É possível usar o SDK da Vertex AI para Python para avaliar de maneira programática seus modelos de linguagem generativa.
Instale o SDK da Vertex AI
Para instalar a avaliação rápida do SDK da Vertex AI para Python, execute o seguinte comando:
pip install --upgrade google-cloud-aiplatform[rapid_evaluation]
Para mais informações, consulte Instalar o SDK da Vertex AI para Python.
Autenticar o SDK da Vertex AI
Depois de instalar o SDK da Vertex AI para Python, é preciso fazer a autenticação. Os tópicos a seguir explicam como autenticar com o SDK da Vertex AI se você estiver trabalhando localmente e no Colaboratory:
Se você estiver desenvolvendo localmente, configure o Application Default Credentials (ADC) no seu ambiente local:
Instale a Google Cloud CLI e inicialize-a executando o seguinte comando:
gcloud initCrie as credenciais de autenticação para sua Conta do Google:
gcloud auth application-default loginUma tela de login será exibida. Após o login, suas credenciais são armazenadas no arquivo de credenciais local usado pelo ADC. Para mais informações sobre como trabalhar com o ADC em um ambiente local, consulte Ambiente de desenvolvimento local.
Se você estiver trabalhando no Colaboratory, execute o seguinte comando em uma célula do Colab para autenticar:
from google.colab import auth auth.authenticate_user()Esse comando abre uma janela em que você pode concluir a autenticação.
Consulte a referência do SDK de avaliação rápida para saber mais.
Criar uma tarefa de avaliação
Como a avaliação é orientada principalmente por tarefas com os modelos de IA generativa, a avaliação on-line introduz a abstração de tarefas de avaliação para facilitar os casos de uso de avaliação. Para conseguir comparações justas de modelos generativos, é possível executar geralmente avaliações de modelos e modelos de comandos em um conjunto de dados de avaliação e as respectivas métricas associadas repetidamente. A classe EvalTask foi projetada para permitir esse novo paradigma de avaliação. Além disso, o EvalTask permite uma integração total com os Experimentos da Vertex AI, que podem ajudar a monitorar configurações e resultados para cada execução de avaliação.
Os Experimentos da Vertex AI podem ajudar a gerenciar e interpretar resultados de avaliação, permitindo que você aja em menos tempo. O exemplo a seguir mostra como criar uma instância da classe EvalTask e executar uma avaliação:
from vertexai.preview.evaluation import EvalTask
eval_task = EvalTask(
dataset=DATASET,
metrics=["bleu", "rouge_l_sum"],
experiment=EXPERIMENT_NAME
)
O parâmetro metrics aceita uma lista de métricas, permitindo a avaliação simultânea de várias métricas em uma única chamada de avaliação.
Preparação do conjunto de dados de avaliação
Os conjuntos de dados são transmitidos para uma instância do EvalTask como um DataFrame do pandas, em que cada linha representa um exemplo de avaliação separado (chamado de instância) e cada coluna representa um parâmetro de entrada de métrica. Veja métricas das entradas esperadas por cada métrica. Apresentamos vários exemplos de como criar o conjunto de dados para diferentes tarefas de avaliação.
Avaliação de resumo
Crie um conjunto de dados para resumo por pontos com as seguintes métricas:
summarization_qualitygroundednessfulfillmentsummarization_helpfulnesssummarization_verbosity
Considerando os parâmetros de entrada de métrica obrigatórios, você precisa incluir as seguintes colunas no nosso conjunto de dados de avaliação:
instructioncontextresponse
Neste exemplo, temos duas instâncias de resumo. Crie os campos instruction e context como entradas, que são exigidos pelas avaliações de tarefas de resumo:
instructions = [
# example 1
"Summarize the text in one sentence.",
# example 2
"Summarize the text such that a five-year-old can understand.",
]
contexts = [
# example 1
"""As part of a comprehensive initiative to tackle urban congestion and foster
sustainable urban living, a major city has revealed ambitious plans for an
extensive overhaul of its public transportation system. The project aims not
only to improve the efficiency and reliability of public transit but also to
reduce the city\'s carbon footprint and promote eco-friendly commuting options.
City officials anticipate that this strategic investment will enhance
accessibility for residents and visitors alike, ushering in a new era of
efficient, environmentally conscious urban transportation.""",
# example 2
"""A team of archaeologists has unearthed ancient artifacts shedding light on a
previously unknown civilization. The findings challenge existing historical
narratives and provide valuable insights into human history.""",
]
Se você tiver a resposta do LLM (o resumo) pronta e quiser fazer a avaliação do tipo "traga sua própria previsão" (BYOP, na sigla em inglês), construa a entrada da resposta da seguinte maneira:
responses = [
# example 1
"A major city is revamping its public transportation system to fight congestion, reduce emissions, and make getting around greener and easier.",
# example 2
"Some people who dig for old things found some very special tools and objects that tell us about people who lived a long, long time ago! What they found is like a new puzzle piece that helps us understand how people used to live.",
]
Com essas entradas, estamos prontos para criar nosso conjunto de dados de avaliação e EvalTask.
eval_dataset = pd.DataFrame(
{
"instruction": instructions,
"context": contexts,
"response": responses,
}
)
eval_task = EvalTask(
dataset=eval_dataset,
metrics=[
'summarization_quality',
'groundedness',
'fulfillment',
'summarization_helpfulness',
'summarization_verbosity'
],
experiment=EXPERIMENT_NAME
)
Avaliação geral da geração de texto
Algumas métricas baseadas em modelo, como coherence, fluency e safety, só precisam da resposta do modelo para avaliar a qualidade:
eval_dataset = pd.DataFrame({
"response": ["""The old lighthouse, perched precariously on the windswept cliff,
had borne witness to countless storms. Its once-bright beam, now dimmed by time
and the relentless sea spray, still flickered with stubborn defiance."""]
})
eval_task = EvalTask(
dataset=eval_dataset,
metrics=["coherence", "fluency", "safety"],
experiment=EXPERIMENT_NAME
)
Avaliação baseada em computação
As métricas baseadas em computação, como correspondência exata, bleu e rouge, comparam uma resposta a uma referência e, portanto, precisam dos campos de resposta e de referência no conjunto de dados de avaliação:
eval_dataset = pd.DataFrame({
"response": ["The Roman Senate was filled with exuberance due to Pompey's defeat in Asia."],
"reference": ["The Roman Senate was filled with exuberance due to successes against Catiline."],
})
eval_task = EvalTask(
dataset=eval_dataset,
metrics=["exact_match", "bleu", "rouge"],
experiment=EXPERIMENT_NAME
)
Avaliação do uso da ferramenta
Para a avaliação do uso da ferramenta, basta incluir a resposta e a referência no conjunto de dados de avaliação.
eval_dataset = pd.DataFrame({
"response": ["""{
"content": "",
"tool_calls":[{
"name":"get_movie_info",
"arguments": {"movie":"Mission Impossible", "time": "today 7:30PM"}
}]
}"""],
"reference": ["""{
"content": "",
"tool_calls":[{
"name":"book_tickets",
"arguments":{"movie":"Mission Impossible", "time": "today 7:30PM"}
}]
}"""],
})
eval_task = EvalTask(
dataset=eval_dataset,
metrics=["tool_call_valid", "tool_name_match", "tool_parameter_key_match",
"tool_parameter_kv_match"],
experiment=EXPERIMENT_NAME
)
Pacotes de métricas
Os pacotes de métricas combinam métricas geralmente associadas para simplificar o processo de avaliação. As métricas são categorizadas em quatro pacotes:
- Tarefas de avaliação: resumo, respostas a perguntas e geração de texto
- Perspectivas da avaliação: similaridade, segurança e qualidade
- Consistência de entrada: todas as métricas no mesmo pacote usam as mesmas entradas do conjunto de dados
- Paradigma de avaliação: por pontos versus em pares
É possível usar esses pacotes de métricas no serviço de avaliação on-line para otimizar o fluxo de trabalho de avaliação personalizado.
Esta tabela lista detalhes sobre os pacotes de métricas disponíveis:
| Nome do pacote de métricas | Nome da métrica | Coluna de conjunto de dados obrigatória |
|---|---|---|
text_generation_similarity |
exact_matchbleurouge |
resposta referência |
tool_call_quality |
tool_call_validtool_name_matchtool_parameter_key_matchtool_parameter_kv_match |
resposta referência |
text_generation_quality |
coherencefluency |
resposta |
text_generation_instruction_following |
fulfillment |
resposta referência |
text_generation_safety |
safety |
resposta |
text_generation_factuality |
groundedness |
response context |
summarization_pointwise_reference_free |
summarization_qualitysummarization_helpfulnesssummarization_verbosity |
response context instruction |
summary_pairwise_reference_free |
pairwise_summarization_quality |
response context instruction |
qa_pointwise_reference_free |
question_answering_qualityquestion_answering_relevancequestion_answering_helpfulness |
response context instruction |
qa_pointwise_reference_based |
question_answering_correctness |
response context instruction reference |
qa_pairwise_reference_free |
pairwise_question_answering_quality |
response context instruction |
Visualizar os resultados da avaliação
Depois de definir a tarefa de avaliação, execute-a para receber os resultados da avaliação conforme a seguir:
eval_result: EvalResult = eval_task.evaluate(
model=MODEL,
prompt_template=PROMPT_TEMPLATE
)
A classe EvalResult representa o resultado de uma execução de avaliação, que inclui métricas de resumo e uma tabela de métricas com uma instância de conjunto de dados de avaliação e métricas por instância correspondentes. Defina a classe desta maneira:
@dataclasses.dataclass
class EvalResult:
"""Evaluation result.
Attributes:
summary_metrics: the summary evaluation metrics for an evaluation run.
metrics_table: a table containing eval inputs, ground truth, and
metrics per row.
"""
summary_metrics: Dict[str, float]
metrics_table: Optional[pd.DataFrame] = None
Com o uso de funções auxiliares, os resultados da avaliação podem ser exibidos no bloco do Colab.

Visualizações
É possível representar as métricas de resumo em um gráfico de barras ou radar para visualização e comparação entre resultados de diferentes execuções de avaliação. Essa visualização pode ser útil para avaliar diferentes modelos e diferentes modelos de comandos.
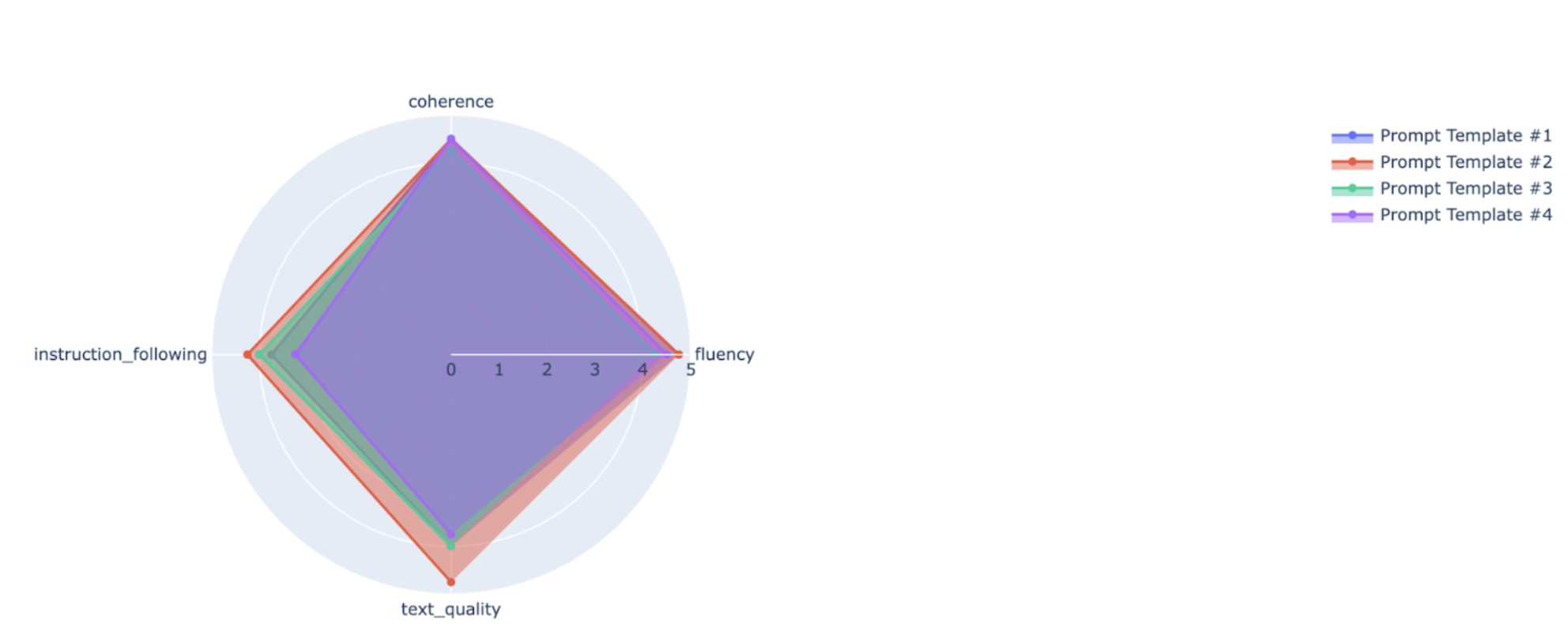
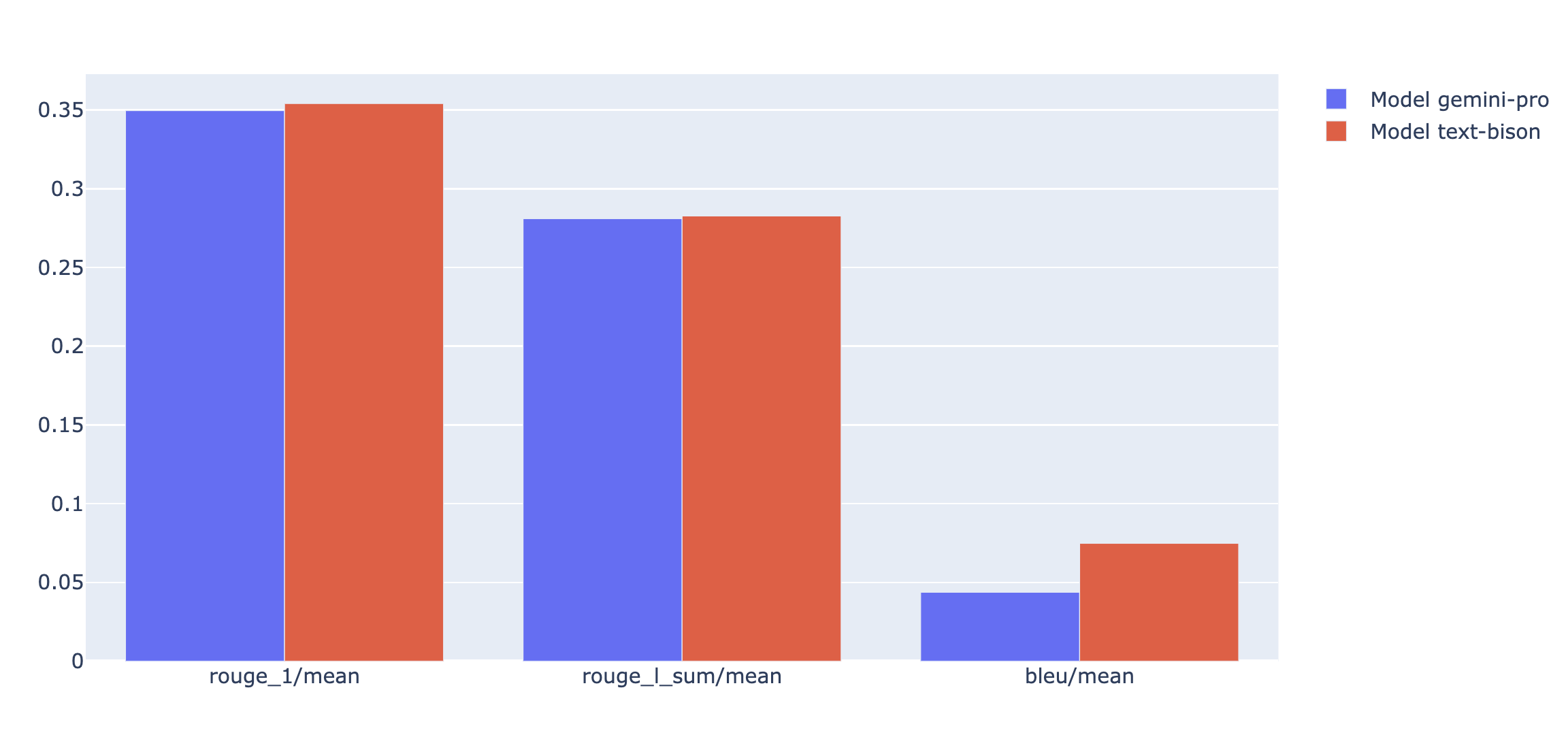
API de avaliação rápida
Para informações sobre a API de avaliação rápida, consulte este link.
Noções básicas sobre contas de serviço
As contas de serviço são usadas pelo serviço de avaliação on-line para receber previsões do serviço de previsão on-line sobre métricas de avaliação baseadas em modelo. Essa conta de serviço é provisionada automaticamente na primeira solicitação para o serviço de avaliação on-line.
| Nome | Descrição | Endereço de e-mail | Papel |
|---|---|---|---|
| Agente de serviço de avaliação rápida do Vertex AI | A conta de serviço usada para receber previsões para avaliação baseada em modelo. | service-PROJECT_NUMBER@gcp-sa-ENV-vertex-eval.iam.gserviceaccount.com |
roles/aiplatform.rapidevalServiceAgent |
As permissões associadas ao agente de serviço de avaliação rápida são:
| Papel | Permissões |
|---|---|
| Agente de serviço de avaliação rápida da Vertex AI (roles/aiplatform.rapidevalServiceAgent) | aiplatform.endpoints.predict |
A seguir
- Teste um notebook de exemplo de avaliação.
- Saiba mais sobre avaliação de IA generativa.
- Saiba mais sobre a avaliação em pares baseada em modelo com o pipeline AutoSxS.
- Saiba mais sobre o pipeline de avaliação baseado em computação.
- Saiba como ajustar um modelo de fundação.