Casi d'uso
Questa architettura di riferimento per la disponibilità è adatta ai seguenti casi d'uso:
- Applicazioni business critical che richiedono RTO e RPO inferiori.
- Vuoi eseguire il deployment di una replica in un'altra zona o in un altro nodo che fornisca alta disponibilità per i tuoi database e protegga da errori a livello di istanza, server e zona.
- Vuoi protezione da errori dell'utente e danneggiamento dei dati (utilizzando i backup).
Come funziona l'architettura di riferimento
La disponibilità avanzata si aggiunge alla disponibilità standard aggiungendo istanze di replica di lettura all'interno della regione per abilitare l'alta disponibilità (HA) che riduce l'RTO (Recovery Time Objective) RTO. Questo approccio riduce anche il Recovery Point Objective (RPO) consentendo lo streaming delle modifiche transazionali nella replica.
L'alta affidabilità in AlloyDB Omni utilizza almeno due istanze di database. Un'istanza funge da database principale, supportando le operazioni di lettura e scrittura. Le istanze rimanenti fungono da repliche di lettura e operano in modalità di sola lettura.
Di seguito sono riportati concetti importanti relativi all'alta affidabilità:
- Il failover è la procedura durante un'interruzione non pianificata in cui l'istanza principale non funziona o non è disponibile e la replica in standby viene attivata per assumere la modalità principale (lettura/scrittura). Questo processo è chiamato promozione. In genere, in questi scenari, quando il server o il database principale torna online, il database deve essere ricreato e poi deve fungere da standby. Per garantire un uptime elevato, sono in atto meccanismi per rendere automatici i failover.
- Uno switchover, noto anche come inversione di ruolo, è una procedura utilizzata per cambiare le modalità tra il database principale e uno dei database di standby, in modo che il database principale diventi di standby e quello di standby diventi principale. I cambi di ruolo in genere avvengono in modo controllato e graduale e possono essere avviati per diversi motivi, ad esempio per consentire il downtime e l'applicazione di patch al precedente database primario. I failover controllati devono consentire un futuro switchback senza dover reintegrare il nuovo standby o altri aspetti della configurazione della replica.
Opzioni di alta disponibilità
Per supportare l'alta affidabilità, puoi eseguire il deployment di AlloyDB Omni nei seguenti modi:
- Negli ambienti Kubernetes che utilizzano gli operatori AlloyDB Omni Kubernetes. Per saperne di più, consulta Gestire l'alta affidabilità in Kubernetes.
- Utilizzo di Patroni e HAProxy adatti ai deployment non Kubernetes. Per maggiori informazioni, consulta Architettura ad alta disponibilità per AlloyDB Omni per PostgreSQL.
| Nota: Patroni e HAProxy sono strumenti di terze parti non commerciali e sono compatibili con AlloyDB Omni. |
|---|
Ti consigliamo di avere almeno due database di standby in modo che la perdita di un database non influisca sull'alta disponibilità del cluster. In questa modalità, hai almeno una coppia HA in caso di failover o durante qualsiasi manutenzione pianificata di un nodo.
Per pianificare le dimensioni e la forma del deployment di AlloyDB Omni, consulta Pianificare l'installazione di AlloyDB Omni su una VM.
Bilanciatori del carico
Un altro meccanismo importante che facilita le procedure di switchover e failover più fluide è la presenza di un bilanciatore del carico. Per i deployment non Kubernetes, il software HAProxy fornisce il bilanciamento del carico. HAProxy offre il bilanciamento del carico distribuendo il traffico di rete su più server. HAProxy mantiene anche lo stato di integrità dei server di backend a cui si connette eseguendo controlli di integrità. Se un server non supera un controllo di integrità, HAProxy interrompe l'invio di traffico finché non supera di nuovo i controlli di integrità.
L'operatore Kubernetes esegue il deployment del proprio bilanciatore del carico, che si comporta in modo simile, creando un servizio per il database che punta al bilanciatore del carico per rendere questa operazione trasparente per l'utente.
Alta disponibilità
I database di replica di lettura di cui è stato eseguito il deployment all'interno di una regione forniscono alta disponibilità se il database principale non funziona. Quando si verifica un errore del database primario, il database di standby viene promosso per sostituire il database primario e l'applicazione continua con un'interruzione minima o nulla.
In genere è buona norma eseguire controlli regolari annuali o semestrali sotto forma di switchover per garantire che tutte le applicazioni che si basano su questi database siano ancora in grado di connettersi e rispondere in un intervallo di tempo adeguato.
La protezione a livello di zona può essere ottenuta utilizzando uno dei due tipi di deployment posizionando una delle repliche di lettura di standby in una zona di disponibilità diversa dal database primario.
Un ulteriore vantaggio delle repliche di lettura è la possibilità di trasferire le operazioni di sola lettura ai database di standby, che possono fungere da database di reporting utilizzando dati aggiornati. Questo approccio riduce il carico e l'overhead sulla replica primaria di lettura/scrittura.
Configurazione di backup e alta disponibilità
Le repliche di lettura possono essere configurate in più zone che garantiscono l'alta disponibilità. Sebbene forniscano RTO e RPO bassi, non proteggono da determinate interruzioni, come il danneggiamento logico dei dati, ad esempio eliminazioni accidentali di tabelle o aggiornamenti errati dei dati. Pertanto, oltre alla configurazione HA, è necessario eseguire backup regolari. Per ulteriori informazioni, consulta la documentazione sull'architettura di disponibilità standard.
La Figura 1 mostra una configurazione HA consigliata con due database di standby di replica di lettura in due zone di disponibilità diverse.
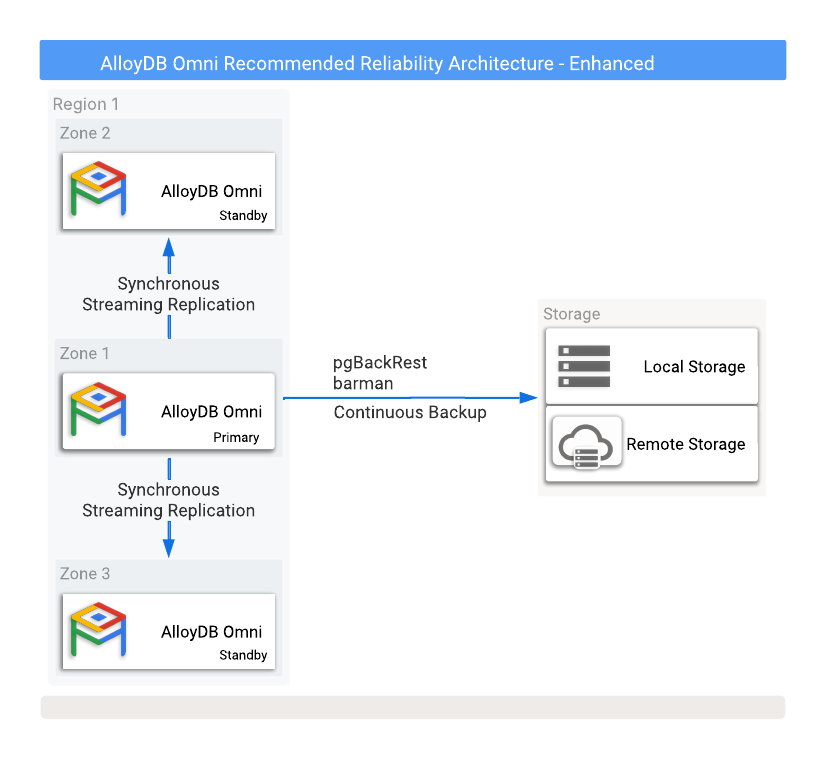
Figura 1. AlloyDB Omni con opzioni di backup e alta disponibilità.
Per proteggerti dalla perdita di dati in caso di errore dell'istanza primaria, è necessario configurare la replica in modalità sincrona. Sebbene questo metodo fornisca una protezione solida dei dati, può influire sulle prestazioni del database primario perché tutti i commit devono essere scritti sia nel database primario sia in tutti i database standby sincronizzati. Per questa configurazione è fondamentale una connessione di rete a bassa latenza tra queste istanze di database.
Deployment Kubernetes HA
Per i deployment Kubernetes, utilizzando alcune modifiche e aggiunte di attributi di base al file di deployment di AlloyDB Omni, puoi aggiungere standby di failover o repliche di lettura per consentire l'errore del database principale. È possibile configurare una replica di standby di failover e di sola lettura e l'operatore si occupa del provisioning e della pubblicazione del servizio. L'operatore automatizza anche molti dei processi HA, come la ricostruzione dei database di standby dopo un failover e l'utilizzo dei meccanismi di riparazione integrati nel motore Kubernetes di AlloyDB Omni.
In un deployment Kubernetes, la disponibilità di infrastruttura e applicazioni beneficia delle funzionalità Kubernetes integrate che si occupano degli errori di nodi e pod, tra cui:
- kube-controller-manager
- Parametri come
node-status-update-frequency,node-monitor-period,node-monitor-grace-period, epod-eviction-timeout.
Oltre alla protezione integrata, l'operatore espone i seguenti parametri per influenzare il rilevamento di un'istanza primaria o di standby non riuscita:
healthcheckPeriodSeconds: il tempo che intercorre tra i controlli di integrità. Il valore predefinito è 30 secondi.autoFailoverTriggerThreshold: il numero di controlli di integrità consecutivi non riusciti prima di avviare il failover. Il valore predefinito è 3.
Per saperne di più, consulta Gestire l'alta affidabilità in Kubernetes.
Deployment HA non Kubernetes
Il deployment non Kubernetes autonomo è una configurazione manuale che richiede strumenti di terze parti più complessi da configurare e gestire rispetto al deployment Kubernetes.
Quando utilizzi un deployment non Kubernetes, esistono alcuni parametri che influiscono sul modo in cui viene rilevato un failover e sulla rapidità con cui si verifica un failover dopo che il primario diventa non disponibile. Di seguito è riportato un breve riepilogo di questi parametri:
Ttl: il tempo massimo necessario per acquisire un blocco per il database primario prima di avviare un failover. Il valore predefinito è 30 secondi.Loop_wait: il tempo di attesa prima di eseguire nuovamente il controllo. Il valore predefinito è 10 secondi.Retry_timeout: il timeout prima di declassare l'istanza principale a causa di un errore di rete. Il valore predefinito è 10 secondi.
Per saperne di più, consulta Architettura ad alta disponibilità per AlloyDB Omni per PostgreSQL.
Implementazione
Quando scegli un'architettura di riferimento per la disponibilità, tieni presente i seguenti vantaggi, limitazioni e alternative.
Vantaggi
- Protegge dai guasti delle istanze.
- Protegge dagli errori del server.
- Protegge da errori a livello di zona.
- RTO notevolmente ridotto rispetto alla disponibilità standard.
Limitazioni
- Nessuna protezione aggiuntiva per i disastri regionali.
- Potenziale impatto sulle prestazioni dell'istanza principale a causa della replica sincrona.
- La configurazione dello streaming WAL di PostgreSQL in modalità sincrona
offre una perdita di dati pari a zero (
RPO=0) durante il normale funzionamento o i tipici failover. Tuttavia, questo approccio non protegge dalla perdita di dati in situazioni specifiche di doppio errore, ad esempio quando tutte le istanze di standby vengono perse o diventano irraggiungibili dalla primaria e questo è immediatamente seguito da un riavvio della primaria.
Alternative
- L'architettura di disponibilità standard per le opzioni di backup e ripristino.
- L'architettura di disponibilità premium per il ripristino di emergenza a livello di regione, repliche di lettura aggiuntive e copertura del ripristino di emergenza estesa.
Passaggi successivi
- Panoramica dell'architettura di riferimento per la disponibilità di AlloyDB Omni.
- Disponibilità standard di AlloyDB Omni.
- Disponibilità di AlloyDB Omni Premium.
- Pianifica l'installazione di AlloyDB Omni su una VM.
- Architettura ad alta disponibilità per AlloyDB Omni per PostgreSQL.
- Gestisci l'alta disponibilità in Kubernetes.