모델을 학습시키거나 클라우드에서 예측을 할 때 발생하는 오류의 원인을 찾기란 쉽지 않습니다. 이 페이지에서는 AI Platform Training에서 발생하는 문제를 찾고 디버깅하는 방법에 대해 설명합니다. 사용 중인 머신러닝 프레임워크에 문제가 발생할 경우 머신러닝 프레임워크 문서를 대신 읽어보세요.
명령줄 도구
ERROR: (gcloud) Invalid choice: 'ai-platform'.이 오류는 gcloud 업데이트가 필요함을 의미합니다. gcloud를 업데이트하려면 다음 명령어를 실행합니다.
gcloud components updateERROR: (gcloud) unrecognized arguments: --framework=SCIKIT_LEARN.이 오류는 gcloud 업데이트가 필요함을 의미합니다. gcloud를 업데이트하려면 다음 명령어를 실행합니다.
gcloud components updateERROR: (gcloud) unrecognized arguments: --framework=XGBOOST.이 오류는 gcloud 업데이트가 필요함을 의미합니다. gcloud를 업데이트하려면 다음 명령어를 실행합니다.
gcloud components updateERROR: (gcloud) Failed to load model: Could not load the model: /tmp/model/0001/model.pkl. '\\x03'. (Error code: 0)이 오류는 모델을 내보내는 데 잘못된 라이브러리가 사용되었음을 의미합니다. 이 문제를 해결하려면 올바른 라이브러리를 사용하여 모델을 다시 내보냅니다. 예를 들어
model.pkl형태의 모델은pickle라이브러리를 사용하여 내보내고model.joblib형태의 모델은joblib라이브러리를 사용하여 내보냅니다.ERROR: (gcloud.ai-platform.jobs.submit.prediction) argument --data-format: Invalid choice: 'json'.이 오류는 일괄 예측 작업을 제출할 때
json이--data-format플래그의 값으로 지정되었음을 의미합니다.JSON데이터 형식을 사용하려면text를--data-format플래그의 값으로 제공해야 합니다.
Python 버전
ERROR: Bad model detected with error: "Failed to load model: Could not load the
model: /tmp/model/0001/model.pkl. unsupported pickle protocol: 3. Please make
sure the model was exported using python 2. Otherwise, please specify the
correct 'python_version' parameter when deploying the model. Currently,
'python_version' accepts 2.7 and 3.5. (Error code: 0)"
Python 3으로 내보낸 모델 파일을 Python 2.7로 설정된 AI Platform Training 모델 버전 리소스에 배포할 때 이 오류가 발생합니다.
이 문제를 해결하려면 다음 안내를 따르세요.
- 새 모델 버전 리소스를 만들고 'python_version'을 3.5로 설정합니다.
- 동일한 모델 파일을 새 모델 버전 리소스에 배포합니다.
virtualenv 명령어를 찾을 수 없음
virtualenv를 활성화하려 할 때 이 오류가 발생한 경우, 가능한 한 가지 해결방법은 virtualenv가 포함된 디렉터리를 $PATH 환경 변수에 추가하는 것입니다. 이 변수를 수정하면 전체 파일 경로를 입력하지 않고도 virtualenv 명령어를 사용할 수 있습니다.
먼저 다음 명령어를 실행하여 virtualenv를 설치합니다.
pip install --user --upgrade virtualenv
설치 프로그램이 $PATH 환경 변수를 수정하라는 메시지를 표시하고 virtualenv 스크립트에 대한 경로를 제공합니다. macOS에서는 /Users/[YOUR-USERNAME]/Library/Python/[YOUR-PYTHON-VERSION]/bin과 비슷하게 표시됩니다.
셸에서 환경 변수를 로드하는 파일을 엽니다. 일반적으로는 macOS에서 ~/.bashrc 또는 ~/.bash_profile입니다.
다음 줄을 추가하고 [VALUES-IN-BRACKETS]를 적절한 값으로 바꿉니다.
export PATH=$PATH:/Users/[YOUR-USERNAME]/Library/Python/[YOUR-PYTHON-VERSION]/bin
마지막으로 업데이트된 .bashrc(또는 .bash_profile) 파일을 로드하기 위해 다음 명령어를 실행합니다.
source ~/.bashrc
작업 로그 사용
문제해결을 시작하는 가장 좋은 방법은 Cloud Logging에서 캡처한 작업 로그를 확인하는 것입니다.
다양한 유형의 작업 로깅
다음 섹션에서 볼 수 있듯이 로깅 환경은 작업 유형에 따라 다릅니다.
학습 로그
모든 학습 작업은 로그에 기록됩니다. 이 로그에는 학습 서비스 및 학습 애플리케이션의 이벤트가 포함됩니다. 표준 Python 라이브러리를 사용하여(예: logging) 애플리케이션에 로깅 이벤트를 포함할 수 있습니다. AI Platform Training은 애플리케이션의 모든 로깅 메시지를 캡처합니다. stderr로 전송되는 모든 메시지는 Cloud Logging의 작업 항목에 자동으로 캡처됩니다.
일괄 예측 로그
모든 일괄 예측 작업은 로그에 기록됩니다.
온라인 예측 로그
온라인 예측 요청은 기본적으로 로그를 생성하지 않습니다. 모델 리소스를 만들 때 Cloud Logging을 사용 설정할 수 있습니다.
gcloud
gcloud ai-platform models create를 실행할 때 --enable-logging 플래그를 포함합니다.
Python
projects.models.create 호출을 위해 사용하는 Model 리소스에서 onlinePredictionLogging을 True로 설정합니다.
로그 찾기
분산 학습을 사용할 때 클러스터의 모든 프로세스 이벤트를 비롯한 작업의 모든 이벤트가 작업 로그에 기록됩니다. 분산 학습 작업을 실행 중인 경우 마스터 작업자 프로세스에 대한 작업 수준 로그가 보고됩니다. 일반적으로 오류를 해결하는 첫 번째 단계는 클러스터의 다른 프로세스에 대해 로깅된 이벤트를 필터링하여 해당 프로세스의 로그를 검사하는 것입니다. 이 섹션의 예시는 이러한 필터링을 설명합니다.
Google Cloud 콘솔의 명령줄 또는 Cloud Logging 섹션에서 로그를 필터링할 수 있습니다. 두 경우 모두 필요에 따라 필터에 다음 메타데이터 값을 사용합니다.
| 메타데이터 항목 | 필터링 결과 |
|---|---|
| resource.type | "cloud_ml_job"과 동일 |
| resource.labels.job_id | 작업 이름과 동일 |
| resource.labels.task_name | 마스터 작업자의 로그 항목만 읽기 위해 'master-replica-0'과 동일 |
| 심각도 | 오류 조건에 해당하는 로그 항목만 읽도록 오류보다 크거나 동일 |
명령줄
gcloud 베타 로깅 읽기를 사용하여 필요에 맞는 쿼리를 구성합니다. 예를 들면 다음과 같습니다.
각 예는 다음 환경 변수를 사용합니다.
PROJECT="my-project-name"
JOB="my_job_name"
원하는 경우 문자열 리터럴을 대신 입력할 수 있습니다.
작업 로그를 화면에 출력하는 방법은 다음과 같습니다.
gcloud ai-platform jobs stream-logs $JOB
gcloud ai-platform jobs stream-logs의 모든 옵션을 확인하세요.
마스터 작업자의 로그를 화면에 출력하는 방법은 다음과 같습니다.
gcloud beta logging read --project=${PROJECT} "resource.type=\"ml_job\" and resource.labels.job_id=${JOB} and resource.labels.task_name=\"master-replica-0\""
마스터 작업자의 오류 로그만 화면에 출력하는 방법은 다음과 같습니다.
gcloud beta logging read --project=${PROJECT} "resource.type=\"ml_job\" and resource.labels.job_id=${JOB} and resource.labels.task_name=\"master-replica-0\" and severity>=ERROR"
앞의 예시는 AI Platform Training의 학습 작업에서 로그를 필터링하는 가장 일반적인 경우입니다. Cloud Logging은 상세검색이 필요할 때 사용할 수 있는 여러 가지 강력한 필터링 옵션을 제공합니다. 고급 필터링 문서에서 이러한 옵션을 자세히 설명합니다.
콘솔
Google Cloud Console에서 AI Platform Training 작업 페이지를 엽니다.
작업 페이지 목록에서 실패한 작업을 선택하여 세부정보를 확인합니다.

- 로그 보기를 클릭하여 Cloud Logging을 엽니다.
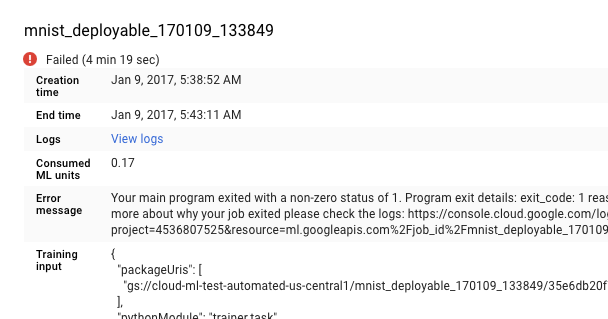
Cloud Logging으로 바로 이동할 수 있지만 추가 단계를 통해 작업을 찾을 수도 있습니다.
- 리소스 선택기를 펼칩니다.
- 리소스 목록에서 Cloud ML 작업을 확장합니다.
- job_id 목록에서 작업 이름을 찾습니다. 검색창에 작업 이름의 처음 몇 글자를 입력하여 표시되는 작업 범위를 좁힐 수 있습니다.
- 작업 항목을 펼치고 작업 목록에서
master-replica-0을 선택합니다.

로그에서 정보 얻기
작업에 적합한 로그를 찾아 master-replica-0으로 필터링하면 로깅된 이벤트를 검사하여 문제의 원인을 찾을 수 있습니다. 이때 표준 Python 디버깅 절차가 필요하며 주의 사항은 다음과 같습니다.
- 이벤트에는 여러 수준의 심각도가 있습니다. 필터링하여 오류 또는 오류 및 경고와 같은 특정 수준의 이벤트만 확인할 수 있습니다.
- 트레이너가 복구할 수 없는 오류 조건으로 종료되는 문제는(반환 코드 > 0) 스택 trace 이전에 예외로 로깅됩니다.
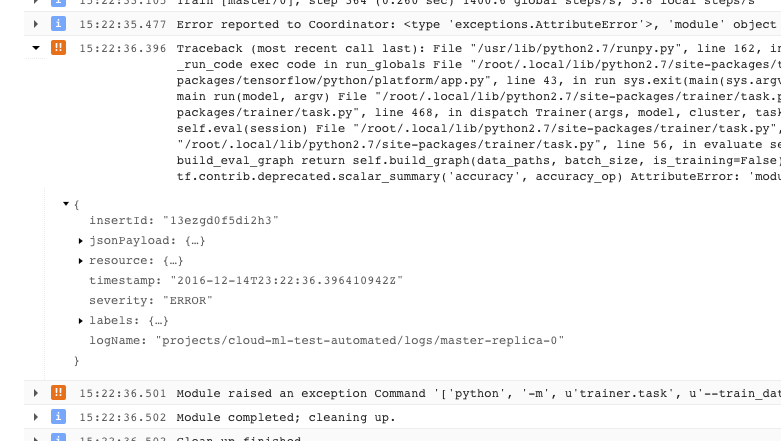
- 로깅된 JSON 메시지의 객체를 펼쳐 더 많은 정보를 가져올 수 있습니다(오른쪽 방향 화살표로 표시되며 콘텐츠는 {...} 형태로 나열됨). 예를 들어 jsonPayload를 펼치면 기본 오류 정보에 표시되는 것보다 더 읽기 쉬운 형식으로 스택 trace를 확인할 수 있습니다.
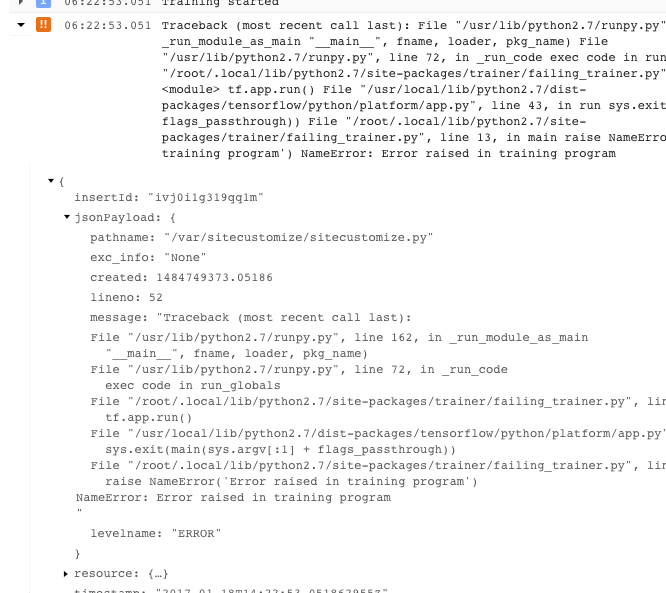
- 일부 오류는 재시도 가능한 오류의 인스턴스를 표시합니다. 이러한 오류는 일반적으로 스택 추적을 포함하지 않으므로 진단하기가 더 어려울 수 있습니다.
로깅을 최대한 활용
AI Platform Training의 학습 서비스는 다음 이벤트를 자동으로 로깅합니다.
- 서비스 내부의 상태 정보
- 트레이너 애플리케이션이
stderr로 전송하는 메시지 - 트레이너 애플리케이션이
stdout으로 전송하는 출력 텍스트
적절한 프로그래밍 권장사항을 따르면 트레이너 애플리케이션의 오류를 더 쉽게 해결할 수 있습니다.
- 의미 있는 메시지를 표준 오류로 전송합니다(예: 로깅을 통해).
- 문제가 생기면 가장 논리적이고 구체적인 예외를 발생시킵니다.
- 예외 객체에 설명 문자열을 추가합니다.
예외에 대한 자세한 내용은 Python 문서를 참조하세요.
학습 문제해결
이 섹션에서는 학습 작업에 적용되는 개념 및 오류 조건을 설명합니다.
학습 애플리케이션 반환 코드에 대한 이해
클라우드에서 학습 작업은 학습 클러스터의 마스터 작업자 프로세스에서 실행되는 기본 프로그램에 의해 제어됩니다.
- 분산되지 않은 단일 프로세스로 학습 중인 경우 유일한 작업자는 마스터 작업자입니다.
- 기본 프로그램은 TensorFlow 학습 애플리케이션의
__main__함수입니다. - AI Platform Training의 학습 서비스는 작업이 완료되거나 복구할 수 없는 오류가 발생할 때까지 트레이너 애플리케이션을 실행합니다. 즉, 재시도 가능한 오류가 발생하면 프로세스를 다시 시작할 수 있습니다.
학습 서비스는 프로세스를 관리하며, 마스터 작업자 프로세스의 반환 코드에 따라 프로그램 종료를 처리합니다.
| 반환 코드 | 의미 | AI Platform Training 응답 |
|---|---|---|
| 0 | 성공적으로 완료 | 종료 및 작업 리소스 해제 |
| 1~128 | 복구할 수 없는 오류 | 작업 종료 및 오류 로깅 |
__main__ 함수의 반환 코드와 관련해서는 특별한 작업을 수행할 필요가 없습니다. 작업이 성공적으로 완료되면 Python은 자동으로 0을 반환하고 처리되지 않은 예외가 발생하면 양수 코드를 반환합니다. 특정 반환 코드를 예외 객체(유효하지만 일반적이지 않은 방법)로 설정하는 데 익숙한 경우, 위 테이블의 패턴을 따르는 한 AI Platform Training 작업에 문제가 되지 않을 것입니다. 이렇게 해도 클라이언트 코드는 일반적으로 재시도 가능한 오류를 직접 나타내지 않으며 이러한 오류는 운영 환경에서 나타납니다.
특정 오류 조건 처리
이 섹션에서는 일부 사용자들에게 영향을 미치는 오류 조건에 대한 지침을 제공합니다.
리소스가 소진됨
us-central1 리전에서는 GPU와 컴퓨팅 리소스의 수요가 높습니다.
작업 로그에 'Resources are
insufficient in region: <region>. Please try a different region.'이라는 오류 메시지가 나타날 수 있습니다.
이 문제를 해결하려면 다른 리전을 사용하거나 나중에 다시 시도하세요.
트레이너가 구체적인 진전 없이 계속 실행됨
상황에 따라 학습 작업에 구체적인 진전 없이 트레이너 애플리케이션이 계속 실행될 수 있습니다. 이는 차단 호출이 사용 불가능한 리소스를 기다릴 때 발생할 수 있습니다. 이 문제는 트레이너에 시간 제한 간격을 구성하여 해결할 수 있습니다.
트레이너에 시간 제한 간격 구성
세션을 만들거나 그래프의 단계를 실행할 때 시간 제한을 밀리초 단위로 설정할 수 있습니다.
Session 객체를 만들 때 config 매개변수를 사용하여 원하는 시간 제한 간격을 설정합니다.
sess = tf.Session(config=tf.ConfigProto(operation_timeout_in_ms=500))Session.run 매개변수를 사용하여 Session.run에 대한 단일 호출에 원하는 제한 시간 간격을 설정합니다.
v = session.run(fetches, options=tf.RunOptions(timeout_in_ms=500))
자세한 내용은 TensorFlow 세션 문서를 참조하세요.
-9 코드로 프로그램 종료
-9 종료 코드가 지속적으로 발생한다면 트레이너 애플리케이션이 해당 프로세스에 할당된 것보다 더 많은 메모리를 사용 중일 수 있습니다. 메모리 사용량을 줄이거나 더 많은 메모리를 제공하는 머신 유형을 사용하여 이 오류를 해결합니다.
- 그래프 및 트레이너 애플리케이션에서 예상보다 많은 메모리를 사용하는 작업을 확인합니다. 메모리 사용량은 데이터의 복잡성 및 연산 그래프 작업의 복잡성에 의해 영향을 받습니다.
- 작업에 할당된 메모리를 늘리려면 약간의 기교가 필요할 수 있습니다.
- 정의된 확장 등급을 사용하는 경우 머신을 새로 추가하지 않으면 머신별로 할당된 메모리를 늘릴 수 없습니다. 이 경우 CUSTOM 등급으로 전환하여 클러스터에서 머신 유형을 직접 정의해야 합니다.
- 정의된 각 머신 유형의 정확한 구성은 변경될 수 있지만 대략적인 비교는 가능합니다. 학습 개념 페이지에서 머신 유형 비교 표를 확인하세요.
- 적절한 메모리 할당을 위해 머신 유형을 테스트할 때 발생하는 비용을 최소화하기 위해 단일 머신이나 크기가 작은 클러스터를 사용할 수 있습니다.
-15 코드로 프로그램 종료
일반적으로 -15 종료 코드는 시스템의 유지보수를 나타냅니다. 이는 재시도 가능한 오류이므로 프로세스가 자동으로 다시 시작됩니다.
장시간 대기 중인 작업
학습 작업의 상태가 장시간 동안 QUEUED이면 작업 요청 할당량을 초과했을 수 있습니다.
AI Platform Training은 선입 선출 규칙에 따라 작업 생성 시간을 기준으로 학습 작업을 시작합니다. 작업이 대기 중인 경우, 이는 일반적으로 프로젝트 할당량이 해당 작업보다 먼저 제출된 다른 작업에 의해 사용 중이거나 큐의 첫 번째 작업이 사용 가능한 할당량보다 많은 ML 단위/GPU를 요청한 경우입니다.
작업이 큐에 있는 이유는 학습 로그에 기록됩니다. 로그에서 다음과 비슷한 메시지를 검색합니다.
This job is number 2 in the queue and requires
4.000000 ML units and 0 GPUs. The project is using 4.000000 ML units out of 4
allowed and 0 GPUs out of 10 allowed.이 메시지는 해당 작업의 현재 큐 위치와 프로젝트의 현재 사용량 및 할당량을 설명합니다.
대기 사유는 작업 생성 시간순으로 처음 10개의 대기 작업에 대해서만 기록됩니다.
할당된 수보다 많은 요청을 주기적으로 실행해야 하는 경우에는 할당량 증가를 요청할 수 있습니다. 프리미엄 지원 패키지가 있는 경우 지원팀에 문의하세요. 그렇지 않은 경우 AI Platform Training 의견에 이메일로 요청을 보낼 수 있습니다.
할당량 초과
'project_number:...할당량 초과'와 같은 오류 메시지가 표시되면 리소스 할당량 중 하나를 초과했을 수 있습니다. 콘솔의 API 관리자에서 AI Platform Training 할당량 페이지를 통해 리소스 소비를 모니터링하고 증가를 요청할 수 있습니다.
잘못된 저장 경로
'잘못된 저장 경로 gs://...로 인해 복원 호출'과 같은 오류 메시지와 함께 작업이 종료되면 잘못 구성된 Google Cloud Storage 버킷을 사용 중일 수 있습니다.
Google Cloud Console에서 Google Cloud Storage 브라우저 페이지를 엽니다.
사용 중인 버킷의 기본 스토리지 클래스를 확인합니다.

- 기본 스토리지 클래스는 리전이어야 합니다. 이미 리전으로 설정되어 있다면 다른 문제가 있을 수 있습니다. 작업을 다시 실행해보세요.
- 다중 리전으로 설정되어 있다면 이를 리전으로 변경하거나 학습 자료를 다른 버킷으로 옮겨야 합니다. 전자의 경우 Cloud Storage 문서에서 버킷의 스토리지 클래스 변경에 대한 안내를 확인하세요.
AbortedError로 트레이너 종료
이 오류는 TensorFlow Supervisor를 사용하여 분산 작업을 관리하는 트레이너를 실행 중인 경우 발생할 수 있습니다. TensorFlow는 전체 작업이 중단되면 안 되는 상황에서 AbortedError 예외를 발생시키기도 합니다. 트레이너에서 이 예외를 포착하여 적절히 대응할 수 있습니다. AI Platform Training에서 실행하는 트레이너에는 TensorFlow Supervisor가 지원되지 않습니다.
예측 문제해결
이 섹션에서는 예측 진행 시 일반적으로 발생하는 문제를 다룹니다.
온라인 예측의 특정 상황 처리
이 섹션에서는 일부 사용자들에게 영향을 미치는 온라인 예측 오류 조건에 대한 지침을 제공합니다.
예측 완료까지 너무 많은 시간 소요(30~180초)
온라인 예측을 느리게 만드는 가장 일반적인 원인은 처리 노드를 0에서부터 확장하는 것입니다. 만약 모델에 정기적으로 예측 요청을 하는 경우 시스템은 하나 이상의 노드를 준비시켜 예측 작업에 사용합니다. 모델이 오랜 시간 동안 예측을 제공하지 않으면 서비스에서 준비 노드를 0으로 '축소'합니다. 이러한 축소가 일어난 후 실행되는 다음 예측 요청에는 평소보다 더 많은 시간이 걸립니다. 이는 해당 요청을 처리하기 위해 서비스에서 노드를 프로비저닝해야 하기 때문입니다.
HTTP 상태 코드
온라인 예측 요청에 오류가 발생하면 일반적으로 서비스에서 HTTP 상태 코드가 반환됩니다. 다음은 온라인 예측 환경에서 일반적으로 발생하는 코드와 그 의미입니다.
- 429 - 메모리 부족
모델을 실행하는 동안 처리 노드의 메모리가 부족합니다. 이 시점에서 예측 노드에 할당된 메모리를 늘릴 방법은 없습니다. 모델을 실행하기 위해 다음을 시도해볼 수 있습니다.
- 다음을 통해 모델 크기를 줄입니다.
- 정밀도가 낮은 변수 사용
- 지속적인 데이터 정량화
- 다른 입력 기능의 크기 줄이기(예: 더 짧은 단어 사용)
- 더 작은 인스턴스 배치를 사용하여 요청을 재전송
- 다음을 통해 모델 크기를 줄입니다.
- 429 - 보류 중인 요청이 너무 많음
모델이 처리할 수 있는 것보다 더 많은 요청을 받고 있습니다. 자동 확장을 사용 중인 경우 시스템이 확장하는 것보다 더 빠르게 요청을 받는 경우입니다.
자동 확장을 사용하면 지수 백오프로 요청을 재전송할 수 있습니다. 이렇게 하면 시스템이 확장할 시간을 벌 수 있습니다.
- 429 - 할당량
Google Cloud Platform 프로젝트에서 보낼 수 있는 요청은 100초당 10,000회(초당 약 100회)로 제한됩니다. 이 오류가 일시적으로 급증하는 경우 지수 백오프를 통해 재시도하여 모든 요청을 제시간에 처리할 수 있습니다. 이 코드가 지속적으로 나타나는 경우 할당량 증가를 요청할 수 있습니다. 자세한 내용은 할당량 페이지를 참조하세요.
- 503 - 시스템이 컴퓨터 네트워크에서 비정상적인 트래픽을 감지함
모델이 단일 IP에서 받은 요청의 비율이 너무 높아서 시스템에서 서비스 거부 공격을 의심합니다. 1분 동안 요청을 중단한 후 더 낮은 속도로 전송을 재개하세요.
- 500 - 모델을 로드할 수 없음
시스템이 모델을 로드하는 데 문제가 있는 경우입니다. 다음 단계를 시도해 보세요.
- 트레이너가 올바른 모델을 내보내고 있는지 확인합니다.
gcloud ai-platform local predict명령어로 테스트 예측을 시도합니다.- 모델을 다시 내보내고 로드를 재시도합니다.
예측 요청의 오류 형식 지정
다음 메시지는 모두 예측 입력과 관련되어 있습니다.
- '요청 본문에 비어 있거나 잘못된/유효하지 않은 JSON이 있음'
- 서비스가 요청에서 JSON을 파싱하지 못했거나 요청이 비어 있습니다. JSON을 무효화하는 오류 메시지나 누락이 있는지 확인합니다.
- '요청 본문에 누락된 '인스턴스' 필드가 있음'
- 요청 본문이 올바른 형식을 따르지 않는 경우입니다. 이는 모든 입력 인스턴스가 있는 목록을 포함하는
"instances"라는 단일 키를 가진 JSON 객체여야 합니다. - 요청 생성 시 JSON 인코딩 오류 발생
요청에 base64로 인코딩된 데이터가 포함되어 있지만 적절한 JSON 형식은 아닙니다. 각 base64 인코딩된 문자열은
"b64"라는 단일 키가 포함된 객체로 표시해야 합니다. 예를 들면 다음과 같습니다.{"b64": "an_encoded_string"}base64로 인코딩되지 않은 바이너리 데이터가 있는 경우에도 base64 오류가 발생합니다. 다음과 같이 데이터를 인코딩하고 형식을 지정합니다.
{"b64": base64.b64encode(binary_data)}자세한 내용은 바이너리 데이터 형식 지정 및 인코딩을 참조하세요.
데스크톱보다 클라우드에서 예측 소요 시간이 오래 걸림
온라인 예측은 높은 속도의 예측 요청을 신속하게 제공하도록 확장 가능한 서비스로 설계되었습니다. 이 서비스는 모든 제공 요청 전반의 집계 성능에 최적화되어 있습니다. 확장성에 중점을 두기 때문에 로컬 머신에서 작은 수의 예측을 생성할 때와는 다른 성능 특성을 갖게 됩니다.
다음 단계
- 지원 받기
- Google API 오류 모델, 특히
google.rpc.Code에 정의된 정규 오류 코드와 google/rpc/error_details.proto에 정의된 표준 오류 세부정보에 대해 자세히 알아보기 - 학습 작업을 모니터링하는 방법 알아보기
- Cloud TPU 문제 해결 및 FAQ에서 Cloud TPU와 함께 AI Platform Training을 실행할 때의 문제 진단 및 해결 방법 알아보기