O AlloyDB Omni é um pacote de software de base de dados transferível que lhe permite implementar uma versão simplificada do AlloyDB para PostgreSQL no seu próprio ambiente de computação. O AlloyDB Omni e o serviço AlloyDB para PostgreSQL totalmente gerido no Google Cloud partilham os mesmos componentes principais. O AlloyDB for PostgreSQL usa uma camada de armazenamento nativa da nuvem que otimiza o desempenho do WAL, enquanto o AlloyDB Omni usa a mesma interface de sistema de ficheiros padrão usada pelo PostgreSQL.
A portabilidade do AlloyDB Omni permite-lhe executá-lo em muitos ambientes, incluindo os seguintes:
- Centros de dados
- Portáteis
- Instâncias de VM baseadas na nuvem
Exemplos de utilização do AlloyDB Omni
O AlloyDB Omni é adequado para os seguintes cenários:
- Precisa de uma versão escalável e de bom desempenho do PostgreSQL, mas não pode executar uma base de dados na nuvem devido a requisitos regulamentares ou de soberania dos dados.
- Precisa de uma base de dados que continue a ser executada mesmo quando está desligada da Internet.
- Para minimizar a latência, quer localizar a sua base de dados o mais perto possível dos seus utilizadores em termos geográficos.
- Quer uma forma de migrar de uma base de dados antiga, mas sem se comprometer com uma migração completa para a nuvem.
O AlloyDB Omni não inclui funcionalidades do AlloyDB para PostgreSQL que dependam da operação no Google Cloud. Se quiser atualizar o seu projeto para as funcionalidades de escalabilidade, segurança e disponibilidade totalmente geridas do AlloyDB for PostgreSQL, pode migrar os seus dados do AlloyDB Omni para um cluster do AlloyDB for PostgreSQL tal como faria com qualquer outra importação de dados inicial.
Funcionalidades principais
- Um servidor de base de dados compatível com PostgreSQL.
- Suporte para o AlloyDB AI, que ajuda a criar aplicações de IA generativa de nível empresarial com os seus dados operacionais.
- Integrações com o Google Cloud ecossistema de IA, incluindo o Vertex AI Model Garden e ferramentas de IA generativa de código aberto.
Suporte para funcionalidades de condução automática do AlloyDB para PostgreSQL no Google Cloud que permite ao AlloyDB Omni autogerir-se e autoajustar-se.
Por exemplo, o AlloyDB Omni suporta a gestão automática de memória e o autovacuum adaptativo de dados desatualizados.
Um consultor de índices que analisa as consultas executadas com frequência e recomenda novos índices para um melhor desempenho das consultas.
O motor de colunas do AlloyDB Omni, que mantém os dados consultados com frequência num formato de colunas na memória para um desempenho mais rápido na inteligência empresarial, nos relatórios e nas cargas de trabalho de processamento transacional e analítico híbrido (HTAP).
Nos nossos testes de desempenho, as cargas de trabalho transacionais no AlloyDB Omni são mais de 2 vezes mais rápidas e as consultas analíticas são até 100 vezes mais rápidas do que o PostgreSQL padrão.
Como funciona o AlloyDB Omni
Pode instalar o AlloyDB Omni como um servidor autónomo ou como parte de um ambiente do Kubernetes.
O AlloyDB Omni é executado num contentor Docker que instala no seu próprio ambiente. Recomendamos que execute o AlloyDB Omni num sistema Linux com armazenamento SSD e, pelo menos, 8 GB de memória por CPU.
O operador do AlloyDB Omni Kubernetes é uma extensão da API Kubernetes que lhe permite executar o AlloyDB Omni na maioria dos ambientes Kubernetes compatíveis com a CNCF. Para mais informações, consulte o artigo Instale o AlloyDB Omni no Kubernetes.
As suas aplicações ligam-se e comunicam com a instalação do AlloyDB Omni, tal como as aplicações se ligam e comunicam com um servidor de base de dados PostgreSQL padrão. O controlo de acesso do utilizador também se baseia nas normas do PostgreSQL.
Desde o registo à limpeza, até ao motor colunar, pode configurar o comportamento da base de dados do AlloyDB Omni através de flags da base de dados.
Vantagens da execução do AlloyDB Omni como um contentor
A Google distribui o AlloyDB Omni como um contentor que pode executar com tempos de execução de contentores, como o Docker e o Podman. Do ponto de vista operacional, os contentores apresentam as seguintes vantagens:
- Gestão de dependências transparente: todas as dependências necessárias são incluídas no pacote do contentor e testadas pela Google para garantir que são totalmente compatíveis com o AlloyDB Omni.
- Portabilidade: pode esperar que o AlloyDB Omni funcione de forma consistente em todos os ambientes.
- Isolamento de segurança: escolhe a que o contentor do AlloyDB Omni tem acesso na máquina anfitriã.
- Gestão de recursos: pode definir a quantidade de recursos de computação que quer que o contentor do AlloyDB Omni use.
- Aplicação de patches e atualizações integradas: para aplicar um patch a um contentor, só tem de substituir a imagem existente por uma nova.
Cópia de segurança de dados e recuperação de desastres
O AlloyDB Omni inclui um sistema de cópia de segurança e recuperação contínuo que lhe permite criar um novo cluster de base de dados com base em qualquer ponto no tempo dentro de um período de retenção ajustável. Isto permite-lhe recuperar rapidamente de acidentes de perda de dados.
Além disso, o AlloyDB Omni pode criar e armazenar cópias de segurança completas dos dados do cluster da base de dados, a pedido ou de forma regular. Em qualquer altura, pode restaurar a partir de uma cópia de segurança para um cluster de base de dados do AlloyDB Omni que contenha todos os dados do cluster de base de dados original no momento da criação da cópia de segurança.
Como método adicional de recuperação de desastres, pode conseguir a replicação entre centros de dados criando clusters de bases de dados secundários em centros de dados separados. O AlloyDB Omni transmite dados de forma assíncrona de um cluster de base de dados principal designado para cada um dos respetivos clusters secundários. Sempre que necessário, pode promover um cluster de base de dados secundário num cluster de base de dados AlloyDB Omni principal.
Componentes da VM do AlloyDB Omni
O AlloyDB Omni na VM consiste em dois conjuntos de componentes de arquitetura: componentes do PostgreSQL com melhorias do AlloyDB for PostgreSQL e componentes do AlloyDB for PostgreSQL. O diagrama seguinte descreve ambos os conjuntos de componentes, a camada de infraestrutura em que residem numa VM ou num servidor e as funcionalidades relacionadas que pode esperar para cada componente.
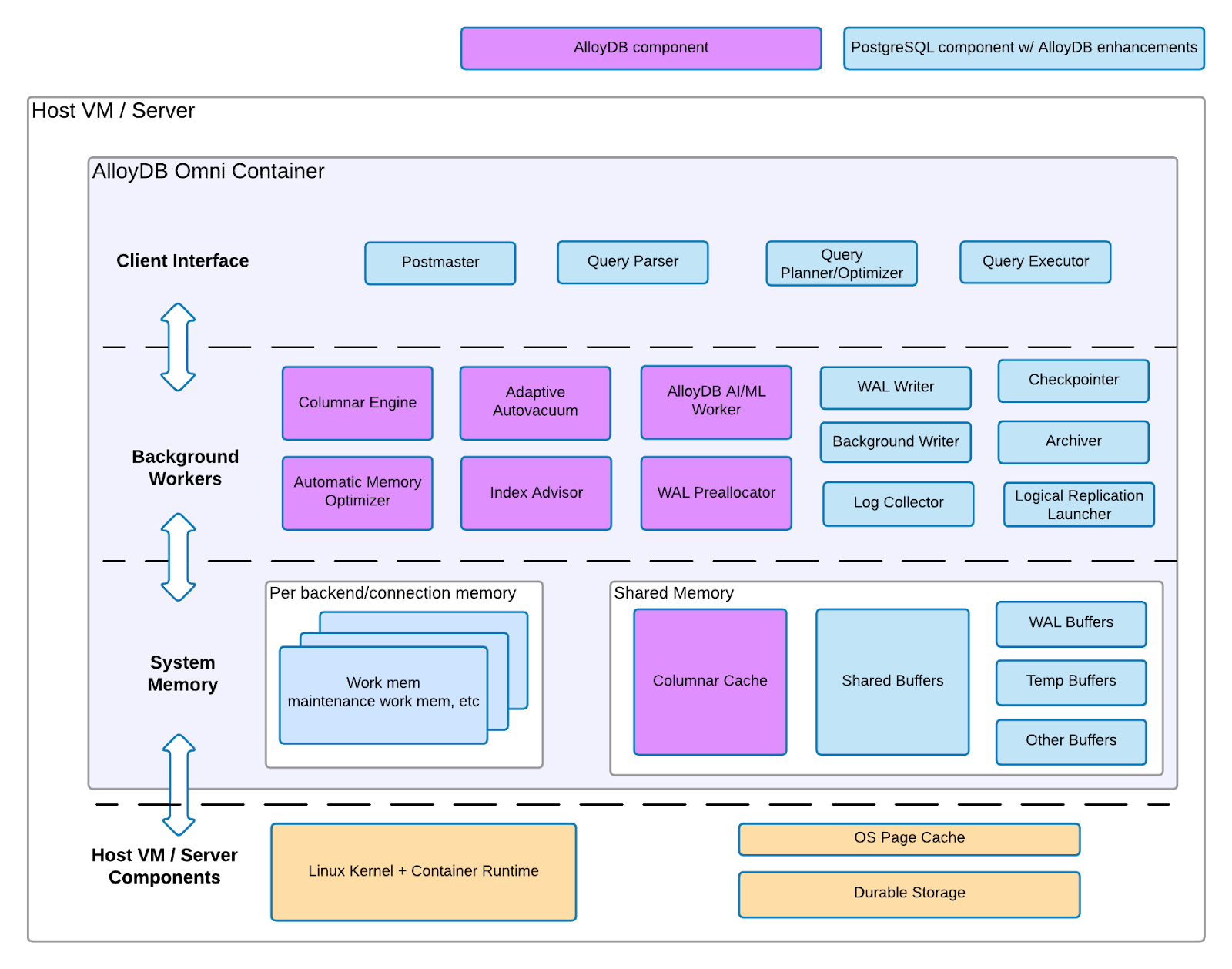
Figura 1. Arquitetura do AlloyDB Omni
Motor de base de dados
Este documento descreve a arquitetura da base de dados no AlloyDB Omni num contentor. Este documento pressupõe que tem conhecimentos do PostgreSQL.
Um motor de base de dados realiza as seguintes tarefas:
- Traduz uma consulta de um cliente num plano executável
- Encontra os dados necessários para satisfazer a consulta
- Executa qualquer filtragem, ordenação e agregação necessárias
- Devolve os resultados ao cliente
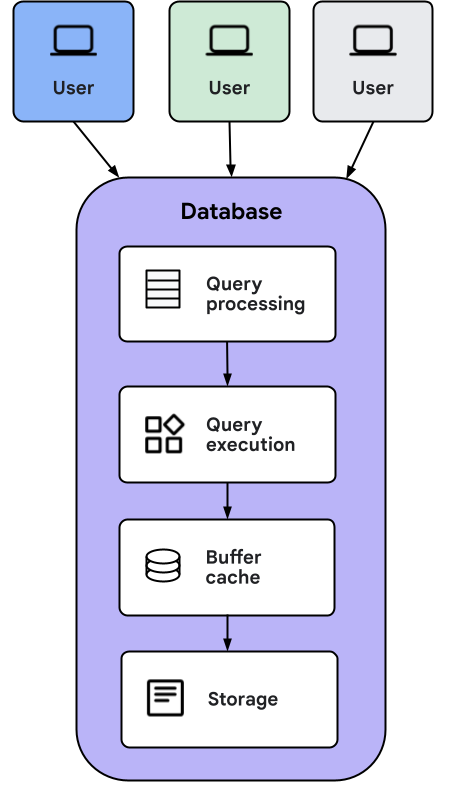
Quando a aplicação cliente envia uma consulta para o AlloyDB Omni, ocorrem as seguintes ações:
- A camada de tratamento de consultas transforma a consulta num plano de execução que é enviado para a camada de execução de consultas.
- A camada de execução de consultas realiza as operações necessárias para calcular a resposta à consulta.
- Durante a execução, os dados podem ser carregados a partir da cache de buffer ou carregados diretamente a partir do armazenamento. Se os dados forem carregados a partir do armazenamento, os dados do armazenamento são armazenados na cache para utilizações futuras.
Os recursos usados ao processar a consulta do cliente incluem CPU, memória, E/S, rede e primitivas de sincronização, como bloqueios de bases de dados. A otimização do desempenho visa otimizar a utilização de recursos durante cada um dos passos na execução de consultas.
O objetivo de um motor de base de dados com bom desempenho é responder a uma consulta usando o menor número de recursos necessário. Este objetivo começa com um bom modelo de dados e um design de consulta.
- Como é possível responder a consultas com a menor quantidade de dados possível?
- Que índices são necessários para reduzir o espaço de pesquisa e a E/S?
- A ordenação de dados requer CPU e, muitas vezes, acesso ao disco para grandes conjuntos de dados. Como se pode evitar a ordenação de dados?
Armazenamento de dados
O AlloyDB Omni armazena dados em páginas de tamanho fixo que são armazenadas no sistema de ficheiros subjacente. Quando uma consulta precisa de aceder a dados, o AlloyDB Omni verifica primeiro o conjunto de buffers. Se as páginas que contêm os dados necessários não forem encontradas no conjunto de buffers, o AlloyDB Omni lê as páginas necessárias do sistema de ficheiros. O acesso aos dados do conjunto de buffers é significativamente mais rápido do que a leitura do sistema de ficheiros e, por isso, maximizar o tamanho do conjunto de buffers para a quantidade de dados que uma aplicação vai aceder é um fator importante.
Gestão de recursos
O AlloyDB Omni usa a gestão dinâmica de memória para permitir que o conjunto de buffers aumente e diminua dinamicamente dentro dos limites configurados, consoante as exigências de memória do sistema. Por conseguinte, não é necessário ajustar o tamanho do conjunto de buffers. Ao diagnosticar problemas de desempenho, as primeiras métricas a considerar são a taxa de acertos do conjunto de buffers e a taxa de leitura para ver se a sua aplicação está a tirar partido do conjunto de buffers. Caso contrário, isso indica que o conjunto de dados da aplicação não se ajusta ao conjunto de buffers e pode considerar redimensioná-lo para uma máquina maior com mais memória.
O processo de obtenção, filtragem, agregação, ordenação e projeção de dados requer recursos da CPU no servidor da base de dados. Para reduzir a quantidade de recursos de CPU necessários para este processo, minimize a quantidade de dados que têm de ser manipulados. Monitorize a utilização da CPU no servidor da base de dados para garantir que a utilização em estado estável é de cerca de 70%. Este valor deixa espaço suficiente no servidor para picos de utilização ou alterações nos padrões de acesso ao longo do tempo. A execução com uma utilização mais próxima de 100% introduz sobrecarga devido ao agendamento de processos e à comutação de contexto, e pode criar gargalos noutras partes do sistema. A utilização elevada da CPU é outra métrica importante a usar quando toma decisões sobre as especificações da máquina.
As operações de entrada/saída por segundo (IOPS) são um fator importante no desempenho das aplicações de base de dados, ou seja, quantas operações de entrada ou saída por segundo o dispositivo de armazenamento subjacente pode fornecer à base de dados. Para evitar atingir os limites de IOPS do armazenamento da base de dados, minimize as leituras e as escritas no armazenamento maximizando a quantidade de dados que cabem no conjunto de buffers.
Motor colunar
O motor de colunas acelera o processamento de consultas SQL de análises, junções e agregações, fornecendo os seguintes componentes:
Armazenamento de colunas na memória: contém dados de tabelas e vistas materializadas para colunas selecionadas num formato orientado para colunas. Por predefinição, o armazenamento de colunas consome 1 GB de memória disponível. Para alterar a quantidade de memória utilizável pelo armazenamento de colunas, defina o parâmetro
google_columnar_engine.memory_size_in_mbnopostgresql.confusado pela sua instância do AlloyDB Omni.Planeador de consultas e motor de execução colunar: suporta a utilização do armazenamento de colunas em consultas.
Gestão de memória automática
O gestor de memória automático monitoriza e otimiza continuamente o consumo de memória numa instância completa do AlloyDB Omni. Quando executa as suas cargas de trabalho, este módulo ajusta o tamanho da cache do buffer partilhado com base na pressão da memória. Por predefinição, o gestor de memória automático define o limite superior para 80% da memória do sistema e atribui 10% da memória do sistema à cache de buffer partilhada.
Para alterar o limite superior do tamanho da cache do buffer partilhado, defina o parâmetro shared_buffers no postgresql.conf usado pela sua instância do AlloyDB Omni.
Autovacuum adaptável
O autovacuum adaptável analisa as operações com base na carga de trabalho da base de dados e ajusta automaticamente a frequência de limpeza. Este ajuste automático ajuda a base de dados a funcionar com o máximo desempenho, mesmo quando a carga de trabalho muda, sem interferência do processo de vácuo.
O autovacuum adaptável usa os seguintes fatores para determinar a frequência e a intensidade das operações de limpeza:
- Tamanho da base de dados
- Número de tuplos mortos na base de dados
- Antiguidade dos dados na base de dados
- Número de transações por segundo em comparação com a velocidade de vácuo estimada
O autovacuum adaptativo oferece as seguintes vantagens:
- Gestão dinâmica de recursos de vácuo: em vez de usar um limite de custo fixo, o AlloyDB Omni usa estatísticas de recursos em tempo real para ajustar os trabalhadores de vácuo. Quando o sistema está ocupado, o processo de limpeza e a utilização de recursos associada são limitados. Se estiver disponível memória suficiente, é alocada memória adicional para o
maintenance_work_mempara reduzir o tempo de vácuo de ponta a ponta. - Limitação dinâmica do XID: monitoriza automaticamente e continuamente o progresso da limpeza e a velocidade do consumo do ID da transação. Se for detetado um risco de repetição do ID da transação, o AlloyDB Omni abranda as transações para limitar o consumo de IDs. Além disso, o AlloyDB Omni atribui mais recursos aos trabalhadores de vácuo para processar as tabelas que bloqueiam o avanço e a libertação do espaço de IDs de transações. Durante este processo, as transações gerais por segundo são reduzidas até que os IDs das transações estejam numa zona segura (observável como sessões a aguardar
AdaptiveVacuumNewXidDelay). Quando a antiguidade do ID da transação aumenta, os trabalhadores de limpeza são aumentados dinamicamente. - Limpeza eficiente para tabelas maiores: a lógica do PostgreSQL predefinida usada para decidir quando limpar uma tabela baseia-se em estatísticas específicas da tabela armazenadas em
pg_stat_all_tables, que contém a taxa de tuplos mortos. Esta lógica funciona para tabelas pequenas, mas pode não funcionar de forma eficiente para tabelas maiores e atualizadas com frequência. O AlloyDB Omni oferece um mecanismo de verificação atualizado que ajuda a acionar o autovacuum com mais frequência. Este mecanismo de análise analisa blocos de tabelas grandes e remove tuplos inativos de forma mais eficiente do que a lógica predefinida do PostgreSQL. - Mensagens de aviso de registo: no AlloyDB Omni, os bloqueadores de vácuo, como transações de longa duração, transações preparadas ou slots de replicação que perdem os respetivos destinos, são detetados e os avisos são registados nos registos do PostgreSQL para que possa resolver os problemas atempadamente.
Trabalhador de IA/AA
No AlloyDB Omni, o trabalhador em segundo plano de IA/ML fornece todas as capacidades necessárias para chamar modelos da Vertex AI diretamente da base de dados. O trabalhador de IA/ML é executado como um processo denominado omni ml worker.
O que se segue?
- Escolha um ambiente de implementação do AlloyDB Omni.
- Comece a usar o AlloyDB Omni para Kubernetes.
- Comece a usar o AlloyDB Omni para contentores