使用场景
此可用性参考架构适用于以下应用场景:
- 对 RTO 和 RPO 要求较低的业务关键型应用。
- 您希望在另一个可用区或节点中部署副本,以便为数据库提供高可用性,并防范实例、服务器及可用区级故障。
- 您希望防范用户错误及数据损坏风险(通过使用备份)。
参考架构的运作方式
增强型可用性在标准可用性的基础上,通过在区域内添加读取副本实例来实现高可用性 (HA),从而缩短恢复时间目标 (RTO)。此方法还允许将事务性更改流式传输到副本,从而减少恢复点目标 (RPO)。
AlloyDB Omni 中的高可用性至少需要两个数据库实例。一个实例充当主数据库,支持读取和写入操作。其余实例充当读取副本,以只读模式运行。
以下是重要的高可用性概念:
- 故障切换是指在发生意外中断期间,当主实例发生故障或变得不可用时,激活备用副本以让其接管主实例模式(读写)职责的过程。此过程称为“提升”。通常,在这些场景中,在主服务器或数据库恢复在线状态后,必须重建数据库并让其充当备用数据库。为了提供高正常运行时间,我们已设置相关机制来自动执行故障切换。
- 切换(也称为角色逆转)是一种用于在主数据库与其中一个备用数据库之间切换模式的过程,这样主数据库会成为备用数据库,而备用数据库则会成为主数据库。切换通常以受控的优雅方式进行,并且可以出于多种原因而发起,例如,为了对先前的主数据库进行停机及补丁更新。优雅切换必须能够在未来切换回来,而无需重新实例化新的备用实例或复制配置的其他方面。
高可用性选项
为了支持高可用性,您可以按以下方式部署 AlloyDB Omni:
- 在使用 AlloyDB Omni Kubernetes 操作器的 Kubernetes 环境中。如需了解详情,请参阅在 Kubernetes 中管理高可用性。
- 使用适合非 Kubernetes 部署的 Patroni 和 HAProxy。如需了解详情,请参阅 AlloyDB Omni for PostgreSQL 的高可用性架构。
| 注意:Patroni 和 HAProxy 是非商业性的第三方工具,与 AlloyDB Omni 兼容。 |
|---|
我们建议您至少拥有两个备用数据库,这样即使丢失一个数据库,也不会影响集群的高可用性。在该模式下,在发生故障切换或节点进行任何计划内维护时,您至少具有一个高可用性对。
如需规划 AlloyDB Omni 部署的大小及类型,请参阅规划虚拟机上的 AlloyDB Omni 安装。
负载均衡器
有助于更顺畅地执行切换和故障切换过程的另一个重要机制是具有负载均衡器。对于非 Kubernetes 部署,由 HAProxy 软件提供负载均衡。HAProxy 通过在多个服务器之间分配网络流量来提供负载均衡。HAProxy 还通过执行健康检查来维护其连接到的后端服务器的健康状况。如果有服务器未通过健康检查,HAProxy 会停止向其发送流量,直到该服务器再次通过健康检查。
Kubernetes 操作器会部署自己的负载均衡器,其行为方式类似,为指向负载均衡器的数据库创建一个服务,以便用户透明地使用该服务。
高可用性
如果主数据库发生故障,部署在区域内的读取副本数据库可提供高可用性。当主数据库发生故障时,备用数据库会被提升以取代主数据库,并且应用会继续运行,几乎不会或根本不会中断。
一般来说,最好每年或每半年进行一次定期检查(以切换的形式),以确保依赖这些数据库的所有应用都仍能在适当的时间范围内进行连接和响应。
通过将一个备用读取副本放置在与主数据库不同的可用区中,可以使用任一种部署类型来实现可用区级保护。
拥有读取副本的另一个好处是,能够将只读操作分流到备用数据库,这些数据库可以使用最新数据充当报告数据库。此方法可减少读写主实例的负载和开销。
备份和高可用性配置
读取副本可以在多个可用区内设置,从而实现高可用性。由于它们所能实现的 RTO 和 RPO 较低,因此可能无法防范某些中断情况,例如逻辑数据损坏(如意外删除表或数据更新不正确)。因此,除了设置高可用性之外,还应定期进行备份。如需了解详情,请参阅“标准可用性架构”文档。
图 1 显示了一个推荐的高可用性配置,其中包含两个位于不同可用区的读取副本备用数据库。
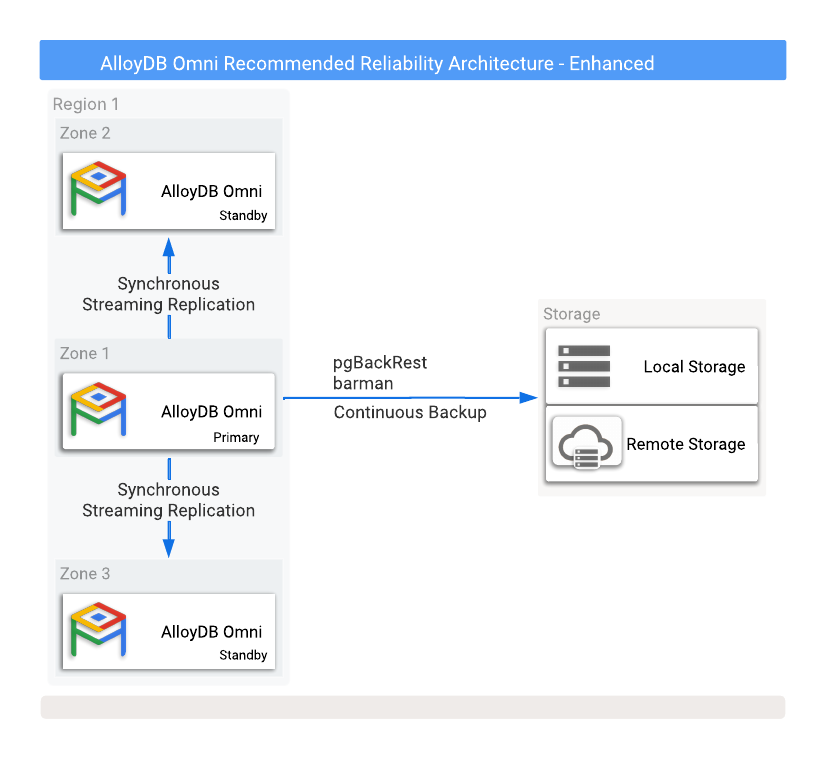
图 1. 支持备份和高可用性选项的 AlloyDB Omni。
为了防止主实例发生故障时数据丢失,必须以同步模式配置复制。虽然此方法可提供强大的数据保护,但它可能会影响主数据库性能,因为所有提交内容都需要同时写入主数据库及所有同步的备用数据库。对于此设置,在这些数据库实例之间实现低延迟网络连接至关重要。
Kubernetes 高可用性部署
对于 Kubernetes 部署,通过对 AlloyDB Omni 部署文件进行一些基本的属性更改和添加,您可以添加故障切换备用副本或读取副本,以应对主数据库故障。可以配置故障切换备用副本和只读副本,并且由操作器来负责预配和发布服务。该操作器还可自动执行许多高可用性过程,例如在故障切换后重建备用数据库,以及使用 AlloyDB Omni Kubernetes 引擎内置的修复机制。
在 Kubernetes 部署中,基础架构和应用可用性得益于内置的 Kubernetes 功能,这些功能可处理节点和 Pod 故障,包括:
- kube-controller-manager
node-status-update-frequency、node-monitor-period、node-monitor-grace-period和pod-eviction-timeout.等参数
除了提供内置保护之外,该操作器还公开了以下参数,这些参数会影响对故障主实例或备用实例的检测:
healthcheckPeriodSeconds:健康检查之间的时间。默认值为 30 秒。autoFailoverTriggerThreshold:在启动故障切换之前健康检查连续失败的次数。默认值为 3。
如需了解详情,请参阅在 Kubernetes 中管理高可用性。
非 Kubernetes 高可用性部署
独立的非 Kubernetes 部署是一种手动配置,需要使用第三方工具来实现,与 Kubernetes 部署相比,它们设置和维护起来更加复杂。
当您使用非 Kubernetes 部署时,有一些参数会影响故障切换的检测方式以及在主服务器变得不可用后故障切换发生的速度。以下是这些参数的简要总结:
Ttl:在启动故障切换之前,锁定主数据库所花费时间的上限。默认值为 30 秒。Loop_wait:重新检查之前等待的时间量。默认值为 10 秒。Retry_timeout:由于网络故障而降级主实例之前的超时。默认值为 10 秒。
如需了解详情,请参阅 AlloyDB Omni for PostgreSQL 的高可用性架构。
实现
选择可用性参考架构时,请注意以下优势、限制和替代方案。
优势
- 防范实例故障。
- 防范服务器故障。
- 防范可用区故障。
- 与标准可用性相比,RTO 大幅缩短。
限制
- 无法针对区域级灾难提供额外保护。
- 同步复制对主实例的潜在性能影响。
- 在同步模式下配置 PostgreSQL WAL 流式传输可在正常运行或典型故障切换期间实现零数据丢失 (
RPO=0)。不过,此方法无法防范特定双重故障情况下的数据丢失,例如在所有备用实例都丢失或无法从主实例访问,且紧接着主实例重启时。
替代方案
后续步骤
- AlloyDB Omni 可用性参考架构概览。
- AlloyDB Omni 标准可用性。
- AlloyDB Omni 高级可用性。
- 规划虚拟机上的 AlloyDB Omni 安装。
- AlloyDB Omni for PostgreSQL 的高可用性架构。
- 在 Kubernetes 中管理高可用性。