Casos prácticos
Esta arquitectura de referencia de disponibilidad es adecuada para los siguientes casos prácticos:
- Aplicaciones esenciales para el negocio que requieren un RTO y un RPO más bajos.
- Quieres implementar una réplica en otra zona o nodo que proporcione alta disponibilidad a tus bases de datos y las proteja frente a fallos de instancias, servidores y zonas.
- Quieres protegerte frente a errores de los usuarios y a la corrupción de datos (mediante copias de seguridad).
Cómo funciona la arquitectura de referencia
La disponibilidad mejorada se suma a la disponibilidad estándar añadiendo instancias de réplica de lectura en la región para habilitar la alta disponibilidad (HA), que reduce el objetivo de tiempo de recuperación (RTO). Este enfoque también reduce el objetivo de punto de recuperación (RPO) al permitir que se transmitan los cambios transaccionales a la réplica.
La alta disponibilidad de AlloyDB Omni utiliza al menos dos instancias de base de datos. Una instancia funciona como base de datos principal y admite operaciones de lectura y escritura. Las instancias restantes actúan como réplicas de lectura y operan en modo de solo lectura.
Estos son algunos conceptos importantes sobre la alta disponibilidad:
- La conmutación por error es el procedimiento que se lleva a cabo durante una interrupción no planificada en la que la instancia principal falla o deja de estar disponible, y se activa la réplica de espera para asumir el modo principal (lectura y escritura). Este proceso se denomina promoción. Normalmente, en estos casos, cuando el servidor o la base de datos principales vuelven a estar online, la base de datos debe reconstruirse y, después, actuar como reserva. Para ofrecer un tiempo de actividad elevado, se han implementado mecanismos para automatizar las conmutaciones por error.
- Un cambio, también conocido como inversión de roles, es un procedimiento que se usa para cambiar los modos entre la base de datos principal y una de las bases de datos de reserva, de forma que la principal se convierta en la de reserva y la de reserva se convierta en la principal. Los cambios suelen producirse de forma controlada y gradual, y pueden iniciarse por diversos motivos, como permitir el tiempo de inactividad y la aplicación de parches de la antigua base de datos principal. Los cambios a otro servidor deben permitir volver al servidor original sin necesidad de volver a crear una instancia del nuevo servidor de reserva ni de otros aspectos de la configuración de la réplica.
Opciones de alta disponibilidad
En entornos de Kubernetes, para admitir la alta disponibilidad, puedes desplegar AlloyDB Omni con operadores de AlloyDB Omni Kubernetes. Para obtener más información, consulta Gestionar la alta disponibilidad en Kubernetes.
| Nota: Patroni y HAProxy son herramientas de terceros no comerciales y compatibles con AlloyDB Omni. |
|---|
Te recomendamos que tengas al menos dos bases de datos de reserva para que la pérdida de una de ellas no afecte a la alta disponibilidad del clúster. En ese modo, tienes al menos un par de alta disponibilidad en caso de conmutación por error o durante cualquier mantenimiento planificado de un nodo.
Para planificar el tamaño y la forma de tu implementación de AlloyDB Omni, consulta Planificar la instalación de AlloyDB Omni en una VM.
Balanceadores de carga
Otro mecanismo importante que facilita los procedimientos de conmutación y de conmutación por error es la presencia de un balanceador de carga.
El operador de Kubernetes implementa su propio balanceador de carga, que se comporta de forma similar, creando un servicio para la base de datos que apunta al balanceador de carga para que el usuario no tenga que preocuparse por ello.
Alta disponibilidad
Las bases de datos de réplica de lectura implementadas en una región ofrecen alta disponibilidad si falla la base de datos principal. Cuando se produce un error en la base de datos principal, la base de datos de reserva se convierte en la principal y la aplicación continúa con poco o ningún tiempo de inactividad.
Por lo general, es recomendable realizar comprobaciones periódicas anuales o semestrales en forma de cambios para asegurarse de que todas las aplicaciones que dependen de estas bases de datos puedan seguir conectándose y respondiendo en un plazo adecuado.
La protección a nivel de zona se puede conseguir con cualquiera de los dos tipos de implementación colocando una de las réplicas de lectura de espera en una zona de disponibilidad diferente de la base de datos principal.
Otra ventaja de tener réplicas de lectura es la posibilidad de derivar las operaciones de solo lectura a las bases de datos de reserva, que pueden actuar como bases de datos de informes con datos actualizados. Este enfoque reduce la carga y la sobrecarga de la instancia principal de lectura y escritura.
Configuración de copias de seguridad y alta disponibilidad
Las réplicas de lectura se pueden configurar en varias zonas que proporcionen alta disponibilidad. Aunque proporcionan un tiempo de recuperación y un punto de recuperación bajos, no protegen frente a determinadas interrupciones, como la corrupción lógica de datos (por ejemplo, la eliminación accidental de tablas o las actualizaciones de datos incorrectas). Por lo tanto, deben hacerse copias de seguridad periódicas además de la configuración de alta disponibilidad. Para obtener más información, consulta la documentación sobre la arquitectura de disponibilidad estándar.
En la figura 1 se muestra una configuración de alta disponibilidad recomendada con dos bases de datos de réplica de lectura en espera en dos zonas de disponibilidad diferentes.
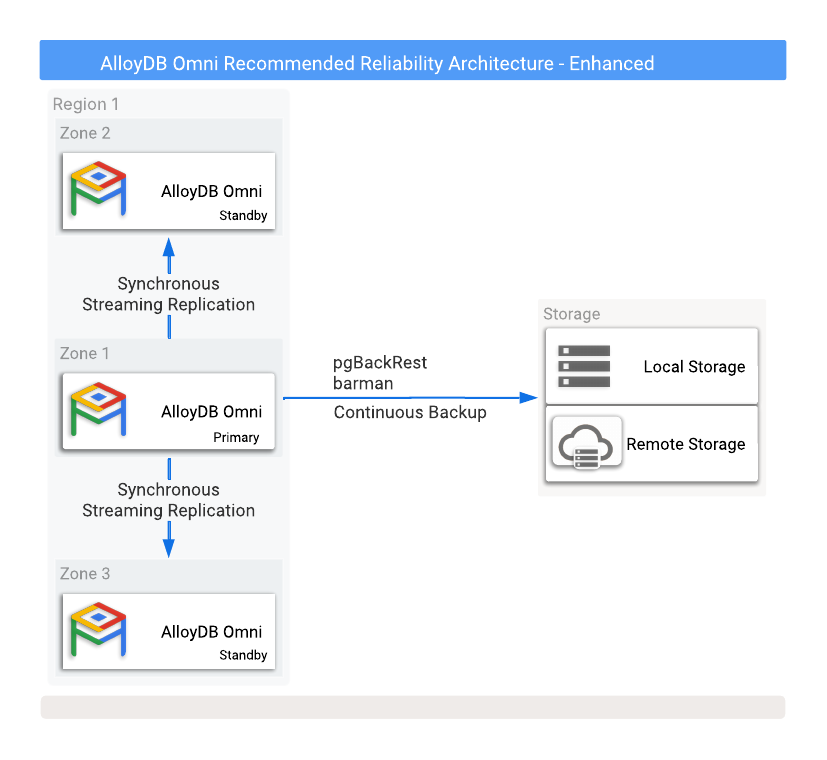
Imagen 1. AlloyDB Omni con opciones de copias de seguridad y alta disponibilidad.
Para protegerte frente a la pérdida de datos si falla la instancia principal, es necesario configurar la replicación en modo síncrono. Aunque este método proporciona una protección de datos sólida, puede afectar al rendimiento de la base de datos principal, ya que todas las confirmaciones deben escribirse en la base de datos principal y en todas las bases de datos de espera sincronizadas. Para esta configuración, es fundamental que haya una conexión de red de baja latencia entre estas instancias de base de datos.
Despliegues de alta disponibilidad de Kubernetes
En el caso de los despliegues de Kubernetes, si cambias y añades algunos atributos básicos al archivo de despliegue de AlloyDB Omni, puedes añadir réplicas de lectura o de espera ante fallos para permitir que se produzcan fallos en la base de datos principal. Se puede configurar una réplica de espera de conmutación por error y de solo lectura, y el operador se encarga de aprovisionar y publicar el servicio. El operador también automatiza muchos de los procesos de alta disponibilidad, como la reconstrucción de bases de datos de reserva después de una conmutación por error, y utiliza los mecanismos de reparación integrados en el motor de Kubernetes de AlloyDB Omni.
En un despliegue de Kubernetes, la disponibilidad de la infraestructura y las aplicaciones se beneficia de las funciones integradas de Kubernetes que se encargan de los errores de nodos y pods, entre las que se incluyen las siguientes:
- kube-controller-manager
- Parámetros como
node-status-update-frequency,node-monitor-period,node-monitor-grace-period, ypod-eviction-timeout.
Además de la protección integrada, el operador expone los siguientes parámetros para influir en la detección de un elemento principal o de reserva que ha fallado:
healthcheckPeriodSeconds: el tiempo entre comprobaciones del estado. El valor predeterminado es 30 segundos.autoFailoverTriggerThreshold: número de comprobaciones de estado fallidas consecutivas antes de iniciar la conmutación por error. y el predeterminado es 3.
Para obtener más información, consulta Gestionar la alta disponibilidad en Kubernetes.
Implementación
Cuando elijas una arquitectura de referencia de disponibilidad, ten en cuenta las siguientes ventajas, limitaciones y alternativas.
Ventajas
- Protege frente a fallos de instancias.
- Protege frente a fallos del servidor.
- Protege frente a fallos de zona.
- El tiempo de recuperación tras un fallo se reduce drásticamente en comparación con la disponibilidad estándar.
Limitaciones
- No hay protección adicional en caso de desastres regionales.
- Posible impacto en el rendimiento de la instancia principal debido a la replicación síncrona.
- Configurar la transmisión de WAL de PostgreSQL en modo síncrono ofrece cero pérdida de datos (
RPO=0) durante el funcionamiento normal o las conmutaciones por error típicas. Sin embargo, este enfoque no protege contra la pérdida de datos en situaciones específicas de doble fallo, como cuando se pierden todas las instancias de espera o no se puede acceder a ellas desde la instancia principal, y a continuación se reinicia la instancia principal.
Alternativas
- La arquitectura de disponibilidad estándar para las opciones de copia de seguridad y recuperación.
- La arquitectura de disponibilidad premium para la recuperación tras fallos a nivel de región, las réplicas de lectura adicionales y la cobertura ampliada de la recuperación tras fallos.
Siguientes pasos
- Descripción general de la arquitectura de referencia de disponibilidad de AlloyDB Omni
- Disponibilidad estándar de AlloyDB Omni.
- Disponibilidad de AlloyDB Omni Premium.
- Arquitectura de alta disponibilidad de AlloyDB Omni para PostgreSQL.
- Gestionar la alta disponibilidad en Kubernetes.