MedLM es una familia de modelos de base que se ajustan para el sector de la atención médica. Med-PaLM 2 es uno de los modelos basados en texto que desarrolló Google Research y que impulsa MedLM, y fue el primer sistema de IA en llegar a los niveles de expertos humanos para responder a preguntas del estilo del examen de licencias médicas (USMLE) de EE.UU. El desarrollo de estos modelos se pensó en base a las necesidades específicas de los clientes, como tener que responder preguntas médicas y redactar resúmenes.
Tarjeta del modelo de MedLM
La tarjeta del modelo MedLM describe los detalles del modelo, como el uso previsto para MedLM, el resumen de datos y la información de seguridad. Haz clic en el siguiente vínculo para descargar una versión de la tarjeta del modelo de MedLM en formato PDF:
Descarga la tarjeta del modelo de MedLM
Casos de uso
- Búsqueda de respuestas: Proporciona respuestas de borrador a preguntas relacionadas con la medicina en formato de texto.
- Resumen: Haz un borrador de una versión más corta de un documento (como un resumen para luego de la visita o historia, o una nota de la examinación física) que incorpore información pertinente del texto original.
Para obtener más información sobre cómo diseñar instrucciones de texto, consulta Descripción general de las estrategias de instrucciones.
Solicitud HTTP
MedLM-medium (medlm-medium):
POST https://us-central1-aiplatform.googleapis.com/v1/projects/{PROJECT_ID}/locations/us-central1/publishers/google/models/medlm-medium:predict
MedLM-large (medlm-large):
POST https://us-central1-aiplatform.googleapis.com/v1/projects/{PROJECT_ID}/locations/us-central1/publishers/google/models/medlm-large:predict
Consulta el método predict para obtener más información.
Versiones del modelo
MedLM proporciona los siguientes modelos:
- MedLM-medium (
medlm-medium) - MedLM-large (
medlm-large)
La siguiente tabla contiene las versiones disponibles del modelo estable:
| medlm-medium model | Fecha de lanzamiento |
|---|---|
medlm-medium |
13 de diciembre de 2023 |
| medlm-large model | Fecha de lanzamiento |
|---|---|
medlm-large |
13 de diciembre de 2023 |
MedLM-medium y MedLM-large tienen extremos independientes y proporcionan a los clientes flexibilidad adicional para sus casos de uso. MedLM-medium proporciona a los clientes una mejor capacidad de procesamiento y, además, incluye datos más recientes. MedLM-large es el mismo modelo de la fase de versión preliminar. Ambos modelos seguirán actualizándose durante el ciclo de vida del producto. En esta página, "MedLM" hace referencia a ambos modelos.
Para obtener más información, consulta Versiones de modelo y ciclo de vida
Atributos y filtros de seguridad de MedLM
El contenido procesado a través de la API de MedLM se evalúa en función de una lista de atributos de seguridad, incluidas las “categorías perjudiciales” y los temas que pueden considerarse sensibles. Si ves una respuesta de resguardo, como “No puedo ayudarte con eso, ya que solo soy un modelo de lenguaje”, significa que la solicitud o la respuesta activan un filtro de seguridad.
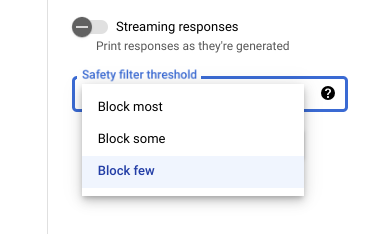
Umbrales de seguridad
Con Vertex AI Studio puedes usar un umbral de filtro de seguridad ajustable para determinar la probabilidad de ver respuestas que podrían ser perjudiciales. Las respuestas del modelo se bloquean según la probabilidad de que incluya acoso, incitación al odio o a la violencia, contenido peligroso o contenido sexual explícito. La configuración del filtro de seguridad se encuentra en la parte derecha del campo de instrucción en Vertex AI Studio. Puedes elegir entre tres opciones: block most, block some y block few.
Prueba tus umbrales de confianza y gravedad
Puedes probar los filtros de seguridad de Google y definir los umbrales de confianza adecuados para tu empresa. El uso de estos umbrales permite adoptar medidas exhaustivas para detectar contenidos que infrinjan las políticas de uso o las condiciones del servicio de Google y tomar las medidas adecuadas.
Las puntuaciones de confianza son solo predicciones y no debes depender de las puntuaciones para confiabilidad o precisión. Google no es responsable de interpretar ni usar estas puntuaciones para las decisiones empresariales.
Prácticas recomendadas
Para usar esta tecnología de forma segura y responsable, también es importante considerar otros riesgos específicos de tu caso de uso, los usuarios y el contexto empresarial, además de las protecciones técnicas integradas.
Te recomendamos que sigas estos pasos:
- Evalúa los riesgos de seguridad de tu aplicación.
- Considera realizar ajustes para mitigar los riesgos de seguridad.
- Realiza pruebas de seguridad adecuadas según tu caso de uso.
- Solicita comentarios de los usuarios y supervisa el contenido.
Para obtener más información, consulta las recomendaciones de Google sobre la IA responsable.
Cuerpo de la solicitud
{
"instances": [
{
"content": string
}
],
"parameters": {
"temperature": number,
"maxOutputTokens": integer,
"topK": integer,
"topP": number
}
}
Usa los siguientes parámetros para los modelos medlm-medium y medlm-large.
Para obtener más información, consulta Diseña indicaciones de texto.
| Parámetro | Descripción | Valores aceptables |
|---|---|---|
|
Entrada de texto para generar una respuesta del modelo. Las instrucciones pueden incluir predicado, preguntas, sugerencias, instrucciones o ejemplos. | Texto |
|
La temperatura se usa para las muestras durante la generación de respuesta, que se genera cuando se aplican topP y topK. La temperatura controla el grado de aleatorización en la selección de tokens.
Las temperaturas más bajas son buenas para los mensajes que requieren una respuesta menos abierta o de creativa, mientras que
las temperaturas más altas pueden generar resultados más diversos o creativos. Una temperatura de 0
significa que siempre se seleccionan los tokens de probabilidad más alta. En este caso, las respuestas para un mensaje determinado
son, en su mayoría, deterministas, pero es posible que haya una pequeña cantidad de variación.
Si el modelo muestra una respuesta demasiado genérica, demasiado corta o el modelo proporciona una respuesta de resguardo, intenta aumentar la temperatura. |
|
|
Cantidad máxima de tokens que se pueden generar en la respuesta. Un token tiene casi cuatro caracteres. 100 tokens corresponden a casi 60 u 80 palabras.
Especifica un valor más bajo para las respuestas más cortas y un valor más alto para las respuestas potencialmente más largas. |
|
|
El parámetro Top-K cambia la manera en la que el modelo selecciona los tokens para el resultado. K superior a 1 significa que el siguiente token seleccionado es el más probable entre todos los tokens en el vocabulario del modelo (también llamado decodificación voraz), mientras que el K superior a 3 significa que el siguiente token se selecciona de los tres tokens más probables mediante la temperatura.
Para cada paso de selección de tokens, se muestran los tokens de K superior con las probabilidades más altas. Luego, los tokens se filtran según el superior con el token final seleccionado mediante el muestreo de temperatura. Especifica un valor más bajo para respuestas menos aleatorias y un valor más alto para respuestas más aleatorias. |
|
|
Top-P cambia la manera en la que el modelo selecciona los tokens para el resultado. Los tokens se seleccionan del más probable al menos probable hasta que la suma de sus probabilidades sea igual al valor de Top-P. Por ejemplo, si los tokens A, B y C tienen una probabilidad de 0.3, 0.2 y 0.1, y el valor P superior es 0.5, el modelo elegirá A o B como el siguiente token mediante la temperatura y excluirá a C como candidato.
Especifica un valor más bajo para respuestas menos aleatorias y un valor más alto para respuestas más aleatorias. |
|
Solicitud de muestra
Cuando usas la API de MedLM, es importante incorporar la ingeniería de instrucciones. Por ejemplo, te recomendamos que proporciones instrucciones adecuadas y específicas para cada tarea al comienzo de cada instrucción. Para obtener más información, consulta Introducción a las instrucciones.
REST
Antes de usar cualquiera de los datos de solicitud a continuación, realiza los siguientes reemplazos:
PROJECT_ID: El ID del proyecto.MEDLM_MODEL: el modelo de MedLM, ya seamedlm-mediumomedlm-large.
HTTP method and URL:
POST https://us-central1-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/publishers/google/models/MEDLM_MODEL:predict
Cuerpo JSON de la solicitud:
{
"instances": [
{
"content": "Question: What causes you to get ringworm?"
}
],
"parameters": {
"temperature": 0,
"maxOutputTokens": 256,
"topK": 40,
"topP": 0.95
}
}
Para enviar tu solicitud, elige una de estas opciones:
curl
Guarda el cuerpo de la solicitud en un archivo llamado request.json.
Ejecuta el comando siguiente en la terminal para crear o reemplazar este archivo en el directorio actual:
cat > request.json << 'EOF'
{
"instances": [
{
"content": "Question: What causes you to get ringworm?"
}
],
"parameters": {
"temperature": 0,
"maxOutputTokens": 256,
"topK": 40,
"topP": 0.95
}
}
EOFLuego, ejecuta el siguiente comando para enviar tu solicitud de REST:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://us-central1-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/publishers/google/models/MEDLM_MODEL:predict"
PowerShell
Guarda el cuerpo de la solicitud en un archivo llamado request.json.
Ejecuta el comando siguiente en la terminal para crear o reemplazar este archivo en el directorio actual:
@'
{
"instances": [
{
"content": "Question: What causes you to get ringworm?"
}
],
"parameters": {
"temperature": 0,
"maxOutputTokens": 256,
"topK": 40,
"topP": 0.95
}
}
'@ | Out-File -FilePath request.json -Encoding utf8Luego, ejecuta el siguiente comando para enviar tu solicitud de REST:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://us-central1-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/publishers/google/models/MEDLM_MODEL:predict" | Select-Object -Expand Content
Cuerpo de la respuesta
{
"predictions": [
{
"content": string,
"citationMetadata": {
"citations": [
{
"startIndex": integer,
"endIndex": integer,
"url": string,
"title": string,
"license": string,
"publicationDate": string
}
]
},
"logprobs": {
"tokenLogProbs": [ float ],
"tokens": [ string ],
"topLogProbs": [ { map<string, float> } ]
},
"safetyAttributes": {
"categories": [ string ],
"blocked": boolean,
"scores": [ float ],
"errors": [ int ]
}
}
],
"metadata": {
"tokenMetadata": {
"input_token_count": {
"total_tokens": integer,
"total_billable_characters": integer
},
"output_token_count": {
"total_tokens": integer,
"total_billable_characters": integer
}
}
}
}
| Elemento de la respuesta | Descripción |
|---|---|
content |
El resultado generado a partir del texto de entrada. |
categories |
Los nombres visibles de las categorías de atributos de seguridad asociados con el contenido generado. El orden coincide con las puntuaciones. |
scores |
Las puntuaciones de confianza de cada categoría, un valor más alto significa más confianza. |
blocked |
Una marca que indica si la entrada o salida del modelo se bloqueó. |
errors |
Un código de error que identifica por qué se bloqueó la entrada o la salida. Para obtener una lista de códigos de error, consulta Filtros y atributos de seguridad. |
startIndex |
Índice en el resultado de la predicción en el que comienza la cita (inclusive). Debe ser mayor o igual que 0 y menor que end_index. |
endIndex |
Índice en el resultado de la predicción en el que finaliza la cita (exclusivo). Debe ser mayor que start_index y menor que len(output). |
url |
URL asociada con esta cita. Si está presente, esta URL vincula a la página web de la fuente de esta cita. Las URLs posibles incluyen sitios web de noticias, repositorios de GitHub, etcétera. |
title |
Título asociado a esta cita. Si está presente, hace referencia al título de la fuente de esta cita. Los títulos posibles incluyen títulos de noticias, de libros, etc. |
license |
Licencia asociada con esta repetición. Si está presente, hace referencia a la licencia de la fuente de esta cita. Las licencias posibles incluyen licencias de código, como la licencia MIT. |
publicationDate |
Es la fecha de publicación asociada con esta cita. Si está presente, hace referencia a la fecha en la que se publicó la fuente de esta cita. Los formatos posibles son AAAA, AAAA-MM y AAAA-MM-DD. |
input_token_count |
Cantidad de tokens de entrada. Esta es la cantidad total de tokens en todos los mensajes, prefijos y sufijos. |
output_token_count |
Cantidad de tokens de salida. Esta es la cantidad total de tokens en content en todas las predicciones. |
tokens |
Los tokens de muestra. |
tokenLogProbs |
Las probabilidades de registro de los tokens de muestra. |
topLogProb |
Los tokens de candidatos más probables y sus probabilidades de registro en cada paso. |
logprobs |
Resultados del parámetro “logprobs”. Asignación de 1 a 1 a “candidatos”. |
Respuesta de muestra
{
"predictions": [
{
"citationMetadata": {
"citations": []
},
"content": "\n\nAnswer and Explanation:\nRingworm is a fungal infection of the skin that is caused by a type of fungus called dermatophyte. Dermatophytes can live on the skin, hair, and nails, and they can be spread from person to person through direct contact or through contact with contaminated objects.\n\nRingworm can cause a variety of symptoms, including:\n\n* A red, itchy rash\n* A raised, circular border\n* Blisters or scales\n* Hair loss\n\nRingworm is most commonly treated with antifungal medications, which can be applied to the skin or taken by mouth. In some cases, surgery may be necessary to remove infected hair or nails.",
"safetyAttributes": {
"scores": [
1
],
"blocked": false,
"categories": [
"Health"
]
}
}
],
"metadata": {
"tokenMetadata": {
"outputTokenCount": {
"totalTokens": 140,
"totalBillableCharacters": 508
},
"inputTokenCount": {
"totalTokens": 10,
"totalBillableCharacters": 36
}
}
}
}