes do Kubernetes, para suportar a HA, pode implementar o AlloyDB Omni através dos operadores do AlloyDB Omni Kubernetes. Para mais informações, consulte o artigo Faça a gestão da elevada disponibilidade no Kubernetes.
| Nota: o Patroni e o HAProxy são ferramentas de terceiros não comerciais e são compatíveis com o AlloyDB Omni. |
|---|
Recomendamos que tenha, pelo menos, duas bases de dados em espera para que a perda de uma base de dados não afete a elevada disponibilidade do cluster. Nesse modo, tem, pelo menos, um par de HA em caso de comutação por falha ou durante qualquer manutenção planeada de um nó.
Para planear o tamanho e o formato da sua implementação do AlloyDB Omni, consulte o artigo Planeie a instalação do AlloyDB Omni numa VM.
Balanceadores de carga
Outro mecanismo importante que ajuda a simplificar os procedimentos de comutação e tolerância a falhas é a presença de um equilibrador de carga.
O operador do Kubernetes implementa o seu próprio equilibrador de carga, que se comporta de forma semelhante, criando um serviço para a base de dados que aponta para o equilibrador de carga para tornar este processo transparente para o utilizador.
Alta disponibilidade
As bases de dados de réplicas de leitura implementadas numa região oferecem alta disponibilidade se a base de dados principal falhar. Quando ocorre uma falha na base de dados principal, a base de dados de reserva é promovida para substituir a principal e a aplicação continua com pouca ou nenhuma indisponibilidade.
Geralmente, é uma boa prática realizar verificações anuais ou semestrais regulares sob a forma de comutações para garantir que todas as aplicações que dependem destas bases de dados continuam a conseguir estabelecer ligação e responder num período adequado.
A proteção ao nível da zona pode ser alcançada através de qualquer um dos tipos de implementação, colocando uma das réplicas de leitura em espera numa zona de disponibilidade diferente da base de dados principal.
Uma vantagem adicional de ter réplicas de leitura é a capacidade de transferir operações só de leitura para as bases de dados em espera, que podem atuar como bases de dados de relatórios com dados atualizados. Esta abordagem reduz a carga e a sobrecarga no primário de leitura/escrita.
Configuração de cópias de segurança e alta disponibilidade
As réplicas de leitura podem ser configuradas em várias zonas que oferecem elevada disponibilidade. Embora ofereçam um RTO e um RPO baixos, não protegem contra determinadas interrupções, como a corrupção lógica de dados, como eliminações acidentais de tabelas ou atualizações de dados incorretas. Por isso, devem ser feitas cópias de segurança regulares além da configuração de HA. Consulte a documentação sobre a arquitetura de disponibilidade padrão para ver detalhes.
A Figura 1 mostra uma configuração de HA recomendada com duas bases de dados de reserva de réplicas de leitura em duas zonas de disponibilidade diferentes.
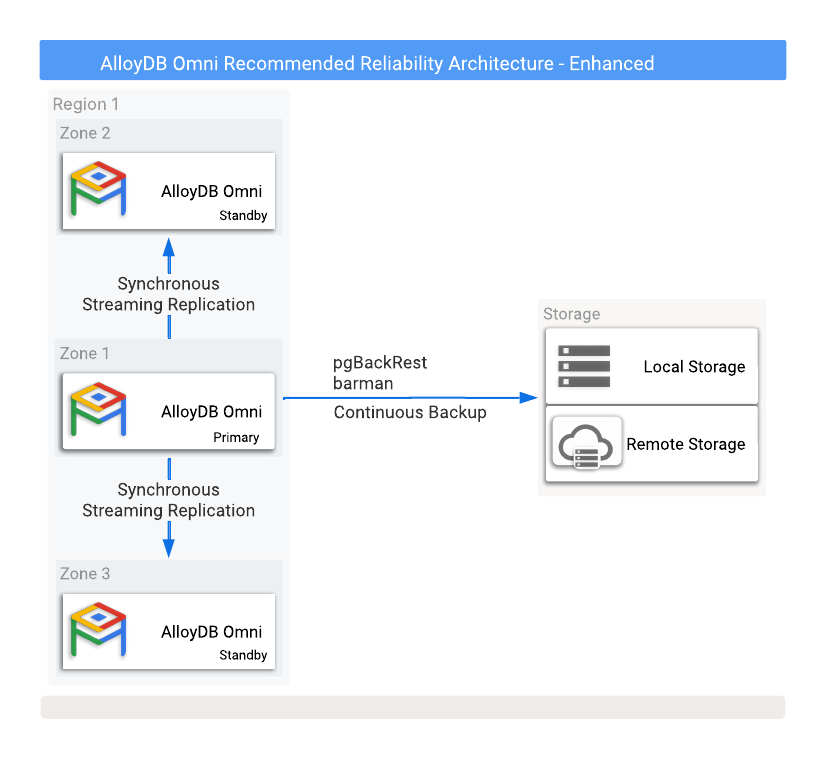
Figura 1. AlloyDB Omni com opções de cópias de segurança e alta disponibilidade.
Para se proteger contra a perda de dados se a instância principal falhar, é necessário configurar a replicação no modo síncrono. Embora este método ofereça uma forte proteção de dados, pode afetar o desempenho da base de dados principal, uma vez que todas as confirmações têm de ser escritas na base de dados principal e em todas as bases de dados de reserva sincronizadas. Uma ligação de rede de baixa latência entre estas instâncias da base de dados é crucial para esta configuração.
Implementações de HA do Kubernetes
Para implementações do Kubernetes, pode adicionar um modo de espera de comutação por falha ou réplicas de leitura para permitir a falha da base de dados principal, usando algumas alterações e adições básicas de atributos ao ficheiro de implementação do AlloyDB Omni. Pode configurar uma réplica de standby de comutação por falha e só de leitura, e o operador encarrega-se do aprovisionamento e da publicação do serviço. O operador também automatiza muitos dos processos de HA, como a reconstrução de bases de dados em espera após uma comutação por falha e a utilização dos mecanismos de recuperação incorporados no motor do Kubernetes do AlloyDB Omni.
Numa implementação do Kubernetes, a disponibilidade da infraestrutura e das aplicações beneficia das funcionalidades integradas do Kubernetes que resolvem falhas de nós e pods, incluindo o seguinte:
- kube-controller-manager
- Parâmetros como
node-status-update-frequency,node-monitor-period,node-monitor-grace-periodepod-eviction-timeout.
Além da proteção integrada, o operador expõe os seguintes parâmetros para influenciar a deteção de uma primária ou uma secundária com falhas:
healthcheckPeriodSeconds: o tempo entre as verificações de funcionamento. A predefinição são 30 segundos.autoFailoverTriggerThreshold: o número de verificações de estado com falhas consecutivas antes de iniciar a comutação por falha. A predefinição é 3.
Para mais informações, consulte o artigo Faça a gestão da elevada disponibilidade no Kubernetes.
Implementação
Quando escolhe uma arquitetura de referência de disponibilidade, tenha em atenção as seguintes vantagens, limitações e alternativas.
Vantagens
- Protege contra falhas de instâncias.
- Protege contra falhas do servidor.
- Protege contra falhas de zonas.
- O RTO foi reduzido drasticamente em relação à disponibilidade padrão.
Limitações
- Sem proteção adicional para desastres regionais.
- Potencial impacto no desempenho do servidor principal devido à replicação síncrona.
- A configuração da transmissão em fluxo WAL do PostgreSQL no modo síncrono oferece zero perda de dados (
RPO=0) durante o funcionamento normal ou as comutações por falha típicas. No entanto, esta abordagem não protege contra a perda de dados em situações específicas de falha dupla, como quando todas as instâncias de espera são perdidas ou ficam inacessíveis a partir da instância principal, e isto é imediatamente seguido de um reinício da instância principal.
Alternativas
- A arquitetura de disponibilidade padrão para opções de cópia de segurança e recuperação.
- A arquitetura de disponibilidade premium para recuperação de desastres ao nível da região, réplicas de leitura adicionais e alcance de recuperação de desastres expandido.
O que se segue?
- Vista geral da arquitetura de referência de disponibilidade do AlloyDB Omni.
- AlloyDB Omni Standard Availability.
- Disponibilidade do AlloyDB Omni Premium.
- Arquitetura de alta disponibilidade para o AlloyDB Omni para PostgreSQL.
- Faça a gestão da elevada disponibilidade no Kubernetes.