Architektur
Das folgende Diagramm zeigt die allgemeine Architektur einer serverlosen ELT-Pipeline (Extrahieren, Laden und Transformieren), die Workflows verwendet.

Betrachten Sie im obigen Diagramm eine Einzelhandelsplattform, die regelmäßig Verkaufsereignisse als Dateien aus verschiedenen Geschäften erfasst und die Dateien anschließend in einen Cloud Storage-Bucket schreibt. Die Ereignisse werden verwendet, um Geschäftsmesswerte durch Importieren und Verarbeiten in BigQuery bereitzustellen. Diese Architektur bietet ein zuverlässiges und serverloses Orchestrierungssystem zum Importieren Ihrer Dateien in BigQuery und ist in die beiden folgenden Module unterteilt:
- Dateiliste: Verwaltet die Liste der nicht verarbeiteten Dateien, die einem Cloud Storage-Bucket in einer Firestore-Sammlung hinzugefügt wurden.
Dieses Modul arbeitet mit einer Cloud Run-Funktion, die durch das Speicherereignis Objekt finalisieren ausgelöst wird. Dieses wird generiert, wenn dem Cloud Storage-Bucket eine neue Datei hinzugefügt wird. Der Dateiname wird an das Array
filesder Sammlung mit dem Namennewin Firestore angehängt. Workflow: Führt die geplanten Workflows werden aus. Cloud Scheduler löst einen Workflow aus, der eine Reihe von Schritten gemäß einer YAML-basierten Syntax ausführt, um das Laden zu orchestrieren und dann die Daten durch Aufrufen von Cloud Run-Funktionen in BigQuery zu transformieren. Die Schritte im Workflow rufen Cloud Run Functions auf, um die folgenden Aufgaben auszuführen:
- Erstellen und starten Sie einen BigQuery-Ladejob.
- Fragen Sie den Ladejobstatus ab.
- Erstellen und starten Sie den Transformationsabfragejob.
- Fragen Sie den Status des Transformationsjobs ab.
Durch die Verwendung der Transaktionen zum Verwalten der Liste der neuen Dateien in Firestore wird sichergestellt, dass keine Datei übersehen wird, wenn sie von einem Workflow in BigQuery importiert werden. Separate Ausführungen des Workflows sind idempotent, indem Job-Metadaten und der Status in Firestore gespeichert werden.
Ziele
- Erstellen Sie eine Firestore-Datenbank.
- Richten Sie einen Cloud Run-Funktionstrigger ein, um Dateien zu verfolgen, die dem Cloud Storage-Bucket in Firestore hinzugefügt wurden.
- Cloud Run-Funktionen zum Ausführen und Überwachen von BigQuery-Jobs bereitstellen.
- Einen Workflow bereitstellen und ausführen, um den Prozess zu automatisieren.
Kosten
In diesem Dokument verwenden Sie die folgenden kostenpflichtigen Komponenten von Google Cloud:
Mit dem Preisrechner können Sie eine Kostenschätzung für Ihre voraussichtliche Nutzung vornehmen.
Nach Abschluss der in diesem Dokument beschriebenen Aufgaben können Sie weitere Kosten vermeiden, indem Sie die erstellten Ressourcen löschen. Weitere Informationen finden Sie unter Bereinigen.
Hinweise
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Cloud Build, Cloud Run functions, Identity and Access Management, Resource Manager, and Workflows APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. Rufen Sie die Seite Willkommen auf und notieren Sie sich die Projekt-ID, die Sie in einem späteren Schritt benötigen.
In the Google Cloud console, activate Cloud Shell.
Umgebung vorbereiten
Um Ihre Umgebung vorzubereiten, erstellen Sie eine Firestore-Datenbank, klonen Sie die Codebeispiele aus dem GitHub-Repository, erstellen Sie Ressourcen mit Terraform, bearbeiten Sie die YAML-Datei für Workflows und installieren Sie die Anforderungen für den Dateigenerator.
So erstellen Sie eine Firestore-Datenbank:
Rufen Sie in der Google Cloud Console die Seite „Firestore“ auf.
Klicken Sie auf Nativen Modus auswählen.
Wählen Sie im Menü Standort auswählen die Region aus, in der Sie die Firestore-Datenbank hosten möchten. Wir empfehlen, eine Region in der Nähe Ihres physischen Standorts auszuwählen.
Klicken Sie auf Datenbank erstellen.
Klonen Sie in Cloud Shell das Quell-Repository:
cd $HOME && git clone https://github.com/GoogleCloudPlatform/workflows-demos cd workflows-demos/workflows-bigquery-loadErstellen Sie in Cloud Shell mit Terraform die folgenden Ressourcen:
terraform init terraform apply \ -var project_id=PROJECT_ID \ -var region=REGION \ -var zone=ZONE \ --auto-approveErsetzen Sie Folgendes:
PROJECT_ID: Ihre Google Cloud -Projekt-IDREGION: Ein bestimmter geografischer Standort von Google Cloudzum Hosten Ihrer Ressourcen, z. B.us-central1ZONE: Ein Standort innerhalb einer Region zum Hosten Ihrer Ressourcen, z. B.us-central1-b
Es sollte eine Meldung ähnlich der folgenden angezeigt werden:
Apply complete! Resources: 7 added, 0 changed, 1 destroyed.Mit Terraform können Sie Infrastruktur in großem Maßstab sicher und vorhersehbar erstellen, ändern und aktualisieren. Die folgenden Ressourcen werden in Ihrem Projekt erstellt:
- Dienstkonten mit den erforderlichen Berechtigungen, um einen sicheren Zugriff auf Ihre Ressourcen zu gewährleisten.
- Ein BigQuery-Dataset mit dem Namen
serverless_elt_datasetund eine Tabelle namensword_count, um die eingehenden Dateien zu laden - Ein Cloud Storage-Bucket mit dem Namen
${project_id}-ordersbucketfür das Staging von Eingabedateien - Die folgenden fünf Cloud Run-Funktionen:
file_add_handlerfügt den Namen der Dateien hinzu, die dem Cloud Storage-Bucket in der Firestore-Sammlung hinzugefügt wurden.create_joberstellt einen neuen BigQuery-Ladejob und verknüpft Dateien in der Firebase-Sammlung mit dem Job.create_queryerstellt einen neuen BigQuery-Abfragejob.poll_bigquery_jobruft den Status eines BigQuery-Jobs ab.run_bigquery_jobstartet einen BigQuery-Job.
Rufen Sie die URLs für die Cloud Run-Funktionen
create_job,create_query,poll_jobundrun_bigquery_jobab, die Sie im vorherigen Schritt bereitgestellt haben.gcloud functions describe create_job | grep url gcloud functions describe poll_bigquery_job | grep url gcloud functions describe run_bigquery_job | grep url gcloud functions describe create_query | grep url
Die Ausgabe sieht etwa so aus:
url: https://REGION-PROJECT_ID.cloudfunctions.net/create_job url: https://REGION-PROJECT_ID.cloudfunctions.net/poll_bigquery_job url: https://REGION-PROJECT_ID.cloudfunctions.net/run_bigquery_job url: https://REGION-PROJECT_ID.cloudfunctions.net/create_query
Notieren Sie sich diese URLs, da Sie sie beim Bereitstellen des Workflows benötigen.
Workflow erstellen und bereitstellen
Öffnen Sie in Cloud Shell die Quelldatei für den Workflow,
workflow.yaml:Ersetzen Sie Folgendes:
CREATE_JOB_URL: die URL der Funktion zum Erstellen eines neuen JobsPOLL_BIGQUERY_JOB_URL: die URL der Funktion, die den Status eines laufenden Jobs abfragtRUN_BIGQUERY_JOB_URL: die URL der Funktion zum Starten eines BigQuery-LadejobsCREATE_QUERY_URL: die URL der Funktion zum Starten eines BigQuery-AbfragejobsBQ_REGION: die BigQuery-Region, in der Daten gespeichert sind, z. B.USBQ_DATASET_TABLE_NAME: Der Name der BigQuery-Dataset-Tabelle im FormatPROJECT_ID.serverless_elt_dataset.word_count
Stellen Sie die Datei
workflowbereit:gcloud workflows deploy WORKFLOW_NAME \ --location=WORKFLOW_REGION \ --description='WORKFLOW_DESCRIPTION' \ --service-account=workflow-runner@PROJECT_ID.iam.gserviceaccount.com \ --source=workflow.yamlDabei gilt:
WORKFLOW_NAME: der eindeutige Name des WorkflowsWORKFLOW_REGION: die Region, in der der Workflow bereitgestellt wird, z. B.us-central1WORKFLOW_DESCRIPTION: die Beschreibung des Workflows
Erstellen Sie eine virtuelle Python 3-Umgebung und installieren Sie die Installationsanforderungen für den Dateigenerator:
sudo apt-get install -y python3-venv python3 -m venv env . env/bin/activate cd generator pip install -r requirements.txt
Zu importierende Dateien generieren
Das Python-Skript
gen.pygeneriert zufällige Inhalte im Avro-Format. Das Schema ist mit der BigQuery-Tabelleword_countidentisch. Diese Avro-Dateien werden in den angegebenen Cloud Storage-Bucket kopiert.Generieren Sie die Dateien in Cloud Shell:
python gen.py -p PROJECT_ID \ -o PROJECT_ID-ordersbucket \ -n RECORDS_PER_FILE \ -f NUM_FILES \ -x FILE_PREFIXDabei gilt:
RECORDS_PER_FILE: die Anzahl der Datensätze in einer einzelnen DateiNUM_FILES: die Gesamtanzahl der hochzuladenden DateienFILE_PREFIX: das Präfix für die Namen der generierten Dateien
Dateieinträge in Firestore ansehen
Wenn die Dateien in Cloud Storage kopiert werden, wird die Cloud Run-Funktion
handle_new_fileausgelöst. Diese Funktion fügt die Dateiliste dem Dateilistenarray im Dokumentnewin der Firestore-Sammlungjobshinzu.Rufen Sie in der Google Cloud Console die Firestore-Seite Daten auf, um sich die Dateiliste anzeigen zu lassen.
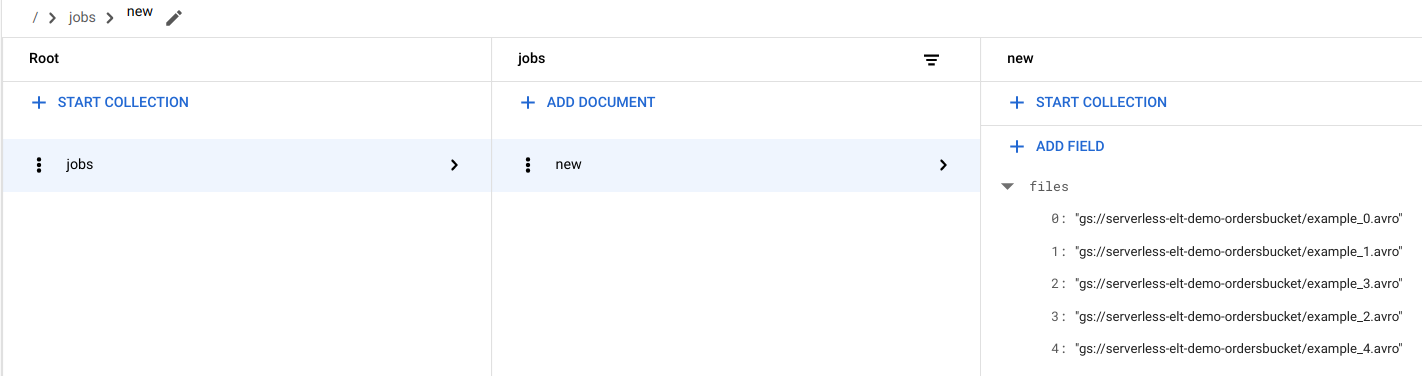
Workflow auslösen
Mit Workflows wird eine Reihe von serverlosen Aufgaben ausGoogle Cloud - und API-Diensten verknüpft. Einzelne Schritte in diesem Workflow werden als Cloud Run-Funktionen ausgeführt und der Status wird in Firestore gespeichert. Alle Aufrufe von Cloud Run Functions werden mithilfe des Dienstkontos des Workflows authentifiziert.
Führen Sie den Workflow in Cloud Shell aus:
gcloud workflows execute WORKFLOW_NAME
Das folgende Diagramm zeigt die im Workflow verwendeten Schritte:

Der Workflow ist in zwei Teile unterteilt: den Hauptworkflow und den untergeordneten Workflow. Der Hauptworkflow übernimmt die Joberstellung und die bedingte Ausführung, während der untergeordnete Workflow einen BigQuery-Job ausführt. Der Workflow führt folgende Vorgänge aus:
- Die Cloud Run-Funktion
create_joberstellt ein neues Jobobjekt, ruft die Liste der zu Cloud Storage hinzugefügten Dateien aus dem Firestore-Dokument ab und verknüpft die Dateien mit dem Ladejob. Wenn keine Dateien zum Laden vorhanden sind, erstellt die Funktion keinen neuen Job. - Die Cloud Run-Funktion
create_queryverwendet die auszuführende Abfrage zusammen mit der BigQuery-Region, in der die Abfrage ausgeführt werden soll. Die Funktion erstellt den Job in Firestore und gibt die Job-ID zurück. - Die Cloud Run-Funktion
run_bigquery_jobruft die ID des Jobs ab, der ausgeführt werden muss, und ruft dann die BigQuery API auf, um den Job zu senden. - Statt auf den Abschluss des Jobs in der Cloud Run-Funktion zu warten, können Sie den Status des Jobs regelmäßig abfragen.
- Die Cloud Run-Funktion
poll_bigquery_jobgibt den Status des Jobs an. Sie wird so lange wiederholt aufgerufen, bis der Job abgeschlossen ist. - Um Verzögerungen zwischen Aufrufen der Cloud Run-Funktion
poll_bigquery_jobhinzuzufügen, wird über Workflows einesleep-Routine aufgerufen.
- Die Cloud Run-Funktion
Jobstatus ansehen
Sie können die Dateiliste und den Status des Jobs aufrufen.
Rufen Sie in derGoogle Cloud -Konsole die Firestore-Seite Daten auf.
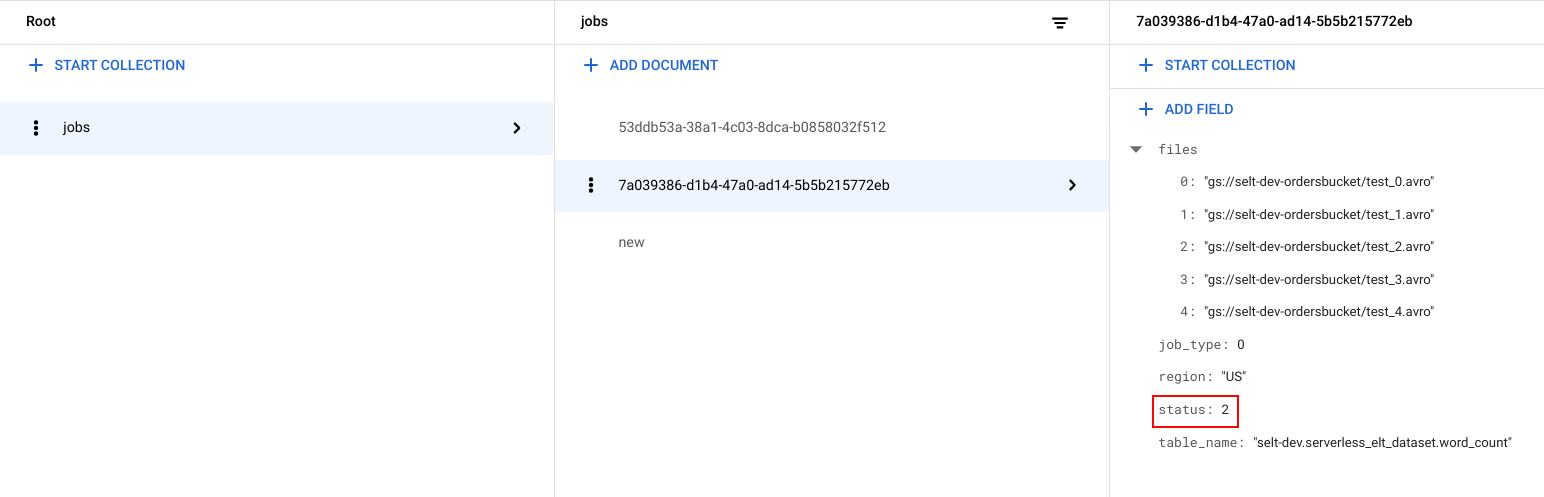
Für jeden Job wird eine eindeutige Kennzeichnung (UUID) generiert. Klicken Sie auf die Job-ID, um
job_typeundstatusaufzurufen. Jeder Job kann einen der folgenden Typen und Status haben:job_type: Der Typ des Jobs, der vom Workflow ausgeführt wird, mit einem der folgenden Werte:- 0: Daten in BigQuery laden
- 1: Abfrage in BigQuery ausführen
status: der aktuelle Status des Jobs mit einem der folgenden Werte:- 0: Der Job wurde erstellt, aber nicht gestartet.
- 1: Der Job wird ausgeführt.
- 2: Der Job wurde erfolgreich ausgeführt.
- 3: Es ist ein Fehler aufgetreten und der Job wurde nicht erfolgreich abgeschlossen.
Das Jobobjekt enthält auch Metadatenattribute wie die Region des BigQuery-Datasets, den Namen der BigQuery-Tabelle und bei einem Abfragejob den ausgeführten Abfragestring.
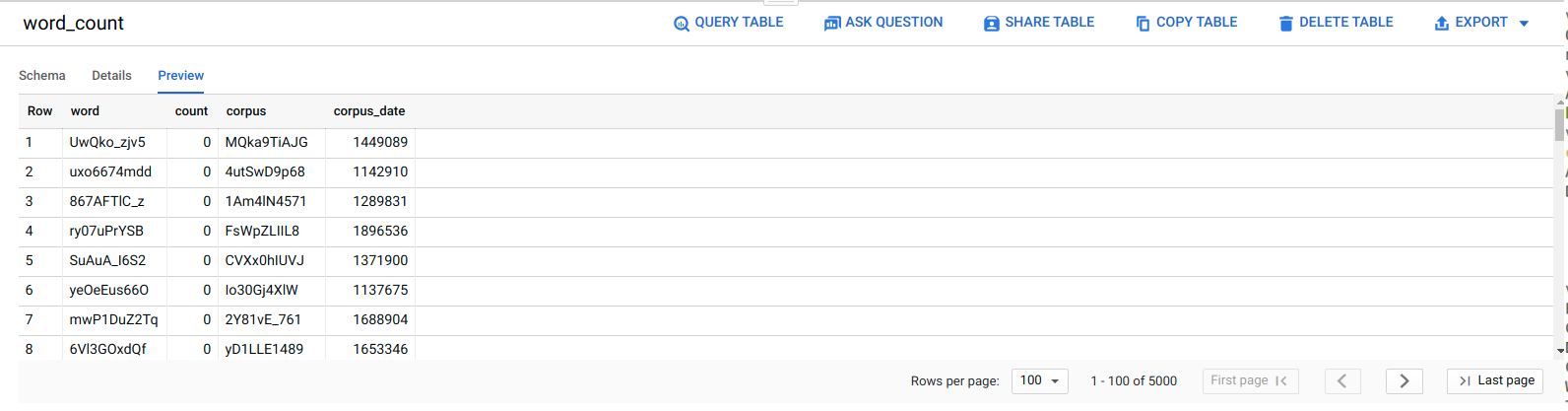
Daten in BigQuery ansehen
Wenn Sie wissen möchten, ob der ELT-Job erfolgreich ausgeführt wurde, überprüfen Sie, ob die Daten in der Tabelle angezeigt werden.
Rufen Sie in der Google Cloud Console die Seite Editor auf.
Klicken Sie auf die Tabelle
serverless_elt_dataset.word_count.Klicken Sie auf den Tab Preview (Vorschau).
Workflow planen
Zur regelmäßigen Ausführung des Workflows nach Zeitplan können Sie Cloud Scheduler verwenden.
Bereinigen
Am einfachsten vermeiden Sie weitere Kosten, wenn Sie das für die Anleitung erstellte Projekt Google Cloud löschen. Alternativ haben Sie die Möglichkeit, die einzelnen Ressourcen zu löschen.Einzelne Ressourcen löschen
Entfernen Sie in Cloud Shell alle mit Terraform erstellten Ressourcen:
cd $HOME/bigquery-workflows-load terraform destroy \ -var project_id=PROJECT_ID \ -var region=REGION \ -var zone=ZONE \ --auto-approve
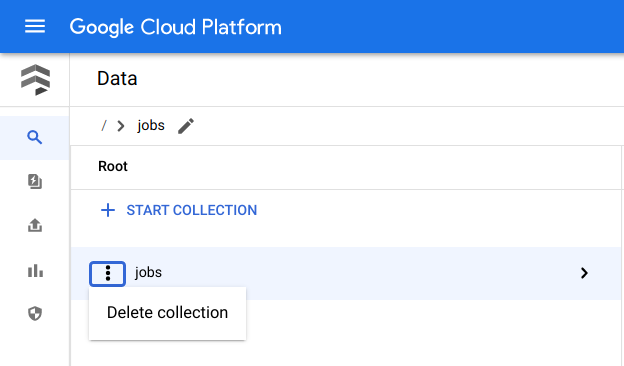
Rufen Sie in der Google Cloud Console die Firestore-Seite Daten auf.
Klicken Sie neben Jobs auf Menü und wählen Sie Löschen aus.
Projekt löschen
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Nächste Schritte
- Um mehr über BigQuery zu erfahren, lesen Sie die BigQuery-Dokumentation.
- Benutzerdefinierte serverlose ML-Pipelines erstellen
- Weitere Referenzarchitekturen, Diagramme und Best Practices finden Sie im Cloud-Architekturcenter.