Casos prácticos
Esta arquitectura de referencia admite los siguientes casos prácticos:
- Tienes bases de datos que pueden tolerar cierto tiempo de inactividad y pérdida de datos desde la última copia de seguridad.
- Quieres proteger tu base de datos de AlloyDB Omni frente a errores de los usuarios, corrupción o fallos físicos a nivel de base de datos (en lugar de capturas de servidor o de imagen de VM).
- Quieres poder recuperar tu base de datos in situ o de forma remota, posiblemente hasta un momento determinado.
Cómo funciona la arquitectura de referencia
La arquitectura de referencia de disponibilidad estándar abarca la copia de seguridad y la recuperación de tus bases de datos de AlloyDB Omni, tanto si se ejecutan como una instancia independiente en un servidor host, como una máquina virtual (Instalar AlloyDB Omni) o en un clúster de Kubernetes (Instalar AlloyDB Omni en Kubernetes).
Aunque la disponibilidad estándar es una implementación básica y minimiza el hardware o los servicios adicionales necesarios, el objetivo de tiempo de recuperación (RTO) aumenta a medida que la base de datos se hace más grande. Cuantos más datos haya que incluir en la copia de seguridad, más tiempo se tardará en restaurar y recuperar la base de datos. La pérdida de datos depende del tipo de copia de seguridad. Si solo se crean copias de seguridad de los archivos de datos periódicamente, cuando los restaure, perderá los datos que se hayan creado desde la última copia de seguridad.
Reducir el RPO
La función de archivado continuo de PostgreSQL te permite conseguir un objetivo de punto de recuperación (RPO) bajo y habilitar la recuperación a un momento dado mediante copias de seguridad. Este proceso implica archivar archivos de registro de escritura anticipada (WAL) y transmitir datos WAL, posiblemente a una ubicación de almacenamiento remota.
Si los archivos WAL solo se archivan cuando están llenos o a intervalos específicos, una pérdida completa de la base de datos (incluidos los archivos WAL actuales) restringe la recuperación al último archivo WAL archivado, lo que significa que el objetivo de punto de recuperación (RPO) debe tener en cuenta la posible pérdida de datos. Por el contrario, la transferencia continua de datos WAL maximiza la pérdida de datos cero.
Cuando hagas copias de seguridad continuas, podrás restaurar a un momento dado. La recuperación a un momento dado permite restaurar un estado anterior a un error, como la eliminación accidental de una tabla o actualizaciones incorrectas por lotes. Sin embargo, este método de recuperación afecta al objetivo de punto de recuperación (RPO), a menos que se utilice una base de datos auxiliar temporal.
Estrategias de copia de seguridad
Puedes configurar copias de seguridad a nivel de PostgreSQL de AlloyDB Omni para que se almacenen en un almacenamiento local o remoto. Aunque el almacenamiento local puede ser más rápido para crear copias de seguridad y recuperarlas, el almacenamiento remoto suele ser más robusto para gestionar los fallos cuando falla un host o una VM completos.
Copias de seguridad en entornos que no son de Kubernetes
En el caso de los despliegues que no sean de Kubernetes, puedes programar copias de seguridad con las siguientes herramientas de PostgreSQL:
- pgBackRest. Para obtener más información, consulta Configurar pgBackRest para AlloyDB Omni.
- Camarero. Para obtener más información, consulta Configurar Barman para AlloyDB Omni.
En el caso de bases de datos pequeñas, también puedes hacer una copia de seguridad lógica de la base de datos (con pg_dump para una sola base de datos o pg_dumpall para todo el clúster). Puedes restaurar la base de datos con pg_restore.
Copias de seguridad en Kubernetes con el operador de AlloyDB Omni
En el caso de AlloyDB Omni desplegado en un clúster de Kubernetes, puedes configurar copias de seguridad continuas mediante un plan de copias de seguridad para cada clúster de base de datos. Para obtener más información, consulta Crear copias de seguridad y restaurar en Kubernetes.
Puedes almacenar copias de seguridad de AlloyDB Omni de forma local o remota en Cloud Storage, incluidas las opciones que ofrecen los proveedores de servicios en la nube. Para obtener más información, consulta la figura 1, que muestra los posibles destinos de las copias de seguridad.
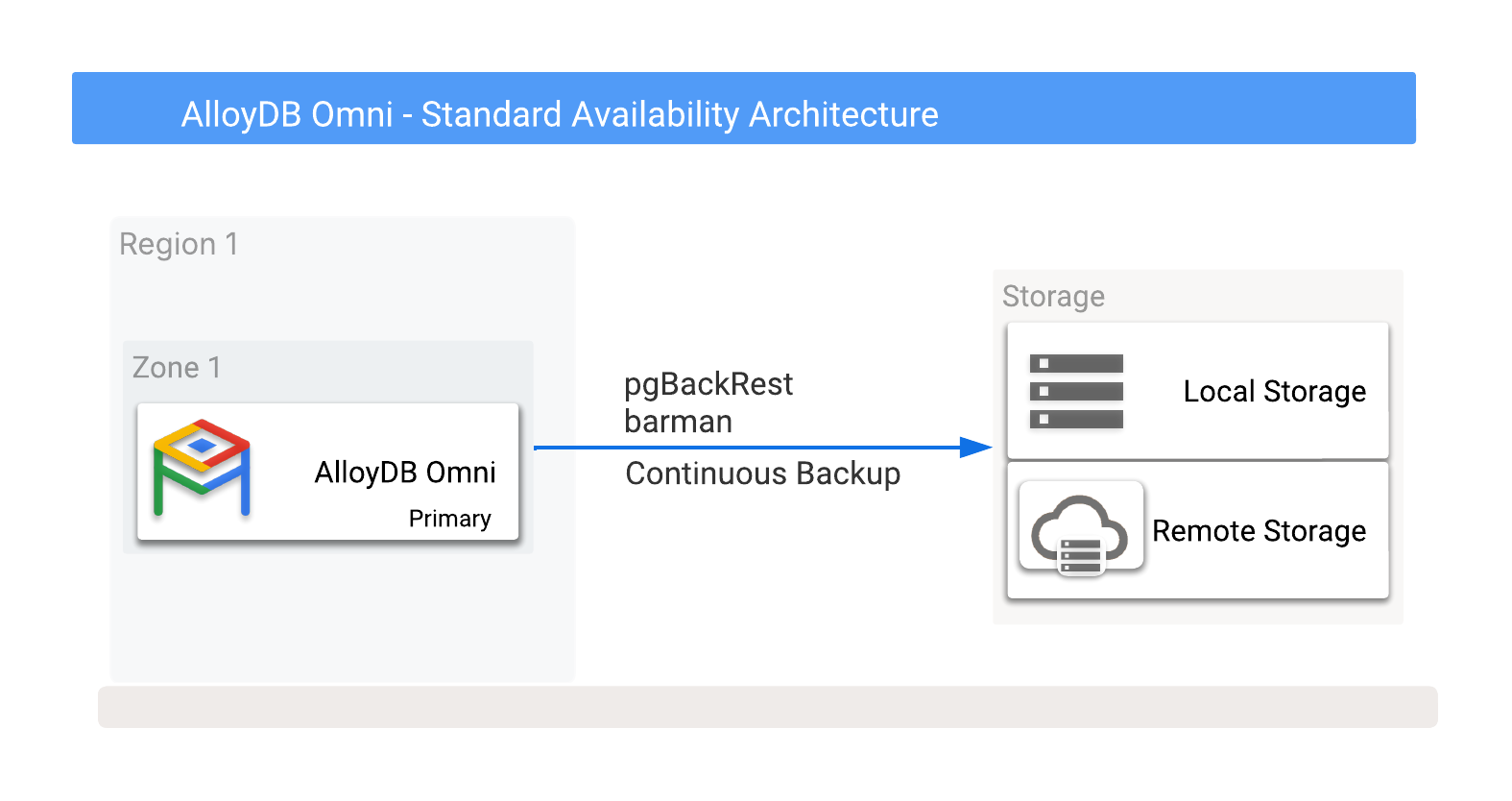
Imagen 1. AlloyDB Omni con opciones de copia de seguridad.
Las copias de seguridad se pueden crear en opciones de almacenamiento local o remoto. Las copias de seguridad locales suelen ser más rápidas porque solo dependen del rendimiento de E/S, mientras que las copias de seguridad remotas suelen tener una latencia más alta y un ancho de banda de red más bajo. Sin embargo, las copias de seguridad remotas ofrecen una protección óptima, incluidos los fallos de zona.
También puedes dividir las copias de seguridad locales en almacenamiento local o compartido. Aunque las opciones de almacenamiento local se ven afectadas por la falta de opciones de recuperación tras desastres cuando falla un host de base de datos, el almacenamiento compartido permite que ese almacenamiento se traslade a otro servidor y se utilice para la recuperación. Esto significa que el almacenamiento compartido puede ofrecer un tiempo de recuperación más rápido.
En las implementaciones de almacenamiento local y compartido, se pueden programar o crear manualmente copias de seguridad de los siguientes tipos:
- Copias de seguridad completas: copias de seguridad completas de todos los archivos de la base de datos necesarios para recuperar los datos.
- Copias de seguridad diferenciales: copias de seguridad de los cambios realizados en los archivos desde la última copia de seguridad completa.
- Copias de seguridad incrementales: copias de seguridad que solo incluyen los cambios realizados en los archivos desde la última copia de seguridad de cualquier tipo.
Recuperación a un momento dado
Las copias de seguridad continuas de los archivos de registro de escritura previa (WAL) de PostgreSQL admiten la recuperación a un momento dado. Si, después de un fallo, los archivos WAL están intactos y se pueden usar, puedes usarlos para recuperarte sin perder datos.
Para controlar la escritura de los archivos WAL, puede configurar los siguientes parámetros:
| Parámetro | Descripción |
|---|---|
|
Especifica la frecuencia con la que el escritor de WAL vacía el WAL en el disco, a menos que una transacción que se confirme de forma asíncrona active la escritura antes. El valor predeterminado es 200 ms. Al aumentar este valor, se reduce la frecuencia de escritura, pero puede aumentar la cantidad de datos que se pierden si el servidor falla. |
|
Especifica la cantidad de datos WAL que se pueden acumular antes de que el escritor de WAL fuerce un vaciado en el disco. El valor predeterminado es 1 MB. Si se define en cero, los datos de WAL siempre se escriben en el disco inmediatamente. |
|
Especifica si la confirmación devuelve una respuesta al usuario antes de que los datos de WAL se escriban en el disco. El ajuste predeterminado es on, lo que asegura que la transacción sea duradera. En otras palabras, la confirmación se ha escrito en el disco antes de devolver un código de éxito al usuario. Si se le asigna el valor off, habrá hasta tres veces wal_writer_delay antes de que la transacción se escriba en el disco. |
Monitorización del uso de WAL
Puedes usar los siguientes métodos para observar el uso de WAL:
| Método de observación | Descripción |
|---|---|
|
Esta vista estándar tiene las columnas wal_write
y wal_sync, que almacenan los recuentos del número de escrituras y sincronizaciones de WAL. Si el parámetro de configuración track_wal_io_timing
está habilitado, también se almacenarán wal_write_time
y wal_sync_time. Las instantáneas periódicas de esta vista pueden ayudar a mostrar la actividad de escritura y sincronización de WAL a lo largo del tiempo. |
pg_current_wal_lsn() |
Esta función devuelve la posición del número de secuencia de registro (LSN) actual que, cuando se asocia a una marca de tiempo y se recoge como instantáneas a lo largo del tiempo, puede proporcionar los bytes por segundo de WAL generados mediante la función pg_wal_lsn_diff(lsn1, lsn2).
Esta función es una métrica útil para comprender la tasa de transacciones y el rendimiento de los archivos WAL. |
Transmitir datos WAL a una ubicación remota
Cuando usas Barman, los datos WAL también se pueden configurar para que se transmitan en tiempo real a una ubicación remota para asegurar que haya poca o ninguna pérdida de datos durante la recuperación. A pesar de la transmisión en tiempo real, existe una pequeña probabilidad de perder transacciones confirmadas, ya que las escrituras de transmisión en el servidor Barman remoto son asíncronas de forma predeterminada. Sin embargo, es posible configurar la transmisión de WAL mediante el modo síncrono, que almacena el WAL y envía una respuesta de estado a la base de datos de origen. Ten en cuenta que este enfoque puede ralentizar las transacciones si tienen que esperar a que se complete esta escritura antes de continuar.
Frecuencias de las copias de seguridad
En la mayoría de los entornos, las copias de seguridad suelen programarse semanalmente. A continuación, se muestra una programación semanal de copias de seguridad habitual:
- Domingo: copia de seguridad completa
- Lunes y martes: copia de seguridad
- Miércoles: copia de seguridad diferencial
- Jueves y viernes: copia de seguridad incremental
- Sábado: copia de seguridad diferencial
Con esta programación habitual, una ventana de recuperación continua de una semana requiere espacio de almacenamiento para hasta tres copias de seguridad completas, además de las copias de seguridad incrementales o diferenciales necesarias. Este enfoque admite la recuperación en caso de fallo durante la copia de seguridad completa del domingo, y la recuperación de la base de datos debe extenderse al domingo anterior a que se inicie la copia de seguridad.
Para minimizar el RTO con un RPO potencialmente más alto, se pueden usar bases de datos adicionales en modo de recuperación continua. Esto implica reproducir copias de seguridad y actualizar continuamente el entorno secundario archivando y reproduciendo nuevos archivos WAL. El RPO real, que refleja la posible pérdida de datos, depende de la frecuencia de las transacciones, del tamaño del archivo WAL y del uso del streaming WAL.
Restaurar en un entorno que no sea de Kubernetes
En las implementaciones que no son de Kubernetes, para restaurar una base de datos de AlloyDB Omni, debes detener el contenedor Docker y, a continuación, restaurar los datos, o bien restaurar los datos en otra ubicación e iniciar una nueva instancia de Docker con esos datos restaurados. Una vez que se reinicie el contenedor, se podrá acceder a la base de datos con los datos restaurados.
Para obtener más información sobre las opciones de recuperación, consulta Restaurar un clúster de AlloyDB Omni con pgBackRest y Restaurar un clúster de AlloyDB Omni con Barman.
Restaurar en Kubernetes con el operador
Para restaurar una base de datos en Kubernetes, el operador ofrece la recuperación en el mismo clúster y espacio de nombres de Kubernetes a partir de una copia de seguridad con nombre o de un clon de un momento dado. Para clonar una base de datos en otro clúster de Kubernetes, usa pgBackRest. Para obtener más información, consulta los artículos Crear copias de seguridad y restaurar en Kubernetes y Descripción general de la clonación de un clúster de base de datos a partir de una copia de seguridad de Kubernetes.
Implementación
Cuando elijas una arquitectura de referencia de disponibilidad, ten en cuenta las siguientes ventajas, limitaciones y alternativas.
Ventajas
- Es fácil de usar y gestionar, y es adecuado para bases de datos no críticas con RTO y RPO flexibles.
- Se requiere un hardware adicional mínimo
- Siempre se necesitan copias de seguridad para un plan de recuperación tras fallos completo
- Se puede recuperar a cualquier momento dentro de la ventana de recuperación
Limitaciones
- Requisitos de almacenamiento que pueden ser mayores que la propia base de datos, en función de los requisitos de conservación.
- Puede tardar en recuperarse y puede dar lugar a un RTO más alto.
- Puede provocar la pérdida de algunos datos, en función de la disponibilidad de los datos WAL actuales después de un fallo de la base de datos, lo que podría afectar negativamente al RPO.
Alternativas
- Considera la arquitectura de disponibilidad mejorada o premium para mejorar la disponibilidad y las opciones de recuperación tras desastres.
Siguientes pasos
- Descripción general de la arquitectura de referencia de disponibilidad de AlloyDB Omni
- Disponibilidad mejorada de AlloyDB Omni.
- Disponibilidad de AlloyDB Omni Premium.
- Instala AlloyDB Omni en Kubernetes.
- Configura pgBackRest para AlloyDB Omni.
- Configura Barman para AlloyDB Omni.
- Crea copias de seguridad y restaura datos en Kubernetes.
- Restaurar un clúster de AlloyDB Omni con pgBackRest.
- Restaurar un clúster de AlloyDB Omni con Barman
- Crea copias de seguridad y restaura datos en Kubernetes.
- Clonar un clúster de base de datos a partir de una copia de seguridad de Kubernetes.