Casi d'uso
Questa architettura di riferimento supporta i seguenti scenari:
- Hai database che possono tollerare alcuni tempi di inattività e perdite di dati dall'ultimo backup.
- Vuoi proteggere il tuo database AlloyDB Omni da errori utente, danneggiamento o guasti fisici a livello di database (anziché snapshot di server o immagini VM).
- Vuoi essere in grado di recuperare il database in loco o da remoto, possibilmente fino a un momento specifico.
Come funziona l'architettura di riferimento
L'architettura di riferimento per la disponibilità standard copre il backup e il ripristino dei database AlloyDB Omni, indipendentemente dal fatto che vengano eseguiti come istanza autonoma su un server host, come macchina virtuale (Installa AlloyDB Omni) o in un cluster Kubernetes (Installa AlloyDB Omni su Kubernetes).
Sebbene la disponibilità standard sia un'implementazione di base e riduca al minimo l'hardware o i servizi aggiuntivi richiesti, il Recovery Time Objective (RTO) aumenta man mano che il database diventa più grande. Più dati devono essere sottoposti a backup, più tempo è necessario per ripristinare e recuperare il database. La perdita di dati dipende dal tipo di backup. Se vengono eseguiti periodicamente backup solo dei file di dati, al ripristino si verifica una perdita di dati dall'ultimo backup.
Riduzione dell'RPO
La funzionalità di archiviazione continua di PostgreSQL ti consente di ottenere un Recovery Point Objective (RPO) basso e di attivare il recupero point-in-time tramite i backup. Questo processo prevede l'archiviazione dei file Write-Ahead Logging (WAL) e lo streaming dei dati WAL, potenzialmente in una posizione di archiviazione remota.
Se i file WAL vengono archiviati solo quando sono pieni o a intervalli specifici, una perdita completa del database (inclusi i file WAL correnti) limita il recupero all'ultimo file WAL archiviato, il che significa che il Recovery Point Objective (RPO) deve tenere conto della potenziale perdita di dati. Al contrario, il trasferimento continuo dei dati WAL massimizza la perdita di dati pari a zero.
Quando esegui backup continui, puoi eseguire il recupero in un momento specifico. Il recupero point-in-time consente il ripristino a uno stato precedente a un errore, ad esempio l'eliminazione accidentale di una tabella o aggiornamenti batch errati. Tuttavia, questo metodo di recupero influisce sul Recovery Point Objective (RPO) a meno che non venga utilizzato un database ausiliario temporaneo.
Strategie di backup
Puoi configurare i backup a livello di AlloyDB Omni Postgres in modo che vengano archiviati su spazio di archiviazione locale o remoto. Sebbene l'archiviazione locale possa essere più veloce per il backup e il ripristino, l'archiviazione remota è in genere più solida per la gestione degli errori quando si verifica un errore dell'intera VM o dell'intero host.
Backup in ambienti non Kubernetes
Per i deployment non Kubernetes, puoi pianificare i backup utilizzando i seguenti strumenti PostgreSQL:
- pgBackRest. Per saperne di più, vedi Configurare pgBackRest per AlloyDB Omni.
- Barman. Per saperne di più, vedi Configurare Barman per AlloyDB Omni.
In alternativa, per i database di piccole dimensioni, puoi scegliere di eseguire un backup logico del database (utilizzando pg_dump per un singolo database o pg_dumpall per l'intero cluster). Puoi eseguire il ripristino utilizzando pg_restore.
Backup in Kubernetes utilizzando l'operatore AlloyDB Omni
Per AlloyDB Omni di cui è stato eseguito il deployment in un cluster Kubernetes, puoi configurare i backup continui utilizzando un piano di backup per ogni cluster di database. Per maggiori informazioni, vedi Backup e ripristino in Kubernetes.
Puoi archiviare i backup di AlloyDB Omni localmente o in remoto in Cloud Storage, incluse le opzioni fornite da qualsiasi fornitore di servizi cloud. Per saperne di più, vedi la Figura 1, che mostra le potenziali destinazioni di backup.
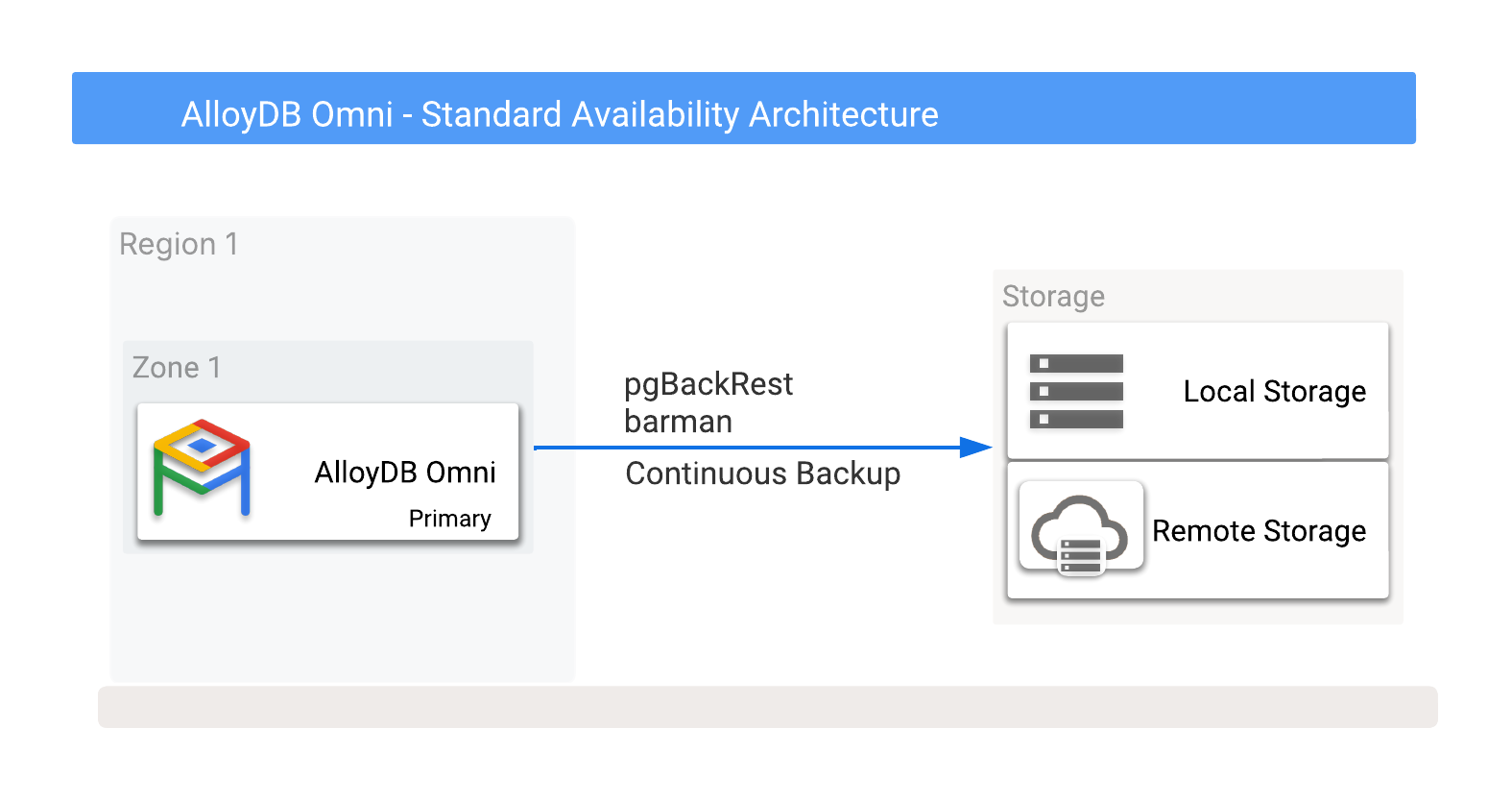
Figura 1. AlloyDB Omni con opzioni di backup.
I backup possono essere eseguiti su opzioni di archiviazione locali o remote. I backup locali tendono a essere più veloci perché si basano solo sulla velocità effettiva di I/O, mentre i backup remoti di solito hanno una latenza maggiore e una larghezza di banda di rete inferiore. Tuttavia, i backup remoti offrono una protezione ottimale, inclusi gli errori a livello di zona.
Puoi anche dividere i backup locali in spazio di archiviazione locale o condiviso. Mentre le opzioni di archiviazione locale sono interessate dalla mancanza di opzioni di ripristino di emergenza quando un host di database non funziona, l'archiviazione condivisa consente di trasferire l'archiviazione su un altro server e quindi utilizzarla per il ripristino. Ciò significa che l'archiviazione condivisa potenzialmente offre un RTO più rapido.
Per le implementazioni di archiviazione locale e condivisa, i seguenti tipi di backup possono essere pianificati o eseguiti manualmente su richiesta:
- Backup completi: backup completi di tutti i file di database necessari per il recupero dei dati.
- Backup differenziali: backup solo delle modifiche ai file dall'ultimo backup completo.
- Backup incrementali: backup solo delle modifiche ai file dall'ultimo backup di qualsiasi tipo.
Recupero point-in-time
I backup continui dei file di log write-ahead (WAL) di PostgreSQL supportano il recupero point-in-time. Se, dopo un evento di errore, i file WAL sono intatti e utilizzabili, puoi utilizzarli per il recupero senza perdita di dati.
Per controllare la scrittura dei file WAL, puoi configurare i seguenti parametri:
| Parametro | Descrizione |
|---|---|
|
Specifica la frequenza con cui il writer WAL esegue il flush del WAL su disco, a meno che la scrittura non venga riattivata prima da una transazione che viene eseguita il commit in modo asincrono. Il valore predefinito è 200 ms. L'aumento di questo valore riduce la frequenza di scrittura, ma potrebbe aumentare la quantità di dati persi in caso di arresto anomalo del server. |
|
Specifica la quantità di dati WAL che possono accumularsi prima che il writer WAL forzi lo scaricamento su disco. Il valore predefinito è 1 MB. Se impostato su zero, i dati WAL vengono sempre scaricati immediatamente sul disco. |
|
Specifica se il commit restituisce una risposta all'utente prima che i dati WAL vengano scaricati sul disco. L'impostazione predefinita è
on, che garantisce la durabilità della transazione. In
altre parole, il commit è stato scritto su disco prima di restituire un
codice di successo all'utente. Se il valore è impostato su off, il valore wal_writer_delay viene ripetuto fino a tre volte prima che la transazione venga scritta su disco. |
Monitoraggio dell'utilizzo del WAL
Puoi utilizzare i seguenti metodi per osservare l'utilizzo di WAL:
| Metodo di osservazione | Descrizione |
|---|---|
|
Questa visualizzazione standard include le colonne wal_write
e wal_sync, che memorizzano
i conteggi del numero di scritture WAL e sincronizzazioni WAL. Quando il
parametro di configurazione track_wal_io_timing
è attivato, vengono memorizzati
anche wal_write_time e wal_sync_time. I snapshot regolari di questa visualizzazione possono contribuire a mostrare l'attività di scrittura
e sincronizzazione WAL nel tempo. |
pg_current_wal_lsn() |
Questa funzione restituisce la posizione corrente del numero di sequenza del log (lsn)
che, se associata a un timestamp e raccolta come snapshot
nel tempo, può fornire i byte/secondo di WAL generati utilizzando la
funzione pg_wal_lsn_diff(lsn1, lsn2).
Questa funzione è una metrica utile per comprendere la velocità delle transazioni e il rendimento dei file WAL. |
Streaming dei dati WAL in una posizione remota
Quando utilizzi Barman, i dati WAL possono anche essere configurati per lo streaming in tempo reale in una posizione remota per garantire una perdita di dati minima o nulla durante il recupero. Nonostante lo streaming in tempo reale, esiste una piccola possibilità di perdere le transazioni di commit poiché le scritture di streaming sul server Barman remoto sono asincrone per impostazione predefinita. Tuttavia, è possibile configurare lo streaming WAL utilizzando la modalità sincrona che memorizza il WAL e invia una risposta di stato al database di origine. Tieni presente che questo approccio può rallentare le transazioni se devono attendere il completamento di questa scrittura prima di continuare.
Pianificazioni di backup
Nella maggior parte degli ambienti, i backup vengono generalmente pianificati su base settimanale. Di seguito è riportata una pianificazione settimanale tipica dei backup:
- Domenica: backup completo
- Lunedì, martedì: backup
- Mercoledì: backup differenziale
- Giovedì, venerdì: backup incrementale
- Sabato: backup differenziale
Utilizzando questa pianificazione tipica, una finestra di ripristino continua di una settimana richiede spazio di archiviazione per un massimo di tre backup completi più i backup incrementali o differenziali necessari. Questo approccio supporta il recupero in caso di errore che si verifica durante il backup completo di domenica e il recupero del database deve estendersi alla domenica precedente l'inizio del backup.
Per ridurre al minimo l'RTO con un potenziale RPO più elevato, i database aggiuntivi possono operare in modalità di recupero continuo. Ciò comporta la riproduzione dei backup e l'aggiornamento continuo dell'ambiente secondario mediante l'archiviazione e la riproduzione di nuovi file WAL. L'RPO effettivo, che riflette la potenziale perdita di dati, dipende da frequenza delle transazioni, dimensioni del file WAL e utilizzo dello streaming WAL.
Ripristino in ambienti non Kubernetes
Per i deployment non Kubernetes, il ripristino di un database AlloyDB Omni comporta l'arresto del container Docker e il ripristino dei dati oppure il ripristino dei dati in una posizione diversa e l'avvio di una nuova istanza Docker utilizzando i dati ripristinati. Una volta riavviato il container, il database è accessibile con i dati ripristinati.
Per saperne di più sulle opzioni di ripristino, consulta Ripristinare un cluster AlloyDB Omni utilizzando pgBackRest e Ripristinare un cluster AlloyDB Omni utilizzando Barman.
Ripristino in Kubernetes utilizzando l'operatore
Per ripristinare un database in Kubernetes, l'operatore offre il recupero nello stesso cluster e spazio dei nomi Kubernetes da un backup denominato o da un clone da un point-in-time (PIT). Per clonare un database in un cluster Kubernetes diverso, utilizza pgBackRest. Per ulteriori informazioni, vedi Backup e ripristino in Kubernetes e Clonare un cluster di database da una panoramica del backup di Kubernetes.
Implementazione
Quando scegli un'architettura di riferimento per la disponibilità, tieni presente i seguenti vantaggi, limitazioni e alternative.
Vantaggi
- Semplice da usare e gestire e adatto a database non critici con RTO/RPO flessibili.
- Hardware aggiuntivo minimo richiesto
- I backup sono sempre necessari per un piano di ripristino di emergenza completo
- È possibile il recupero in qualsiasi momento all'interno della finestra di recupero
Limitazioni
- Requisiti di spazio di archiviazione potenzialmente superiori a quelli del database stesso, a seconda dei requisiti di conservazione.
- Il recupero può essere lento e potrebbe comportare un RTO più elevato.
- Può comportare una perdita di dati, a seconda della disponibilità dei dati WAL attuali dopo l'errore del database, il che potrebbe influire negativamente sull'RPO.
Alternative
- Prendi in considerazione l'architettura di disponibilità avanzata o premium per opzioni di disponibilità e ripristino di emergenza migliorate.
Passaggi successivi
- Panoramica dell'architettura di riferimento per la disponibilità di AlloyDB Omni.
- AlloyDB Omni Enhanced Availability.
- Disponibilità di AlloyDB Omni Premium.
- Installa AlloyDB Omni su Kubernetes.
- Configura pgBackRest per AlloyDB Omni.
- Configura Barman per AlloyDB Omni.
- Backup e ripristino in Kubernetes.
- Ripristina un cluster AlloyDB Omni utilizzando pgBackRest.
- Ripristina un cluster AlloyDB Omni utilizzando Barman.
- Backup e ripristino in Kubernetes.
- Clona un cluster di database da una panoramica dei backup di Kubernetes.