This article is the fourth part of a four-part series that discusses how you can predict customer lifetime value (CLV) by using AI Platform (AI Platform) on Google Cloud. This article shows you how to use AutoML Tables to perform the predictions.
The articles in this series include the following:
- Part 1: Introduction. Introduces CLV and two modeling techniques for predicting CLV.
- Part 2: Training the model Discusses how to prepare the data and train the models.
- Part 3: Deploying to production. Describes how to deploy the models discussed in Part 2 to a production system.
- Part 4: Using AutoML Tables (this article). Shows how to use AutoML Tables to build and deploy a model.
The process described in this article relies on the same data processing steps in BigQuery that are described in Part 2 of the series. This article shows you how to upload that BigQuery dataset to AutoML Tables and create a model. This article also shows you how to integrate the AutoML model into the production system that's described in Part 3.
The code for implementing this system is in the same GitHub repository as the original series. This article discusses how to use the code for AutoML Tables in that repository.
Advantages of AutoML Tables
In the earlier parts of the series, you saw how to predict CLV using both a statistical model and a DNN model implemented in TensorFlow. AutoML Tables has several advantages over the other two methods:
- No coding is required in order to create the model. There is a console UI that allows you to create, train, manage, and deploy your datasets and models.
- Adding or changing features is easy, and can be done directly in the console interface.
- The training process is automated, including hyperparameter tuning.
- AutoML Tables searches for the best architecture for your dataset, relieving you of the need to choose from the many available options.
- AutoML Tables provides detailed analysis of the performance of a trained model, including feature importance.
As a result, it can take less time and cost to develop and train a fully optimized model using AutoML Tables.
A production deployment of an AutoML Tables solution requires you to use the Python client API to create and deploy models and run predictions. This article shows how to create and train AutoML Tables models using the client API. For guidance on how to perform these steps using the AutoML Tables console, see the AutoML Tables documentation.
Installing the code
If you have not installed the code for the original series, follow the same steps described in Part 2 of the original series to install the code. The README file in the GitHub repository describes all the steps necessary to prepare your environment, install the code, and set up AutoML Tables in your project.
If you previously installed the code, you need to perform these additional steps to complete the installation for this article:
- Enable the AutoML Tables API in your project.
- Activate the miniconda environment that you previously installed.
- Install the Python client library as described in the AutoML Tables documentation.
- Create and download an API key file and save it in a known location for later use with the client library.
Running the code
For many of the steps in this article, you run Python commands. After you prepare your environment and install the code, you have the following options for running the code:
Run the code in a Jupyter notebook. From the terminal window in your activated miniconda environment, run the following command:
$ (clv) jupyter notebook
The code for each of the steps in this article is in a notebook in the code repository named
notebooks/clv_automl.ipynb. Open this notebook in the Jupyter interface. You can then execute each of the steps as you follow along with the tutorial.Run the code as a Python script. The code steps for this tutorial are in the code repository in the
clv_automl/clv_automl.pyfile. The script takes arguments on the command line for configurable parameters such as the project ID, the location of the API key file, the Google Cloud region, and the name of the BigQuery dataset. You run the script from the terminal window in your activated miniconda environment, substituting your Google Cloud project name for[YOUR_PROJECT]:$ (clv) cd clv_automl $ (clv) python clv_automl.py --project_id [YOUR_PROJECT]
For the full list of parameters and default values, see the
create_parsermethod in the script, or run the script without arguments to see usage documentation.After you install the Cloud Composer environment as described in the README, run the code by executing the DAGs, as described later under Running the DAGs.
Preparing the data
This article uses the same dataset and data preparation steps in BigQuery that are described in Part 2 of the original series. After you've completed aggregating the data as described in that article, you are ready to create a dataset for use with AutoML Tables.
Creating the AutoML Tables dataset
To begin, upload the data you prepared in BigQuery into AutoML Tables.
To initialize the client, set the key file name to the name of the file you downloaded in the installation step:
keyfile_name = "mykey.json" client = automl_v1beta1.AutoMlClient.from_service_account_file(keyfile_name)Create the dataset:
create_dataset_response = client.create_dataset( location_path, {'display_name': dataset_display_name, 'tables_dataset_metadata': {}}) dataset_name = create_dataset_response.name
Importing the data from BigQuery
After you create the dataset, you can import the data from BigQuery.
Import the data from BigQuery into the AutoML Tables dataset:
dataset_bq_input_uri = 'bq://{}.{}.{}'.format(args.project_id, args.bq_dataset, args.bq_table) input_config = { 'bigquery_source': { 'input_uri': dataset_bq_input_uri}} import_data_response = client.import_data(dataset_name, input_config)
Training the model
After you've created the AutoML dataset for the CLV data, you can create the AutoML Tables model.
Get the AutoML Tables column specs for each column in the dataset:
list_table_specs_response = client.list_table_specs(dataset_name) table_specs = [s for s in list_table_specs_response] table_spec_name = table_specs[0].name list_column_specs_response = client.list_column_specs(table_spec_name) column_specs = {s.display_name: s for s in list_column_specs_response}The column specs are necessary in later steps.
Assign one of the columns as the label for the AutoML Tables model:
TARGET_LABEL = 'target_monetary' ... label_column_name = TARGET_LABEL label_column_spec = column_specs[label_column_name] label_column_id = label_column_spec.name.rsplit('/', 1)[-1] update_dataset_dict = { 'name': dataset_name, 'tables_dataset_metadata': { 'target_column_spec_id': label_column_id } } update_dataset_response = client.update_dataset(update_dataset_dict)This code uses the same label column (
target_monetary) as the TensorFlow DNN model in Part 2.Define the features to train the model:
feat_list = list(column_specs.keys()) feat_list.remove('target_monetary') feat_list.remove('customer_id') feat_list.remove('monetary_btyd') feat_list.remove('frequency_btyd') feat_list.remove('frequency_btyd_clipped') feat_list.remove('monetary_btyd_clipped') feat_list.remove('target_monetary_clipped')The features used to train the AutoML Tables model are the same ones used to train the TensorFlow DNN model in Part 2 of the original series. However, adding or subtracting features from the model is much easier with AutoML Tables. After a feature is created in BigQuery, it's automatically included in the model, unless you explicitly remove it as shown in the preceding code snippet.
Define the options for creating the model. The optimization objective of minimizing mean absolute error, represented by the parameter
MINIMIZE_MAE, is recommended for this dataset.model_display_name = args.automl_model model_training_budget = args.training_budget * 1000 model_dict = { 'display_name': model_display_name, 'dataset_id': dataset_name.rsplit('/', 1)[-1], 'tables_model_metadata': { 'target_column_spec': column_specs['target_monetary'], 'input_feature_column_specs': [ column_specs[x] for x in feat_list], 'train_budget_milli_node_hours': model_training_budget, 'optimization_objective': 'MINIMIZE_MAE' } }For more information, see the AutoML Tables documentation on optimization objectives.
Create the model and start training:
create_model_response = client.create_model(location_path, model_dict) create_model_result = create_model_response.result() model_name = create_model_result.nameThe return value from the client call (
create_model_response) is returned immediately. The valuecreate_model_response.result()is a promise, which blocks until training is complete. Themodel_namevalue is a resource path that's necessary for further client calls that operate on the model.
Evaluating the model
After the model training is complete, you can retrieve the model evaluation statistics. You can use either the Google Cloud console or the client API.
To use the console, in the AutoML Tables console, go to the Evaluate tab:

To use the client API, retrieve the model evaluation statistics:
model_evaluations = [e for e in client.list_model_evaluations(model_name)] model_evaluation = model_evaluations[0]You see output similar to this:
name: "projects/595920091534/locations/us-central1/models/TBL3912308662231629824/modelEvaluations/9140437057533851929" create_time { seconds: 1553108019 nanos: 804478000 } evaluated_example_count: 125 regression_evaluation_metrics: { mean_absolute_error: 591.091 root_mean_squared_error: 853.481 mean_absolute_percentage_error: 21.47 r_squared: 0.907 }
The root mean squared error of 853.481 compares favorably against the probabilistic and TensorFlow models used in the original series. However, as discussed in Part 2, it's advisable to try each of the provided techniques with your data to see which performs best.
Deploying the AutoML model
The Cloud Composer DAGs from the original series have been updated to include the AutoML Tables model for both training and prediction. For general information on the functioning of the Cloud Composer DAGs, see the section on Automating the Solution in Part 3 of the original articles.
You can install the Cloud Composer orchestration system for this solution by following the instructions in the README.
The updated DAGs call methods in the clv_automl/clv_automl.py script that
replicate the client code calls shown earlier in order to create the model and
run predictions.
The training DAG
The updated DAG for training includes tasks to create an AutoML Tables model. The following diagram shows the new DAG for training.

The prediction DAG
The updated DAG for prediction includes tasks to run batch predictions with the AutoML Tables model. The following diagram shows the new DAG for predictions.
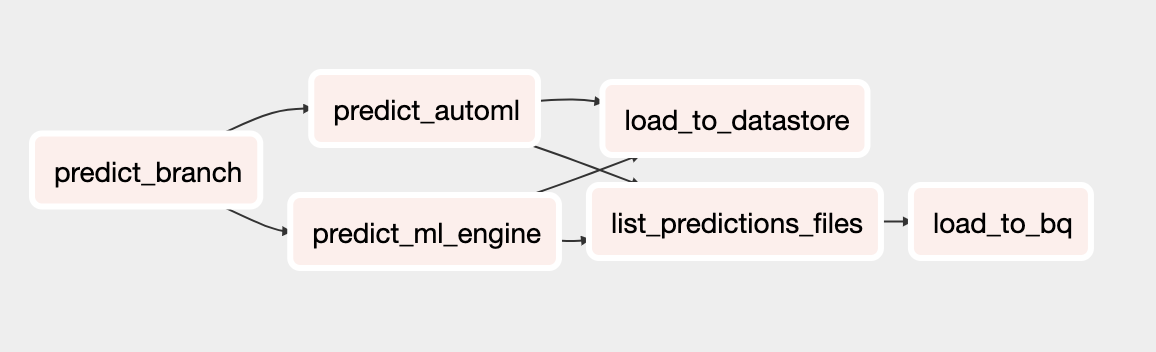
Running the DAGs
To trigger the DAGs manually, you can run the commands from the Run Dags section of the README file in Cloud Shell or by using the Google Cloud CLI.
To run the
build_train_deployDAG:gcloud composer environments run ${COMPOSER_NAME} \ --project ${PROJECT} \ --location ${REGION} \ dags trigger \ -- \ build_train_deploy \ --conf '{"model_type":"automl", "project":"'${PROJECT}'", "dataset":"'${DATASET_NAME}'", "threshold_date":"2011-08-08", "predict_end":"2011-12-12", "model_name":"automl_airflow", "model_version":"v1", "max_monetary":"15000"}'Run the
predict_serveDAG:gcloud composer environments run ${COMPOSER_NAME} \ --project ${PROJECT} \ --location ${REGION} \ dags trigger \ -- \ predict_serve \ --conf '{"model_name":"automl_airflow", "model_version":"v1", "dataset":"'${DATASET_NAME}'"}'
What's next
- Review the complete CLV tutorial set.
- Run the full example in the GitHub repository.
- Learn about other predictive forecasting solutions.
- Explore reference architectures, diagrams, and best practices about Google Cloud. Take a look at our Cloud Architecture Center.