Artikel ini adalah bagian kedua dari seri empat bagian yang membahas cara Anda memprediksi nilai umur pelanggan (CLV) menggunakan AI Platform (AI Platform) di Google Cloud.
Artikel dalam seri ini mencakup hal berikut:
- Bagian 1: Pengantar. Memperkenalkan CLV dan dua teknik pemodelan untuk memprediksi CLV.
- Bagian 2: Melatih model (artikel ini). Mendiskusikan cara menyiapkan data dan melatih model.
- Bagian 3: Men-deploy ke produksi. Menjelaskan cara men-deploy model yang dibahas di Bagian 2 ke sistem produksi.
- Bagian 4: Menggunakan AutoML Tables. Menunjukkan cara menggunakan AutoML Tables untuk membuat dan men-deploy model.
Kode untuk menerapkan sistem ini ada di repositori GitHub. Seri ini membahas tujuan kode dan cara penggunaannya.
Pengantar
Artikel ini mengikuti Bagian 1, tempat Anda mempelajari dua model berbeda untuk memprediksi nilai umur pelanggan (CLV):
- Model probabilistik
- Model deep neural network (DNN), jenis model machine learning
Seperti yang disebutkan di Bagian 1, salah satu tujuan seri ini adalah membandingkan model ini untuk memprediksi CLV. Bagian dari seri ini menjelaskan cara menyiapkan data serta membuat dan melatih kedua jenis model untuk memprediksi CLV, dan memberikan beberapa informasi perbandingan.
Menginstal kode
Jika ingin mengikuti proses yang dijelaskan dalam artikel ini, Anda harus menginstal kode contoh dari GitHub.
Jika Anda telah menginstal gcloud CLI, buka jendela terminal di komputer untuk menjalankan perintah ini. Jika Anda belum menginstal gcloud CLI, buka instance Cloud Shell.
Clone repositori kode sampel:
git clone https://github.com/GoogleCloudPlatform/tensorflow-lifetime-value
Ikuti petunjuk penginstalan di bagian Instal dalam file README untuk menyiapkan lingkungan Anda.
Persiapan data
Bagian ini menjelaskan cara mendapatkan data dan membersihkannya.
Mendapatkan dan membersihkan set data sumber
Sebelum dapat menghitung CLV, Anda harus memastikan bahwa data sumber Anda berisi setidaknya hal berikut:
- ID pelanggan yang digunakan untuk membedakan setiap pelanggan.
- Jumlah pembelian per pelanggan yang menunjukkan jumlah pembelanjaan pelanggan pada waktu tertentu.
- Tanggal untuk setiap pembelian.
Dalam artikel ini, kita akan membahas cara melatih model menggunakan data penjualan historis dari Set Data Retail Online yang tersedia secara publik dari UCI Machine Learning Repository.[1]
Langkah pertama adalah menyalin set data sebagai file CSV ke dalam Cloud Storage.
Dengan menggunakan salah satu alat pemuatan untuk BigQuery, Anda kemudian membuat tabel yang bernama data_source. (Nama ini bersifat arbitrer, tetapi kode di repositori GitHub menggunakan nama ini.) Set data ini
tersedia di bucket publik yang terkait dengan seri ini dan telah
dikonversi ke format CSV.
- Di komputer atau di Cloud Shell, jalankan perintah yang didokumentasikan di bagian Penyiapan file README di repositori GitHub.
Contoh set data berisi kolom yang tercantum dalam tabel berikut. Untuk pendekatan yang kami jelaskan dalam artikel ini, Anda hanya menggunakan
kolom dengan kolom Digunakan ditetapkan ke Ya. Beberapa kolom tidak
digunakan secara langsung, tetapi membantu membuat kolom baru—misalnya, UnitPrice
dan Quantity membuat order_value.
| Digunakan | Kolom | Jenis | Deskripsi |
|---|---|---|---|
| Tidak | InvoiceNo |
STRING |
Nominal. Nomor integral 6 digit yang ditetapkan secara unik untuk setiap transaksi.
Jika kode ini dimulai dengan huruf c, kode tersebut menunjukkan pembatalan. |
| Tidak | StockCode |
STRING |
Kode produk (item). Nominal, angka integral 5 digit yang ditetapkan secara unik ke setiap produk yang berbeda. |
| Tidak | Description |
STRING |
Nama produk (item). Nominal. |
| Ya | Quantity |
INTEGER |
Jumlah setiap produk (item) per transaksi. Numerik. |
| Ya | InvoiceDate |
STRING |
Tanggal dan waktu Invoice dalam format mm/dd/yy hh:mm. Hari dan waktu saat setiap transaksi dibuat. |
| Ya | UnitPrice |
FLOAT |
Harga unit. Numerik. Harga produk per unit dalam sterling. |
| Ya | CustomerID |
STRING |
Nomor pelanggan. Nominal. Angka integral 5 digit yang ditetapkan secara unik untuk setiap pelanggan. |
| Tidak | Country |
STRING |
Nama negara. Nominal. Nama negara tempat setiap pelanggan tinggal. |
Membersihkan data
Apa pun model yang Anda gunakan, Anda harus melakukan serangkaian langkah persiapan dan pembersihan yang umum untuk semua model. Operasi berikut diperlukan untuk mendapatkan kumpulan kolom dan data yang dapat digunakan:
- Mengelompokkan pesanan menurut hari, bukan menggunakan
InvoiceNo, karena unit waktu minimum yang digunakan oleh model probabilistik dalam solusi ini adalah hari. - Hanya pertahankan kolom yang berguna untuk model probabilistik.
- Hanya simpan data yang memiliki jumlah pesanan dan nilai uang positif, seperti pembelian.
- Hanya simpan data dengan jumlah pesanan negatif, seperti pengembalian.
- Hanya simpan data dengan ID pelanggan.
- Hanya simpan pelanggan yang membeli sesuatu dalam 90 hari terakhir.
- Hanya simpan pelanggan yang membeli minimal dua kali dalam jangka waktu yang digunakan untuk membuat fitur.
Anda dapat melakukan semua operasi ini menggunakan kueri BigQuery berikut. (Seperti perintah sebelumnya, Anda menjalankan kode ini di mana pun Anda meng-clone repositori GitHub.) Karena datanya sudah lama, tanggal 12 Desember 2011 dianggap sebagai tanggal hari ini untuk tujuan artikel ini.
Kueri ini melakukan dua tugas. Pertama, jika set data yang sedang digunakan berukuran besar, kueri akan mengecilkannya. (Set data yang berfungsi untuk solusi ini cukup kecil, tetapi kueri ini dapat memperkecil set data yang sangat besar sebesar dua urutan magnitudo dalam beberapa detik.)
Kedua, kueri membuat set data dasar untuk dikerjakan yang terlihat seperti berikut:
customer_id
|
order_date
|
order_value
|
order_qty_articles
|
|---|---|---|---|
| 16915 | 2011-08-04 | 173,7 | 6 |
| 15349 | 2011-07-04 | 107,7 | 77 |
| 14794 | 2011-03-30 | -33,9 | -2 |
Set data yang dibersihkan juga berisi kolom order_qty_articles. Kolom ini
hanya disertakan untuk digunakan oleh deep neural network (DNN) yang dijelaskan di
bagian berikutnya.
Menentukan interval pelatihan dan target
Untuk mempersiapkan pelatihan model, Anda harus memilih tanggal nilai minimum. Tanggal tersebut memisahkan pesanan menjadi dua partisi:
- Pesanan sebelum tanggal nilai minimum digunakan untuk melatih model.
- Pesanan setelah tanggal nilai minimum digunakan untuk menghitung nilai target.

Library Lifetimes menyertakan metode untuk memproses data secara pra-pemrosesan. Namun, set data yang Anda gunakan untuk CLV dapat cukup besar, sehingga tidak praktis untuk melakukan prapemrosesan data di satu mesin. Pendekatan yang dijelaskan dalam artikel ini menggunakan kueri yang dijalankan langsung di BigQuery untuk membagi pesanan menjadi dua set. Model ML dan probabilistik menggunakan kueri yang sama, yang memastikan bahwa kedua model beroperasi pada data yang sama.
Tanggal nilai minimum optimal mungkin berbeda untuk model ML dan model probabilistik. Anda dapat memperbarui nilai tanggal ini langsung dalam pernyataan SQL. Anggap tanggal nilai minimum yang optimal sebagai hyperparameter. Anda menemukan nilai yang paling sesuai dengan menjelajahi data dan menjalankan beberapa pelatihan pengujian.
Tanggal nilai minimum digunakan dalam klausa WHERE dari kueri SQL yang memilih
data pelatihan dari tabel data yang dibersihkan, seperti yang ditunjukkan dalam contoh berikut:
Menggabungkan data
Setelah membagi data menjadi interval pelatihan dan target, Anda akan menggabungkannya untuk membuat fitur dan target sebenarnya bagi setiap pelanggan. Untuk model probabilistik, agregasi dibatasi pada kolom recency, frequency, dan monetary (RFM). Untuk model DNN, model ini juga menggunakan fitur RFM, tetapi dapat menggunakan fitur tambahan untuk membuat prediksi yang lebih baik.
Kueri berikut menunjukkan cara membuat fitur untuk model DNN dan probabilistik secara bersamaan:
Tabel berikut mencantumkan fitur yang dibuat oleh kueri.
| Nama perlengkapan | Deskripsi | Probabilistik | DNN |
|---|---|---|---|
monetary_dnn
|
Jumlah semua nilai uang pesanan per pelanggan selama periode fitur. | x | |
monetary_btyd
|
Rata-rata semua nilai uang pesanan untuk setiap pelanggan selama periode fitur. Model probabilistik mengasumsikan bahwa nilai urutan pertama adalah 0. Hal ini diterapkan oleh kueri. | x | |
recency
|
Waktu antara pesanan pertama dan terakhir yang dilakukan oleh pelanggan selama periode fitur. | x | |
frequency_dnn
|
Jumlah pesanan yang dilakukan oleh pelanggan selama periode fitur. | x | |
frequency_btyd
|
Jumlah pesanan yang dilakukan oleh pelanggan selama periode fitur dikurangi pesanan pertama. | x | |
T
|
Waktu antara pesanan pertama yang dilakukan oleh pelanggan dan akhir periode fitur. | x | x |
time_between
|
Waktu rata-rata antara pesanan untuk pelanggan selama periode fitur. | x | |
avg_basket_value
|
Nilai uang rata-rata keranjang pelanggan selama periode fitur. | x | |
avg_basket_size
|
Jumlah item yang rata-rata dimiliki pelanggan di keranjang mereka selama periode fitur. | x | |
cnt_returns
|
Jumlah pesanan yang telah dikembalikan pelanggan selama periode fitur. | x | |
has_returned
|
Apakah pelanggan telah mengembalikan minimal satu pesanan selama periode fitur. | x | |
frequency_btyd_clipped
|
Sama seperti frequency_btyd, tetapi terpotong oleh outlier batas. |
x | |
monetary_btyd_clipped
|
Sama seperti monetary_btyd, tetapi terpotong oleh outlier batas. |
x | |
target_monetary_clipped
|
Sama seperti target_monetary, tetapi terpotong oleh outlier batas. |
x | |
target_monetary
|
Total jumlah yang dibelanjakan oleh pelanggan, termasuk periode pelatihan dan target. | x |
Pemilihan kolom ini dilakukan dalam kode. Untuk model probabilistik, pemilihan dilakukan menggunakan DataFrame Pandas:
Untuk model DNN, fitur TensorFlow ditentukan dalam
file context.py. Untuk model ini, hal berikut diabaikan sebagai fitur:
customer_id. Ini adalah nilai unik yang tidak berguna sebagai fitur.target_monetary. Ini adalah target yang harus diprediksi model, dan karenanya tidak digunakan sebagai input.
Membuat set pelatihan, evaluasi, dan pengujian untuk DNN
Bagian ini hanya berlaku untuk model DNN. Untuk melatih model ML, Anda harus menggunakan tiga set data yang tidak tumpang-tindih:
Set data pelatihan (70–80%) digunakan untuk mempelajari bobot guna mengurangi fungsi loss. Pelatihan berlanjut hingga fungsi kerugian tidak lagi menurun.
Set data evaluasi (10–15%) digunakan selama fase pelatihan untuk mencegah overfitting, yaitu saat model berperforma baik pada data pelatihan, tetapi tidak melakukan generalisasi dengan baik.
Set data pengujian (10–15%) hanya boleh digunakan sekali, setelah semua pelatihan dan evaluasi selesai, untuk melakukan pengukuran akhir performa model. Set data ini adalah set data yang belum pernah dilihat model selama proses pelatihan, sehingga memberikan pengukuran akurasi model yang valid secara statistik.
Kueri berikut membuat set pelatihan dengan sekitar 70% data. Kueri memisahkan data menggunakan teknik berikut:
- Hash ID pelanggan dihitung, yang menghasilkan bilangan bulat.
- Operasi modulo digunakan untuk memilih nilai hash yang berada di bawah nilai minimum tertentu.
Konsep yang sama digunakan untuk set evaluasi dan set pengujian, dengan data yang di atas nilai minimum akan disimpan.
Pelatihan
Seperti yang Anda lihat di bagian sebelumnya, Anda dapat menggunakan model yang berbeda untuk mencoba
memprediksi CLV. Kode yang digunakan dalam artikel ini dirancang agar Anda dapat memutuskan
model mana yang akan digunakan. Anda memilih model menggunakan parameter model_type
yang Anda teruskan ke skrip shell pelatihan berikut. Kode akan menangani
sisanya.
Sasaran pertama pelatihan adalah agar kedua model dapat mengalahkan benchmark sederhana, yang kita tentukan di bawah. Jika kedua jenis model dapat mengalahkannya (dan harus demikian), Anda dapat membandingkan performa setiap jenis dengan yang lain.
Melakukan benchmark pada model
Untuk tujuan seri ini, tolok ukur naif ditentukan menggunakan parameter berikut:
- Nilai keranjang rata-rata. Nilai ini dihitung pada semua pesanan yang dilakukan sebelum tanggal nilai minimum.
- Jumlah pesanan. Ini dihitung untuk interval pelatihan pada semua pesanan yang dilakukan sebelum tanggal nilai minimum.
- Pengganda jumlah. Nilai ini dihitung berdasarkan rasio jumlah hari sebelum tanggal nilai minimum dan jumlah hari antara tanggal nilai minimum dan saat ini.
Tolok ukur secara naif mengasumsikan bahwa rasio pembelian yang ditetapkan oleh pelanggan selama interval pelatihan tetap konstan selama interval target. Jadi, jika pelanggan membeli 6 kali selama 40 hari, asumsinya adalah mereka akan membeli 9 kali selama 60 hari (60/40 * 6 = 9). Mengalikan pengganda jumlah, jumlah pesanan, dan nilai keranjang rata-rata untuk setiap pelanggan akan memberikan nilai target prediksi naif untuk pelanggan tersebut.
Error tolok ukur adalah error akar rataan kuadrat (RMSE): rata-rata di semua pelanggan dari perbedaan absolut antara nilai target yang diprediksi dan nilai target sebenarnya. RMSE dihitung menggunakan kueri berikut di BigQuery:
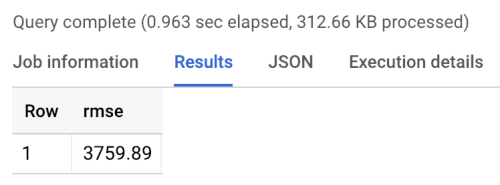
Benchmark menampilkan RMSE 3760, seperti yang ditunjukkan dalam hasil berikut dari menjalankan benchmark. Model harus mengalahkan nilai tersebut.
Model probabilistik
Seperti yang disebutkan dalam Bagian 1 dari seri ini, seri ini menggunakan library Python yang disebut Lifetimes yang mendukung berbagai model termasuk distribusi Pareto/binomial negatif (NBD) dan model BG/NBD beta-geometri. Contoh kode berikut menunjukkan cara menggunakan library Lifetimes untuk melakukan prediksi nilai masa aktif dengan model probabilistik.
Untuk menghasilkan hasil CLV menggunakan model probabilistik di lingkungan lokal, Anda dapat menjalankan skrip mltrain.sh berikut. Anda memberikan
parameter untuk tanggal mulai dan akhir bagian pelatihan serta untuk akhir
periode prediksi.
./mltrain.sh local data --model_type paretonbd_model --threshold_date [YOUR_THRESHOLD_DATE] --predict_end [YOUR_END_DATE]
Model DNN
Kode contoh mencakup implementasi DNN di TensorFlow menggunakan
class Estimator DNNRegressor bawaan, serta model Estimator
kustom. DNNRegressor dan Estimator kustom menggunakan jumlah lapisan dan jumlah neuron yang sama di setiap lapisan. Nilai tersebut adalah hyperparameter
yang perlu disesuaikan. Dalam file task.py berikut, Anda dapat menemukan daftar
beberapa hyperparameter yang ditetapkan ke nilai yang diuji
secara manual dan memberikan hasil yang baik.
Jika menggunakan AI Platform, Anda dapat menggunakan fitur penyesuaian hyperparameter, yang akan menguji berbagai parameter yang Anda tentukan dalam file yaml. AI Platform menggunakan pengoptimalan Bayesian untuk menelusuri ruang hyperparameter.
Hasil perbandingan model
Tabel berikut menunjukkan nilai RMSE untuk setiap model, seperti yang dilatih pada set data contoh. Semua model dilatih dengan data RFM. Nilai RMSE sedikit bervariasi di antara operasi, karena inisialisasi parameter acak. Model DNN menggunakan fitur tambahan seperti nilai keranjang rata-rata dan jumlah pengembalian.
| Model | RMSE |
|---|---|
| DNN | 947,9 |
| BG/NBD | 1557 |
| Pareto/NBD | 1558 |
Hasilnya menunjukkan bahwa pada set data ini, model DNN mengungguli model probabilistik saat memprediksi nilai uang. Namun, ukuran set data UCI yang relatif kecil membatasi validitas statistik hasil ini. Anda harus mencoba setiap teknik pada set data untuk melihat mana yang memberikan hasil terbaik. Semua model dilatih menggunakan data asli yang sama (termasuk ID pelanggan, tanggal pesanan, dan nilai pesanan) pada nilai RFM yang diekstrak dari data tersebut. Data pelatihan DNN menyertakan beberapa fitur tambahan seperti ukuran keranjang rata-rata dan jumlah pengembalian.
Model DNN hanya menghasilkan output nilai uang pelanggan secara keseluruhan. Jika Anda tertarik untuk memprediksi frekuensi atau churn, Anda harus melakukan beberapa tugas tambahan:
- Siapkan data dengan cara yang berbeda untuk mengubah target dan mungkin tanggal nilai minimum.
- Latih ulang model regresor untuk memprediksi target yang Anda minati.
- Sesuaikan hyperparameter.
Tujuannya di sini adalah untuk melakukan perbandingan pada fitur input yang sama antara dua jenis model. Salah satu keuntungan menggunakan DNN adalah Anda dapat meningkatkan hasil dengan menambahkan lebih banyak fitur daripada yang digunakan dalam contoh ini. Dengan DNN, Anda dapat memanfaatkan data dari sumber seperti peristiwa clickstream, profil pengguna, atau fitur produk.
Ucapan terima kasih
Dua, D. and Karra Taniskidou, E. (2017). Repositori Machine Learning UCI http://archive.ics.uci.edu/ml. Irvine, CA: University of California, School of Information and Computer Science.
Langkah selanjutnya
- Baca Bagian 3: Men-deploy ke produksi dari rangkaian ini untuk memahami cara men-deploy model tersebut.
- Pelajari solusi perkiraan prediktif lainnya.
- Pelajari arsitektur referensi, diagram, dan praktik terbaik tentang Google Cloud. Lihat Cloud Architecture Center kami.