Garantir a fiabilidade e a qualidade da sua configuração de alta disponibilidade do Patroni é fundamental para manter as operações contínuas da base de dados e minimizar o tempo de inatividade. Esta página oferece um guia abrangente para testar o seu cluster Patroni, que abrange vários cenários de falha, consistência da replicação e mecanismos de comutação por falha.
Teste a configuração do Patroni
Ligue-se a qualquer uma das suas instâncias do patroni (
alloydb-patroni1,alloydb-patroni2oualloydb-patroni3) e navegue para a pasta do patroni do AlloyDB Omni.cd /alloydb/
Inspecione os registos do Patroni.
docker compose logs alloydbomni-patroni
As últimas entradas devem refletir informações sobre o nó Patroni. Deve ver algo semelhante ao seguinte.
alloydbomni-patroni | 2024-06-12 15:10:29,020 INFO: no action. I am (patroni1), the leader with the lock alloydbomni-patroni | 2024-06-12 15:10:39,010 INFO: no action. I am (patroni1), the leader with the lock alloydbomni-patroni | 2024-06-12 15:10:49,007 INFO: no action. I am (patroni1), the leader with the lockEstabeleça ligação a qualquer instância que execute o Linux com conetividade de rede à sua instância Patroni principal,
alloydb-patroni1, e obtenha informações sobre a instância. Pode ter de instalar a ferramentajqexecutando o comandosudo apt-get install jq -y.curl -s http://alloydb-patroni1:8008/patroni | jq .
Deve ver algo semelhante ao seguinte.
{ "state": "running", "postmaster_start_time": "2024-05-16 14:12:30.031673+00:00", "role": "master", "server_version": 150005, "xlog": { "location": 83886408 }, "timeline": 1, "replication": [ { "usename": "alloydbreplica", "application_name": "patroni2", "client_addr": "10.172.0.40", "state": "streaming", "sync_state": "async", "sync_priority": 0 }, { "usename": "alloydbreplica", "application_name": "patroni3", "client_addr": "10.172.0.41", "state": "streaming", "sync_state": "async", "sync_priority": 0 } ], "dcs_last_seen": 1715870011, "database_system_identifier": "7369600155531440151", "patroni": { "version": "3.3.0", "scope": "my-patroni-cluster", "name": "patroni1" } }
Chamar o ponto final da API HTTP do Patroni num nó do Patroni expõe vários detalhes acerca do estado e da configuração dessa instância específica do PostgreSQL gerida pelo Patroni, incluindo informações do estado do cluster, cronologia, informações do WAL e verificações de estado que indicam se os nós e o cluster estão a funcionar corretamente.
Teste a configuração do HAProxy
Num computador com um navegador e conetividade de rede ao seu nó HAProxy, aceda ao seguinte endereço:
http://haproxy:7000. Em alternativa, pode usar o endereço IP externo da instância do HAProxy em vez do respetivo nome de anfitrião.Deve ver algo semelhante à seguinte captura de ecrã.
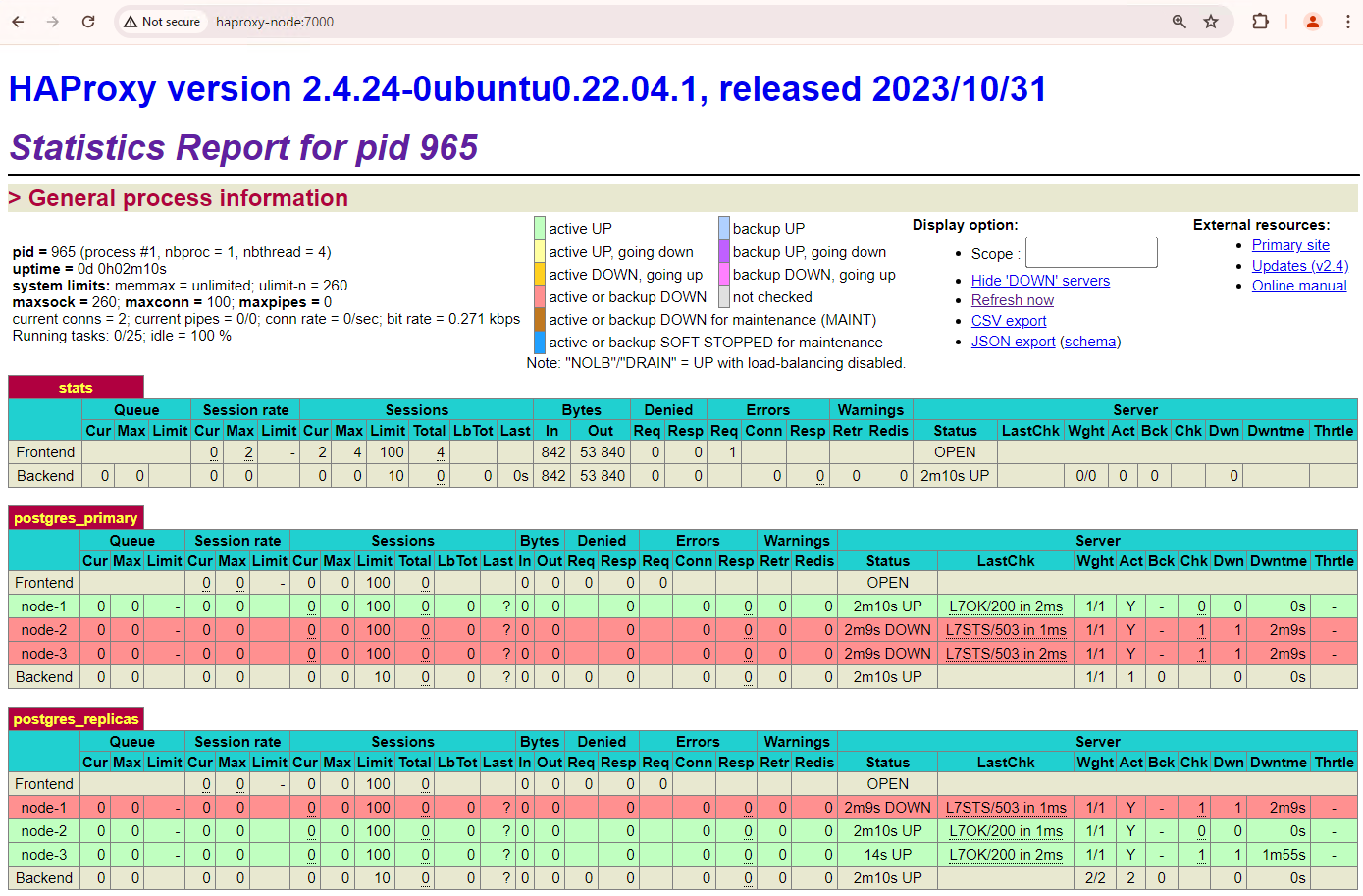
Figura 1. Página de estado do HAProxy a mostrar o estado de funcionamento e a latência dos nós do Patroni.
No painel de controlo do HAProxy, pode ver o estado de funcionamento e a latência do seu nó Patroni principal,
patroni1, e das duas réplicas,patroni2epatroni3.Pode executar consultas para verificar as estatísticas de replicação no seu cluster. A partir de um cliente, como o pgAdmin, estabeleça ligação ao servidor de base de dados principal através do HAProxy e execute a seguinte consulta.
SELECT pid, usename, application_name, client_addr, state, sync_state FROM pg_stat_replication;Deve ver algo semelhante ao seguinte diagrama, que mostra que
patroni2epatroni3estão a fazer streaming a partir depatroni1.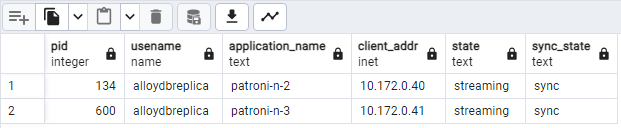
Figura 2. Saída de pg_stat_replication que mostra o estado de replicação dos nós do Patroni.
Teste a comutação automática por falha
Nesta secção, no cluster de três nós, simulamos uma indisponibilidade no nó principal parando o contentor Patroni em execução anexado. Pode parar o serviço Patroni no nó principal para simular uma indisponibilidade ou aplicar algumas regras de firewall para parar a comunicação com esse nó.
Na instância principal do Patroni, navegue para a pasta do AlloyDB Omni Patroni.
cd /alloydb/
Pare o contentor.
docker compose down
Deverá ver algo semelhante ao seguinte resultado. Isto deve validar que o contentor e a rede foram parados.
[+] Running 2/2 ✔ Container alloydb-patroni Removed ✔ Network alloydbomni-patroni_default RemovedAtualize o painel de controlo do HAProxy e veja como ocorre a comutação por falha.
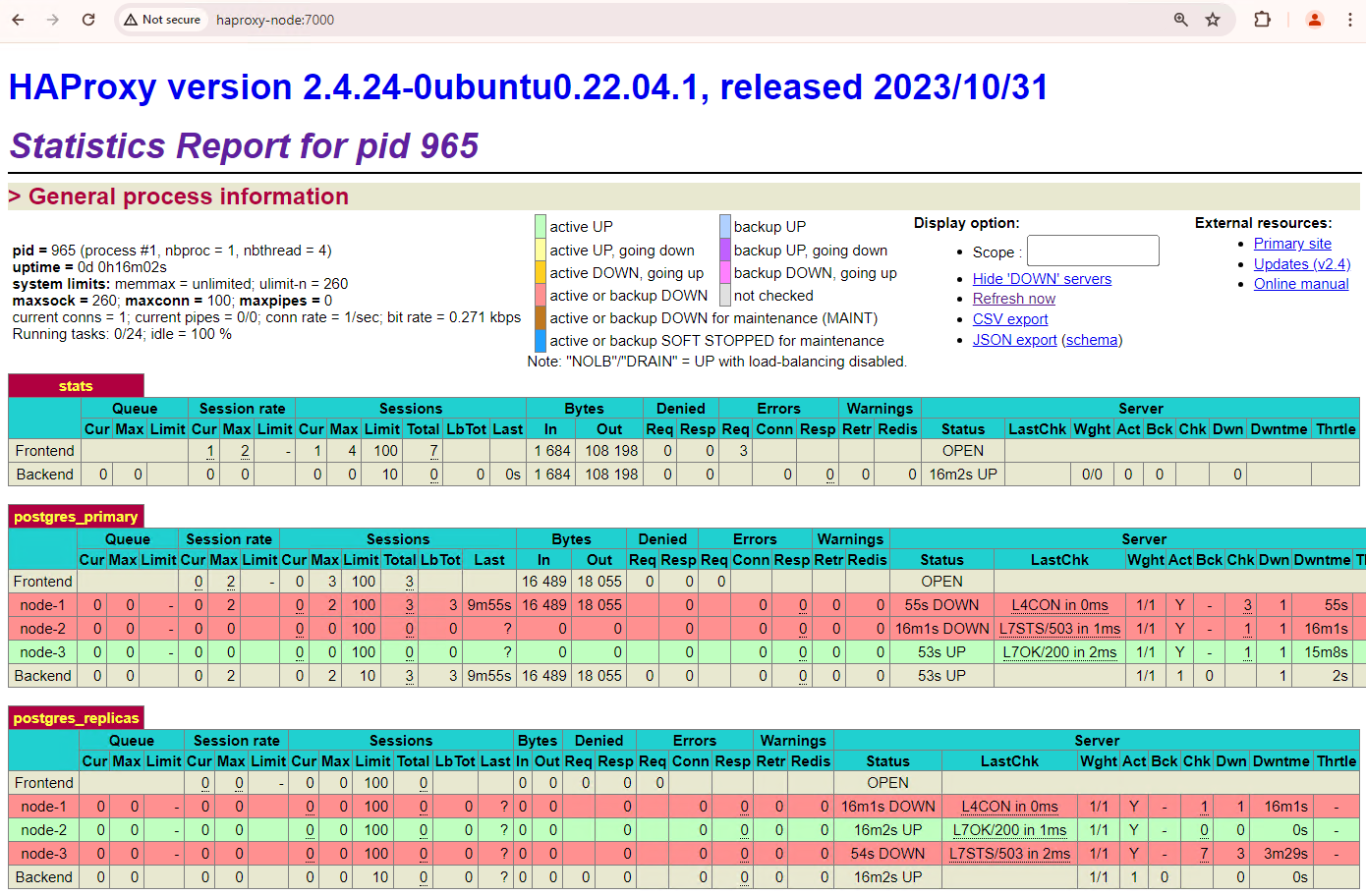
Figura 3. Painel de controlo do HAProxy a mostrar a comutação por falha do nó principal para o nó de reserva.
A instância
patroni3tornou-se a nova instância principal epatroni2é a única réplica restante. O principal anterior,patroni1, está inativo e as verificações de estado falham para o mesmo.O Patroni executa e gere a comutação por falha através de uma combinação de monitorização, consenso e orquestração automatizada. Assim que o nó principal não renovar a respetiva concessão dentro de um limite de tempo especificado ou se comunicar uma falha, os outros nós no cluster reconhecem esta condição através do sistema de consenso. Os restantes nós coordenam-se para selecionar a réplica mais adequada para promover como a nova réplica principal. Assim que é selecionada uma réplica candidata, o Patroni promove este nó a principal aplicando as alterações necessárias, como a atualização da configuração do PostgreSQL e a repetição de todos os registos WAL pendentes. Em seguida, o novo nó principal atualiza o sistema de consenso com o respetivo estado, e as outras réplicas reconfiguram-se para seguir o novo nó principal, incluindo a mudança da respetiva origem de replicação e, potencialmente, a sincronização com quaisquer novas transações. O HAProxy deteta o novo servidor principal e redireciona as ligações dos clientes em conformidade, garantindo uma interrupção mínima.
A partir de um cliente, como o pgAdmin, ligue-se ao servidor da base de dados através do HAProxy e verifique as estatísticas de replicação no cluster após a comutação por falha.
SELECT pid, usename, application_name, client_addr, state, sync_state FROM pg_stat_replication;Deve ver algo semelhante ao seguinte diagrama, que mostra que apenas o dispositivo
patroni2está a fazer streaming agora.
Figura 4. Saída de pg_stat_replication que mostra o estado de replicação dos nós do Patroni após a comutação por falha.
O seu cluster de três nós pode sobreviver a mais uma indisponibilidade. Se parar o nó principal atual,
patroni3, ocorre outra comutação por falha.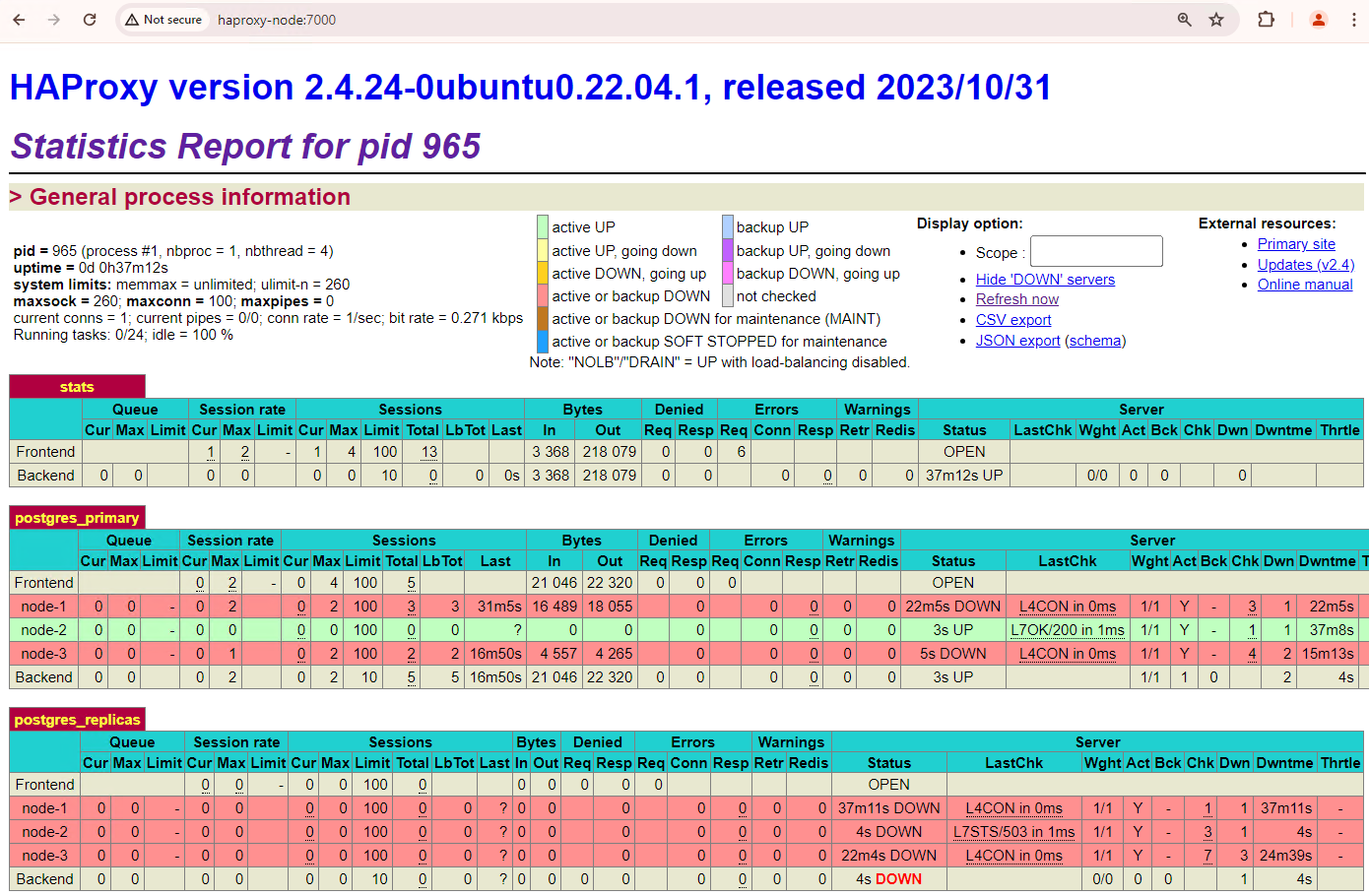
Figura 5. Painel de controlo do HAProxy a mostrar a comutação por falha do nó principal,
patroni3, para o nó de reserva,patroni2.
Considerações sobre o alternativo
A reversão é o processo de reposição do nó de origem anterior após uma comutação por falha. Geralmente, a alternativa automática não é recomendada num cluster de base de dados de alta disponibilidade devido a vários problemas críticos, como a recuperação incompleta, o risco de cenários de divisão de cérebro e o atraso na replicação.
No cluster do Patroni, se ativar os dois nós com os quais simulou uma interrupção, estes voltam a juntar-se ao cluster como réplicas em espera.
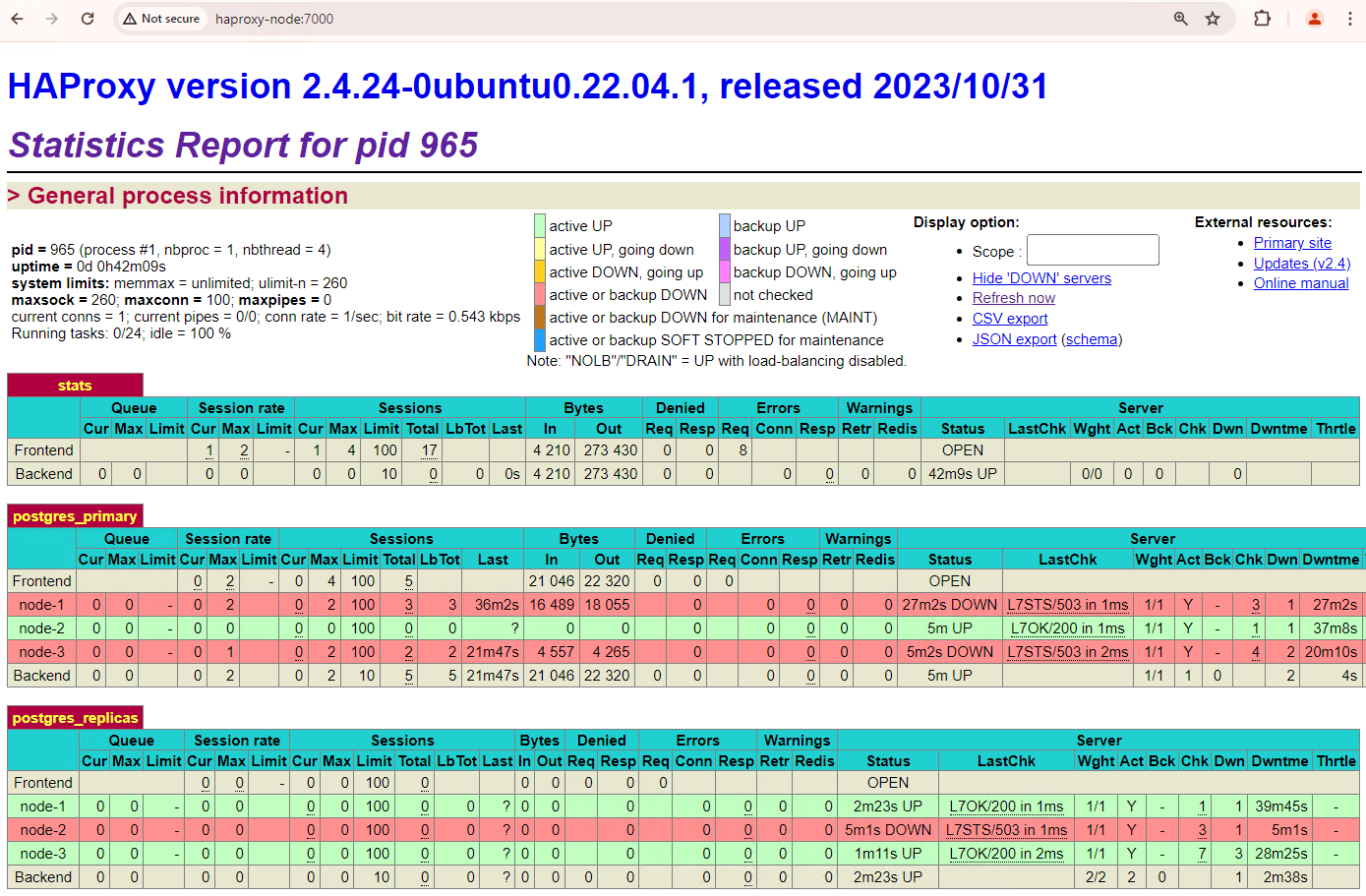
Figura 6. Painel de controlo do HAProxy a mostrar o restauro de patroni1 e patroni3 como nós de espera.
Agora, patroni1 e patroni3 estão a ser replicados a partir do principal atual patroni2.

Figura 7. Saída de pg_stat_replication que mostra o estado de replicação dos nós do Patroni após o fallback.
Se quiser reverter manualmente para o seu principal inicial, pode fazê-lo através da interface de linha de comandos patronictl. Ao optar pela alternativa manual, pode garantir um processo de recuperação mais fiável, consistente e totalmente validado, mantendo a integridade e a disponibilidade dos seus sistemas de base de dados.