LangChain on Vertex AI(プレビュー)により、LangChain のオープンソース ライブラリを使用してカスタムの生成 AI アプリケーションを構築できます。また、モデル、ツール、デプロイに Vertex AI を使用できます。LangChain on Vertex AI(プレビュー)を使用すると、次のことができます。
- 使用する大規模言語モデル(LLM)を選択する。
- 外部 API にアクセスするツールを定義する。
- オーケストレーション フレームワークで、ユーザーとシステム コンポーネント間のインターフェースを構成する。
- フレームワークをマネージド ランタイムにデプロイする。
利点
- カスタマイズ可能: LangChain の標準化されたインターフェースを利用することで、LangChain on Vertex AI を採用してさまざまな種類のアプリケーションを構築できます。アプリケーションのロジックをカスタマイズし、任意のフレームワークを組み込むことができるため、高い柔軟性を実現できます。
- デプロイを簡素化: LangChain on Vertex AI は、LangChain と同じ API を使用して LLM とやり取りし、アプリケーションを構築します。LangChain on Vertex AI では、Reasoning Engine ランタイムがシングルクリック デプロイをサポートし、ライブラリに基づいて準拠 API を生成するため、Vertex AI LLM によるデプロイが簡素化され、高速化されます。
- Vertex AI エコシステムとのインテグレーション: LangChain on Vertex AI の Reasoning Engine は、Vertex AI のインフラストラクチャとビルド済みコンテナを使用して、LLM アプリケーションのデプロイをサポートします。Vertex AI API を使用して、Gemini モデル、関数呼び出し、拡張機能と統合できます。
- 安全、非公開、スケーラブル: 開発プロセスを独自に管理する代わりに、単一の SDK 呼び出しを使用できます。Reasoning Engine マネージド ランタイムを使用すると、アプリケーション サーバーの開発、コンテナの作成、認証、IAM、スケーリングの構成などのタスクから解放されます。Vertex AI は、自動スケーリング、リージョンの拡大、コンテナの脆弱性に対応します。
ユースケース
エンドツーエンドの例を使用して Vertex AI の LangChain の詳細を確認するには、次のリソースをご覧ください。
システム コンポーネント
OSS LangChain と Vertex AI を使用してカスタムの生成 AI アプリケーションを構築してデプロイするには、次の 4 つのコンポーネントが必要です。
| コンポーネント | 説明 |
|---|---|
| LLM |
カスタム アプリケーションにクエリを送信すると、LLM がクエリを処理してレスポンスを提供します。 外部 API と通信する一連のツールを定義してモデルに提供することもできます。クエリの処理中に、モデルは特定のタスクをツールに委任します。これは、基盤モデルまたはファインチューニング済みモデルへの 1 つ以上のモデル呼び出しを意味します。 詳細については、モデルのバージョンとライフサイクルをご覧ください。 |
| ツール |
外部 API(データベースなど)と通信する一連のツールを定義してモデルに提供することもできます。クエリの処理中に、モデルは特定のタスクをツールに委任できます。 Vertex AI のマネージド ランタイムを介したデプロイは、Gemini 関数呼び出しに基づくツールを使用するように最適化されていますが、LangChain ツール / 関数呼び出しもサポートしています。Gemini 関数呼び出しの詳細については、関数の呼び出しをご覧ください。 |
| オーケストレーション フレームワーク |
LangChain on Vertex AI を使用すると、Vertex AI で LangChain オーケストレーション フレームワークを使用できます。LangChain を使用して、アプリケーションの確定性を決定します。 すでに LangChain を使用している場合は、既存の LangChain コードを使用して Vertex AI にアプリケーションをデプロイできます。それ以外の場合は、独自のアプリケーション コードを作成し、Vertex AI の LangChain テンプレートを活用するオーケストレーション フレームワークで構造化できます。 詳細については、アプリケーションを開発するをご覧ください。 |
| マネージド ランタイム | LangChain on Vertex AI を使用すると、Reasoning Engine マネージド ランタイムにアプリケーションをデプロイできます。このランタイムは、セキュリティ、プライバシー、オブザーバビリティ、スケーラビリティなど、Vertex AI インテグレーションのすべてのメリットを備えた Vertex AI サービスです。API 呼び出しでアプリケーションの本番環境への展開、スケーリングを行い、ローカルでテストしたプロトタイプをエンタープライズ対応のデプロイにすばやく移行できます。詳細については、アプリケーションをデプロイするをご覧ください。 |
Gemini などのモデルの上にツールとカスタム関数を重ねることでエージェント機能を使用するカスタム生成 AI アプリケーションのプロトタイピングと構築を行う方法は、数多くあります。アプリケーションを本番環境に移行するときは、エージェントとその基盤となるコンポーネントをデプロイして管理する方法を検討する必要があります。
LangChain on Vertex AI のコンポーネントを使用する目的は、カスタム関数、エージェントの動作、モデル パラメータなど、エージェント機能の特に重要な側面にユーザーが注力してカスタマイズできるようにすることです。デプロイ、スケーリング、パッケージ化、バージョンの管理は Google が担います。スタックの下位レベルでは、想定していた以上の管理が求められる場合があります。スタックの上位レベルでは、デベロッパーが制御できる範囲は限られる場合があります。
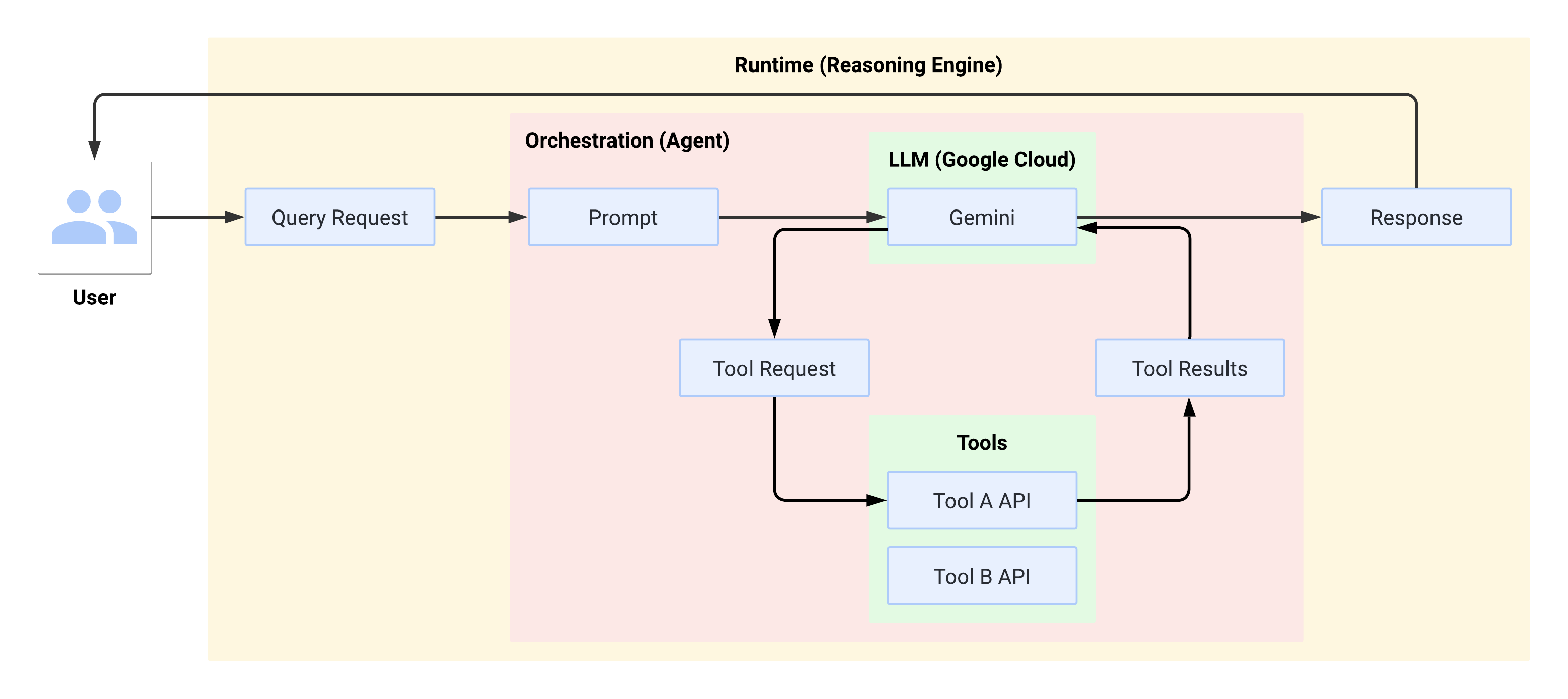
実行時のシステムフロー
ユーザーがクエリを実行すると、定義されたエージェントがクエリを LLM のプロンプトに変換します。LLM はプロンプトを処理し、どのツールを使用するかどうかを判断します。
LLM がツールを使用する場合、ツールを呼び出す名前とパラメータを含む FunctionCall を生成します。エージェントは FunctionCall を使用してツールを呼び出し、ツールの結果を LLM に返します。LLM がツールを使用しない場合は、エージェントがユーザーに返信するコンテンツを生成します。
次の図は、実行時のシステムフローを示しています。
生成 AI アプリケーションの作成とデプロイ
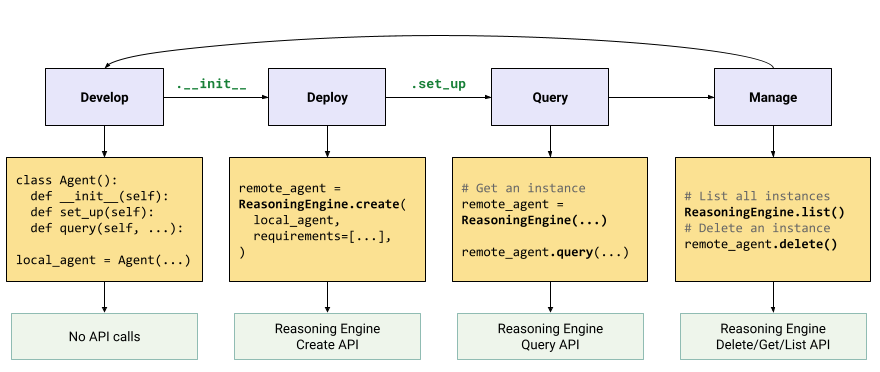
生成 AI アプリケーションを構築するワークフローは次のとおりです。
| ステップ | 説明 |
|---|---|
| 1. 環境を設定する | Google プロジェクトを設定し、最新バージョンの Vertex AI SDK for Python をインストールします。 |
| 2. アプリケーションを開発する | Reasoning Engine にデプロイできる LangChain アプリケーションを開発します。 |
| 3. アプリケーションをデプロイする | アプリケーションを Reasoning Engine にデプロイします。 |
| 4. アプリケーションを使用する | Reasoning Engine にクエリを実行してレスポンスを取得します。 |
| 5. デプロイされたアプリケーションを管理する | Reasoning Engine にデプロイしたアプリケーションを管理、削除します。 |
| 6. (省略可)アプリケーション テンプレートをカスタマイズする | 新しいアプリケーション用にテンプレートをカスタマイズします。 |
次の図は、このプロセスを示しています。
料金
料金体系は、リクエストの処理、コンテナの起動、コンテナのシャットダウン中に使用される vCPU 時間と GiB 時間に基づいています。つまり、ワークロードで消費されるコンピューティング(vCPU)リソースとメモリリソースの両方が課金されます。
不要な費用が発生しないように、未使用のリソースは削除することをおすすめします。