Cas d'utilisation
Cette architecture de référence de disponibilité convient aux cas d'utilisation suivants :
- Applications critiques nécessitant un RTO et un RPO plus faibles.
- Vous souhaitez déployer un réplica dans une autre zone ou un autre nœud qui offre une haute disponibilité pour vos bases de données et protège contre les défaillances d'instance, de serveur et de zone.
- Vous souhaitez vous protéger contre les erreurs utilisateur et la corruption des données (à l'aide de sauvegardes).
Fonctionnement de l'architecture de référence
La disponibilité améliorée s'ajoute à la disponibilité standard en ajoutant des instances répliquées en lecture dans la région pour activer la haute disponibilité (HA), ce qui réduit l'objectif de temps de récupération (RTO). Cette approche réduit également l'objectif de point de récupération (RPO) en permettant la diffusion en flux continu des modifications transactionnelles vers le réplica.
La haute disponibilité dans AlloyDB Omni utilise au moins deux instances de base de données. Une instance sert de base de données principale et accepte les opérations de lecture et d'écriture. Les instances restantes servent d'instances dupliquées avec accès en lecture et fonctionnent en mode lecture seule.
Voici quelques concepts importants concernant la haute disponibilité :
- Le basculement est la procédure qui se déroule lors d'une panne imprévue au cours de laquelle l'instance principale échoue ou devient indisponible, et l'instance répliquée de secours est activée pour prendre le relais en mode principal (lecture/écriture). Ce processus est appelé promotion. Dans ces scénarios, lorsque le serveur ou la base de données principaux sont de nouveau en ligne, la base de données doit généralement être reconstruite et agir en tant que base de données de secours. Pour assurer une disponibilité élevée, des mécanismes sont en place pour automatiser les basculements.
- Une commutation, également appelée inversion de rôle, est une procédure utilisée pour inverser les modes entre la base de données principale et l'une des bases de données de secours, de sorte que la base de données principale devienne la base de données de secours et inversement. Les basculements se font généralement de manière contrôlée et fluide. Ils peuvent être initiés pour de nombreuses raisons, par exemple pour permettre l'arrêt et la mise à jour de l'ancienne base de données principale. Les basculements fluides doivent permettre un futur retour en arrière sans avoir à réinstancier la nouvelle instance de secours ni d'autres aspects de la configuration de la réplication.
Options de haute disponibilité
Pour prendre en charge la haute disponibilité, vous pouvez déployer AlloyDB Omni de différentes manières :
- Dans les environnements Kubernetes utilisant des opérateurs Kubernetes AlloyDB Omni. Pour en savoir plus, consultez Gérer la haute disponibilité dans Kubernetes.
- Utilisation de Patroni et HAProxy adaptés aux déploiements non Kubernetes. Pour en savoir plus, consultez Architecture à haute disponibilité pour AlloyDB Omni pour PostgreSQL.
| Remarque : Patroni et HAProxy sont des outils tiers non commerciaux et compatibles avec AlloyDB Omni. |
|---|
Nous vous recommandons d'avoir au moins deux bases de données de secours afin que la perte d'une base de données n'ait pas d'incidence sur la haute disponibilité du cluster. Dans ce mode, vous disposez d'au moins une paire HA en cas de basculement ou lors de toute maintenance planifiée d'un nœud.
Pour planifier la taille et la forme de votre déploiement AlloyDB Omni, consultez Planifier votre installation AlloyDB Omni sur une VM.
Équilibreurs de charge
La présence d'un équilibreur de charge est un autre mécanisme important qui facilite les procédures de bascule et de reprise après sinistre. Pour les déploiements non Kubernetes, le logiciel HAProxy fournit l'équilibrage de charge. HAProxy propose un équilibrage de charge en répartissant le trafic réseau sur plusieurs serveurs. HAProxy gère également l'état d'intégrité des serveurs de backend auxquels il se connecte en effectuant des vérifications d'état. Si un serveur échoue à une vérification de l'état'état, HAProxy cesse de lui envoyer du trafic jusqu'à ce qu'il réussisse à nouveau les vérifications de l'état.
L'opérateur Kubernetes déploie son propre équilibreur de charge, qui se comporte de manière similaire, en créant un service pour la base de données pointant vers l'équilibreur de charge afin de rendre cela transparent pour l'utilisateur.
Haute disponibilité
Les bases de données répliquées avec accès en lecture déployées dans une région offrent une haute disponibilité en cas de défaillance de la base de données principale. En cas de défaillance de la base de données principale, la base de données de secours est promue pour la remplacer, et l'application continue de fonctionner avec peu ou pas d'interruption.
Il est généralement recommandé d'effectuer des vérifications régulières (annuelles ou semestrielles) sous la forme de basculements pour s'assurer que toutes les applications qui s'appuient sur ces bases de données peuvent toujours se connecter et répondre dans un délai approprié.
La protection au niveau de la zone peut être obtenue avec l'un ou l'autre type de déploiement en plaçant l'une des répliques en lecture de secours dans une zone de disponibilité différente de celle de la base de données principale.
Un autre avantage des instances répliquées en lecture est la possibilité de décharger les opérations en lecture seule sur les bases de données de secours, qui peuvent servir de bases de données de reporting à l'aide de données à jour. Cette approche réduit la charge et les frais généraux sur l'instance principale en lecture/écriture.
Sauvegardes et configuration de la haute disponibilité
Les instances répliquées avec accès en lecture peuvent être configurées dans plusieurs zones offrant une haute disponibilité. Bien qu'ils offrent des RTO et RPO faibles, ils ne protègent pas contre certaines pannes, comme la corruption logique des données (par exemple, la suppression accidentelle de tables ou la mise à jour incorrecte de données). Par conséquent, des sauvegardes régulières doivent être effectuées en plus de la configuration de la haute disponibilité. Pour en savoir plus, consultez la documentation sur l'architecture de disponibilité standard.
La figure 1 montre une configuration de haute disponibilité recommandée avec deux bases de données de secours avec répliquas en lecture dans deux zones de disponibilité différentes.
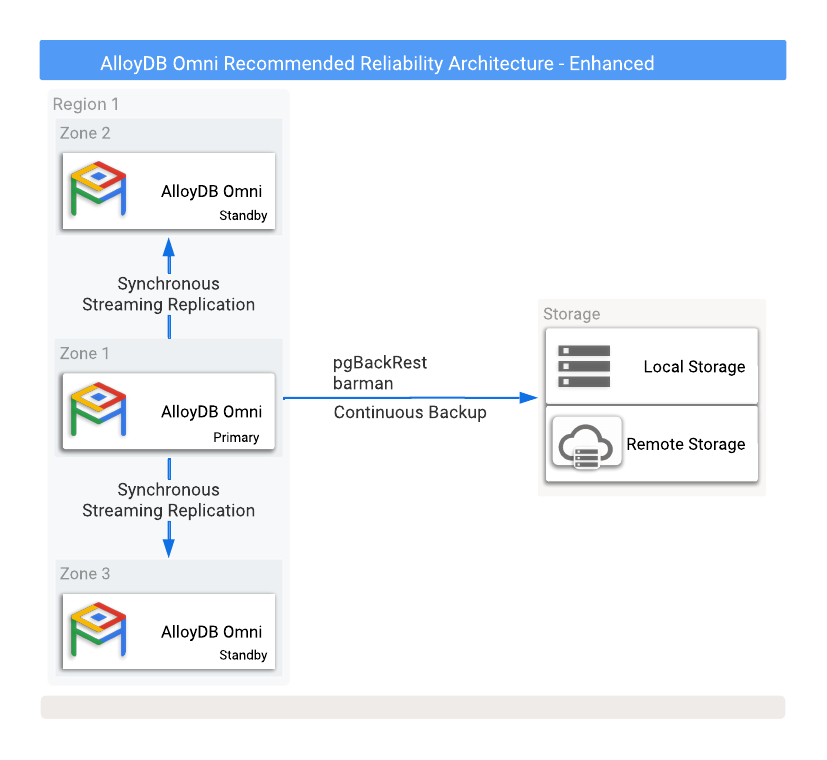
Figure 1 : AlloyDB Omni avec options de sauvegarde et de haute disponibilité.
Pour vous protéger contre la perte de données en cas d'échec de l'instance principale, vous devez configurer la réplication en mode synchrone. Bien que cette méthode offre une protection solide des données, elle peut avoir un impact sur les performances de la base de données principale, car tous les commits doivent être écrits à la fois dans la base de données principale et dans toutes les bases de données de secours synchronisées. Une connexion réseau à faible latence entre ces instances de base de données est essentielle pour cette configuration.
Déploiements Kubernetes HA
Pour les déploiements Kubernetes, vous pouvez ajouter des instances de secours pour le basculement ou des instances répliquées en lecture seule afin de faire face à une défaillance de la base de données principale. Pour ce faire, modifiez et ajoutez quelques attributs de base à votre fichier de déploiement AlloyDB Omni. Une réplique de secours et une réplique en lecture seule peuvent être configurées, et l'opérateur se charge du provisionnement et de la publication du service. L'opérateur automatise également de nombreux processus de haute disponibilité, tels que la reconstruction des bases de données de secours après un basculement et l'utilisation des mécanismes de réparation intégrés au moteur Kubernetes AlloyDB Omni.
Dans un déploiement Kubernetes, la disponibilité de l'infrastructure et des applications bénéficie des fonctionnalités Kubernetes intégrées qui gèrent les défaillances de nœuds et de pods, y compris les suivantes :
- kube-controller-manager
- Paramètres tels que
node-status-update-frequency,node-monitor-period,node-monitor-grace-periodetpod-eviction-timeout.
En plus de la protection intégrée, l'opérateur expose les paramètres suivants pour influencer la détection d'un serveur principal ou de secours défaillant :
healthcheckPeriodSeconds: temps entre les vérifications d'état. La valeur par défaut est de 30 secondes.autoFailoverTriggerThreshold: nombre de vérifications de l'état consécutives ayant échoué avant le lancement du basculement. La valeur par défaut est 3.
Pour en savoir plus, consultez Gérer la haute disponibilité dans Kubernetes.
Déploiements HA non Kubernetes
Le déploiement autonome non Kubernetes est une configuration manuelle qui nécessite des outils tiers. Il est plus complexe à configurer et à gérer que le déploiement Kubernetes.
Lorsque vous utilisez un déploiement non Kubernetes, certains paramètres affectent la façon dont un basculement est détecté et la rapidité avec laquelle il se produit après que le nœud principal devient indisponible. Voici un bref récapitulatif de ces paramètres :
Ttl: délai maximal pour acquérir un verrou pour la base de données principale avant de lancer un basculement. La valeur par défaut est de 30 secondes.Loop_wait: délai d'attente avant la prochaine vérification. La valeur par défaut est de 10 secondes.Retry_timeout: délai avant rétrogradation de l'instance principale en raison d'une défaillance du réseau. La valeur par défaut est de 10 secondes.
Pour en savoir plus, consultez Architecture à haute disponibilité pour AlloyDB Omni pour PostgreSQL.
Implémentation
Lorsque vous choisissez une architecture de référence de disponibilité, gardez à l'esprit les avantages, les limites et les alternatives suivants.
Avantages
- Protège contre les défaillances d'instance.
- Protège contre les défaillances du serveur.
- Protège contre les défaillances de zones.
- Le RTO est considérablement réduit par rapport à la disponibilité standard.
Limites
- Aucune protection supplémentaire en cas de catastrophe régionale.
- Impact potentiel sur les performances de l'instance principale en raison de la réplication synchrone.
- La configuration du streaming WAL PostgreSQL en mode synchrone permet d'éviter toute perte de données (
RPO=0) en cas de fonctionnement normal ou de basculement typique. Toutefois, cette approche ne protège pas contre la perte de données dans des situations spécifiques de double défaillance, par exemple lorsque toutes les instances de secours sont perdues ou deviennent inaccessibles depuis l'instance principale, et que l'instance principale redémarre immédiatement après.
Alternatives
- L'architecture de disponibilité standard pour les options de sauvegarde et de récupération.
- L'architecture de disponibilité Premium pour la reprise après sinistre au niveau de la région, les instances répliquées avec accès en lecture supplémentaires et la couverture étendue de la reprise après sinistre.
Étapes suivantes
- Présentation de l'architecture de référence de la disponibilité d'AlloyDB Omni
- Disponibilité standard d'AlloyDB Omni
- Disponibilité d'AlloyDB Omni Premium
- Planifiez l'installation d'AlloyDB Omni sur une VM.
- Architecture à haute disponibilité pour AlloyDB Omni pour PostgreSQL.
- Gérer la haute disponibilité dans Kubernetes