Cas d'utilisation
Cette architecture de référence est compatible avec les scénarios suivants :
- Vous disposez de bases de données qui peuvent tolérer un certain temps d'arrêt et une perte de données depuis la dernière sauvegarde.
- Vous souhaitez protéger votre base de données AlloyDB Omni contre les erreurs utilisateur, la corruption ou les défaillances physiques au niveau de la base de données (par opposition aux snapshots de serveur ou d'image de VM).
- Vous souhaitez pouvoir récupérer votre base de données sur place ou à distance, éventuellement jusqu'à un moment précis.
Fonctionnement de l'architecture de référence
L'architecture de référence de disponibilité standard couvre la sauvegarde et la récupération de vos bases de données AlloyDB Omni, qu'elles s'exécutent en tant qu'instance autonome sur un serveur hôte, en tant que machine virtuelle (Installer AlloyDB Omni) ou dans un cluster Kubernetes (Installer AlloyDB Omni sur Kubernetes).
Bien que la disponibilité standard soit une implémentation de base qui minimise le matériel ou les services supplémentaires requis, l'objectif de temps de récupération (RTO) augmente à mesure que la base de données s'agrandit. Plus il y a de données à sauvegarder, plus la restauration et la récupération de la base de données prennent du temps. La perte de données dépend du type de sauvegarde. Si seuls les fichiers de données sont sauvegardés régulièrement, vous perdrez des données depuis la dernière sauvegarde lorsque vous les restaurerez.
Réduire le RPO
La fonctionnalité d'archivage continu de PostgreSQL vous permet d'atteindre un objectif de point de récupération (RPO) faible et d'activer la récupération à un moment précis grâce aux sauvegardes. Ce processus implique l'archivage des fichiers WAL (Write-Ahead Logging) et le streaming des données WAL, potentiellement vers un emplacement de stockage distant.
Si les fichiers WAL ne sont archivés que lorsqu'ils sont pleins ou à des intervalles spécifiques, une perte complète de la base de données (y compris les fichiers WAL actuels) limite la récupération au dernier fichier WAL archivé. Cela signifie que l'objectif de point de récupération (RPO) doit tenir compte de la perte de données potentielle. À l'inverse, le transfert continu des données WAL maximise l'absence de perte de données.
Lorsque vous effectuez des sauvegardes continues, vous pouvez restaurer les données à un moment précis. La récupération à un moment précis permet de restaurer un état antérieur à une erreur, comme la suppression accidentelle d'une table ou des mises à jour par lot incorrectes. Toutefois, cette méthode de récupération a un impact sur l'objectif de point de récupération (RPO), sauf si une base de données auxiliaire temporaire est utilisée.
Stratégies de sauvegarde
Vous pouvez configurer les sauvegardes AlloyDB Omni au niveau de PostgreSQL pour qu'elles soient stockées sur un espace de stockage local ou distant. Bien que le stockage local puisse être plus rapide pour la sauvegarde et la récupération, le stockage à distance est généralement plus robuste pour gérer les défaillances lorsqu'un hôte ou une VM entiers échouent.
Sauvegardes dans les environnements non Kubernetes
Pour les déploiements non Kubernetes, vous pouvez planifier des sauvegardes à l'aide des outils PostgreSQL suivants :
- pgBackRest. Pour en savoir plus, consultez Configurer pgBackRest pour AlloyDB Omni.
- Barman. Pour en savoir plus, consultez Configurer Barman pour AlloyDB Omni.
Vous pouvez également choisir d'effectuer une sauvegarde logique de la base de données (à l'aide de pg_dump pour une seule base de données ou de pg_dumpall pour l'ensemble du cluster). Vous pouvez effectuer une restauration à l'aide de pg_restore.
Sauvegardes dans Kubernetes à l'aide de l'opérateur AlloyDB Omni
Pour AlloyDB Omni déployé dans un cluster Kubernetes, vous pouvez configurer des sauvegardes continues à l'aide d'un plan de sauvegarde pour chaque cluster de bases de données. Pour en savoir plus, consultez Sauvegarder et restaurer dans Kubernetes.
Vous pouvez stocker les sauvegardes AlloyDB Omni localement ou à distance dans Cloud Storage, y compris les options fournies par n'importe quel fournisseur de services cloud. Pour en savoir plus, consultez l'illustration 1, qui présente les destinations de sauvegarde potentielles.
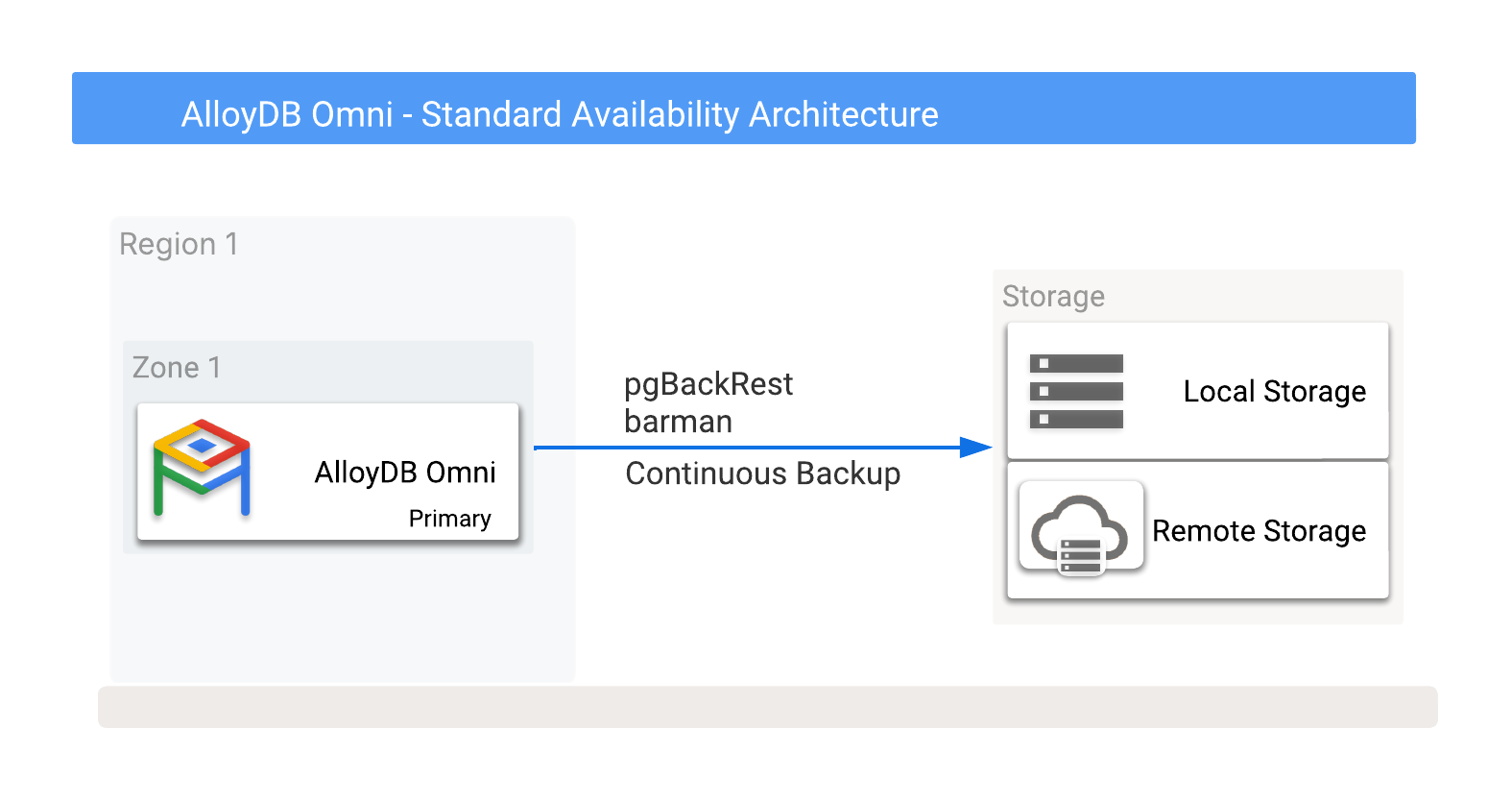
Figure 1 : AlloyDB Omni avec options de sauvegarde.
Les sauvegardes peuvent être effectuées sur des options de stockage locales ou à distance. Les sauvegardes locales ont tendance à être plus rapides, car elles ne dépendent que du débit d'E/S, tandis que les sauvegardes à distance ont généralement une latence plus élevée et une bande passante réseau plus faible. Toutefois, les sauvegardes à distance offrent une protection optimale, y compris contre les défaillances de zones.
Vous pouvez également répartir les sauvegardes locales entre le stockage local et le stockage partagé. Alors que les options de stockage local sont affectées par l'absence d'options de reprise après sinistre en cas de défaillance d'un hôte de base de données, le stockage partagé permet de déplacer ce stockage vers un autre serveur, puis de l'utiliser pour la récupération. Cela signifie que le stockage partagé offre potentiellement un RTO plus rapide.
Pour les déploiements de stockage local et partagé, les types de sauvegarde suivants peuvent être planifiés ou effectués manuellement à la demande :
- Sauvegardes complètes : sauvegardes complètes de tous les fichiers de base de données nécessaires à la récupération des données.
- Les sauvegardes différentielles : sauvegardes des modifications apportées aux fichiers depuis la dernière sauvegarde complète.
- Sauvegardes incrémentielles : sauvegardes des modifications apportées aux fichiers depuis la dernière sauvegarde, quel que soit son type.
Récupération à un moment précis
Les sauvegardes continues des fichiers WAL (Write-Ahead Logging) de PostgreSQL sont compatibles avec la récupération à un moment précis. Si, après un événement d'échec, les fichiers WAL sont intacts et utilisables, vous pouvez les utiliser pour effectuer une récupération sans perte de données.
Pour contrôler l'écriture des fichiers WAL, vous pouvez configurer les paramètres suivants :
| Paramètre | Description |
|---|---|
|
Indique la fréquence à laquelle le programme d'écriture WAL vide le WAL sur le disque, sauf si l'écriture est réactivée plus tôt par une transaction qui s'engage de manière asynchrone. La valeur par défaut est de 200 ms. L'augmentation de cette valeur réduit la fréquence des écritures, mais peut augmenter la quantité de données perdues en cas de plantage du serveur. |
|
Spécifie la quantité de données WAL pouvant s'accumuler avant que l'enregistreur WAL ne force une vidange sur le disque. La valeur par défaut est de 1 Mo. Si la valeur est définie sur zéro, les données WAL sont toujours vidées immédiatement sur le disque. |
|
Indique si le commit renvoie une réponse à l'utilisateur avant que les données WAL ne soient vidées sur le disque. Le paramètre par défaut est on, ce qui garantit la durabilité de la transaction. En d'autres termes, le commit a été écrit sur le disque avant de renvoyer un code de réussite à l'utilisateur. Si la valeur est définie sur off, la transaction est écrite sur le disque après un maximum de trois wal_writer_delay. |
Surveillance de l'utilisation du WAL
Vous pouvez utiliser les méthodes suivantes pour observer l'utilisation de WAL :
| Méthode d'observation | Description |
|---|---|
|
Cette vue standard comporte les colonnes wal_write et wal_sync, qui stockent le nombre d'écritures et de synchronisations WAL. Lorsque le paramètre de configuration track_wal_io_timing est activé, wal_write_time et wal_sync_time sont également stockés. Des instantanés réguliers de cette vue peuvent aider à afficher l'activité d'écriture et de synchronisation WAL au fil du temps. |
pg_current_wal_lsn() |
Cette fonction renvoie la position actuelle du numéro de séquence de journal (lsn), qui, lorsqu'elle est associée à un code temporel et collectée sous forme d'instantanés au fil du temps, peut fournir les octets/seconde de WAL générés à l'aide de la fonction pg_wal_lsn_diff(lsn1, lsn2).
Cette fonction est une métrique utile pour comprendre le taux de transactions et les performances des fichiers WAL. |
Insérer des données WAL en flux continu vers un emplacement distant
Lorsque vous utilisez Barman, les données WAL peuvent également être configurées pour être diffusées en temps réel vers un emplacement distant afin de garantir une perte de données minime, voire nulle, lors de la récupération. Malgré le streaming en temps réel, il existe une faible probabilité de perdre des transactions validées, car les écritures de streaming sur le serveur Barman distant sont asynchrones par défaut. Toutefois, il est possible de configurer le streaming WAL à l'aide du mode synchrone qui stocke le WAL et renvoie une réponse d'état à la base de données source. Gardez à l'esprit que cette approche peut ralentir les transactions si elles doivent attendre la fin de cette écriture avant de continuer.
Planifications de sauvegarde
Dans la plupart des environnements, les sauvegardes sont généralement planifiées toutes les semaines. Voici un exemple de programme de sauvegarde hebdomadaire :
- Dimanche : sauvegarde complète
- Lundi et mardi : sauvegarde
- Mercredi : sauvegarde différentielle
- Jeudi et vendredi : sauvegarde incrémentielle
- Samedi : sauvegarde différentielle
En utilisant ce calendrier type, une période de récupération continue d'une semaine nécessite un espace de stockage pour un maximum de trois sauvegardes complètes, ainsi que les sauvegardes incrémentielles ou différentielles requises. Cette approche permet de récupérer les données en cas d'échec lors de la sauvegarde complète du dimanche. La récupération de la base de données doit s'étendre au dimanche précédent le début de la sauvegarde.
Pour minimiser le RTO avec un RPO potentiellement plus élevé, des bases de données supplémentaires peuvent fonctionner en mode de récupération continue. Cela implique de relire les sauvegardes et de mettre à jour en permanence l'environnement secondaire en archivant et en relisant les nouveaux fichiers WAL. Le RPO réel, qui reflète la perte de données potentielle, dépend de la fréquence des transactions, de la taille des fichiers WAL et de l'utilisation du streaming WAL.
Restaurer dans un environnement non Kubernetes
Pour les déploiements non Kubernetes, la restauration d'une base de données AlloyDB Omni implique d'arrêter le conteneur Docker, puis de restaurer les données, ou de restaurer les données à un autre emplacement et de lancer une nouvelle instance Docker à l'aide de ces données restaurées. Une fois le conteneur redémarré, la base de données est accessible avec les données restaurées.
Pour en savoir plus sur les options de récupération, consultez Restaurer un cluster AlloyDB Omni à l'aide de pgBackRest et Restaurer un cluster AlloyDB Omni à l'aide de Barman.
Restaurer dans Kubernetes à l'aide de l'opérateur
Pour restaurer une base de données dans Kubernetes, l'opérateur propose une récupération dans le même cluster et espace de noms Kubernetes, à partir d'une sauvegarde nommée ou d'un clone à partir d'un point dans le temps (PIT). Pour cloner une base de données dans un autre cluster Kubernetes, utilisez pgBackRest. Pour en savoir plus, consultez Sauvegarder et restaurer dans Kubernetes et Cloner un cluster de bases de données à partir d'une sauvegarde Kubernetes.
Implémentation
Lorsque vous choisissez une architecture de référence de disponibilité, gardez à l'esprit les avantages, les limites et les alternatives suivants.
Avantages
- Facile à utiliser et à gérer, et adapté aux bases de données non critiques avec un RTO/RPO souple.
- Matériel supplémentaire minimal requis
- Les sauvegardes sont toujours requises pour un plan de reprise après sinistre complet.
- Il est possible de récupérer les données à n'importe quel moment de la période de récupération.
Limites
- Des exigences de stockage potentiellement supérieures à celles de la base de données elle-même, en fonction des exigences de conservation.
- La récupération peut être lente et entraîner un RTO plus élevé.
- Cela peut entraîner une perte de données, en fonction de la disponibilité des données WAL actuelles après une défaillance de la base de données, ce qui peut avoir un impact négatif sur le RPO.
Alternatives
- Envisagez d'utiliser l'architecture de disponibilité Enhanced (Améliorée) ou Premium (Premium) pour améliorer la disponibilité et les options de reprise après sinistre.
Étapes suivantes
- Présentation de l'architecture de référence de la disponibilité d'AlloyDB Omni
- Disponibilité améliorée d'AlloyDB Omni
- Disponibilité d'AlloyDB Omni Premium
- Installez AlloyDB Omni sur Kubernetes.
- Configurez pgBackRest pour AlloyDB Omni.
- Configurez Barman pour AlloyDB Omni.
- Sauvegarder et restaurer dans Kubernetes
- Restaurer un cluster AlloyDB Omni à l'aide de pgBackRest
- Restaurez un cluster AlloyDB Omni à l'aide de Barman.
- Sauvegarder et restaurer dans Kubernetes
- Cloner un cluster de bases de données à partir d'une sauvegarde Kubernetes