AI Platform Pipelines では、機械学習(ML)ワークフローを再利用、再現可能なパイプラインとしてオーケストレートできます。AI Platform Pipelines を使用すると、Google Kubernetes Engine で TensorFlow Extended を使用して Kubeflow Pipelines を設定する手間が省けます。
このガイドでは、AI Platform Pipelines を GKE にデプロイするためのいくつかのオプションについて説明します。既存の GKE クラスタに Kubeflow Pipelines をデプロイしても、新しい GKE クラスタを作成してもかまいません。既存の GKE クラスタを再利用する場合は、クラスタが次の要件を満たしているかを確認します。
- クラスタには少なくとも 3 つのノードが必要です。各ノードには、少なくとも 2 つの CPU と 4 GB のメモリが必要です。
- クラスタのアクセス スコープですべての Cloud APIs への完全アクセス権を付与するか、クラスタでカスタム サービス アカウントを使用する必要があります。
- クラスタに Kubeflow Pipelines がインストールされていない状態である必要があります。
状況に応じて最適なデプロイ オプションを選択してください。
- AI Platform Pipelines を使用して、Google Cloud への完全アクセス権を持つ新しい GKE クラスタを作成し、Kubeflow Pipelines をクラスタにデプロイする。このオプションを使用すると、AI Platform Pipelines を簡単にデプロイして使用できます。
- Google Cloud へのきめ細かいアクセス権を持つ新しい GKE クラスタを作成し、このクラスタに Kubeflow Pipelines をデプロイする。このオプションを使用すると、クラスタ上のワークロードがアクセスできる Google Cloud のリソースと API を指定できます。
- AI Platform Pipelines を既存の GKE クラスタにデプロイする。このオプションでは、AI Platform Pipelines を既存の GKE クラスタにデプロイする方法について説明します。
始める前に
このガイドに進む前に、Google Cloud プロジェクトが正しく設定され、AI Platform Pipelines をデプロイするための十分な権限があることを確認してください。- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
- 次の手順で、AI Platform Pipelines のデプロイに必要なロールが付与されているかどうかを確認します。
-
Cloud Shell セッションを開きます。
Cloud Shell は、Google Cloud Console の下部にあるフレームで開きます。
-
AI Platform Pipelines のデプロイには、プロジェクトの閲覧者(
roles/viewer)と Kubernetes Engine 管理者(roles/container.admin)のロールか、プロジェクトのオーナー(roles/owner)のロールなどの同等の権限を含むロールが必要です。Cloud Shell で次のコマンドを実行して、閲覧者と Kubernetes Engine 管理者のロールを持つプリンシパルを一覧表示します。gcloud projects get-iam-policy PROJECT_ID \ --flatten="bindings[].members" --format="table(bindings.role, bindings.members)" \ --filter="bindings.role:roles/container.admin OR bindings.role:roles/viewer"
PROJECT_ID は、Google Cloud プロジェクトの ID に置き換えます。
このコマンドの出力を使用して、アカウントに閲覧者と Kubernetes Engine 管理者のロールがあることを確認します。
-
クラスタにきめ細かいアクセス権を付与する場合は、プロジェクトのサービス アカウント管理者(
roles/iam.serviceAccountAdmin)のロールか、プロジェクトの編集者(roles/editor)やオーナー(roles/owner)のロールなど、同等の権限を含むロールも必要になります。Cloud Shell で次のコマンドを実行して、サービス アカウント管理者のロールを持つプリンシパルを一覧表示します。gcloud projects get-iam-policy PROJECT_ID \ --flatten="bindings[].members" --format="table(bindings.role, bindings.members)" \ --filter="bindings.role:roles/iam.serviceAccountAdmin"
PROJECT_ID は、Google Cloud プロジェクトの ID に置き換えます。
このコマンドの出力を使用して、アカウントにサービス アカウント管理者のロールがあることを確認します。
-
必要なロールが付与されていない場合は、Google Cloud プロジェクト管理者にお問い合わせください。
詳しくは、Identity and Access Management ロールの付与についてご覧ください。
-
Google Cloud への完全アクセス権を持つ AI Platform Pipelines をデプロイする
AI Platform Pipelines がユーザーに代わって GKE クラスタを作成し、Kubeflow Pipelines をクラスタにデプロイするため、Kubeflow Pipelines の設定と使用が簡単になります。AI Platform Pipelines がユーザーに代わって GKE クラスタを作成すると、そのクラスタはデフォルトの Compute Engine サービス アカウントを使用します。プロジェクトで有効にした Google Cloud リソースと API への完全アクセス権をクラスタに付与するには、クラスタに https://www.googleapis.com/auth/cloud-platform アクセス スコープへのアクセスを許可します。この方法でアクセス権を付与すると、クラスタで実行される ML パイプラインが AI Platform Training や AI Platform Prediction などの API にアクセスできるようになります。このプロセスにより、AI Platform Pipelines の設定が容易になりますが、パイプライン開発者に Google Cloud リソースと API へのアクセスを必要以上に付与することになります。
Google Cloud のリソースと API への完全アクセス権を持つ AI Platform Pipelines をデプロイするには、次の手順を使用します。
Google Cloud Console で AI Platform Pipelines を開きます。
AI Platform Pipelines ツールバーで、[新しいインスタンス] をクリックします。Kubeflow Pipelines が Google Cloud Marketplace で開きます。
[構成] をクリックします。[Kubeflow Pipelines をデプロイ] フォームが開きます。
[新しいクラスタを作成] のリンクが表示されたら、[新しいクラスタを作成] をクリックします。それ以外の場合は、次の手順に進みます。

クラスタを配置するクラスタゾーンを選択します。使用するゾーンの決定については、リージョン選択のベスト プラクティスをご覧ください。
[次の Cloud API へのアクセスを許可する] をオンにし、GKE クラスタ上で実行されるアプリケーションに Google Cloud リソースへのアクセス権を付与します。このチェックボックスをオンにすると、
https://www.googleapis.com/auth/cloud-platformアクセス スコープへのアクセス権がクラスタに付与されます。このアクセス スコープは、プロジェクトで有効にした Google Cloud リソースへの完全アクセス権を提供します。この方法でクラスタに Google Cloud リソースへのアクセス権を付与すると、サービス アカウントの作成と管理や Kubernetes Secret の作成の手間が省けます。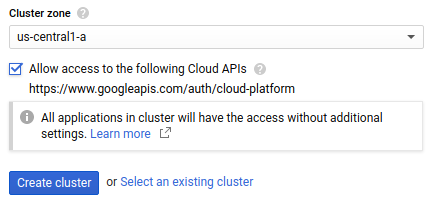
[クラスタを作成] をクリックします。この手順には数分かかることがあります。
名前空間は大規模な GKE クラスタのリソースの管理に使用されます。クラスタで名前空間を使用する予定がない場合は、[名前空間] プルダウン リストで [デフォルト] を選択します。
GKE クラスタで名前空間を使用する場合は、[名前空間] プルダウン リストを使用して名前空間を作成します。名前空間を作成するには:
- [名前空間] プルダウン リストで [名前空間の作成] を選択します。[新しい名前空間名] ボックスが表示されます。
- [新しい名前空間名] に名前空間名を入力します。
名前空間の詳細については、Kubernetes と名前空間の編成に関するブログ記事をご覧ください。
[アプリ インスタンス名] ボックスに、Kubeflow Pipelines インスタンスの名前を入力します。
マネージド ストレージを使用すると、ML パイプラインのメタデータとアーティファクトを Compute Engine の永続ディスクに保存する代わりに、Cloud SQL と Cloud Storage を使用して保存できます。マネージド サービスを使用してパイプラインのアーティファクトとメタデータを保存することで、クラスタのデータのバックアップや復元が容易になります。マネージド ストレージを使用して Kubeflow Pipelines をデプロイするには、[Use managed storage] を選択して、次の情報を入力します。
アーティファクト ストレージ Cloud Storage バケット: マネージド ストレージでは、Kubeflow Pipelines は、パイプライン アーティファクトを Cloud Storage バケットに保存します。Kubeflow Pipelines がアーティファクトを保存するバケットの名前を指定します。指定されたバケットが存在しない場合、Kubeflow Pipelines デプロイツールは
us-central1リージョンにバケットを自動的に作成します。Cloud SQL インスタンス接続名: マネージド ストレージを使用すると、Kubeflow Pipelines はパイプライン メタデータを Cloud SQL 上の MySQL データベースに保存します。Cloud SQL の MySQL インスタンスの接続名を指定します。
データベースのユーザー名: MySQL インスタンスへの接続時に使用する Kubeflow Pipelines のデータベースのユーザー名を指定します。現在、マネージド ストレージを使用する Kubeflow Pipelines をデプロイするには、データベース ユーザーに
ALLMySQL 権限が必要です。このフィールドを空のままにすると、この値はデフォルトで root になります。データベース パスワード: MySQL インスタンスへの接続時に使用する Kubeflow Pipelines のデータベース パスワードを指定します。このフィールドを空白のままにすると、Kubeflow Pipelines はパスワードを指定せずにデータベースに接続します。指定したユーザー名にパスワードが必要な場合は失敗します。
データベース名の接頭辞: データベース名の接頭辞を指定します。接頭辞の値は文字で始め、小文字、数字、アンダースコアのみ使用できます。
デプロイ プロセス中に、Kubeflow Pipelines は DATABASE_NAME_PREFIX_pipeline と DATABASE_NAME_PREFIX_metadata という 2 つのデータベースを作成します。これらの名前のデータベースが MySQL インスタンスに存在する場合は、Kubeflow Pipelines は既存のデータベースを再利用します。この値が指定されていない場合、データベース インスタンス名の接頭辞としてアプリのインスタンス名が使用されます。
[デプロイ] をクリックします。この手順には数分かかることがあります。
パイプライン ダッシュボードにアクセスするには、Google Cloud Console で AI Platform Pipelines を開きます。
AI Platform Pipelines インスタンスの [パイプライン ダッシュボードを開く] をクリックします。
Google Cloud へのきめ細かいアクセス権を持つ AI Platform Pipelines をデプロイする
ML パイプラインは、GKE クラスタのノードプールのサービス アカウントとアクセス スコープを使用して Google Cloud リソースにアクセスします。現在、クラスタのアクセスを特定の Google Cloud リソースに制限するには、ユーザーが管理するサービス アカウントを使用する GKE クラスタに AI Platform Pipelines をデプロイする必要があります。
次のセクションの手順に従って、サービス アカウントを作成して構成し、サービス アカウントを使用して GKE クラスタを作成してから、Kubeflow Pipelines を GKE クラスタにデプロイします。
GKE クラスタのサービス アカウントを作成する
GKE クラスタのサービス アカウントを設定する手順は次のとおりです。
Cloud Shell セッションを開きます。
Cloud Shell は、Google Cloud Console の下部にあるフレームに表示されます。
Cloud Shell で次のコマンドを実行して、サービス アカウントを作成し、AI Platform Pipelines を実行するのに十分なアクセス権を付与します。詳しくは、ユーザーが管理するサービス アカウントで AI Platform Pipelines を実行するために必要なロールをご覧ください。
export PROJECT=PROJECT_IDexport SERVICE_ACCOUNT=SERVICE_ACCOUNT_NAMEgcloud iam service-accounts create $SERVICE_ACCOUNT \ --display-name=$SERVICE_ACCOUNT \ --project=$PROJECTgcloud projects add-iam-policy-binding $PROJECT \ --member="serviceAccount:$SERVICE_ACCOUNT@$PROJECT.iam.gserviceaccount.com" \ --role=roles/logging.logWritergcloud projects add-iam-policy-binding $PROJECT \ --member="serviceAccount:$SERVICE_ACCOUNT@$PROJECT.iam.gserviceaccount.com" \ --role=roles/monitoring.metricWritergcloud projects add-iam-policy-binding $PROJECT \ --member="serviceAccount:$SERVICE_ACCOUNT@$PROJECT.iam.gserviceaccount.com" \ --role=roles/monitoring.viewergcloud projects add-iam-policy-binding $PROJECT \ --member="serviceAccount:$SERVICE_ACCOUNT@$PROJECT.iam.gserviceaccount.com" \ --role=roles/storage.objectViewer以下のように置き換えます。
- SERVICE_ACCOUNT_NAME: 作成するサービス アカウントの名前。
- PROJECT_ID: サービス アカウントが作成される Google Cloud プロジェクト。
ML パイプラインに必要な Google Cloud リソースまたは API へのアクセス権をサービス アカウントに付与します。詳しくは、Identity and Access Management のロールとサービス アカウントの管理についてご覧ください。
ユーザー アカウントにサービス アカウントのサービス アカウント ユーザー(
iam.serviceAccountUser)のロールを付与します。gcloud iam service-accounts add-iam-policy-binding \ "SERVICE_ACCOUNT_NAME@PROJECT_ID.iam.gserviceaccount.com" \ --member=user:USERNAME \ --role=roles/iam.serviceAccountUser
以下のように置き換えます。
- SERVICE_ACCOUNT_NAME: サービス アカウントの名前。
- PROJECT_ID: Google Cloud プロジェクト。
- USERNAME: Google Cloud のユーザー名。
GKE クラスタを設定する
次の手順で GKE クラスタを設定します。
Google Cloud コンソールで Google Kubernetes Engine を開きます。
[クラスタを作成] ボタンをクリックします。[クラスタの基本] フォームが開きます。
クラスタの名前を [名前] に入力します。
[ロケーション タイプ] で [ゾーン] を選択し、クラスタに使用するゾーンを選択します。使用するゾーンの決定については、リージョン選択のベスト プラクティスをご覧ください。
ナビゲーション ペインの [ノードプール] で [default-pool] をクリックします。[ノードプールの詳細] フォームが表示されます。
[ノード数] に、クラスタ内に作成するノードの数を入力します。AI Platform Pipelines をデプロイするには、クラスタに 3 つ以上のノードが必要です。ノードとそのリソース(ファイアウォール ルートなど)に使用できるリソース割り当てが必要です。
ナビゲーション パネルで、[ノードプール] の下の [ノード] をクリックします。[ノード] フォームが開きます。
インスタンスに使用するデフォルトのマシンの構成を選択します。AI Platform Pipelines をデプロイするには、少なくとも 2 つの CPU と 4 GB のメモリを備えたマシンタイプ(
n1-standard-2など)を選択する必要があります。マシンタイプごとに課金方法は異なります。マシンタイプごとの料金については、マシンタイプの料金表をご覧ください。ナビゲーション パネルで、[ノードプール] の下の [セキュリティ] をクリックします。[ノードのセキュリティ] フォームが表示されます。
[サービス アカウント] プルダウン リストから、このガイドで作成したサービス アカウントを選択します。
それ以外の場合は、必要に応じて GKE クラスタを構成します。詳しくは、GKE クラスタの作成についてご覧ください。
[作成] をクリックします。
GKE クラスタに Kubeflow Pipelines をインストールする
GKE クラスタに Kubeflow Pipelines を設定するには、次の手順を実行します。
Google Cloud Console で AI Platform Pipelines を開きます。
AI Platform Pipelines ツールバーで、[新しいインスタンス] をクリックします。Kubeflow Pipelines が Google Cloud Marketplace で開きます。
[構成] をクリックします。[Kubeflow Pipelines をデプロイ] フォームが開きます。
[クラスタ] プルダウン リストで、前の手順で作成したクラスタを選択します。使用するクラスタがデプロイの対象でない場合、クラスタが Kubeflow Pipelines のデプロイ要件を満たしていることを確認します。
名前空間は大規模な GKE クラスタのリソースの管理に使用されます。クラスタで名前空間を使用する予定がない場合は、[名前空間] プルダウン リストで [デフォルト] を選択します。
GKE クラスタで名前空間を使用する場合は、[名前空間] プルダウン リストを使用して名前空間を作成します。名前空間を作成するには:
- [名前空間] プルダウン リストで [名前空間の作成] を選択します。[新しい名前空間名] ボックスが表示されます。
- [新しい名前空間名] に名前空間名を入力します。
名前空間の詳細については、Kubernetes と名前空間の編成に関するブログ記事をご覧ください。
[アプリ インスタンス名] ボックスに、Kubeflow Pipelines インスタンスの名前を入力します。
マネージド ストレージを使用すると、ML パイプラインのメタデータとアーティファクトを Compute Engine の永続ディスクに保存する代わりに、Cloud SQL と Cloud Storage を使用して保存できます。マネージド サービスを使用してパイプラインのアーティファクトとメタデータを保存することで、クラスタのデータのバックアップや復元が容易になります。マネージド ストレージを使用して Kubeflow Pipelines をデプロイするには、[Use managed storage] を選択して、次の情報を入力します。
アーティファクト ストレージ Cloud Storage バケット: マネージド ストレージでは、Kubeflow Pipelines は、パイプライン アーティファクトを Cloud Storage バケットに保存します。Kubeflow Pipelines がアーティファクトを保存するバケットの名前を指定します。指定されたバケットが存在しない場合、Kubeflow Pipelines デプロイツールは
us-central1リージョンにバケットを自動的に作成します。Cloud SQL インスタンス接続名: マネージド ストレージを使用すると、Kubeflow Pipelines はパイプライン メタデータを Cloud SQL 上の MySQL データベースに保存します。Cloud SQL の MySQL インスタンスの接続名を指定します。
データベースのユーザー名: MySQL インスタンスへの接続時に使用する Kubeflow Pipelines のデータベースのユーザー名を指定します。現在、マネージド ストレージを使用する Kubeflow Pipelines をデプロイするには、データベース ユーザーに
ALLMySQL 権限が必要です。このフィールドを空のままにすると、この値はデフォルトで root になります。データベース パスワード: MySQL インスタンスへの接続時に使用する Kubeflow Pipelines のデータベース パスワードを指定します。このフィールドを空白のままにすると、Kubeflow Pipelines はパスワードを指定せずにデータベースに接続します。指定したユーザー名にパスワードが必要な場合は失敗します。
データベース名の接頭辞: データベース名の接頭辞を指定します。接頭辞の値は文字で始め、小文字、数字、アンダースコアのみ使用できます。
デプロイ プロセス中に、Kubeflow Pipelines は DATABASE_NAME_PREFIX_pipeline と DATABASE_NAME_PREFIX_metadata という 2 つのデータベースを作成します。これらの名前のデータベースが MySQL インスタンスに存在する場合は、Kubeflow Pipelines は既存のデータベースを再利用します。この値が指定されていない場合、データベース インスタンス名の接頭辞としてアプリのインスタンス名が使用されます。
[デプロイ] をクリックします。この手順には数分かかることがあります。
パイプライン ダッシュボードにアクセスするには、Google Cloud Console で AI Platform Pipelines を開きます。
AI Platform Pipelines インスタンスの [パイプライン ダッシュボードを開く] をクリックします。
既存の GKE クラスタに AI Platform Pipelines をデプロイする
Google Cloud Marketplace を使用して GKE クラスタに Kubeflow Pipelines をデプロイするには、次の条件を満たしている必要があります。
- クラスタには少なくとも 3 つのノードが必要です。各ノードには、少なくとも 2 つの CPU と 4 GB のメモリが必要です。
- クラスタのアクセス スコープですべての Cloud APIs への完全アクセス権を付与するか、クラスタでカスタム サービス アカウントを使用する必要があります。
- クラスタに Kubeflow Pipelines がインストールされていない状態である必要があります。
詳しくは、AI Platform Pipelines 向け GKE クラスタの構成についてご覧ください。
GKE クラスタに Kubeflow Pipelines を設定するには、次の手順を実行します。
Google Cloud Console で AI Platform Pipelines を開きます。
AI Platform Pipelines ツールバーで、[新しいインスタンス] をクリックします。Kubeflow Pipelines が Google Cloud Marketplace で開きます。
[構成] をクリックします。[Kubeflow Pipelines をデプロイ] フォームが開きます。
[クラスタ] のプルダウン リストでクラスタを選択します。使用するクラスタがデプロイの対象でない場合、クラスタが Kubeflow Pipelines のデプロイ要件を満たしていることを確認します。
名前空間は大規模な GKE クラスタのリソースの管理に使用されます。クラスタで Namespace を使用しない場合は、[Namespace] プルダウン リストで [デフォルト] を選択します。
クラスタで名前空間を使用する場合は、既存の名前空間を選択するか、[名前空間] プルダウン リストを使用して名前空間を作成します。名前空間を作成するには:
- [名前空間] プルダウン リストで [名前空間の作成] を選択します。[新しい名前空間名] ボックスが表示されます。
- [新しい名前空間名] に名前空間名を入力します。
名前空間の詳細については、Kubernetes と名前空間の編成に関するブログ記事をご覧ください。
[アプリ インスタンス名] ボックスに、Kubeflow Pipelines インスタンスの名前を入力します。
マネージド ストレージを使用すると、ML パイプラインのメタデータとアーティファクトを Compute Engine の永続ディスクに保存する代わりに、Cloud SQL と Cloud Storage を使用して保存できます。マネージド サービスを使用してパイプラインのアーティファクトとメタデータを保存することで、クラスタのデータのバックアップや復元が容易になります。マネージド ストレージを使用して Kubeflow Pipelines をデプロイするには、[Use managed storage] を選択して、次の情報を入力します。
アーティファクト ストレージ Cloud Storage バケット: マネージド ストレージでは、Kubeflow Pipelines は、パイプライン アーティファクトを Cloud Storage バケットに保存します。Kubeflow Pipelines がアーティファクトを保存するバケットの名前を指定します。指定されたバケットが存在しない場合、Kubeflow Pipelines デプロイツールは
us-central1リージョンにバケットを自動的に作成します。Cloud SQL インスタンス接続名: マネージド ストレージを使用すると、Kubeflow Pipelines はパイプライン メタデータを Cloud SQL 上の MySQL データベースに保存します。Cloud SQL の MySQL インスタンスの接続名を指定します。
データベースのユーザー名: MySQL インスタンスへの接続時に使用する Kubeflow Pipelines のデータベースのユーザー名を指定します。現在、マネージド ストレージを使用する Kubeflow Pipelines をデプロイするには、データベース ユーザーに
ALLMySQL 権限が必要です。このフィールドを空のままにすると、この値はデフォルトで root になります。データベース パスワード: MySQL インスタンスへの接続時に使用する Kubeflow Pipelines のデータベース パスワードを指定します。このフィールドを空白のままにすると、Kubeflow Pipelines はパスワードを指定せずにデータベースに接続します。指定したユーザー名にパスワードが必要な場合は失敗します。
データベース名の接頭辞: データベース名の接頭辞を指定します。接頭辞の値は文字で始め、小文字、数字、アンダースコアのみ使用できます。
デプロイ プロセス中に、Kubeflow Pipelines は DATABASE_NAME_PREFIX_pipeline と DATABASE_NAME_PREFIX_metadata という 2 つのデータベースを作成します。これらの名前のデータベースが MySQL インスタンスに存在する場合は、Kubeflow Pipelines は既存のデータベースを再利用します。この値が指定されていない場合、データベース インスタンス名の接頭辞としてアプリのインスタンス名が使用されます。
[デプロイ] をクリックします。この手順には数分かかることがあります。
パイプライン ダッシュボードにアクセスするには、Google Cloud Console で AI Platform Pipelines を開きます。
AI Platform Pipelines インスタンスの [パイプライン ダッシュボードを開く] をクリックします。
次のステップ
- ML プロセスをパイプラインとしてオーケストレートする。
- Kubeflow Pipelines ユーザー インターフェースを使用してパイプラインを実行する。
- AI Platform Pipelines と ML パイプラインの詳細を確認する。