
Gemini Enterprise Agent Platform
Innova, crea y despliega agentes listos para el ámbito empresarial
Gemini Enterprise Agent Platform es la plataforma integral de Google Cloud para que los desarrolladores creen, escalen, controlen y optimicen agentes. Es un destino único para que los equipos técnicos creen agentes que puedan transformar las aplicaciones y los flujos de trabajo empresariales en potentes sistemas basados en agentes.
Los nuevos clientes reciben hasta 300 USD en crédito sin coste económico para probar Agent Platform y otros productos de Google Cloud.
Características
Crea, escala, gobierna y optimiza agentes de IA de nivel empresarial
Agent Platform es nuestra plataforma abierta y completa que permite a las empresas crear, escalar, gobernar y optimizar rápidamente agentes de nivel empresarial basados en sus datos. Proporciona la base de pila completa y la amplia variedad de opciones para desarrolladores que necesitas para transformar tus aplicaciones y flujos de trabajo en sistemas basados en agentes potentes a escala mundial.
Gemini, los modelos multimodales más eficaces de Google
Agent Platform ofrece acceso a los últimos modelos de Gemini de Google, incluido Gemini 3. Gemini es capaz de comprender prácticamente cualquier entrada gracias a la combinación de diferentes tipos de información, y de generar casi cualquier salida. Prueba y envía prompts a Gemini en Agent Studio con texto, imágenes, vídeo o código. Gracias al razonamiento avanzado y las funciones innovadoras de generación de Gemini, los desarrolladores pueden probar peticiones de ejemplo para extraer texto de imágenes, convertir texto de imagen a JSON e incluso generar respuestas sobre imágenes subidas para crear aplicaciones de IA de nueva generación.

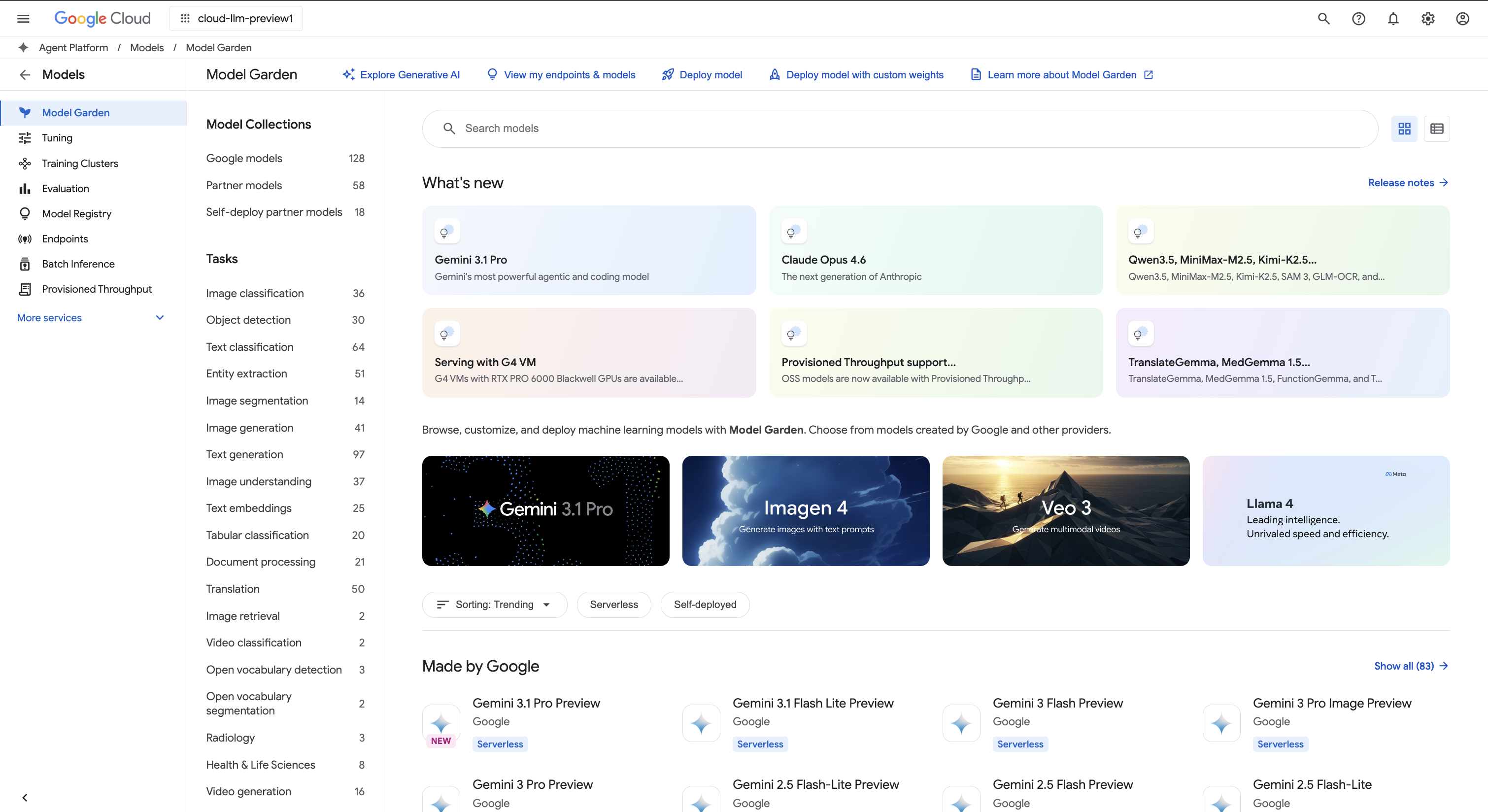
Más de 200 modelos y herramientas de IA generativa en Model Garden
Elige entre la más amplia variedad de modelos propios (Gemini, Imagen, Lyria, Chirp o Veo), de terceros (Anthropic's Claude Model Family) y abiertos (Gemmao Llama) disponibles en Model Garden. Usa extensiones para permitir que los modelos recuperen información en tiempo real y activen acciones. También puedes personalizar los modelos para tu caso práctico con una variedad de opciones de afinamiento.
Nuestro servicio de evaluación de modelos ofrece herramientas de nivel empresarial para realizar evaluaciones objetivas y basadas en datos de los modelos de IA generativa.
Plataforma de IA abierta e integrada
Los científicos de datos pueden agilizar su trabajo gracias a las herramientas de Agent Platform diseñadas específicamente para entrenar, ajustar y desplegar modelos de aprendizaje automático.
Los cuadernos de Agent Platform, incluidos Colab Enterprise o Workbench, están integrados de forma nativa en BigQuery, lo que proporciona una única superficie para todas las cargas de trabajo de datos e IA.
Training y Prediction te ayudan a reducir el tiempo de entrenamiento y a desplegar modelos en producción fácilmente con los frameworks de código abierto que elijas y la infraestructura de IA optimizada.
MLOps para la IA predictiva y generativa
Agent Platform ofrece herramientas de MLOps diseñadas específicamente para que los científicos de datos y los ingenieros de aprendizaje automático puedan automatizar, estandarizar y gestionar proyectos de aprendizaje automático.
Las herramientas modulares te ayudan a colaborar entre equipos y a mejorar modelos a lo largo de todo el ciclo de vida de desarrollo: identifica el modelo más adecuado para un caso práctico con Gen AI Evaluation, orquesta los flujos de trabajo con Pipelines , gestiona cualquier modelo con Model Registry, sirve, comparte y reutiliza las funciones de aprendizaje automático mediante Feature Store, y monitoriza los modelos para encontrar sesgos de entrada.
Cómo funciona
Agent Platform incluye un abanico de opciones para crear, entrenar modelos y desplegar agentes:
- Agent Platform te permite crear, escalar, gobernar y optimizar agentes listos para la empresa en una plataforma unificada
- La IA generativa te da acceso a grandes modelos de IA generativa, como Gemini 3, para que puedas evaluarlos, ajustarlos y desplegarlos para usarlos en tus aplicaciones basadas en IA
- Model Garden te permite descubrir, probar, personalizar y desplegar Agent Platform, así como seleccionar modelos y recursos de código abierto
- El entrenamiento personalizado te da un control absoluto sobre el proceso de entrenamiento, como usar el framework de aprendizaje automático que prefieras, escribir tu propio código de entrenamiento y elegir las opciones de ajuste de hiperparámetros
Agent Platform incluye un abanico de opciones para crear, entrenar modelos y desplegar agentes:
- Agent Platform te permite crear, escalar, gobernar y optimizar agentes listos para la empresa en una plataforma unificada
- La IA generativa te da acceso a grandes modelos de IA generativa, como Gemini 3, para que puedas evaluarlos, ajustarlos y desplegarlos para usarlos en tus aplicaciones basadas en IA
- Model Garden te permite descubrir, probar, personalizar y desplegar Agent Platform, así como seleccionar modelos y recursos de código abierto
- El entrenamiento personalizado te da un control absoluto sobre el proceso de entrenamiento, como usar el framework de aprendizaje automático que prefieras, escribir tu propio código de entrenamiento y elegir las opciones de ajuste de hiperparámetros
Crea e implementa agentes de IA
Accede a funciones avanzadas de IA con Agent Platform
Accede a funciones avanzadas de IA con Agent Platform
Crea agentes y aplicaciones de IA generativa listos para producción en una plataforma que se adapta a tus necesidades. Nuestra plataforma de agentes proporciona un entorno seguro para desarrollar y desplegar modelos y aplicaciones de IA.
Para los desarrolladores, Agent Platform sigue siendo nuestra plataforma avanzada donde pueden crear, personalizar y ajustar agentes sofisticados usando frameworks como Agent Development Kit (ADK).
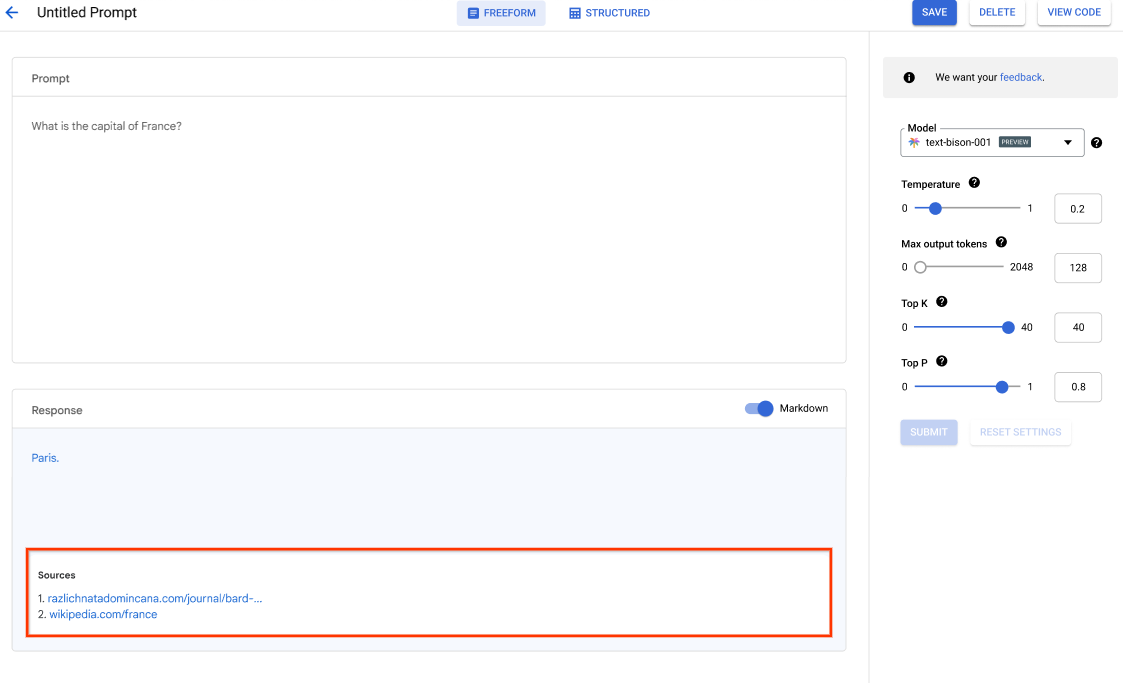
Empieza con este codelab y crea tu primera aplicación de IA hoy mismo
Tutoriales, guías de inicio rápido y experimentos
Accede a funciones avanzadas de IA con Agent Platform
Accede a funciones avanzadas de IA con Agent Platform
Crea agentes y aplicaciones de IA generativa listos para producción en una plataforma que se adapta a tus necesidades. Nuestra plataforma de agentes proporciona un entorno seguro para desarrollar y desplegar modelos y aplicaciones de IA.
Para los desarrolladores, Agent Platform sigue siendo nuestra plataforma avanzada donde pueden crear, personalizar y ajustar agentes sofisticados usando frameworks como Agent Development Kit (ADK).
Empieza con este codelab y crea tu primera aplicación de IA hoy mismo
Desarrolla con modelos de Gemini
Primeros pasos con los modelos multimodales de Google
Primeros pasos con los modelos multimodales de Google
Usa Agent Studio para diseñar, probar y gestionar peticiones para modelos de Gemini usando lenguaje natural, código, imágenes o vídeo. Prueba las peticiones de ejemplo para extraer texto de imágenes, convertirlas en HTML e incluso generar respuestas sobre imágenes subidas.
También puedes empezar a probar Gemini en Agent Platform con una clave de API.
Accede a modelos de Gemini a través de la API de Gemini en Agent Platform
- Python
- JavaScript
- Java
- Go
- Curl
Tutoriales, guías de inicio rápido y experimentos
Primeros pasos con los modelos multimodales de Google
Primeros pasos con los modelos multimodales de Google
Usa Agent Studio para diseñar, probar y gestionar peticiones para modelos de Gemini usando lenguaje natural, código, imágenes o vídeo. Prueba las peticiones de ejemplo para extraer texto de imágenes, convertirlas en HTML e incluso generar respuestas sobre imágenes subidas.
También puedes empezar a probar Gemini en Agent Platform con una clave de API.
Código de ejemplo
Accede a modelos de Gemini a través de la API de Gemini en Agent Platform
- Python
- JavaScript
- Java
- Go
- Curl
Extraer, resumir y clasificar datos
Usa la IA generativa para el resumen, la clasificación y la extracción
Usa la IA generativa para el resumen, la clasificación y la extracción
Aprende a crear prompts de texto para gestionar cualquier cantidad de tareas gracias a la compatibilidad con la IA generativa de Agent Platform. Algunas de las tareas más habituales son la clasificación, el resumen y la extracción. Gemini en Agent Platform te permite diseñar prompts flexibles en cuanto a su estructura y formato.
Tutoriales, guías de inicio rápido y experimentos
Usa la IA generativa para el resumen, la clasificación y la extracción
Usa la IA generativa para el resumen, la clasificación y la extracción
Aprende a crear prompts de texto para gestionar cualquier cantidad de tareas gracias a la compatibilidad con la IA generativa de Agent Platform. Algunas de las tareas más habituales son la clasificación, el resumen y la extracción. Gemini en Agent Platform te permite diseñar prompts flexibles en cuanto a su estructura y formato.
Desplegar un modelo para su uso en producción
Despliega para hacer predicciones online o por lotes
Despliega para hacer predicciones online o por lotes
Cuando tengas todo listo para usar tu modelo para resolver un problema real, regístralo en el registro de modelos y usa el servicio de predicción de Agent Platform para las predicciones por lotes y online.
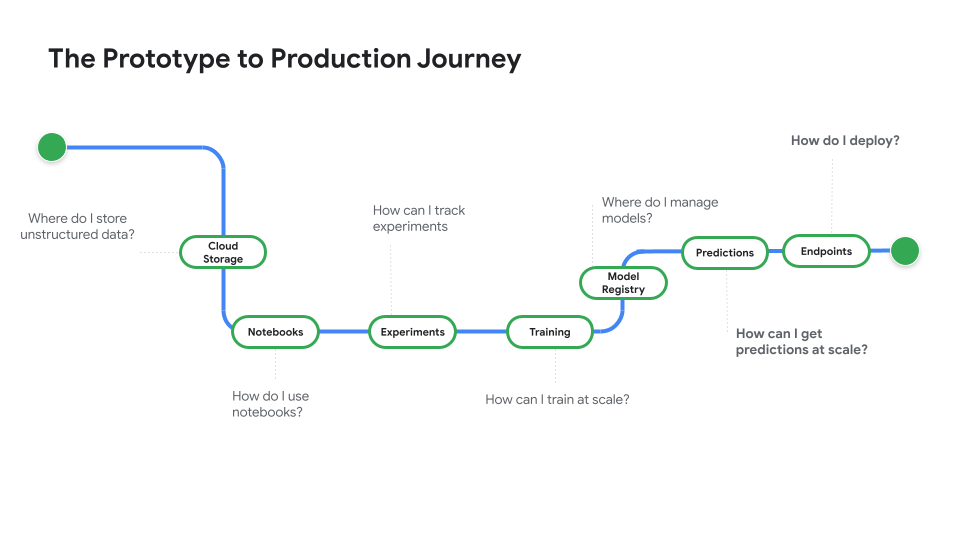
Echa un vistazo a Prototype to Production, una serie de vídeos que te traslada del código de un cuaderno a un modelo desplegado.
Tutoriales, guías de inicio rápido y experimentos
Despliega para hacer predicciones online o por lotes
Despliega para hacer predicciones online o por lotes
Cuando tengas todo listo para usar tu modelo para resolver un problema real, regístralo en el registro de modelos y usa el servicio de predicción de Agent Platform para las predicciones por lotes y online.
Echa un vistazo a Prototype to Production, una serie de vídeos que te traslada del código de un cuaderno a un modelo desplegado.
Preparación de modelos personalizados
Descripción general y documentación de la preparación de modelos personalizados
Descripción general y documentación de la preparación de modelos personalizados
Consulta un resumen del flujo de trabajo de entrenamiento personalizado de Agent Platform, las ventajas del entrenamiento personalizado y las diferentes opciones disponibles. En esta página también se detallan todos los pasos que forman parte del flujo de trabajo de entrenamiento del aprendizaje automático, desde la preparación de datos hasta las predicciones.
Consulta un videotutorial sobre los pasos necesarios para entrenar modelos personalizados en Agent Platform.
Tutoriales, guías de inicio rápido y experimentos
Descripción general y documentación de la preparación de modelos personalizados
Descripción general y documentación de la preparación de modelos personalizados
Consulta un resumen del flujo de trabajo de entrenamiento personalizado de Agent Platform, las ventajas del entrenamiento personalizado y las diferentes opciones disponibles. En esta página también se detallan todos los pasos que forman parte del flujo de trabajo de entrenamiento del aprendizaje automático, desde la preparación de datos hasta las predicciones.
Consulta un videotutorial sobre los pasos necesarios para entrenar modelos personalizados en Agent Platform.
Precios
| Cómo funcionan los precios de Agent Platform | Paga por las herramientas, el almacenamiento, los recursos de computación y los recursos de Cloud de Agent Platform que utilices. Los nuevos clientes reciben 300 USD en crédito sin coste económico para probar Agent Platform y otros productos de Google Cloud. | |
|---|---|---|
| Herramientas y uso | Descripción | Precio |
IA generativa | Modelo de imagen para generar imágenes Se basa en la entrada de imágenes, la entrada de caracteres o los precios del entrenamiento personalizado. | Desde 0,0001 USD |
Generación de texto, chat y código Basado en cada 1000 caracteres de entrada (solicitud) y cada 1000 caracteres de salida (respuesta). | Desde 0,0001 USD por cada 1000 caracteres | |
Modelos con entrenamiento personalizado | Preparación de modelo personalizado Se basa en el tipo de máquina utilizado por hora, la región y los aceleradores utilizados. Obtén una estimación a través de las ventas o nuestra calculadora de precios. | Contactar con Ventas |
Cuadernos de Agent Platform | Recursos de computación y almacenamiento Está basado en las mismas tarifas que para Compute Engine y Cloud Storage. | Consulta los productos |
Comisiones de gestión Además de este uso de recursos, se aplican tarifas de gestión según la región, las instancias, los cuadernos y los cuadernos gestionados que se utilicen. Ver detalles. | Consultar detalles | |
Flujos de procesamiento de Agent Platform | Ejecución y tarifas adicionales Se basan en los cargos de ejecución, los recursos utilizados y las cuotas de servicio adicionales. | Desde 0,03 USD por ejecución de flujo de procesamiento |
Agent Platform Vector Search | Costes de publicación y creación En función del tamaño de los datos, la cantidad de consultas por segundo (CPS) que quieras ejecutar y el número de nodos que uses. Ver ejemplo | Consulta el ejemplo |
Consulta los detalles de los precios de todas las funciones y servicios de Agent Platform.
Cómo funcionan los precios de Agent Platform
Paga por las herramientas, el almacenamiento, los recursos de computación y los recursos de Cloud de Agent Platform que utilices. Los nuevos clientes reciben 300 USD en crédito sin coste económico para probar Agent Platform y otros productos de Google Cloud.
IA generativa
Modelo de imagen para generar imágenes
Se basa en la entrada de imágenes, la entrada de caracteres o los precios del entrenamiento personalizado.
Starting at
0,0001 USD
Generación de texto, chat y código
Basado en cada 1000 caracteres de entrada (solicitud) y cada 1000 caracteres de salida (respuesta).
Starting at
0,0001 USD
por cada 1000 caracteres
Modelos con entrenamiento personalizado
Preparación de modelo personalizado
Se basa en el tipo de máquina utilizado por hora, la región y los aceleradores utilizados. Obtén una estimación a través de las ventas o nuestra calculadora de precios.
Contactar con Ventas
Cuadernos de Agent Platform
Recursos de computación y almacenamiento
Está basado en las mismas tarifas que para Compute Engine y Cloud Storage.
Consulta los productos
Comisiones de gestión
Además de este uso de recursos, se aplican tarifas de gestión según la región, las instancias, los cuadernos y los cuadernos gestionados que se utilicen. Ver detalles.
Consultar detalles
Flujos de procesamiento de Agent Platform
Ejecución y tarifas adicionales
Se basan en los cargos de ejecución, los recursos utilizados y las cuotas de servicio adicionales.
Starting at
0,03 USD
por ejecución de flujo de procesamiento
Agent Platform Vector Search
Costes de publicación y creación
En función del tamaño de los datos, la cantidad de consultas por segundo (CPS) que quieras ejecutar y el número de nodos que uses. Ver ejemplo
Consulta el ejemplo
Consulta los detalles de los precios de todas las funciones y servicios de Agent Platform.
Empieza tu prueba de concepto
Caso de negocio
Aprovecha todo el potencial de la IA generativa

"La precisión de la solución de IA generativa de Google Cloud y la utilidad práctica de Agent Platform Platform nos dan la confianza que necesitábamos para implementar esta tecnología vanguardista en los pilares de nuestro negocio y alcanzar el objetivo a largo plazo de reducir nuestro tiempo de respuesta a menos de 1 minuto".
Abdol Moabery, CEO de GA Telesis
Contenido relacionado
Informes de analistas
Google ha recibido la designación de líder en el informe IDC MarketScape del 2025 de entre todos los proveedores de software de modelos fundacionales del ciclo de vida de la IA generativa evaluados a nivel mundial. Descarga el informe
Google ha sido designado como uno de los líderes en el informe Gartner Magic Quadrant™ sobre plataformas de desarrollo de aplicaciones de IA del cuarto trimestre del 2025. Lee el informe
Google ha recibido la designación de líder en el informe Forrester Wave™ sobre plataformas de IA y aprendizaje automático del tercer trimestre del 2024. Leer el informe











