En este instructivo, se muestra la optimización del objetivo condicional de AI Platform Optimizer.
Conjunto de datos
El Conjunto de datos de ingresos del censo que se usa en esta muestra para el entrenamiento lo aloja UC Irvine Machine Learning Repository.
Con los datos del censo en los que se detallan la edad, la educación, el estado civil y la profesión (los atributos) de una persona, el objetivo será predecir si esta gana más de 50,000 dólares al año (la etiqueta objetivo). Entrenarás un modelo de regresión logística que, según la información de un individuo, mostrará un número entre 0 y 1. Este número puede interpretarse como la probabilidad de que la persona tenga un ingreso anual superior a 50,000 dólares.
Objetivo
En este instructivo, se muestra cómo usar AI Platform Optimizer a fin de optimizar la búsqueda de hiperparámetros para modelos de aprendizaje automático.
En esta muestra, se implementa una demostración de aprendizaje automático que optimiza un modelo de clasificación en un conjunto de datos del censo mediante el uso de AI Platform Optimizer con algoritmos integrados de AI Platform Training. Usarás AI Platform Optimizer para obtener valores de hiperparámetros sugeridos y enviar trabajos de entrenamiento de modelos con esos valores de hiperparámetros sugeridos a través de los algoritmos integrados de AI Platform Training.
Costos
En este instructivo, se usan los siguientes componentes facturables de Google Cloud:
- AI Platform Training
- Cloud Storage
Obtén información sobre los precios de AI Platform Training y los precios de Cloud Storage. Usa la calculadora de precios para generar una estimación de los costos según el uso previsto.
Dependencias y paquetes de instalación de PIP
Instala dependencias adicionales no instaladas en el entorno del notebook.
- Usa la versión con disponibilidad general más reciente del framework.
! pip install -U google-api-python-client
! pip install -U google-cloud
! pip install -U google-cloud-storage
! pip install -U requests
# Automatically restart kernel after installs
import IPython
app = IPython.Application.instance()
app.kernel.do_shutdown(True)
Configura el proyecto de Google Cloud
Los siguientes pasos son obligatorios, sin importar el entorno del notebook.
Asegúrate de tener habilitada la facturación para tu proyecto.
Si ejecutas este notebook de manera local, deberás instalar el SDK de Google Cloud.
Ingresa el ID del proyecto en la celda a continuación. Luego, ejecuta la celda a fin de asegurarte de que el SDK de Cloud use el proyecto correcto para todos los comandos de este notebook.
Nota: Jupyter ejecuta líneas con el prefijo ! como comandos de shell y, luego, interpola las variables de Python con el prefijo $ en estos comandos.
PROJECT_ID = "[project-id]" #@param {type:"string"}
! gcloud config set project $PROJECT_ID
Autentica la cuenta de Google Cloud
Si usas AI Platform Notebooks, tu entorno ya está autenticado. Omite estos pasos.
En la celda que aparece a continuación, deberás autenticarte dos veces.
import sys
# If you are running this notebook in Colab, run this cell and follow the
# instructions to authenticate your Google Cloud account. This provides access
# to your Cloud Storage bucket and lets you submit training jobs and prediction
# requests.
if 'google.colab' in sys.modules:
from google.colab import auth as google_auth
google_auth.authenticate_user()
# If you are running this tutorial in a notebook locally, replace the string
# below with the path to your service account key and run this cell to
# authenticate your Google Cloud account.
else:
%env GOOGLE_APPLICATION_CREDENTIALS your_path_to_credentials.json
# Log in to your account on Google Cloud
! gcloud auth application-default login
! gcloud auth login
Importa las bibliotecas
import json
import time
import datetime
from googleapiclient import errors
Instructivo
Configuración
En esta sección, se definen algunos parámetros y métodos de utilidades para llamar a las API de AI Platform Optimizer. Completa la siguiente información para comenzar.
# Update to your username
USER = '[user-id]' #@param {type: 'string'}
STUDY_ID = '{}_study_{}'.format(USER, datetime.datetime.now().strftime('%Y%m%d_%H%M%S')) #@param {type: 'string'}
REGION = 'us-central1'
def study_parent():
return 'projects/{}/locations/{}'.format(PROJECT_ID, REGION)
def study_name(study_id):
return 'projects/{}/locations/{}/studies/{}'.format(PROJECT_ID, REGION, study_id)
def trial_parent(study_id):
return study_name(study_id)
def trial_name(study_id, trial_id):
return 'projects/{}/locations/{}/studies/{}/trials/{}'.format(PROJECT_ID, REGION,
study_id, trial_id)
def operation_name(operation_id):
return 'projects/{}/locations/{}/operations/{}'.format(PROJECT_ID, REGION, operation_id)
print('USER: {}'.format(USER))
print('PROJECT_ID: {}'.format(PROJECT_ID))
print('REGION: {}'.format(REGION))
print('STUDY_ID: {}'.format(STUDY_ID))
Compila el cliente de la API
Mediante la siguiente celda, se compila el cliente de la API generado de manera automática con el servicio de descubrimiento de API de Google. El esquema de la API con formato JSON se aloja en un bucket de Cloud Storage.
from google.cloud import storage
from googleapiclient import discovery
_OPTIMIZER_API_DOCUMENT_BUCKET = 'caip-optimizer-public'
_OPTIMIZER_API_DOCUMENT_FILE = 'api/ml_public_google_rest_v1.json'
def read_api_document():
client = storage.Client(PROJECT_ID)
bucket = client.get_bucket(_OPTIMIZER_API_DOCUMENT_BUCKET)
blob = bucket.get_blob(_OPTIMIZER_API_DOCUMENT_FILE)
return blob.download_as_string()
ml = discovery.build_from_document(service=read_api_document())
print('Successfully built the client.')
Configuración del estudio
En este instructivo, AI Platform Optimizer crea un estudio y solicita pruebas. En cada prueba, crearás un trabajo de algoritmo integrado de AI Platform Training para realizar el entrenamiento de modelos con los hiperparámetros sugeridos. Una medición para cada prueba se informa como la accuracy del modelo.
Las funciones de parámetros condicionales que proporciona AI Platform Optimizer definen un espacio de búsqueda en forma de árbol para los hiperparámetros. El hiperparámetro de nivel superior es model_type y se decide entre LINEAR y WIDE_AND_DEEP. Cada tipo de modelo tiene hiperparámetros de segundo nivel correspondientes para ajustar:
- Si
model_typeesLINEAR, se ajustalearning_rate. - Si
model_typeesWIDE_AND_DEEP,learning_rateydnn_learning_ratese ajustan.
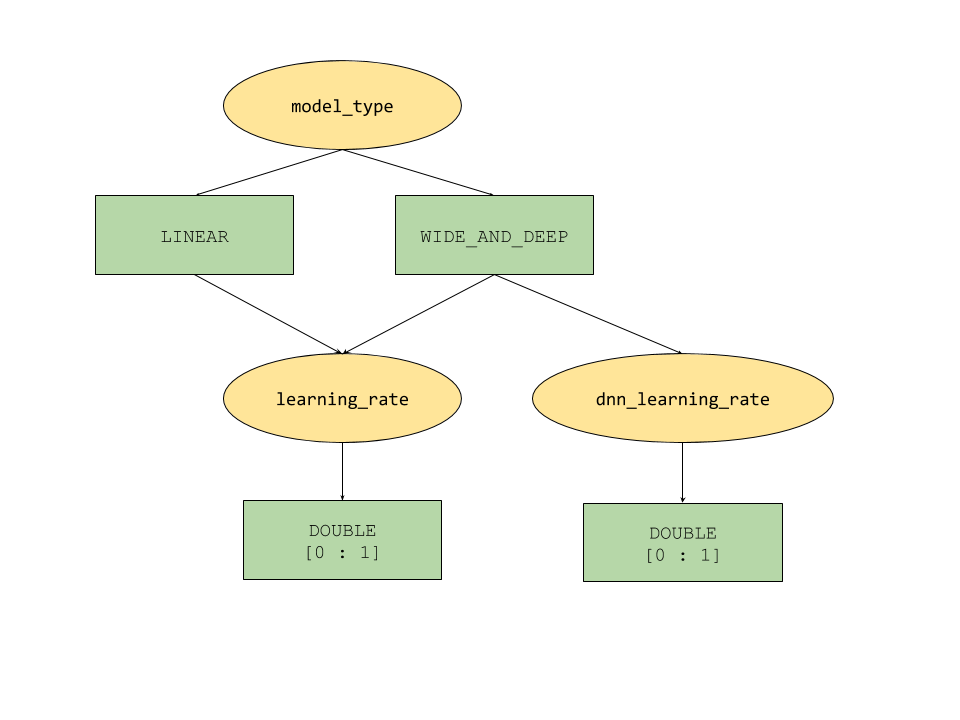
La siguiente es una configuración de estudio de muestra creada como un diccionario de Python jerárquico. Ya se completó. Ejecuta la celda para configurar el estudio.
param_learning_rate = {
'parameter': 'learning_rate',
'type' : 'DOUBLE',
'double_value_spec' : {
'min_value' : 0.00001,
'max_value' : 1.0
},
'scale_type' : 'UNIT_LOG_SCALE',
'parent_categorical_values' : {
'values': ['LINEAR', 'WIDE_AND_DEEP']
},
}
param_dnn_learning_rate = {
'parameter': 'dnn_learning_rate',
'type' : 'DOUBLE',
'double_value_spec' : {
'min_value' : 0.00001,
'max_value' : 1.0
},
'scale_type' : 'UNIT_LOG_SCALE',
'parent_categorical_values' : {
'values': ['WIDE_AND_DEEP']
},
}
param_model_type = {
'parameter': 'model_type',
'type' : 'CATEGORICAL',
'categorical_value_spec' : {'values': ['LINEAR', 'WIDE_AND_DEEP']},
'child_parameter_specs' : [param_learning_rate, param_dnn_learning_rate,]
}
metric_accuracy = {
'metric' : 'accuracy',
'goal' : 'MAXIMIZE'
}
study_config = {
'algorithm' : 'ALGORITHM_UNSPECIFIED', # Let the service choose the `default` algorithm.
'parameters' : [param_model_type,],
'metrics' : [metric_accuracy,],
}
study = {'study_config': study_config}
print(json.dumps(study, indent=2, sort_keys=True))
Crea el estudio
A continuación, crea el estudio que luego ejecutarás para optimizar el objetivo.
# Creates a study
req = ml.projects().locations().studies().create(
parent=study_parent(), studyId=STUDY_ID, body=study)
try :
print(req.execute())
except errors.HttpError as e:
if e.resp.status == 409:
print('Study already existed.')
else:
raise e
Establece parámetros de entrada/salida
A continuación, configura los siguientes parámetros de salida.
OUTPUT_BUCKET y OUTPUT_DIR son el bucket y el directorio de Cloud Storage que se usan como “job_dir” para los trabajos de AI Platform Training. OUTPUT_BUCKET debe ser un bucket en tu proyecto y OUTPUT_DIR es el nombre que quieres darle a la carpeta de salida en tu bucket.
job_dir tendrá el formato siguiente: “gs://$OUTPUT_BUCKET/$OUTPUT_DIR/”
TRAINING_DATA_PATH es la ruta para el conjunto de datos de entrenamiento de entrada.
# `job_dir` will be `gs://${OUTPUT_BUCKET}/${OUTPUT_DIR}/${job_id}`
OUTPUT_BUCKET = '[output-bucket-name]' #@param {type: 'string'}
OUTPUT_DIR = '[output-dir]' #@param {type: 'string'}
TRAINING_DATA_PATH = 'gs://caip-optimizer-public/sample-data/raw_census_train.csv' #@param {type: 'string'}
print('OUTPUT_BUCKET: {}'.format(OUTPUT_BUCKET))
print('OUTPUT_DIR: {}'.format(OUTPUT_DIR))
print('TRAINING_DATA_PATH: {}'.format(TRAINING_DATA_PATH))
# Create the bucket in Cloud Storage
! gcloud storage buckets create gs://$OUTPUT_BUCKET/ --project=$PROJECT_ID
Evaluación de métricas
En esta sección, se definen los métodos para realizar la evaluación de prueba.
En cada prueba, envía un trabajo de algoritmo integrado de AI Platform para entrenar un modelo de aprendizaje automático mediante hiperparámetros sugeridos por AI Platform Optimizer. Cada trabajo escribe el archivo de resumen del modelo en Cloud Storage cuando se completa el trabajo. Puedes recuperar la precisión del modelo desde el directorio del trabajo y, luego, informarlo como la final_measurement de la prueba.
import logging
import math
import subprocess
import os
import yaml
from google.cloud import storage
_TRAINING_JOB_NAME_PATTERN = '{}_condition_parameters_{}_{}'
_IMAGE_URIS = {'LINEAR' : 'gcr.io/cloud-ml-algos/linear_learner_cpu:latest',
'WIDE_AND_DEEP' : 'gcr.io/cloud-ml-algos/wide_deep_learner_cpu:latest'}
_STEP_COUNT = 'step_count'
_ACCURACY = 'accuracy'
def EvaluateTrials(trials):
"""Evaluates trials by submitting training jobs to AI Platform Training service.
Args:
trials: List of Trials to evaluate
Returns: A dict of <trial_id, measurement> for the given trials.
"""
trials_by_job_id = {}
mesurement_by_trial_id = {}
# Submits a AI Platform Training job for each trial.
for trial in trials:
trial_id = int(trial['name'].split('/')[-1])
model_type = _GetSuggestedParameterValue(trial, 'model_type', 'stringValue')
learning_rate = _GetSuggestedParameterValue(trial, 'learning_rate',
'floatValue')
dnn_learning_rate = _GetSuggestedParameterValue(trial, 'dnn_learning_rate',
'floatValue')
job_id = _GenerateTrainingJobId(model_type=model_type,
trial_id=trial_id)
trials_by_job_id[job_id] = {
'trial_id' : trial_id,
'model_type' : model_type,
'learning_rate' : learning_rate,
'dnn_learning_rate' : dnn_learning_rate,
}
_SubmitTrainingJob(job_id, trial_id, model_type, learning_rate, dnn_learning_rate)
# Waits for completion of AI Platform Training jobs.
while not _JobsCompleted(trials_by_job_id.keys()):
time.sleep(60)
# Retrieves model training result(e.g. global_steps, accuracy) for AI Platform Training jobs.
metrics_by_job_id = _GetJobMetrics(trials_by_job_id.keys())
for job_id, metric in metrics_by_job_id.items():
measurement = _CreateMeasurement(trials_by_job_id[job_id]['trial_id'],
trials_by_job_id[job_id]['model_type'],
trials_by_job_id[job_id]['learning_rate'],
trials_by_job_id[job_id]['dnn_learning_rate'],
metric)
mesurement_by_trial_id[trials_by_job_id[job_id]['trial_id']] = measurement
return mesurement_by_trial_id
def _CreateMeasurement(trial_id, model_type, learning_rate, dnn_learning_rate, metric):
if not metric[_ACCURACY]:
# Returns `none` for trials without metrics. The trial will be marked as `INFEASIBLE`.
return None
print(
'Trial {0}: [model_type = {1}, learning_rate = {2}, dnn_learning_rate = {3}] => accuracy = {4}'.format(
trial_id, model_type, learning_rate,
dnn_learning_rate if dnn_learning_rate else 'N/A', metric[_ACCURACY]))
measurement = {
_STEP_COUNT: metric[_STEP_COUNT],
'metrics': [{'metric': _ACCURACY, 'value': metric[_ACCURACY]},]}
return measurement
def _SubmitTrainingJob(job_id, trial_id, model_type, learning_rate, dnn_learning_rate=None):
"""Submits a built-in algo training job to AI Platform Training Service."""
try:
if model_type == 'LINEAR':
subprocess.check_output(_LinearCommand(job_id, learning_rate), stderr=subprocess.STDOUT)
elif model_type == 'WIDE_AND_DEEP':
subprocess.check_output(_WideAndDeepCommand(job_id, learning_rate, dnn_learning_rate), stderr=subprocess.STDOUT)
print('Trial {0}: Submitted job [https://console.cloud.google.com/ai-platform/jobs/{1}?project={2}].'.format(trial_id, job_id, PROJECT_ID))
except subprocess.CalledProcessError as e:
logging.error(e.output)
def _GetTrainingJobState(job_id):
"""Gets a training job state."""
cmd = ['gcloud', 'ai-platform', 'jobs', 'describe', job_id,
'--project', PROJECT_ID,
'--format', 'json']
try:
output = subprocess.check_output(cmd, stderr=subprocess.STDOUT, timeout=3)
except subprocess.CalledProcessError as e:
logging.error(e.output)
return json.loads(output)['state']
def _JobsCompleted(jobs):
"""Checks if all the jobs are completed."""
all_done = True
for job in jobs:
if _GetTrainingJobState(job) not in ['SUCCEEDED', 'FAILED', 'CANCELLED']:
print('Waiting for job[https://console.cloud.google.com/ai-platform/jobs/{0}?project={1}] to finish...'.format(job, PROJECT_ID))
all_done = False
return all_done
def _RetrieveAccuracy(job_id):
"""Retrices the accuracy of the trained model for a built-in algorithm job."""
storage_client = storage.Client(project=PROJECT_ID)
bucket = storage_client.get_bucket(OUTPUT_BUCKET)
blob_name = os.path.join(OUTPUT_DIR, job_id, 'model/deployment_config.yaml')
blob = storage.Blob(blob_name, bucket)
try:
blob.reload()
content = blob.download_as_string()
accuracy = float(yaml.safe_load(content)['labels']['accuracy']) / 100
step_count = int(yaml.safe_load(content)['labels']['global_step'])
return {_STEP_COUNT: step_count, _ACCURACY: accuracy}
except:
# Returns None if failed to load the built-in algo output file.
# It could be due to job failure and the trial will be `INFEASIBLE`
return None
def _GetJobMetrics(jobs):
accuracies_by_job_id = {}
for job in jobs:
accuracies_by_job_id[job] = _RetrieveAccuracy(job)
return accuracies_by_job_id
def _GetSuggestedParameterValue(trial, parameter, value_type):
param_found = [p for p in trial['parameters'] if p['parameter'] == parameter]
if param_found:
return param_found[0][value_type]
else:
return None
def _GenerateTrainingJobId(model_type, trial_id):
return _TRAINING_JOB_NAME_PATTERN.format(STUDY_ID, model_type, trial_id)
def _GetJobDir(job_id):
return os.path.join('gs://', OUTPUT_BUCKET, OUTPUT_DIR, job_id)
def _LinearCommand(job_id, learning_rate):
return ['gcloud', 'ai-platform', 'jobs', 'submit', 'training', job_id,
'--scale-tier', 'BASIC',
'--region', 'us-central1',
'--master-image-uri', _IMAGE_URIS['LINEAR'],
'--project', PROJECT_ID,
'--job-dir', _GetJobDir(job_id),
'--',
'--preprocess',
'--model_type=classification',
'--batch_size=250',
'--max_steps=1000',
'--learning_rate={}'.format(learning_rate),
'--training_data_path={}'.format(TRAINING_DATA_PATH)]
def _WideAndDeepCommand(job_id, learning_rate, dnn_learning_rate):
return ['gcloud', 'ai-platform', 'jobs', 'submit', 'training', job_id,
'--scale-tier', 'BASIC',
'--region', 'us-central1',
'--master-image-uri', _IMAGE_URIS['WIDE_AND_DEEP'],
'--project', PROJECT_ID,
'--job-dir', _GetJobDir(job_id),
'--',
'--preprocess',
'--test_split=0',
'--use_wide',
'--embed_categories',
'--model_type=classification',
'--batch_size=250',
'--learning_rate={}'.format(learning_rate),
'--dnn_learning_rate={}'.format(dnn_learning_rate),
'--max_steps=1000',
'--training_data_path={}'.format(TRAINING_DATA_PATH)]
Configuración para solicitar sugerencias o pruebas
client_id: El identificador del cliente que solicita la sugerencia. Si varias SuggestTrialsRequests tienen el mismo client_id, el servicio mostrará la prueba sugerida idéntica si esta está PENDING y proporcionará una prueba nueva si se completó la última sugerida.
suggestion_count_per_request: La cantidad de sugerencias (pruebas) solicitadas en una sola solicitud.
max_trial_id_to_stop: La cantidad de pruebas que se deben explorar antes de detenerse. Se estableció en 4 para acortar el tiempo de ejecución del código, por lo que no se espera que haya convergencia. Para que haya convergencia, es más probable que se necesite un valor de alrededor de 20 (una buena regla general es multiplicar la dimensionalidad total por 10).
client_id = 'client1' #@param {type: 'string'}
suggestion_count_per_request = 2 #@param {type: 'integer'}
max_trial_id_to_stop = 4 #@param {type: 'integer'}
print('client_id: {}'.format(client_id))
print('suggestion_count_per_request: {}'.format(suggestion_count_per_request))
print('max_trial_id_to_stop: {}'.format(max_trial_id_to_stop))
Solicita y ejecuta pruebas de AI Platform Optimizer
Ejecuta las pruebas.
current_trial_id = 0
while current_trial_id < max_trial_id_to_stop:
# Request trials
resp = ml.projects().locations().studies().trials().suggest(
parent=trial_parent(STUDY_ID),
body={'client_id': client_id, 'suggestion_count': suggestion_count_per_request}).execute()
op_id = resp['name'].split('/')[-1]
# Polls the suggestion long-running operations.
get_op = ml.projects().locations().operations().get(name=operation_name(op_id))
while True:
operation = get_op.execute()
if 'done' in operation and operation['done']:
break
time.sleep(1)
# Featches the suggested trials.
trials = []
for suggested_trial in get_op.execute()['response']['trials']:
trial_id = int(suggested_trial['name'].split('/')[-1])
trial = ml.projects().locations().studies().trials().get(name=trial_name(STUDY_ID, trial_id)).execute()
if trial['state'] not in ['COMPLETED', 'INFEASIBLE']:
print("Trial {}: {}".format(trial_id, trial))
trials.append(trial)
# Evaluates trials - Submit model training jobs using AI Platform Training built-in algorithms.
measurement_by_trial_id = EvaluateTrials(trials)
# Completes trials.
for trial in trials:
trial_id = int(trial['name'].split('/')[-1])
current_trial_id = trial_id
measurement = measurement_by_trial_id[trial_id]
print(("=========== Complete Trial: [{0}] =============").format(trial_id))
if measurement:
# Completes trial by reporting final measurement.
ml.projects().locations().studies().trials().complete(
name=trial_name(STUDY_ID, trial_id),
body={'final_measurement' : measurement}).execute()
else:
# Marks trial as `infeasbile` if when missing final measurement.
ml.projects().locations().studies().trials().complete(
name=trial_name(STUDY_ID, trial_id),
body={'trial_infeasible' : True}).execute()
Crea pruebas con tus propios parámetros (opcional)
Además de solicitar sugerencias (el método suggest) de parámetros del servicio, la API de AI Platform Optimizer también permite que los usuarios creen pruebas (el método create) con sus propios parámetros. AI Platform Optimizer permite registrar los experimentos que realizaron los usuarios y tomar el conocimiento para generar sugerencias nuevas.
Por ejemplo, si ejecutas un trabajo de entrenamiento del modelo con tus propios model_type y learning_rate en lugar de los que sugiere AI Platform Optimizer, puedes crear una prueba para este como parte del estudio.
# User has to leave `trial.name` unset in CreateTrial request, the service will
# assign it.
custom_trial = {
"clientId": "client1",
"finalMeasurement": {
"metrics": [
{
"metric": "accuracy",
"value": 0.86
}
],
"stepCount": "1000"
},
"parameters": [
{
"parameter": "model_type",
"stringValue": "LINEAR"
},
{
"floatValue": 0.3869103706121445,
"parameter": "learning_rate"
}
],
"state": "COMPLETED"
}
trial = ml.projects().locations().studies().trials().create(
parent=trial_parent(STUDY_ID), body=custom_trial).execute()
print(json.dumps(trial, indent=2, sort_keys=True))
Enumera las pruebas
Enumera los resultados de cada entrenamiento de prueba de optimización.
resp = ml.projects().locations().studies().trials().list(parent=trial_parent(STUDY_ID)).execute()
print(json.dumps(resp, indent=2, sort_keys=True))
Realice una limpieza
Para limpiar todos los recursos de Google Cloud que se usaron en este proyecto, puedes borrar el proyecto de Google Cloud que usaste para el instructivo.