GenAI Evaluation Service 提供企业级工具,可对生成式 AI 模型进行客观、数据驱动的评估。它支持并指导多项开发任务,例如模型迁移、提示编辑和微调。
Gen AI Evaluation Service 功能
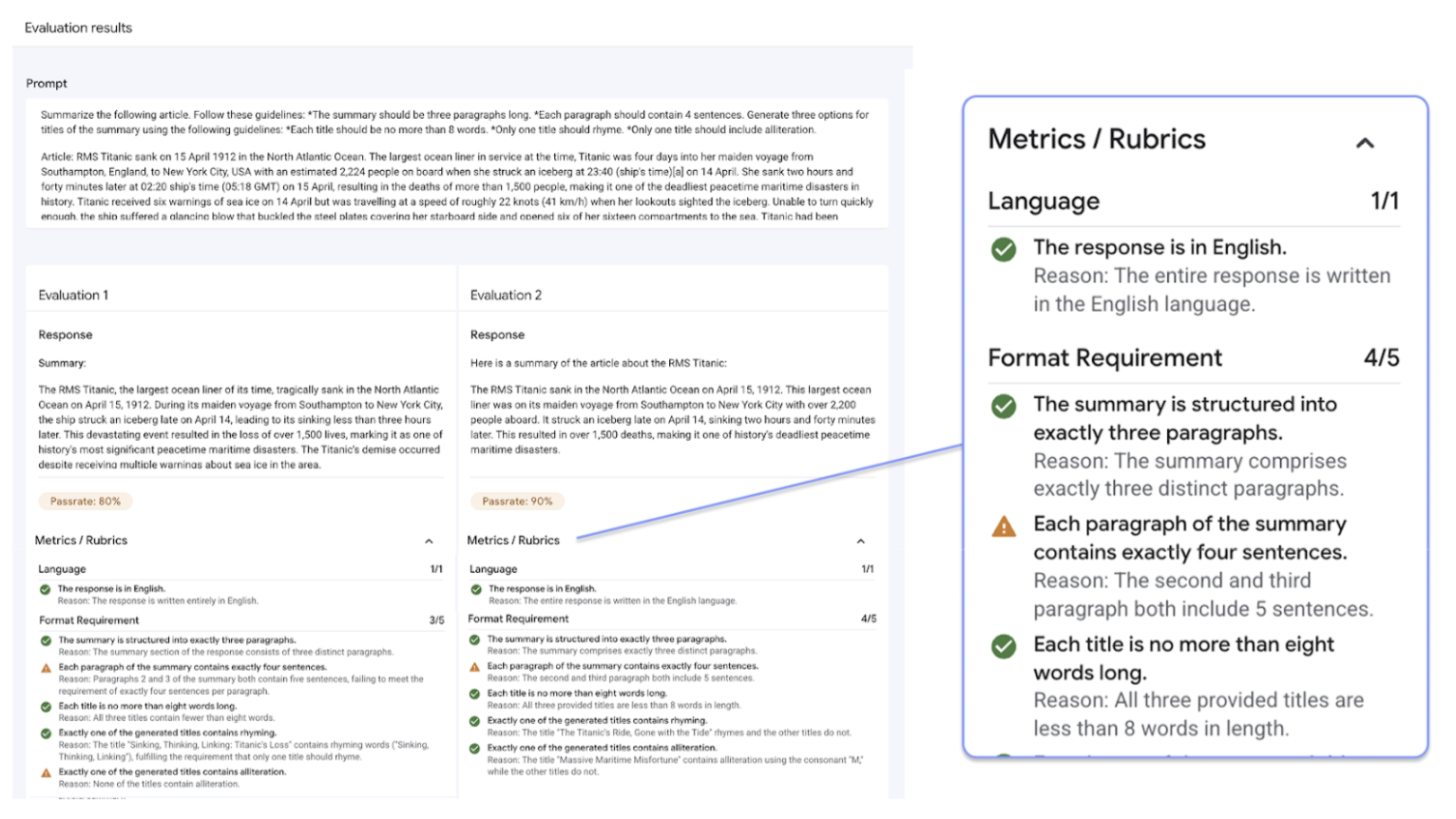
Gen AI Evaluation Service 的一个显著特点是能够使用自适应评分标准,这是一组针对每个单独提示量身定制的通过或失败测试。评估标准类似于软件开发中的单元测试,旨在提高模型在各种任务中的性能。
Gen AI Evaluation Service 支持以下常见评估方法:
自适应评分标准(推荐):为数据集中的每个单独提示生成一组独特的通过或未通过评分标准。
静态评分标准:将一组固定的评分标准应用于所有提示。
基于计算的指标:如果存在标准答案,请使用
ROUGE或BLEU等确定性算法。自定义函数:使用 Python 定义自己的评估逻辑,以满足特殊要求。
生成评估数据集
您可以通过以下方法创建评估数据集:
上传包含完整提示实例的文件,或提供提示模板以及相应的变量值文件,以填充完整的提示。
直接从生产日志中抽样,以评估模型的实际使用情况。
使用合成数据生成功能,为任何提示模板生成大量一致的示例。
支持的接口
您可以使用以下界面定义和运行评估:
Google Cloud 控制台:一种网页界面,可提供引导式端到端工作流程。管理数据集、运行评估,并深入了解互动式报告和可视化图表。请参阅使用控制台执行评估。
Python SDK:以编程方式运行评估,并在 Colab 或 Jupyter 环境中直接呈现并排模型比较结果。请参阅使用 Vertex AI SDK 中的 GenAI 客户端执行评估
使用场景
借助 Gen AI Evaluation Service,您可以了解模型在特定任务中以及根据您的独特标准表现如何,从而获得无法从公开排行榜和一般基准中获得的宝贵数据洞见。这有助于完成关键的开发任务,包括:
模型迁移:比较模型版本,了解行为差异,并相应地调整提示和设置。
寻找最佳模型:对 Google 模型和第三方模型在您的数据上进行直接比较,以建立性能基准并确定最适合您的应用场景的模型。
提示改进:利用评估结果指导您的自定义工作。重新运行评估可形成紧密的反馈环,从而针对您的更改提供即时、可量化的反馈。
模型微调:通过对每次运行应用一致的评估标准来评估微调模型的质量。
采用自适应评分标准的评估
自适应评分标准是大多数评估用例的推荐方法,也是开始评估的最快方式。
与大多数 LLM-as-a-judge 系统使用的一般评分标准不同,测试驱动的评估框架会针对数据集中的每个提示自适应地生成一组独特的通过或失败评分标准。这种方法可确保每次评估都与所评估的特定任务相关。
每个提示的评估流程都使用两步系统:
评分标准生成:该服务首先会分析您的提示,然后生成一份具体且可验证的测试列表(即评分标准),以确定优质回答应满足哪些条件。
评分标准验证:模型生成回答后,该服务会根据每个评分标准评估回答,并提供清晰的
Pass或Fail判定结果和理由。

最终结果是汇总的通过率,以及模型通过的各项评分标准的详细细分,可为您提供可据以采取行动的分析洞见,以便诊断问题和衡量改进情况。
通过从宏观的主观得分转向精细的客观测试结果,您可以采用评估驱动的开发周期,并将软件工程最佳实践应用于构建生成式 AI 应用的流程。
评分准则评估示例
如需了解 Gen AI Evaluation Service 如何生成和使用评分标准,请参考以下示例:
用户提示:Write a four-sentence summary of the provided article about renewable energy, maintaining an optimistic tone.
对于此提示,生成评分标准这一步可能会生成以下评分标准:
评分准则 1:回答是对所提供文章的总结。
评分标准 2:回答包含正好四个句子。
评分准则 3:回答保持乐观的语气。
模型可能会生成以下回答:The article highlights significant growth in solar and wind power. These advancements are making clean energy more affordable. The future looks bright for renewables. However, the report also notes challenges with grid infrastructure.
在评分标准验证期间,Gen AI Evaluation Service 会根据每个评分标准评估回答:
评分准则 1:回答是对所提供文章的总结。
判定结果:
Pass原因:回答准确总结了要点。
评分标准 2:回答包含正好四个句子。
判定结果:
Pass理由:回答由四个不同的句子组成
评分准则 3:回答保持乐观的语气。
判定结果:
Fail原因:最后一句话引入了负面观点,削弱了乐观的语气。
此回答的最终通过率为 66.7%。如需比较两个模型,您可以针对同一组生成的测试评估它们的回答,并比较它们的总体通过率。
评估工作流
完成评估通常需要执行以下步骤:
创建评估数据集:汇集一个包含提示实例的数据集,以反映您的特定使用场景。如果您打算使用基于计算的指标,可以添加参考答案(标准答案)。
定义评估指标:选择要用于衡量模型性能的指标。SDK 支持所有指标类型,而控制台支持自适应评分标准。
生成模型回答:选择一个或多个模型,为数据集生成回答。SDK 支持可通过
LiteLLM调用的任何模型,而控制台支持 Google Gemini 模型。运行评估:执行评估作业,根据您选择的指标评估每个模型的回答。
解读结果:查看汇总得分和各个回答,以分析模型性能。
评估入门
您可以使用控制台开始评估。
或者,以下代码展示了如何使用 Vertex AI SDK 中的 GenAI 客户端完成评估:
from vertexai import Client
from vertexai import types
import pandas as pd
client = Client(project=PROJECT_ID, location=LOCATION)
# Create an evaluation dataset
prompts_df = pd.DataFrame({
"prompt": [
"Write a simple story about a dinosaur",
"Generate a poem about Vertex AI",
],
})
# Get responses from one or multiple models
eval_dataset = client.evals.run_inference(model="gemini-2.5-flash", src=prompts_df)
# Define the evaluation metrics and run the evaluation job
eval_result = client.evals.evaluate(
dataset=eval_dataset,
metrics=[types.RubricMetric.GENERAL_QUALITY]
)
# View the evaluation results
eval_result.show()
Gen AI Evaluation Service 提供两种 SDK 接口:
Vertex AI SDK 中的 GenAI 客户端(推荐)(预览版)
from vertexai import clientGenAI 客户端是用于评估的更新、推荐的接口,可通过统一的客户端类进行访问。它支持所有评估方法,专为包含模型比较、笔记本内可视化和模型自定义洞见的工作流程而设计。
Vertex AI SDK 中的评估模块(正式版)
from vertexai.evaluation import EvalTask评估模块是旧版接口,为了与现有工作流保持向后兼容性而进行维护,但不再处于积极开发阶段。可通过
EvalTask类访问。此方法支持标准 LLM-as-a-judge 和基于计算的指标,但不支持自适应评分标准等较新的评估方法。
支持的区域
Gen AI Evaluation Service 支持以下区域:
爱荷华 (
us-central1)北弗吉尼亚 (
us-east4)俄勒冈 (
us-west1)内华达州,拉斯维加斯 (
us-west4)比利时 (
europe-west1)荷兰 (
europe-west4)法国巴黎 (
europe-west9)