MedLM è una famiglia di modelli di base ottimizzati per il settore sanitario. Med-PaLM 2 è uno dei modelli basati sul testo sviluppati da Google Research che alimenta MedLM ed è stato il primo sistema di IA a raggiungere il livello di esperto umano nella risposta alle domande in stile USMLE (United States Medical Licensure Examination). Lo sviluppo di questi modelli è stato informato da esigenze specifiche dei clienti ad esempio per rispondere a domande mediche e scrivere riassunti.
Scheda del modello MedLM
La scheda del modello MedLM illustra i dettagli del modello, ad esempio lo scopo previsto di MedLM, la panoramica dei dati e le informazioni sulla sicurezza. Fai clic sul seguente link per scaricare una versione PDF della scheda del modello MedLM:
Scarica la scheda del modello MedLM
Casi d'uso
- Risposta alle domande: fornisci bozze di risposte a domande di natura medica, fornite sotto forma di testo.
- Riassunto: crea una bozza di una versione più breve di un documento (ad esempio un Riepilogo della visita o una nota relativa alla storia clinica e all'esame fisico) che includa le informazioni pertinenti del testo originale.
Per saperne di più sulla progettazione di prompt di testo, consulta l'articolo Progettare prompt di testo.
Richiesta HTTP
MedLM-medium (medlm-medium):
POST https://us-central1-aiplatform.googleapis.com/v1/projects/{PROJECT_ID}/locations/us-central1/publishers/google/models/medlm-medium:predict
MedLM-large (medlm-large):
POST https://us-central1-aiplatform.googleapis.com/v1/projects/{PROJECT_ID}/locations/us-central1/publishers/google/models/medlm-large:predict
Per ulteriori informazioni, consulta il metodo predict.
Versioni modello
MedLM fornisce i seguenti modelli:
- MedLM-medio (
medlm-medium) - MedLM di grandi dimensioni (
medlm-large)
La tabella seguente contiene le versioni stabili del modello disponibili:
| modello medlm-medium | Data di uscita |
|---|---|
| medlm-medio | 13 dicembre 2023 |
| Modello medlm-large | Data di uscita |
|---|---|
| medlm-grandi | 13 dicembre 2023 |
MedLM-medium e MedLM-large hanno endpoint distinti e offrono ai clienti una maggiore flessibilità per i loro casi d'uso. MedLM-medium offre ai clienti velocità effettiva e include i dati più recenti. MedLM-large è lo stesso modello della fase di anteprima. Entrambi i modelli continueranno a essere aggiornati durante il ciclo di vita del prodotto. In questa pagina, "MedLM" si riferisce a entrambi i modelli.
Per saperne di più, consulta Versioni dei modelli e ciclo di vita.
Filtri e attributi di sicurezza MedLM
I contenuti elaborati tramite l'API MedLM vengono valutati in base a un elenco di attributi di sicurezza, tra cui "categorie dannose" e argomenti che possono essere considerati sensibili. Se visualizzi una risposta di riserva, ad esempio "Non posso aiutarti perché sono solo un modello linguistico", significa che il prompt o la risposta sta attivando un filtro di sicurezza.
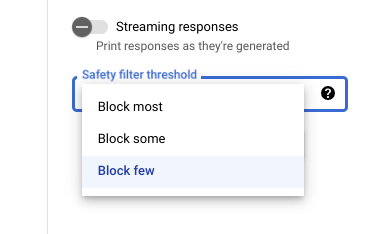
Soglie di sicurezza
Quando utilizzi Vertex AI Studio, puoi usare
una soglia di filtro di sicurezza regolabile per determinare la probabilità di visualizzare risposte potenzialmente dannose. Le risposte del modello vengono bloccate in base alla probabilità che includano molestie, incitamento all'odio, contenuti pericolosi o sessualmente espliciti. L'impostazione del filtro di sicurezza si trova a destra
del prompt in Vertex AI Studio. Puoi scegliere tra
tre opzioni: block most, block some e
block few.
Testare le soglie di confidenza e gravità
Puoi testare i filtri di sicurezza di Google e definire le soglie di affidabilità adatte alla tua attività. Utilizzando queste soglie, puoi adottare misure complete per rilevare i contenuti che violano le norme di utilizzo o i Termini di servizio di Google e adottare le misure del caso.
I punteggi di confidenza sono solo previsioni e non devono dipendere i punteggi di affidabilità o accuratezza. Google non è responsabile a interpretare o utilizzare questi punteggi per le decisioni aziendali.
Pratiche consigliate
Per utilizzare questa tecnologia in modo sicuro e responsabile, è importante considerare altri rischi specifici per il caso d'uso, gli utenti e il contesto aziendale in con salvaguardie tecniche integrate.
Ti consigliamo di procedere nel seguente modo:
- Valuta i rischi per la sicurezza della tua applicazione.
- Valuta la possibilità di apportare modifiche per mitigare i rischi per la sicurezza.
- Esegui test di sicurezza appropriati al tuo caso d'uso.
- Sollecitare il feedback degli utenti e monitorare i contenuti.
Per saperne di più, consulta i consigli di Google per l'IA responsabile.
Corpo della richiesta
{
"instances": [
{
"content": string
}
],
"parameters": {
"temperature": number,
"maxOutputTokens": integer,
"topK": integer,
"topP": number
}
}
Utilizza i seguenti parametri per i modelli medlm-medium e medlm-large.
Per ulteriori informazioni, consulta la sezione Creare prompt di testo.
| Parametro | Descrizione | Valori accettati |
|---|---|---|
|
Input di testo per generare la risposta del modello. I prompt possono includere un preambolo, domande, suggerimenti, istruzioni o esempi. | Testo |
|
La temperatura viene utilizzata per il campionamento durante la generazione della risposta, che si verifica quando topP
e topK. La temperatura controlla il grado di casualità nella selezione dei token.
Le temperature basse sono ideali per prompt che richiedono risposte meno aperte o creative, mentre le temperature più alte possono portare a risultati più diversificati o creativi. Una temperatura di 0
significa che vengono sempre selezionati i token con la probabilità più alta. In questo caso, le risposte per un determinato
sono per lo più deterministici, ma è ancora possibile una piccola variazione.
Se il modello restituisce una risposta troppo generica, troppo breve o fornisce una risposta di riserva, prova ad aumentare la temperatura. |
|
|
Numero massimo di token che possono essere generati nella risposta. Un token è
di circa quattro caratteri. 100 token corrispondono a circa 60-80 parole.
Specifica un valore più basso per risposte più brevi e un valore più alto per risposte potenzialmente più lunghe diverse. |
|
|
Top-K cambia il modo in cui il modello seleziona i token per l'output. Un top-K pari a
1 indica che il token successivo selezionato è il più probabile tra tutti
i token nel vocabolario del modello (chiamato anche decodifica greedy). Un top-K pari a
3 indica invece che il token successivo viene selezionato tra i tre
token più probabili utilizzando la temperatura.
Per ogni passaggio di selezione dei token, vengono mostrati i token top-K con il vengono campionate. Quindi i token vengono ulteriormente filtrati in base a Top-P e il token finale viene selezionato utilizzando il campionamento con temperatura. Specifica un valore più basso per risposte meno casuali e un valore più alto per risposte più casuali. |
|
|
Top-P cambia il modo in cui il modello seleziona i token per l'output. Token selezionati
dal più probabile (vedi top-K) al meno probabile fino alla somma delle probabilità
equivale al valore di top-p. Ad esempio, se i token A, B e C hanno una probabilità di
0,3, 0,2 e 0,1 e il valore di top-P è 0.5, il modello
seleziona A o B come token successivo utilizzando la temperatura ed esclude C come
candidato.
Specifica un valore più basso per risposte meno casuali e un valore più alto per risposte più casuali. |
|
Richiesta di esempio
Quando utilizzi l'API MedLM, è importante incorporare la progettazione dei prompt. Ad esempio, ti consigliamo vivamente di fornire istruzioni appropriate e specifiche per ogni compito all'inizio di ogni prompt. Per ulteriori informazioni, consulta Introduzione alla progettazione dei prompt.
REST
Prima di utilizzare i dati della richiesta, effettua le seguenti sostituzioni:
PROJECT_ID: il tuo ID progetto.MEDLM_MODEL: modello MedLM,medlm-mediumomedlm-large.
Metodo HTTP e URL:
POST https://us-central1-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/publishers/google/models/MEDLM_MODEL:predict
Corpo JSON della richiesta:
{
"instances": [
{
"content": "Question: What causes you to get ringworm?"
}
],
"parameters": {
"temperature": 0,
"maxOutputTokens": 256,
"topK": 40,
"topP": 0.95
}
}
Per inviare la richiesta, scegli una delle seguenti opzioni:
curl
Salva il corpo della richiesta in un file denominato request.json.
Esegui questo comando nel terminale per creare o sovrascrivere
questo file nella directory corrente:
cat > request.json << 'EOF'
{
"instances": [
{
"content": "Question: What causes you to get ringworm?"
}
],
"parameters": {
"temperature": 0,
"maxOutputTokens": 256,
"topK": 40,
"topP": 0.95
}
}
EOFQuindi, esegui questo comando per inviare la richiesta REST:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://us-central1-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/publishers/google/models/MEDLM_MODEL:predict"
PowerShell
Salva il corpo della richiesta in un file denominato request.json.
Esegui questo comando nel terminale per creare o sovrascrivere
questo file nella directory corrente:
@'
{
"instances": [
{
"content": "Question: What causes you to get ringworm?"
}
],
"parameters": {
"temperature": 0,
"maxOutputTokens": 256,
"topK": 40,
"topP": 0.95
}
}
'@ | Out-File -FilePath request.json -Encoding utf8Quindi, esegui il seguente comando per inviare la richiesta REST:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://us-central1-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/publishers/google/models/MEDLM_MODEL:predict" | Select-Object -Expand Content
Corpo della risposta
{
"predictions": [
{
"content": string,
"citationMetadata": {
"citations": [
{
"startIndex": integer,
"endIndex": integer,
"url": string,
"title": string,
"license": string,
"publicationDate": string
}
]
},
"logprobs": {
"tokenLogProbs": [ float ],
"tokens": [ string ],
"topLogProbs": [ { map<string, float> } ]
},
"safetyAttributes": {
"categories": [ string ],
"blocked": boolean,
"scores": [ float ],
"errors": [ int ]
}
}
],
"metadata": {
"tokenMetadata": {
"input_token_count": {
"total_tokens": integer,
"total_billable_characters": integer
},
"output_token_count": {
"total_tokens": integer,
"total_billable_characters": integer
}
}
}
}
| Elemento risposta | Descrizione |
|---|---|
content |
Il risultato generato dal testo inserito. |
categories |
I nomi visualizzati delle categorie di attributi di sicurezza associati ai contenuti generati. L'ordine corrisponde ai punteggi. |
scores |
I punteggi di confidenza di ogni categoria. Un valore più alto corrisponde a una confidenza maggiore. |
blocked |
Un flag che indica se l'input o l'output del modello è stato bloccato. |
errors |
Un codice di errore che identifica il motivo per cui l'input o l'output è stato bloccato. Per un elenco dei codici di errore, consulta Filtri e attributi di sicurezza. |
startIndex |
Indice nell'output della previsione dove inizia la citazione (inclusa). Deve essere maggiore o uguale a 0 e minore di end_index. |
endIndex |
Indice nell'output della previsione dove termina la citazione (esclusa). Deve essere maggiore di start_index e minore di len(output). |
url |
URL associato a questa citazione. Se presente, l'URL rimanda alla pagina web della fonte della citazione. Possibili URL includono siti web di notizie, repository GitHub e così via. |
title |
Titolo associato a questa citazione. Se presente, si riferisce al titolo della fonte di questa citazione. I titoli possibili includono titoli di notizie, titoli di libri e così via. |
license |
Licenza associata a questo suggerimento. Se presente, si riferisce alla licenza della fonte di questa citazione. Le possibili licenze includono licenze di codici come le licenze MIT. |
publicationDate |
Data di pubblicazione associata a questa citazione. Se presente, si riferisce alla data di pubblicazione della fonte di questa citazione. I formati possibili sono AAAA, AAAA-MM, AAAA-MM-GG. |
input_token_count |
Numero di token di input. Si tratta del numero totale di token in tutti i prompt, prefissi e suffissi. |
output_token_count |
Numero di token di output. Questo è il numero totale di token in content per tutte le previsioni. |
tokens |
I token campionati. |
tokenLogProbs |
I token campionati registrare le probabilità. |
topLogProb |
I token candidati più probabili e le relative probabilità di log in ogni passaggio. |
logprobs |
Risultati del parametro "logprobs". Mappatura 1:1 sui "candidati". |
Risposta di esempio
{
"predictions": [
{
"citationMetadata": {
"citations": []
},
"content": "\n\nAnswer and Explanation:\nRingworm is a fungal infection of the skin that is caused by a type of fungus called dermatophyte. Dermatophytes can live on the skin, hair, and nails, and they can be spread from person to person through direct contact or through contact with contaminated objects.\n\nRingworm can cause a variety of symptoms, including:\n\n* A red, itchy rash\n* A raised, circular border\n* Blisters or scales\n* Hair loss\n\nRingworm is most commonly treated with antifungal medications, which can be applied to the skin or taken by mouth. In some cases, surgery may be necessary to remove infected hair or nails.",
"safetyAttributes": {
"scores": [
1
],
"blocked": false,
"categories": [
"Health"
]
}
}
],
"metadata": {
"tokenMetadata": {
"outputTokenCount": {
"totalTokens": 140,
"totalBillableCharacters": 508
},
"inputTokenCount": {
"totalTokens": 10,
"totalBillableCharacters": 36
}
}
}
}
Streaming della risposta dai modelli di IA generativa
I parametri sono gli stessi per le richieste di flusso e non di streaming a le API.
Per visualizzare richieste di codice e risposte di esempio utilizzando l'API REST, consulta Esempi di utilizzo dell'API REST.
Per visualizzare richieste e risposte di codice di esempio che utilizzano l'SDK Vertex AI per Python, consulta Esempi di utilizzo dell'SDK Vertex AI per Python.