Encontrar la causa de los errores que surgen cuando entrenas tu modelo o cuando obtienes predicciones en la nube puede ser un desafío. En esta página, se describe cómo encontrar y depurar los problemas que enfrentas en AI Platform Prediction. Si encuentras problemas con el framework de aprendizaje automático que estás usando, lee la documentación del framework de aprendizaje automático.
Herramienta de línea de comandos
- ERROR: (gcloud) opción no válida: 'ai-platform'.
Este error significa que debes actualizar gcloud. Para actualizar gcloud, ejecuta el siguiente comando:
gcloud components update- ERROR: (gcloud) argumentos no reconocidos: --framework=SCIKIT_LEARN.
Este error significa que debes actualizar gcloud. Para actualizar gcloud, ejecuta el siguiente comando:
gcloud components update- ERROR: (gcloud) argumentos no reconocidos: --framework=XGBOOST.
Este error significa que debes actualizar gcloud. Para actualizar gcloud, ejecuta el siguiente comando:
gcloud components update- ERROR: (gcloud) error durante la carga del modelo: Cloud no pudo cargar el modelo: /tmp/model/0001/model.pkl. '\x03'. (Código de error: 0).
Este error significa que no se usó la biblioteca correcta para exportar el modelo. Para solucionarlo, vuelve a exportar el modelo con la biblioteca correcta. Por ejemplo, exporta los modelos con el formato
model.pklcon la bibliotecapickley los modelos con el formatomodel.joblibcon la bibliotecajoblib.- ERROR: (gcloud.ai-platform.jobs.submit.prediction) argument --data-format: Invalid choice: 'json'.
Este error significa que especificaste
jsoncomo el valor de la marca--data-formatcuando enviaste un trabajo de predicción por lotes. Para usar el formato de datosJSON, debes proporcionartextcomo el valor de la marca--data-format.
Versiones de Python
- ERROR: Se detectó un modelo incorrecto con el error: “Falla en la carga del modelo: no se puede cargar el
- modelo: /tmp/model/0001/model.pkl. Protocolo pickle no compatible: 3. Asegúrate
- de que el modelo se exportó con Python 2. De lo contrario, especifica
- el parámetro“python_version” correcto durante la implementación del modelo. Actualmente,
- “python_version” acepta 2.7 y 3.5. (Código de error: 0)”.
- Este error significa que un archivo del modelo exportado con Python 3 se implementó en un recurso de la versión del modelo de AI Platform Prediction con una configuración de Python 2.7.
Para solucionar el problema, sigue estos pasos:
- Crea un recurso de versión de modelo nuevo y configura “python_version” en 3.5.
- Implementa el mismo archivo de modelo al recurso de versión de modelo nuevo.
No se encuentra el comando virtualenv
Si obtuviste este error cuando intentaste activar virtualenv, una solución posible es agregar el directorio que contiene virtualenv a tu variable de entorno $PATH. Si modificas esta variable, podrás usar los comandos virtualenv sin necesidad que escribir la ruta de archivo completa.
Primero, instala virtualenv mediante la ejecución del comando siguiente:
pip install --user --upgrade virtualenv
El instalador te pide que modifiques tu variable de entorno $PATH y te proporcionará la ruta a la secuencia de comandos virtualenv. En macOS, es similar al ejemplo /Users/[YOUR-USERNAME]/Library/Python/[YOUR-PYTHON-VERSION]/bin.
Abre el archivo en el que tu shell carga las variables de entorno. Por lo general, es ~/.bashrc o ~/.bash_profile en macOS.
Agrega la línea siguiente y reemplaza [VALUES-IN-BRACKETS] por los valores adecuados:
export PATH=$PATH:/Users/[YOUR-USERNAME]/Library/Python/[YOUR-PYTHON-VERSION]/bin
Por último, ejecuta el comando siguiente a fin de cargar tu archivo .bashrc (o .bash_profile) actualizado:
source ~/.bashrc
Usa registros de trabajo
Un buen punto de partida para empezar a solucionar problemas son los registros de trabajos que captura Cloud Logging.
Registros para diferentes tipos de operación
La experiencia de registro varía según el tipo de operación, como se muestra en las secciones a continuación.
Registros de predicción por lotes
Se registran todos tus trabajos de predicción por lotes.
Registros de predicción en línea
Las solicitudes de predicción en línea no generan registros de forma predeterminada. Puedes habilitar Cloud Logging cuando creas el recurso del modelo:
gcloud
Incluye la marca --enable-logging cuando ejecutes gcloud ai-platform models create.
Python
Establece onlinePredictionLogging en True en el recurso Model que usas para llamar a projects.models.create.
Busca registros
Tus registros de los trabajos contienen todos los eventos para tu operación, incluidos los eventos de todos los procesos en tu clúster cuando estás usando el entrenamiento distribuido. Si ejecutas un trabajo de entrenamiento distribuido, tus registros a nivel del trabajo se informan para el proceso de trabajador principal. El primer paso para solucionar problemas de un error es, generalmente, examinar los registros para ese proceso y filtrar los eventos registrados para otros procesos en tu clúster. Los ejemplos en esta sección muestran ese filtro.
Puedes filtrar los registros desde la línea de comandos o la sección Cloud Logging de la consola de Google Cloud. En cualquier caso, usa estos valores de metadatos en el filtro según sea necesario:
| Elemento de metadatos | Filtro para mostrar elementos donde es… |
|---|---|
| resource.type | Igual a "cloud_ml_job". |
| resource.labels.job_id | Igual al nombre de tu trabajo. |
| resource.labels.task_name | Igual a "master-replica-0" para leer solo las entradas de registro para tu trabajador principal. |
| severity (gravedad) | Mayor o igual que ERROR para leer solo las entradas de registro que corresponden a las condiciones de error. |
Línea de comandos
Usa la lectura de registros Beta de gcloud para construir una consulta que satisfaga tus necesidades. A continuación, se incluyen algunos ejemplos:
Cada ejemplo se basa en estas variables de entorno:
PROJECT="my-project-name"
JOB="my_job_name"
Si lo prefieres, puedes ingresar el literal de string en su lugar.
Para imprimir tus registros de trabajos en la pantalla, haz lo siguiente:
gcloud ai-platform jobs stream-logs $JOB
Consulta todas las opciones para gcloud ai-platform jobs stream-logs.
Para imprimir el registro para tu trabajador principal en la pantalla:
gcloud beta logging read --project=${PROJECT} "resource.type=\"ml_job\" and resource.labels.job_id=${JOB} and resource.labels.task_name=\"master-replica-0\""
Para imprimir solo errores registrados para tu trabajador principal en la pantalla:
gcloud beta logging read --project=${PROJECT} "resource.type=\"ml_job\" and resource.labels.job_id=${JOB} and resource.labels.task_name=\"master-replica-0\" and severity>=ERROR"
Los ejemplos anteriores representan los casos más comunes de filtrado de los registros del trabajo de entrenamiento de AI Platform Prediction. Cloud Logging ofrece muchas opciones potentes para los filtros que te permiten definir mejor las búsquedas. En la documentación de filtros avanzados se describen esas opciones en detalle.
Console
Abre la página Trabajos de AI Platform Prediction en la consola de Google Cloud.
Selecciona el trabajo que falló de la lista en la página Trabajos para ver los detalles.

- Haz clic en View logs (Ver registros) para abrir Cloud Logging.
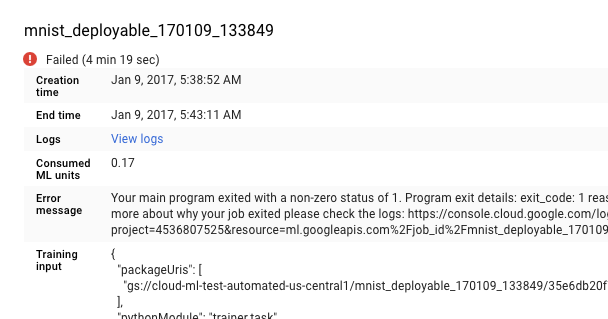
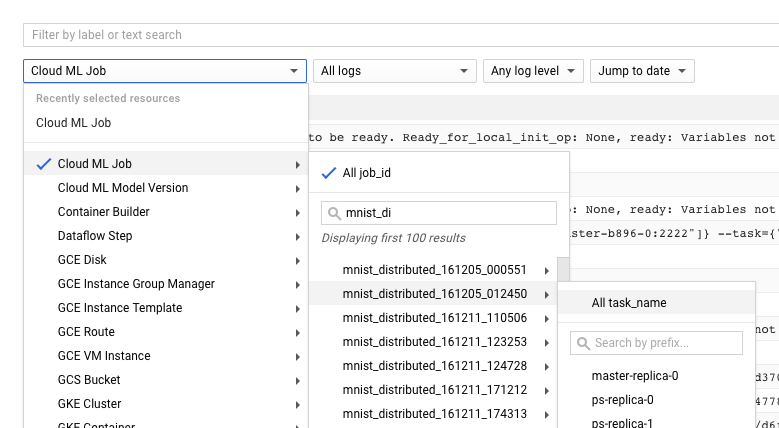
También puedes ir directo a Cloud Logging, pero tienes que realizar un paso adicional, que es buscar el trabajo:
- Expande el selector de recursos.
- Expande el trabajo de AI Platform Prediction en la lista de recursos.
- Busca el nombre de tu trabajo en la lista job_id (puedes ingresar las primeras letras del nombre del trabajo en el cuadro de búsqueda para reducir los trabajos que se muestran).
- Expande la entrada del trabajo y selecciona
master-replica-0de la lista de tareas.
Obtén información de los registros
Luego de que hayas encontrado el registro correcto y lo hayas filtrado con base en master-replica-0, puede examinar los eventos registrados para buscar el origen del problema. Esto implica un procedimiento estándar de depuración de Python, pero vale la pena recordar lo siguiente:
- Los eventos tienen varios niveles de gravedad. Puedes filtrar para ver solo los eventos de un nivel en particular, como errores, o errores y advertencias.
- Un problema que causa que tu entrenador salga con una condición de error irrecuperable (código de retorno > 0) se registra como una excepción precedida por un seguimiento de pila:
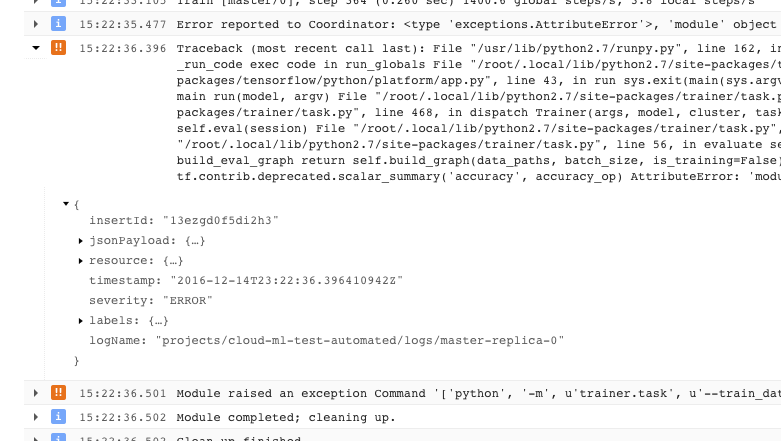
- Puedes obtener más información si expandes los objetos del mensaje JSON registrado (que se denota con una flecha hacia la derecha y cuyo contenido aparece como {…}). Por ejemplo, puedes expandir jsonPayload si quieres ver el seguimiento de pila en un formato más legible que el que aparece en la descripción del error principal:
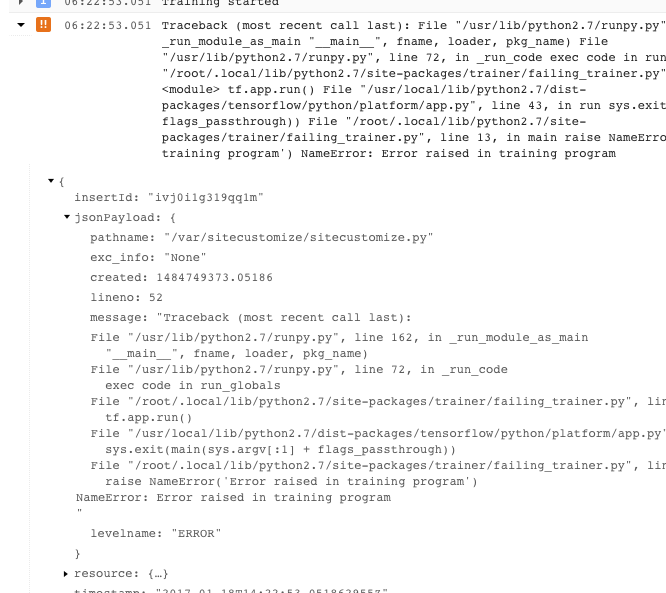
- En algunos errores, se muestran casos de errores que se pueden intentar de nuevo. Por regla general, estos no incluyen un seguimiento de pila y puede ser más difícil diagnosticarlos.
Aprovecha el registro al máximo
El servicio de AI Platform Prediction registra de forma automática estos eventos:
- Información de estado interna al servicio.
- Mensajes que tu aplicación de entrenador envía a
stderr. - Texto de salida que tu aplicación de entrenador envía a
stdout
Puedes simplificar los errores de solución de problemas de tu aplicación de entrenador si sigues las prácticas recomendadas de programación:
- Envía mensajes significativos a stderr (con registro por ejemplo).
- Plantea la excepción más lógica y descriptiva cuando algo sale mal.
- Agrega strings descriptivas a tus proyectos de excepción.
La documentación de Python proporciona más información sobre las excepciones.
Soluciona problemas de predicción
Esta sección reúne algunos problemas comunes que se encuentran cuando se obtienen predicciones.
Cómo controlar condiciones específicas para la predicción en línea
En esta sección, se proporciona orientación sobre algunas condiciones de error de la predicción en línea que se sabe afectan a algunos usuarios.
Predicciones que tardan demasiado en completarse (30-180 segundos)
La causa más común de una predicción en línea lenta es escalar los nodos de procesamiento desde cero. Si tu modelo tiene solicitudes de predicción regulares hechas contra él, el sistema mantiene uno o más nodos listos para entregar predicciones. Si tu modelo no ha entregado ninguna predicción en mucho tiempo, el servicio "reduce" a cero los nodos listos. La próxima solicitud de predicción luego de esta reducción llevará mucho más tiempo en mostrarse de lo habitual porque el servicio tiene que aprovisionar nodos para controlarla.
Códigos de estado de HTTP
Cuando ocurre un error con una solicitud de predicción en línea, generalmente obtienes un código de estado HTTP del servicio. Estos son algunos códigos que se encuentran comúnmente y su significado en el contexto de la predicción en línea:
- 429 - No hay memoria suficiente
El nodo de procesamiento se quedó sin memoria mientras ejecutaba tu modelo. No hay manera de aumentar la memoria asignada a los nodos de predicción en este momento. Puedes probar esto para que tu modelo se ejecute:
- Puedes reducir el tamaño de tu modelo si haces lo siguiente:
- Usa variables menos precisas.
- Cuantizas tus datos continuos.
- Reduces el tamaño de otros atributos de entrada (por ejemplo, mediante el uso de tamaños de vocabulario más pequeños).
- Envías nuevamente la solicitud con un lote de instancias más pequeño.
- Puedes reducir el tamaño de tu modelo si haces lo siguiente:
- 429 - Demasiadas solicitudes pendientes
Tu modelo está recibiendo más solicitudes de las que puede controlar. Si usas el ajuste de escala automático, está recibiendo solicitudes más rápido de lo que el sistema puede escalar. Además, si el valor mínimo de nodos es 0, esta configuración puede generar una situación de “inicio en frío” en la que se observará una tasa de error del 100% hasta que el primer nodo sea viable.
Con el ajuste de escala automático, puedes tratar de volver a enviar solicitudes con un retirada exponencial. Volver a enviar las solicitudes con la retirada exponencial puede darle tiempo al sistema para ajustarse.
De forma predeterminada, el ajuste de escala automático se activa cuando el uso de CPU supera el 60% y es configurable.
- 429 - Cuota
Tu proyecto de Google Cloud Platform está limitado a 10,000 solicitudes cada 100 segundos (aproximadamente 100 por segundo). Si recibes este error en picos temporales, a menudo puedes intentar nuevamente con la retirada exponencial para procesar todas tus solicitudes a tiempo. Si obtienes este código sistemáticamente, puedes solicitar un aumento de cuota. Consulta la página de cuotas para obtener más detalles.
- 503 - Nuestros sistemas han detectado tráfico inusual de tu red de computadoras
La tasa de solicitudes que recibió tu modelo de una sola IP es tan alta que el sistema sospecha un ataque de denegación del servicio. Deja de enviar solicitudes por un minuto y luego vuelve a enviarlas a una tasa más baja.
- 500 - No se pudo cargar el modelo
El sistema tuvo problemas para cargar tu modelo. Sigue estos pasos:
- Asegúrate de que tu entrenador esté exportando el modelo correcto.
- Intenta una predicción de prueba con el comando
gcloud ai-platform local predict. - Exporta el modelo de nuevo y vuelve a intentarlo
Formato de errores para solicitudes de predicción
Todos estos mensajes tienen que ver con tu entrada de predicción.
- "JSON vacío o con formato incorrecto/no válido en el cuerpo de la solicitud"
- Este servicio no pudo analizar el JSON en tu solicitud o tu solicitud está vacía. Revisa tu mensaje para ver si hay omisiones o errores que invaliden JSON.
- "Campo de 'instancias' faltantes en el cuerpo de la solicitud"
- El cuerpo de tu solicitud no sigue el formato correcto. Debe ser un objeto JSON con una sola clave llamada
"instances"que contenga una lista con todas sus instancias de entrada. - Error de codificación JSON cuando se crea una solicitud
La solicitud incluye datos codificados en base64, pero no en el formato JSON adecuado. Cada string codificada en base64 debe estar representada por un objeto con una sola clave llamada
"b64". Por ejemplo:{"b64": "an_encoded_string"}Ocurre otro error de base64 cuando tienes datos binarios que no están codificados en base64. Codifica tus datos y formatéalos de la siguiente manera:
{"b64": base64.b64encode(binary_data)}Consulta más información sobre el formato y la codificación de datos binarios.
La predicción en la nube lleva más tiempo que en la computadora de escritorio
La predicción en línea está diseñada para ser un servicio escalable que entrega rápidamente una tasa alta de solicitudes de predicción. El servicio está optimizado para un rendimiento agregado en todas las solicitudes de servicio. El énfasis en la escalabilidad da lugar a características de rendimiento diferentes que generar un número pequeño de predicciones en tu máquina local.
Pasos siguientes
- Obtén asistencia.
- Obtén más información sobre el modelo de error de las API de Google , en especial los códigos de error canónicos definidos en
google.rpc.Codey los detalles de error estándar definidos en google/rpc/error_details.proto. - Aprende a supervisar tus trabajos de entrenamiento.
- Consulta la solución de problemas y Preguntas frecuentes de Cloud TPU para obtener ayuda sobre cómo diagnosticar y resolver problemas cuando se ejecuta AI Platform Prediction con Cloud TPU.