用途
這項可用性參考架構適用於下列使用案例:
- 需要較低 RTO 和 RPO 的重要業務應用程式。
- 您想在其他可用區或節點中部署副本,為資料庫提供高可用性,並防範執行個體、伺服器和可用區故障。
- 您希望避免使用者錯誤和資料損毀 (使用備份)。
參考架構的運作方式
除了標準可用性之外,增強型可用性還會在區域內新增唯讀副本執行個體,以啟用高可用性 (HA),縮短復原時間目標 (RTO)。這種做法可讓交易變更串流至副本,進而縮短復原點目標 (RPO)。
AlloyDB Omni 的高可用性功能至少會使用兩個資料庫執行個體。其中一個執行個體會做為主要資料庫,支援讀取和寫入作業。其餘執行個體則做為唯讀備用資源,以唯讀模式運作。
以下是重要的 HA 概念:
- 容錯移轉是指在非預期服務中斷期間,主要執行個體發生故障或無法使用時,啟動待命備用資源以接管主要 (讀寫) 模式的程序。這項程序稱為「升級」。通常在這些情況下,主要伺服器或資料庫恢復連線後,必須重建資料庫,然後做為待機資料庫。為確保高正常運作時間,系統會自動執行容錯移轉。
- 切換 (也稱為角色反轉) 是一種程序,用於在主要資料庫和其中一個待命資料庫之間切換模式,讓主要資料庫變成待命資料庫,待命資料庫變成主要資料庫。切換通常會以受控的正常方式進行,且可因任何原因啟動,例如允許前一個主要資料庫停機和修補。安全切換必須允許日後切換回原狀態,而不需重新例項化新的待機或複寫設定的其他方面。
高可用性選項
如要支援高可用性,您可以透過下列方式部署 AlloyDB Omni:
- 在 Kubernetes 環境中,使用 AlloyDB Omni Kubernetes 運算子。詳情請參閱在 Kubernetes 中管理高可用性。
- 使用 Patroni 和 HAProxy,適用於非 Kubernetes 部署作業。詳情請參閱「PostgreSQL 適用的 AlloyDB Omni 高可用性架構」。
| 注意:Patroni 和 HAProxy 是非商業用途的第三方工具,與 AlloyDB Omni 相容。 |
|---|
建議您至少要有兩個待命資料庫,這樣即使其中一個資料庫發生故障,叢集的高可用性也不會受到影響。在該模式下,如果發生容錯移轉或節點的任何排定維護作業,您至少會有一組高可用性配對。
如要規劃 AlloyDB Omni 部署作業的大小和形狀,請參閱「在 VM 上規劃 AlloyDB Omni 安裝作業」。
負載平衡器
負載平衡器是另一個重要機制,可協助順利執行切換和容錯移轉程序。對於非 Kubernetes 部署作業,HAProxy 軟體提供負載平衡功能。HAProxy 會將網路流量分散到多部伺服器,藉此提供負載平衡功能。HAProxy 也會執行健康狀態檢查,維護所連線後端伺服器的健康狀態。如果伺服器未通過健康狀態檢查,HAProxy 會停止將流量傳送至該伺服器,直到伺服器再次通過健康狀態檢查為止。
Kubernetes 運算子會部署自己的負載平衡器,行為類似,並為指向負載平衡器的資料庫建立服務,讓使用者無須瞭解相關細節。
高可用性
如果主要資料庫發生故障,部署在區域內的唯讀副本資料庫可提供高可用性。主要資料庫發生故障時,待命資料庫會升級為主要資料庫,應用程式會繼續運作,停機時間極短或完全不會停機。
一般來說,建議定期 (每年或每半年) 執行切換作業,確保所有依賴這些資料庫的應用程式仍能連線,並在適當的時間範圍內回應。
如要達到區域層級的保護,可以使用任一部署類型,將其中一個待命唯讀備用資源放在與主要資料庫不同的可用區。
唯讀副本的另一項優點是,能夠將唯讀作業卸載至待命資料庫,這些資料庫可做為報表資料庫,使用最新資料。這種做法可減輕讀寫主要執行個體的負擔和負載。
備份和高可用性設定
您可以在多個可用區設定唯讀備用資源,以提供高可用性。雖然這些功能可提供低 RTO 和 RPO,但無法防範特定中斷情形,例如邏輯資料損毀 (如意外捨棄表格或資料更新錯誤)。因此除了設定高可用性,也應定期備份。詳情請參閱「標準可用性架構」說明文件。
圖 1 顯示建議的高可用性設定,其中包含兩個不同可用區中的兩個唯讀副本待命資料庫。
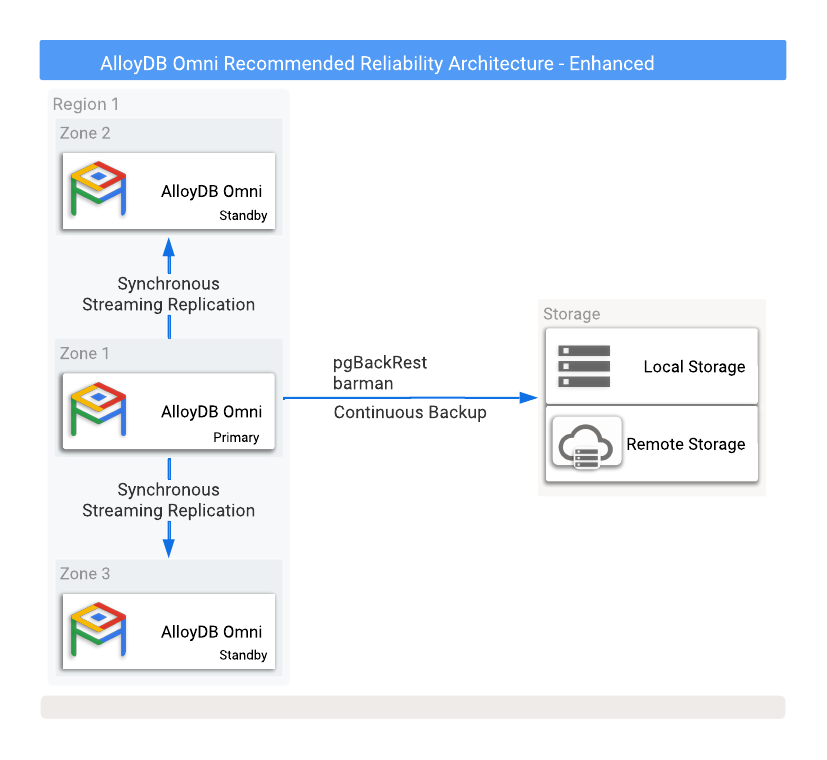
圖 1. AlloyDB Omni,提供備份和高可用性選項。
如要避免主要執行個體故障時遺失資料,請務必以同步模式設定複製功能。雖然這個方法可提供強大的資料保護功能,但所有提交作業都必須寫入主要資料庫和所有同步待命資料庫,因此可能會影響主要資料庫效能。這些資料庫執行個體之間的低延遲網路連線,是這項設定的關鍵。
Kubernetes HA 部署作業
如果是 Kubernetes 部署作業,只要在 AlloyDB Omni 部署檔案中變更及新增一些基本屬性,即可新增容錯移轉待命或讀取副本,以防主要資料庫發生故障。您可以設定容錯移轉待命和唯讀副本,而運算子會負責佈建及發布服務。此外,運算子也會自動執行許多高可用性程序,例如在容錯移轉後重建待機資料庫,以及使用 AlloyDB Omni Kubernetes 引擎內建的修復機制。
在 Kubernetes 部署作業中,基礎架構和應用程式可用性會受益於內建的 Kubernetes 功能,這些功能可處理節點和 Pod 故障,包括:
- kube-controller-manager
- 參數,例如
node-status-update-frequency、node-monitor-period、node-monitor-grace-period和pod-eviction-timeout.
除了內建保護機制,運算子還會公開下列參數,以影響主要或待機失敗的偵測結果:
healthcheckPeriodSeconds:健康狀態檢查之間的時間。預設值為 30 秒。autoFailoverTriggerThreshold:啟動容錯移轉前,連續健康狀態檢查失敗的次數。預設為 3。
詳情請參閱在 Kubernetes 中管理高可用性。
非 Kubernetes HA 部署作業
非 Kubernetes 部署作業是手動設定,需要第三方工具,設定和維護作業比 Kubernetes 部署作業更複雜。
使用非 Kubernetes 部署時,部分參數會影響容錯移轉的偵測方式,以及主要執行個體無法使用後多久會發生容錯移轉。以下簡要說明這些參數:
Ttl:啟動容錯移轉前,取得主要資料庫鎖定的時間上限。預設值為 30 秒。Loop_wait:重新檢查前等待的時間長度。預設值為 10 秒。Retry_timeout:由於網路故障而降級主要執行個體前的逾時時間。預設值為 10 秒。
詳情請參閱「PostgreSQL 適用的 AlloyDB Omni 高可用性架構」。
導入作業
選擇可用性參考架構時,請留意下列優點、限制和替代方案。
優點
- 防止執行個體故障。
- 防止伺服器故障。
- 防範可用區故障。
- 與標準可用性相比,RTO 大幅縮短。
限制
- 無法防範區域性災害。
- 同步複製作業可能會影響主要執行個體的效能。
- 以同步模式設定 PostgreSQL WAL 串流,可在正常運作或一般容錯移轉期間,確保資料不會遺失 (
RPO=0)。不過,這種做法無法避免特定雙重故障情況下的資料遺失,例如所有待命執行個體都遺失或無法從主要執行個體存取,且主要執行個體隨即重新啟動。
替代方案
後續步驟
- AlloyDB Omni 可用性參考架構總覽。
- AlloyDB Omni 標準版。
- AlloyDB Omni Premium 適用情形。
- 規劃在 VM 上安裝 AlloyDB Omni。
- PostgreSQL 適用的 AlloyDB Omni 高可用性架構。
- 在 Kubernetes 中管理高可用性。