온프레미스 호스트는 공개 인터넷을 통해 Vertex AI 온라인 예측 엔드포인트에 도달하거나, Cloud VPN 또는 Cloud Interconnect를 이용해 Private Service Connect(PSC)를 사용하는 하이브리드 네트워킹 아키텍처를 통해 비공개로 Vertex AI 온라인 예측 엔드포인트에 도달할 수 있습니다. 두 옵션 모두 SSL/TLS 암호화를 제공합니다. 그러나 비공개 옵션이 훨씬 더 우수한 성능을 제공하므로 중요한 애플리케이션에는 비공개 옵션이 권장됩니다.
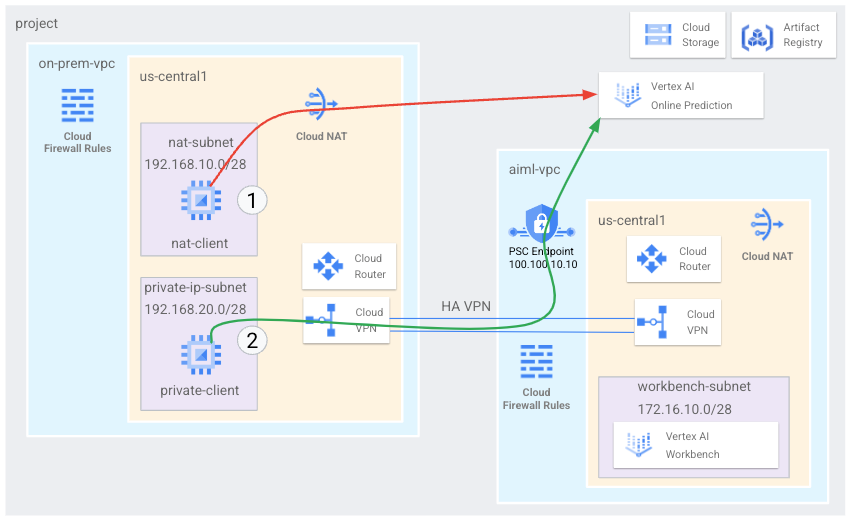
이 튜토리얼에서는 고가용성 VPN(HA VPN)을 사용하여 Cloud NAT를 통해 공개적으로 온라인 예측 엔드포인트에 액세스하며 멀티 클라우드 및 온프레미스 비공개 연결의 기반이 되는 두 가상 프라이빗 클라우드 네트워크 간에 비공개로 온라인 예측 엔드포인트에 액세스합니다.
이 튜토리얼은 Vertex AI, 가상 프라이빗 클라우드(VPC), Google Cloud 콘솔, Cloud Shell에 익숙한 엔터프라이즈 네트워크 관리자, 데이터 과학자, 연구원을 대상으로 합니다. Vertex AI Workbench에 익숙하면 도움이 되지만 필수는 아닙니다.
목표
- 이전 다이어그램에 나와 있듯이 2개의 가상 프라이빗 클라우드(VPC) 네트워크를 만듭니다.
- 하나(
on-prem-vpc)는 온프레미스 네트워크를 나타냅니다. - 다른 하나(
aiml-vpc)는 Vertex AI 온라인 예측 모델을 빌드하고 배포하는 데 사용됩니다.
- 하나(
aiml-vpc및on-prem-vpc를 연결하기 위해 HA VPN 게이트웨이, Cloud VPN 터널, Cloud Router를 배포합니다.- Vertex AI 온라인 예측 모델을 빌드하고 배포합니다.
- Private Service Connect(PSC) 엔드포인트를 만들어 비공개 온라인 예측 요청을 배포된 모델로 전달합니다.
aiml-vpc에서 Cloud Router 커스텀 공지 모드를 활성화하여 Private Service Connect 엔드포인트의 경로를on-prem-vpc에 알립니다.on-prem-vpc에 클라이언트 애플리케이션을 나타내는 Compute Engine VM 인스턴스 두 개를 만듭니다.- 하나(
nat-client)는 공개 인터넷을 통해(Cloud NAT를 통해) 온라인 예측 요청을 전송합니다. 이 액세스 방법은 다이어그램에서 빨간색 화살표와 숫자 1로 표시되어 있습니다. - 다른 하나(
private-client)는 HA VPN을 통해 비공개로 예측 요청을 전송합니다. 이 액세스 방법은 녹색 화살표와 숫자 2로 표시되어 있습니다.
- 하나(
비용
이 문서에서는 비용이 청구될 수 있는 다음과 같은 Google Cloud구성요소를 사용합니다.
프로젝트 사용량을 기준으로 예상 비용을 산출하려면 가격 계산기를 사용합니다.
이 문서에 설명된 태스크를 완료했으면 만든 리소스를 삭제하여 청구가 계속되는 것을 방지할 수 있습니다. 자세한 내용은 삭제를 참조하세요.
시작하기 전에
-
In the Google Cloud console, go to the project selector page.
-
Select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
- Cloud Shell을 열고 이 튜토리얼에 나열된 명령어를 실행합니다. Cloud Shell은 웹브라우저에서 프로젝트와 리소스를 관리할 수 있는 Google Cloud 용 대화형 셸 환경입니다.
- Cloud Shell에서 현재 프로젝트를 Google Cloud 프로젝트 ID로 설정한 후 동일한 프로젝트 ID를
projectid셸 변수에 저장합니다.projectid="PROJECT_ID" gcloud config set project ${projectid} -
Grant roles to your user account. Run the following command once for each of the following IAM roles:
roles/appengine.appViewer, roles/artifactregistry.admin, roles/compute.instanceAdmin.v1, roles/compute.networkAdmin, roles/compute.securityAdmin, roles/dns.admin, roles/iap.admin, roles/iap.tunnelResourceAccessor, roles/notebooks.admin, roles/oauthconfig.editor, roles/resourcemanager.projectIamAdmin, roles/servicemanagement.quotaAdmin, roles/iam.serviceAccountAdmin, roles/iam.serviceAccountUser, roles/servicedirectory.editor, roles/storage.admin, roles/aiplatform.usergcloud projects add-iam-policy-binding PROJECT_ID --member="user:USER_IDENTIFIER" --role=ROLE
Replace the following:
PROJECT_ID: your project ID.USER_IDENTIFIER: the identifier for your user account—for example,myemail@example.com.ROLE: the IAM role that you grant to your user account.
-
Enable the DNS, Artifact Registry, IAM, Compute Engine, Notebooks, and Vertex AI APIs:
gcloud services enable dns.googleapis.com
artifactregistry.googleapis.com iam.googleapis.com compute.googleapis.com notebooks.googleapis.com aiplatform.googleapis.com
VPC 네트워크 만들기
이 섹션에서는 온라인 예측 모델을 만들고 이를 엔드포인트에 배포하기 위한 VPC 네트워크 1개와 해당 엔드포인트에 대한 비공개 액세스를 위한 VPC 네트워크 1개를 만듭니다. 두 VPC 네트워크 각각에 Cloud Router와 Cloud NAT 게이트웨이를 만듭니다. Cloud NAT 게이트웨이는 외부 IP 주소가 없는 Compute Engine 가상 머신(VM) 인스턴스에 대한 발신 연결을 제공합니다.
온라인 예측 엔드포인트의 VPC 네트워크 만들기(aiml-vpc)
VPC 네트워크를 만듭니다.
gcloud compute networks create aiml-vpc \ --project=$projectid \ --subnet-mode=custom기본 IPv4 범위가
172.16.10.0/28인workbench-subnet라는 서브넷을 만듭니다.gcloud compute networks subnets create workbench-subnet \ --project=$projectid \ --range=172.16.10.0/28 \ --network=aiml-vpc \ --region=us-central1 \ --enable-private-ip-google-accesscloud-router-us-central1-aiml-nat이라는 리전 Cloud Router를 만듭니다.gcloud compute routers create cloud-router-us-central1-aiml-nat \ --network aiml-vpc \ --region us-central1Cloud Router에 Cloud NAT 게이트웨이를 추가합니다.
gcloud compute routers nats create cloud-nat-us-central1 \ --router=cloud-router-us-central1-aiml-nat \ --auto-allocate-nat-external-ips \ --nat-all-subnet-ip-ranges \ --region us-central1
'온프레미스' VPC 네트워크 만들기(on-prem-vpc)
VPC 네트워크를 만듭니다.
gcloud compute networks create on-prem-vpc \ --project=$projectid \ --subnet-mode=custom기본 IPv4 범위가
192.168.10.0/28인nat-subnet라는 서브넷을 만듭니다.gcloud compute networks subnets create nat-subnet \ --project=$projectid \ --range=192.168.10.0/28 \ --network=on-prem-vpc \ --region=us-central1기본 IPv4 범위가
192.168.20.0/28인private-ip-subnet라는 서브넷을 만듭니다.gcloud compute networks subnets create private-ip-subnet \ --project=$projectid \ --range=192.168.20.0/28 \ --network=on-prem-vpc \ --region=us-central1cloud-router-us-central1-on-prem-nat이라는 리전 Cloud Router를 만듭니다.gcloud compute routers create cloud-router-us-central1-on-prem-nat \ --network on-prem-vpc \ --region us-central1Cloud Router에 Cloud NAT 게이트웨이를 추가합니다.
gcloud compute routers nats create cloud-nat-us-central1 \ --router=cloud-router-us-central1-on-prem-nat \ --auto-allocate-nat-external-ips \ --nat-all-subnet-ip-ranges \ --region us-central1
Private Service Connect(PSC) 엔드포인트 만들기
이 섹션에서는 on-prem-vpc 네트워크의 VM 인스턴스가 Vertex AI API를 통해 온라인 예측 엔드포인트에 액세스하는 데 사용하는 Private Service Connect(PSC) 엔드포인트를 만듭니다.
Private Service Connect(PSC) 엔드포인트는 해당 네트워크의 클라이언트에서 직접 액세스할 수 있는 on-prem-vpc 네트워크의 내부 IP 주소입니다. 이 엔드포인트는 PSC 엔드포인트의 IP 주소와 일치하는 네트워크 트래픽을 Google API 번들로 전달하는 전달 규칙을 배포함으로써 생성됩니다.
이후 단계에서 PSC 엔드포인트의 IP 주소(100.100.10.10)는 aiml-cr-us-central1 Cloud Router에서 커스텀 공지 경로로 on-prem-vpc 네트워크에 공지됩니다.
PSC 엔드포인트의 IP 주소를 예약합니다.
gcloud compute addresses create psc-ip \ --global \ --purpose=PRIVATE_SERVICE_CONNECT \ --addresses=100.100.10.10 \ --network=aiml-vpcPSC 엔드포인트를 만듭니다.
gcloud compute forwarding-rules create pscvertex \ --global \ --network=aiml-vpc \ --address=psc-ip \ --target-google-apis-bundle=all-apis구성된 PSC 엔드포인트를 나열하고
pscvertex엔드포인트가 생성되었는지 확인합니다.gcloud compute forwarding-rules list \ --filter target="(all-apis OR vpc-sc)" --global구성된 PSC 엔드포인트의 세부정보를 가져오고 IP 주소가
100.100.10.10인지 확인합니다.gcloud compute forwarding-rules describe pscvertex \ --global
하이브리드 연결 구성
이 섹션에서는 서로 연결된 HA VPN 게이트웨이 2개를 만듭니다. 각 게이트웨이에는 Cloud Router와 VPN 터널 쌍이 포함됩니다.
aiml-vpcVPC 네트워크에 대한 HA VPN 게이트웨이를 만듭니다.gcloud compute vpn-gateways create aiml-vpn-gw \ --network=aiml-vpc \ --region=us-central1on-prem-vpcVPC 네트워크에 대한 HA VPN 게이트웨이를 만듭니다.gcloud compute vpn-gateways create on-prem-vpn-gw \ --network=on-prem-vpc \ --region=us-central1Google Cloud 콘솔에서 VPN 페이지로 이동합니다.
VPN 페이지에서 Cloud VPN 게이트웨이 탭을 클릭합니다.
VPN 게이트웨이 목록에서 게이트웨이가 2개 있고 각 게이트웨이에 IP 주소가 2개 있는지 확인합니다.
Cloud Shell에서
aiml-vpc가상 프라이빗 클라우드네트워크의 Cloud Router를 만듭니다.gcloud compute routers create aiml-cr-us-central1 \ --region=us-central1 \ --network=aiml-vpc \ --asn=65001on-prem-vpc가상 프라이빗 클라우드 네트워크를 위한 Cloud Router를 만듭니다.gcloud compute routers create on-prem-cr-us-central1 \ --region=us-central1 \ --network=on-prem-vpc \ --asn=65002
aiml-vpc용 VPN 터널 만들기
aiml-vpc-tunnel0이라는 VPN 터널을 만듭니다.gcloud compute vpn-tunnels create aiml-vpc-tunnel0 \ --peer-gcp-gateway on-prem-vpn-gw \ --region us-central1 \ --ike-version 2 \ --shared-secret [ZzTLxKL8fmRykwNDfCvEFIjmlYLhMucH] \ --router aiml-cr-us-central1 \ --vpn-gateway aiml-vpn-gw \ --interface 0aiml-vpc-tunnel1이라는 VPN 터널을 만듭니다.gcloud compute vpn-tunnels create aiml-vpc-tunnel1 \ --peer-gcp-gateway on-prem-vpn-gw \ --region us-central1 \ --ike-version 2 \ --shared-secret [bcyPaboPl8fSkXRmvONGJzWTrc6tRqY5] \ --router aiml-cr-us-central1 \ --vpn-gateway aiml-vpn-gw \ --interface 1
on-prem-vpc용 VPN 터널 만들기
on-prem-vpc-tunnel0이라는 VPN 터널을 만듭니다.gcloud compute vpn-tunnels create on-prem-tunnel0 \ --peer-gcp-gateway aiml-vpn-gw \ --region us-central1 \ --ike-version 2 \ --shared-secret [ZzTLxKL8fmRykwNDfCvEFIjmlYLhMucH] \ --router on-prem-cr-us-central1 \ --vpn-gateway on-prem-vpn-gw \ --interface 0on-prem-vpc-tunnel1이라는 VPN 터널을 만듭니다.gcloud compute vpn-tunnels create on-prem-tunnel1 \ --peer-gcp-gateway aiml-vpn-gw \ --region us-central1 \ --ike-version 2 \ --shared-secret [bcyPaboPl8fSkXRmvONGJzWTrc6tRqY5] \ --router on-prem-cr-us-central1 \ --vpn-gateway on-prem-vpn-gw \ --interface 1Google Cloud 콘솔에서 VPN 페이지로 이동합니다.
VPN 페이지에서 Cloud VPN 터널 탭을 클릭합니다.
VPN 터널 목록에서 4개의 VPN 터널이 설정되었는지 확인합니다.
BGP 세션 설정
Cloud Router는 경계 게이트웨이 프로토콜(BGP)을 사용하여 VPC 네트워크(이 경우 aiml-vpc)와 온프레미스 네트워크(on-prem-vpc로 표시) 간에 경로를 교환합니다. Cloud Router에서 온프레미스 라우터의 인터페이스와 BGP 피어를 구성합니다.
인터페이스와 BGP 피어 구성은 함께 BGP 세션을 구성합니다.
이 섹션에서는 aiml-vpc에 대한 2개의 BGP 세션과 on-prem-vpc에 대한 2개의 BGP 세션을 만듭니다.
aiml-vpc용 BGP 세션 설정
Cloud Shell에서 첫 번째 BGP 인터페이스를 만듭니다.
gcloud compute routers add-interface aiml-cr-us-central1 \ --interface-name if-tunnel0-to-onprem \ --ip-address 169.254.1.1 \ --mask-length 30 \ --vpn-tunnel aiml-vpc-tunnel0 \ --region us-central1첫 번째 BGP 피어를 만듭니다.
gcloud compute routers add-bgp-peer aiml-cr-us-central1 \ --peer-name bgp-on-premises-tunnel0 \ --interface if-tunnel1-to-onprem \ --peer-ip-address 169.254.1.2 \ --peer-asn 65002 \ --region us-central1두 번째 BGP 인터페이스를 만듭니다.
gcloud compute routers add-interface aiml-cr-us-central1 \ --interface-name if-tunnel1-to-onprem \ --ip-address 169.254.2.1 \ --mask-length 30 \ --vpn-tunnel aiml-vpc-tunnel1 \ --region us-central1두 번째 BGP 피어를 만듭니다.
gcloud compute routers add-bgp-peer aiml-cr-us-central1 \ --peer-name bgp-on-premises-tunnel1 \ --interface if-tunnel2-to-onprem \ --peer-ip-address 169.254.2.2 \ --peer-asn 65002 \ --region us-central1
on-prem-vpc용 BGP 세션 설정
첫 번째 BGP 인터페이스를 만듭니다.
gcloud compute routers add-interface on-prem-cr-us-central1 \ --interface-name if-tunnel0-to-aiml-vpc \ --ip-address 169.254.1.2 \ --mask-length 30 \ --vpn-tunnel on-prem-tunnel0 \ --region us-central1첫 번째 BGP 피어를 만듭니다.
gcloud compute routers add-bgp-peer on-prem-cr-us-central1 \ --peer-name bgp-aiml-vpc-tunnel0 \ --interface if-tunnel1-to-aiml-vpc \ --peer-ip-address 169.254.1.1 \ --peer-asn 65001 \ --region us-central1두 번째 BGP 인터페이스를 만듭니다.
gcloud compute routers add-interface on-prem-cr-us-central1 \ --interface-name if-tunnel1-to-aiml-vpc \ --ip-address 169.254.2.2 \ --mask-length 30 \ --vpn-tunnel on-prem-tunnel1 \ --region us-central1두 번째 BGP 피어를 만듭니다.
gcloud compute routers add-bgp-peer on-prem-cr-us-central1 \ --peer-name bgp-aiml-vpc-tunnel1 \ --interface if-tunnel2-to-aiml-vpc \ --peer-ip-address 169.254.2.1 \ --peer-asn 65001 \ --region us-central1
BGP 세션 생성 검증
Google Cloud 콘솔에서 VPN 페이지로 이동합니다.
VPN 페이지에서 Cloud VPN 터널 탭을 클릭합니다.
VPN 터널 목록에서 이제 4개의 터널 각각에 대한 BGP 세션 상태 열의 값이 BGP 세션 구성에서 BGP 설정됨으로 변경된 것을 확인할 수 있습니다. 새 값을 보려면 Google Cloud 콘솔 브라우저 탭을 새로고침해야 할 수 있습니다.
aiml-vpc가 HA VPN을 통해 서브넷 경로를 학습했는지 확인
Google Cloud 콘솔에서 VPC 네트워크 페이지로 이동합니다.
VPC 네트워크 목록에서
aiml-vpc를 클릭합니다.경로 탭을 클릭합니다.
리전 목록에서 us-central1(아이오와)을 선택하고 보기를 클릭합니다.
대상 IP 범위 열에서
aiml-vpcVPC 네트워크가on-prem-vpcVPC 네트워크의nat-subnet서브넷(192.168.10.0/28) 및private-ip-subnet(192.168.20.0/28) 서브넷에서 경로를 학습했는지 확인합니다.
on-prem-vpc가 HA VPN을 통해 서브넷 경로를 학습했는지 확인
Google Cloud 콘솔에서 VPC 네트워크 페이지로 이동합니다.
VPC 네트워크 목록에서
on-prem-vpc를 클릭합니다.경로 탭을 클릭합니다.
리전 목록에서 us-central1(아이오와)을 선택하고 보기를 클릭합니다.
대상 IP 범위 열에서
on-prem-vpcVPC 네트워크가aiml-vpcVPC 네트워크의workbench-subnet서브넷(172.16.10.0/28)에서 경로를 학습했는지 확인합니다.
aiml-vpc용 커스텀 공지 경로 만들기
서브넷이 VPC 네트워크에 구성되어 있지 않으므로 aiml-cr-us-central1 Cloud Router에서 Private Service Connect 엔드포인트 IP 주소가 자동으로 공지되지 않습니다.
따라서 on-prem-vpc에 대한 BGP를 통해 온프레미스 환경에 공지할 엔드포인트 IP 주소 100.100.10.10에 대한 aiml-cr-us-central Cloud Router에서 커스텀 공지 경로를 만들어야 합니다.
Google Cloud 콘솔에서 Cloud Router 페이지로 이동합니다.
Cloud Router 목록에서
aiml-cr-us-central1을 클릭합니다.라우터 세부정보 페이지에서 수정을 클릭합니다.
공지된 경로 섹션에서 경로에 대해 커스텀 경로 만들기를 선택합니다.
커스텀 경로 추가를 클릭합니다.
소스에 커스텀 IP 범위를 선택합니다.
IP 주소 범위에
100.100.10.10을 입력합니다.설명에
Private Service Connect Endpoint IP를 입력합니다.완료를 클릭한 다음 저장을 클릭합니다.
on-prem-vpc가 HA VPN을 통해 PSC 엔드포인트 IP 주소를 학습했는지 확인
Google Cloud 콘솔에서 VPC 네트워크 페이지로 이동합니다.
VPC 네트워크 목록에서
on-prem-vpc를 클릭합니다.경로 탭을 클릭합니다.
리전 목록에서 us-central1(아이오와)을 선택하고 보기를 클릭합니다.
대상 IP 범위 열에서
on-prem-vpcVPC 네트워크가 PSC 엔드포인트의 IP 주소(100.100.10.10)를 학습했는지 확인합니다.
on-prem-vpc용 커스텀 공지 경로 만들기
on-prem-vpc Cloud Router는 기본적으로 모든 서브넷을 공지하지만 private-ip-subnet 서브넷만 필요합니다.
다음 섹션에서는 on-prem-cr-us-central1 Cloud Router에서 경로 공지를 업데이트합니다.
Google Cloud 콘솔에서 Cloud Router 페이지로 이동합니다.
Cloud Router 목록에서
on-prem-cr-us-central1을 클릭합니다.라우터 세부정보 페이지에서 수정을 클릭합니다.
공지된 경로 섹션에서 경로에 대해 커스텀 경로 만들기를 선택합니다.
Cloud Router에 표시되는 모든 서브넷 공지 체크박스가 선택되어 있으면 선택 취소합니다.
커스텀 경로 추가를 클릭합니다.
소스에 커스텀 IP 범위를 선택합니다.
IP 주소 범위에
192.168.20.0/28을 입력합니다.설명에
Private Service Connect Endpoint IP subnet (private-ip-subnet)를 입력합니다.완료를 클릭한 다음 저장을 클릭합니다.
aiml-vpc가 on-prem-vpc에서 private-ip-subnet 경로를 학습했는지 확인
Google Cloud 콘솔에서 VPC 네트워크 페이지로 이동합니다.
VPC 네트워크 목록에서
aiml-vpc를 클릭합니다.경로 탭을 클릭합니다.
리전 목록에서 us-central1(아이오와)을 선택하고 보기를 클릭합니다.
대상 IP 범위 열에서
aiml-vpcVPC 네트워크가private-ip-subnet경로(192.168.20.0/28)를 학습했는지 확인합니다.
테스트 VM 인스턴스 만들기
사용자 관리형 서비스 계정 만들기
Google Cloud API를 호출해야 하는 애플리케이션이 있는 경우 애플리케이션 또는 워크로드가 실행 중인 VM에 사용자 관리형 서비스 계정을 연결하는 것이 좋습니다. 따라서 이 섹션에서는 이 튜토리얼의 뒷부분에서 만드는 VM 인스턴스에 적용할 사용자 관리형 서비스 계정을 만듭니다.
Cloud Shell에서 서비스 계정을 만듭니다.
gcloud iam service-accounts create gce-vertex-sa \ --description="service account for vertex" \ --display-name="gce-vertex-sa"Compute 인스턴스 관리자(v1)(
roles/compute.instanceAdmin.v1) IAM 역할을 서비스 계정에 할당합니다.gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:gce-vertex-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/compute.instanceAdmin.v1"서비스 계정에 Vertex AI 사용자(
roles/aiplatform.user) IAM 역할을 할당합니다.gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:gce-vertex-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/aiplatform.user"
테스트 VM 인스턴스 만들기
이 단계에서는 Vertex AI API에 도달하는 다양한 방법을 검증하기 위한 테스트 VM 인스턴스를 만들며 구체적으로 다음과 같습니다.
nat-client인스턴스는 Cloud NAT를 사용하여 공개 인터넷을 통해 온라인 예측 엔드포인트에 액세스하도록 Vertex AI를 결정합니다.private-client인스턴스는 Private Service Connect IP 주소100.100.10.10를 사용하여 HA VPN을 통해 온라인 예측 엔드포인트에 액세스합니다.
IAP(Identity-Aware Proxy)가 VM 인스턴스에 연결할 수 있도록 다음과 같은 방화벽 규칙을 만듭니다.
- IAP를 통해 액세스할 수 있게 만들려는 모든 VM 인스턴스에 적용됩니다.
- IP 범위
35.235.240.0/20에서 포트 22를 통한 TCP 트래픽을 허용합니다. 이 범위에는 IAP가 TCP 전달을 위해 사용하는 모든 IP 주소가 포함됩니다.
nat-clientVM 인스턴스를 만듭니다.gcloud compute instances create nat-client \ --zone=us-central1-a \ --image-family=debian-11 \ --image-project=debian-cloud \ --subnet=nat-subnet \ --service-account=gce-vertex-sa@$projectid.iam.gserviceaccount.com \ --scopes=https://www.googleapis.com/auth/cloud-platform \ --no-address \ --metadata startup-script="#! /bin/bash sudo apt-get update sudo apt-get install tcpdump dnsutils -y"private-clientVM 인스턴스를 만듭니다.gcloud compute instances create private-client \ --zone=us-central1-a \ --image-family=debian-11 \ --image-project=debian-cloud \ --subnet=private-ip-subnet \ --service-account=gce-vertex-sa@$projectid.iam.gserviceaccount.com \ --scopes=https://www.googleapis.com/auth/cloud-platform \ --no-address \ --metadata startup-script="#! /bin/bash sudo apt-get update sudo apt-get install tcpdump dnsutils -y"IAP 방화벽 규칙을 만듭니다.
gcloud compute firewall-rules create ssh-iap-on-prem-vpc \ --network on-prem-vpc \ --allow tcp:22 \ --source-ranges=35.235.240.0/20
Vertex AI Workbench 인스턴스 생성
Vertex AI Workbench용 사용자 관리형 서비스 계정 만들기
Vertex AI Workbench 인스턴스를 만들 때는 Compute Engine 기본 서비스 계정을 사용하는 대신 사용자 관리형 서비스 계정을 지정하는 것이 좋습니다.
조직에서 iam.automaticIamGrantsForDefaultServiceAccounts 조직 정책 제약조건을 적용하지 않는 경우 Compute Engine 기본 서비스 계정(및 인스턴스 사용자로 지정하는 모든 사용자)에Google Cloud 프로젝트에 대한 편집자 역할 (roles/editor)이 부여됩니다. 이 동작을 사용 중지하려면 기본 서비스 계정에 대한 자동 역할 부여 사용 중지를 참고하세요.
Cloud Shell에서
workbench-sa라는 이름의 서비스 계정을 만듭니다.gcloud iam service-accounts create workbench-sa \ --display-name="workbench-sa"서비스 계정에 스토리지 관리자(
roles/storage.admin) IAM 역할을 할당합니다.gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/storage.admin"서비스 계정에 Vertex AI 사용자(
roles/aiplatform.user) IAM 역할을 할당합니다.gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/aiplatform.user"서비스 계정에 Artifact Registry 관리자 IAM 역할을 할당합니다.
gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/artifactregistry.admin"
Vertex AI Workbench 인스턴스 만들기
Cloud Shell에서
workbench-sa서비스 계정을 지정하여 Vertex AI Workbench 인스턴스를 만듭니다.gcloud workbench instances create workbench-tutorial \ --vm-image-project=deeplearning-platform-release \ --vm-image-family=common-cpu-notebooks \ --machine-type=n1-standard-4 \ --location=us-central1-a \ --subnet-region=us-central1 \ --shielded-secure-boot=True \ --subnet=workbench-subnet \ --disable-public-ip \ --service-account-email=workbench-sa@$projectid.iam.gserviceaccount.com
온라인 예측 모델 만들기 및 배포
개발 환경 준비
Google Cloud 콘솔의 Vertex AI Workbench 페이지에서 인스턴스 탭으로 이동합니다.
Vertex AI Workbench 인스턴스 이름(
workbench-tutorial) 옆에 있는 JupyterLab 열기를 클릭합니다.Vertex AI Workbench 인스턴스가 JupyterLab을 엽니다.
이 섹션의 나머지 부분에서는 Google Cloud 콘솔이나 Cloud Shell이 아닌 Jupyterlab에서 모델 배포까지 작업합니다.
File(파일) > New(새로 만들기) > Terminal(터미널)을 선택합니다.
JupyterLab 터미널(Cloud Shell 아님)에서 프로젝트의 환경 변수를 정의합니다. PROJECT_ID를 프로젝트 ID로 바꿉니다.
PROJECT_ID=PROJECT_IDJupyterLab 터미널에서
cpr-codelab및cd라는 새 디렉터리를 만듭니다.mkdir cpr-codelab cd cpr-codelabFile Browser(파일 브라우저)에서 새
cpr-codelab폴더를 더블클릭합니다.이 폴더가 파일 브라우저에 표시되지 않으면 Google Cloudconsole 브라우저 탭을 새로고침하고 다시 시도합니다.
파일 > 새로 만들기 > 노트북을 선택합니다.
커널 선택 메뉴에서 Python [conda env:base] *(로컬)을 선택하고 선택을 클릭합니다.
새 노트북 파일 이름을 다음과 같이 바꿉니다.
File Browser(파일 브라우저)에서
Untitled.ipynb파일 아이콘을 마우스 오른쪽 버튼으로 클릭하고task.ipynb를 입력합니다.이제
cpr-codelab디렉터리가 다음과 같이 표시됩니다.+ cpr-codelab/ + task.ipynb다음 단계에서는 새 노트북 셀을 만들고, 코드를 붙여넣고, 셀을 실행하여 Jupyterlab 노트북에서 모델을 만듭니다.
종속 항목을 다음과 같이 설치합니다.
새 노트북을 열면 코드를 입력할 수 있는 기본 코드 셀이 있습니다. 텍스트 필드 뒤에
[ ]:가 표시되어 있습니다. 이 텍스트 필드에 코드를 붙여넣습니다.셀에 다음 코드를 붙여넣고 Run the selected cells and advance(선택한 셀 실행 및 진행)를 클릭하여 다음 단계에서 입력으로 사용할
requirements.txt파일을 만듭니다.%%writefile requirements.txt fastapi uvicorn==0.17.6 joblib~=1.1.1 numpy>=1.17.3, <1.24.0 scikit-learn>=1.2.2 pandas google-cloud-storage>=2.2.1,<3.0.0dev google-cloud-aiplatform[prediction]>=1.18.2이 단계와 이어지는 각 단계에서 Insert a cell below(아래에 셀 삽입)를 클릭하여 코드 셀을 추가하고 셀에 코드를 붙여넣은 후 Run the selected cells and advance(선택한 셀 실행 및 진행)를 클릭합니다.
Pip를 사용하여 노트북 인스턴스에 종속 항목을 설치합니다.!pip install -U --user -r requirements.txt설치가 완료되면 Kernel(커널) > Restart kernel(커널 다시 시작)을 선택하여 커널을 다시 시작하고 라이브러리를 가져올 수 있는지 확인합니다.
다음 코드를 새 노트북 셀에 붙여넣어 모델과 전처리 아티팩트를 저장할 디렉터리를 만듭니다.
USER_SRC_DIR = "src_dir" !mkdir $USER_SRC_DIR !mkdir model_artifacts # copy the requirements to the source dir !cp requirements.txt $USER_SRC_DIR/requirements.txt
File Browser(파일 브라우저)에서
cpr-codelab디렉터리 구조가 이제 다음과 같이 표시됩니다.+ cpr-codelab/ + model_artifacts/ + src_dir/ + requirements.txt + requirements.txt + task.ipynb
모델 학습
계속해서 task.ipynb 노트북에 코드 셀을 추가하고 각 새 셀에 다음 코드를 붙여넣어 실행합니다.
라이브러리를 가져옵니다.
import seaborn as sns import numpy as np import pandas as pd from sklearn import preprocessing from sklearn.ensemble import RandomForestRegressor from sklearn.pipeline import make_pipeline from sklearn.compose import make_column_transformer import joblib import logging # set logging to see the docker container logs logging.basicConfig(level=logging.INFO)PROJECT_ID를 프로젝트 ID로 대체하여 다음 변수를 정의합니다.
REGION = "us-central1" MODEL_ARTIFACT_DIR = "sklearn-model-artifacts" REPOSITORY = "diamonds" IMAGE = "sklearn-image" MODEL_DISPLAY_NAME = "diamonds-cpr" PROJECT_ID = "PROJECT_ID" BUCKET_NAME = "gs://PROJECT_ID-cpr-bucket"Cloud Storage 버킷을 만듭니다.
!gcloud storage buckets create $BUCKET_NAME --location=us-central1seaborn 라이브러리에서 데이터를 로드한 후 데이터 프레임을 특성 및 라벨에 대해 각각 하나씩 총 두 개를 만듭니다.
data = sns.load_dataset('diamonds', cache=True, data_home=None) label = 'price' y_train = data['price'] x_train = data.drop(columns=['price'])학습 데이터를 살펴보고 각 행이 다이아몬드 모양인지 확인합니다.
x_train.head()해당 가격인 라벨을 확인합니다.
y_train.head()sklearn 열 변환을 정의하여 범주형 특성을 원-핫 인코딩하고 숫자 특성을 확장합니다.
column_transform = make_column_transformer( (preprocessing.OneHotEncoder(), [1,2,3]), (preprocessing.StandardScaler(), [0,4,5,6,7,8]))랜덤 포레스트 모델을 정의합니다.
regr = RandomForestRegressor(max_depth=10, random_state=0)sklearn 파이프라인을 만듭니다. 이 파이프라인은 입력 데이터를 가져와 인코딩 및 크기 조정하고 모델에 전달합니다.
my_pipeline = make_pipeline(column_transform, regr)모델을 학습시킵니다.
my_pipeline.fit(x_train, y_train)테스트 샘플을 전달하여 모델에서 predict 메서드를 호출합니다.
my_pipeline.predict([[0.23, 'Ideal', 'E', 'SI2', 61.5, 55.0, 3.95, 3.98, 2.43]])"X does not have valid feature names, but"과 같은 경고가 표시될 수 있지만 무시해도 됩니다.파이프라인을
model_artifacts디렉터리에 저장하고 Cloud Storage 버킷에 복사합니다.joblib.dump(my_pipeline, 'model_artifacts/model.joblib') !gcloud storage cp model_artifacts/model.joblib {BUCKET_NAME}/{MODEL_ARTIFACT_DIR}/
전처리 아티팩트 저장
전처리 아티팩트를 만듭니다. 이 아티팩트는 모델 서버가 시작될 때 맞춤 컨테이너에 로드됩니다. 전처리 아티팩트는 거의 모든 형식(피클 파일 등)일 수 있지만 이 경우에는 사전을 JSON 파일에 씁니다.
clarity_dict={"Flawless": "FL", "Internally Flawless": "IF", "Very Very Slightly Included": "VVS1", "Very Slightly Included": "VS2", "Slightly Included": "S12", "Included": "I3"}
CPR 모델 서버를 사용하여 커스텀 서빙 컨테이너 빌드
학습 데이터의
clarity특성은 항상 축약된 형태(즉, 'Flawless' 대신 'FL')였습니다. 서빙 시점에 이 특성의 데이터도 축약되어 있는지 확인해야 합니다. 모델이 'Flawless'가 아닌 'FL'을 원-핫 인코딩하는 방법을 알고 있기 때문입니다. 이 커스텀 전처리 논리는 나중에 작성합니다. 지금은 이 조회 테이블을 JSON 파일에 저장한 다음 Cloud Storage 버킷에 이를 씁니다.import json with open("model_artifacts/preprocessor.json", "w") as f: json.dump(clarity_dict, f) !gcloud storage cp model_artifacts/preprocessor.json {BUCKET_NAME}/{MODEL_ARTIFACT_DIR}/File Browser(파일 브라우저)에서 디렉터리 구조가 이제 다음과 같이 표시됩니다.
+ cpr-codelab/ + model_artifacts/ + model.joblib + preprocessor.json + src_dir/ + requirements.txt + requirements.txt + task.ipynb노트북에서 다음 코드를 붙여넣고 실행하여
SklearnPredictor를 서브클래스로 만들고src_dir/의 Python 파일에 씁니다. 이 예시에서는 예측 메서드가 아닌 로드, 사전 처리, 후 처리 메서드만 맞춤설정합니다.%%writefile $USER_SRC_DIR/predictor.py import joblib import numpy as np import json from google.cloud import storage from google.cloud.aiplatform.prediction.sklearn.predictor import SklearnPredictor class CprPredictor(SklearnPredictor): def __init__(self): return def load(self, artifacts_uri: str) -> None: """Loads the sklearn pipeline and preprocessing artifact.""" super().load(artifacts_uri) # open preprocessing artifact with open("preprocessor.json", "rb") as f: self._preprocessor = json.load(f) def preprocess(self, prediction_input: np.ndarray) -> np.ndarray: """Performs preprocessing by checking if clarity feature is in abbreviated form.""" inputs = super().preprocess(prediction_input) for sample in inputs: if sample[3] not in self._preprocessor.values(): sample[3] = self._preprocessor[sample[3]] return inputs def postprocess(self, prediction_results: np.ndarray) -> dict: """Performs postprocessing by rounding predictions and converting to str.""" return {"predictions": [f"${value}" for value in np.round(prediction_results)]}Vertex AI SDK for Python으로 커스텀 예측 루틴을 사용해서 이미지를 빌드합니다. Dockerfile이 생성되고 이미지가 자동으로 빌드됩니다.
from google.cloud import aiplatform aiplatform.init(project=PROJECT_ID, location=REGION) import os from google.cloud.aiplatform.prediction import LocalModel from src_dir.predictor import CprPredictor # Should be path of variable $USER_SRC_DIR local_model = LocalModel.build_cpr_model( USER_SRC_DIR, f"{REGION}-docker.pkg.dev/{PROJECT_ID}/{REPOSITORY}/{IMAGE}", predictor=CprPredictor, requirements_path=os.path.join(USER_SRC_DIR, "requirements.txt"), )예측을 위한 샘플 2개가 포함된 테스트 파일을 작성합니다. 인스턴스 중 하나는 축약된 명확성 이름을 갖지만 다른 인스턴스는 먼저 변환해야 합니다.
import json sample = {"instances": [ [0.23, 'Ideal', 'E', 'VS2', 61.5, 55.0, 3.95, 3.98, 2.43], [0.29, 'Premium', 'J', 'Internally Flawless', 52.5, 49.0, 4.00, 2.13, 3.11]]} with open('instances.json', 'w') as fp: json.dump(sample, fp)로컬 모델을 배포하여 컨테이너를 로컬에서 테스트합니다.
with local_model.deploy_to_local_endpoint( artifact_uri = 'model_artifacts/', # local path to artifacts ) as local_endpoint: predict_response = local_endpoint.predict( request_file='instances.json', headers={"Content-Type": "application/json"}, ) health_check_response = local_endpoint.run_health_check()다음 명령어를 사용하여 예측 결과를 확인할 수 있습니다.
predict_response.content출력은 다음과 같이 표시됩니다.
b'{"predictions": ["$479.0", "$586.0"]}'
모델을 온라인 예측 모델 엔드포인트에 배포
컨테이너를 로컬에서 테스트했으므로 이제 이미지를 Artifact Registry로 내보내고 모델을 Vertex AI Model Registry에 업로드할 차례입니다.
Artifact Registry에 액세스하도록 Docker를 구성합니다.
!gcloud artifacts repositories create {REPOSITORY} \ --repository-format=docker \ --location=us-central1 \ --description="Docker repository" !gcloud auth configure-docker {REGION}-docker.pkg.dev --quiet이미지를 내보냅니다.
local_model.push_image()모델을 업로드합니다.
model = aiplatform.Model.upload(local_model = local_model, display_name=MODEL_DISPLAY_NAME, artifact_uri=f"{BUCKET_NAME}/{MODEL_ARTIFACT_DIR}",)모델을 배포합니다.
endpoint = model.deploy(machine_type="n1-standard-2")다음 단계로 계속 진행하기 전에 모델이 배포될 때까지 기다립니다. 배포에 약 10~15분이 걸릴 수 있습니다.
예측을 가져와서 배포된 모델을 테스트합니다.
endpoint.predict(instances=[[0.23, 'Ideal', 'E', 'VS2', 61.5, 55.0, 3.95, 3.98, 2.43]])출력은 다음과 같이 표시됩니다.
Prediction(predictions=['$479.0'], deployed_model_id='3171115779319922688', metadata=None, model_version_id='1', model_resource_name='projects/721032480027/locations/us-central1/models/8554949231515795456', explanations=None)
Vertex AI API에 대한 공개 인터넷 액세스 검증
이 섹션에서는 한 Cloud Shell 세션 탭에서 nat-client VM 인스턴스에 로그인하고 다른 세션 탭을 사용해 us-central1-aiplatform.googleapis.com 도메인에 대해 dig 및 tcpdump 명령어를 실행하여 Vertex AI API에 대한 연결을 검증합니다.
Cloud Shell(탭 1)에서 PROJECT_ID를 프로젝트 ID로 바꿔 다음 명령어를 실행합니다.
projectid=PROJECT_ID gcloud config set project ${projectid}IAP를 사용하여
nat-clientVM 인스턴스에 로그인합니다.gcloud compute ssh nat-client \ --project=$projectid \ --zone=us-central1-a \ --tunnel-through-iapdig명령어를 실행합니다.dig us-central1-aiplatform.googleapis.com온라인 예측 요청을 엔드포인트로 전송할 때
nat-clientVM(탭 1)에서 다음 명령어를 실행하여 DNS 변환을 검증합니다.sudo tcpdump -i any port 53 -nCloud Shell에서 새 탭 열기를 클릭하여 새 Cloud Shell 세션(탭 2)을 엽니다.
새 Cloud Shell 세션(탭 2)에서 PROJECT_ID를 프로젝트 ID로 바꿔 다음 명령어를 실행합니다.
projectid=PROJECT_ID gcloud config set project ${projectid}nat-clientVM 인스턴스에 로그인합니다.gcloud compute ssh --zone "us-central1-a" "nat-client" --project "$projectid"nat-clientVM(탭 2)에서vim또는nano와 같은 텍스트 편집기를 사용하여instances.json파일을 만듭니다. 파일에 쓸 수 있는 권한을 얻으려면sudo를 앞에 추가해야 합니다. 예를 들면 다음과 같습니다.sudo vim instances.json파일에 다음 데이터 문자열을 추가합니다.
{"instances": [ [0.23, 'Ideal', 'E', 'VS2', 61.5, 55.0, 3.95, 3.98, 2.43], [0.29, 'Premium', 'J', 'Internally Flawless', 52.5, 49.0, 4.00, 2.13, 3.11]]}다음과 같이 파일을 저장합니다.
vim을 사용하는 경우Esc키를 누른 후:wq를 입력하여 파일을 저장하고 종료합니다.nano를 사용하는 경우Control+O을 입력하고Enter를 눌러 파일을 저장한 후Control+X를 입력하여 종료합니다.
PSC 엔드포인트의 온라인 예측 엔드포인트 ID를 찾습니다.
Google Cloud 콘솔의 Vertex AI 섹션에서 온라인 예측 페이지의 엔드포인트 탭으로 이동합니다.
자신이 만든
diamonds-cpr_endpoint라는 이름의 엔드포인트 행을 찾습니다.ID 열에서 19자리 엔드포인트 ID를 찾아 복사합니다.
Cloud Shell의
nat-clientVM(탭 2)에서 PROJECT_ID를 프로젝트 ID로 바꾸고 ENDPOINT_ID를 PSC 엔드포인트 ID로 바꿔 다음 명령어를 실행합니다.projectid=PROJECT_ID gcloud config set project ${projectid} ENDPOINT_ID=ENDPOINT_IDnat-clientVM(탭 2)에서 다음 명령어를 실행하여 온라인 예측 요청을 전송합니다.curl -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" -H "Content-Type: application/json" https://us-central1-aiplatform.googleapis.com/v1/projects/${projectid}/locations/us-central1/endpoints/${ENDPOINT_ID}:predict -d @instances.json
예측을 실행했으므로 이제 tcpdump 결과(탭 1)에 Vertex AI API 도메인(us-central1-aiplatform.googleapis.com)의 로컬 DNS 서버(169.254.169.254)에 대한 Cloud DNS 쿼리를 수행하는 nat-client VM 인스턴스(192.168.10.2)가 표시됩니다. 이 DNS 쿼리는 Vertex AI API에 대한 공개 가상 IP 주소(VIP)를 반환합니다.
Vertex AI API에 대한 비공개 액세스 검증
이 섹션에서는 새 Cloud Shell 세션(탭 3)에서 IAP(Identity-Aware Proxy)를 사용하여 private-client VM 인스턴스에 로그인한 후 Vertex AI 도메인(us-central1-aiplatform.googleapis.com)에 대해 dig 명령어를 실행하여 Vertex AI API에 대한 연결을 검증합니다.
Cloud Shell에서 새 탭 열기를 클릭하여 새 Cloud Shell 세션(탭 3)을 엽니다. 새로 연 탭이 탭 3입니다.
새 Cloud Shell 세션(탭 3)에서 PROJECT_ID를 프로젝트 ID로 바꿔 다음 명령어를 실행합니다.
projectid=PROJECT_ID gcloud config set project ${projectid}IAP를 사용하여
private-clientVM 인스턴스에 로그인합니다.gcloud compute ssh private-client \ --project=$projectid \ --zone=us-central1-a \ --tunnel-through-iapdig명령어를 실행합니다.dig us-central1-aiplatform.googleapis.comprivate-clientVM 인스턴스(탭 3)에서vim또는nano와 같은 텍스트 편집기를 사용하여 다음 줄을/etc/hosts파일에 추가합니다.100.100.10.10 us-central1-aiplatform.googleapis.com이 줄은 PSC 엔드포인트의 IP 주소(
100.100.10.10)를 Vertex AI Google API(us-central1-aiplatform.googleapis.com)의 정규화된 도메인 이름에 할당합니다. 수정된 파일은 다음과 같이 표시됩니다.127.0.0.1 localhost ::1 localhost ip6-localhost ip6-loopback ff02::1 ip6-allnodes ff02::2 ip6-allrouters 100.100.10.10 us-central1-aiplatform.googleapis.com # Added by you 192.168.20.2 private-client.c.$projectid.internal private-client # Added by Google 169.254.169.254 metadata.google.internal # Added by Googleprivate-clientVM(탭 3)에서 Vertex AI 엔드포인트를 핑하고 출력이 표시되면Control+C를 눌러 종료합니다.ping us-central1-aiplatform.googleapis.comping명령어는 PSC 엔드포인트 IP 주소가 포함된 다음 출력을 반환합니다.PING us-central1-aiplatform.googleapis.com (100.100.10.10) 56(84) bytes of data.온라인 예측 요청을 엔드포인트로 전송할 때
private-clientVM(탭 3)에서tcpdump를 사용하여 다음 명령어를 실행해 DNS 변환과 IP 데이터 경로를 검증합니다.sudo tcpdump -i any port 53 -n or host 100.100.10.10Cloud Shell에서 새 탭 열기를 클릭하여 새 Cloud Shell 세션(탭 4)을 엽니다.
새 Cloud Shell 세션(탭 4)에서 PROJECT_ID를 프로젝트 ID로 바꿔 다음 명령어를 실행합니다.
projectid=PROJECT_ID gcloud config set project ${projectid}탭 4에서
private-client인스턴스에 로그인합니다.gcloud compute ssh \ --zone "us-central1-a" "private-client" \ --project "$projectid"private-clientVM(탭 4)에서vim또는nano와 같은 텍스트 편집기를 사용하여 다음 데이터 문자열이 포함된instances.json파일을 만듭니다.{"instances": [ [0.23, 'Ideal', 'E', 'VS2', 61.5, 55.0, 3.95, 3.98, 2.43], [0.29, 'Premium', 'J', 'Internally Flawless', 52.5, 49.0, 4.00, 2.13, 3.11]]}private-clientVM(탭 4)에서 PROJECT_ID를 프로젝트 이름으로, ENDPOINT_ID를 PSC 엔드포인트 ID로 바꿔 다음 명령어를 실행합니다.projectid=PROJECT_ID echo $projectid ENDPOINT_ID=ENDPOINT_IDprivate-clientVM(탭 4)에서 다음 명령어를 실행하여 온라인 예측 요청을 전송합니다.curl -v -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" -H "Content-Type: application/json" https://us-central1-aiplatform.googleapis.com/v1/projects/${projectid}/locations/us-central1/endpoints/${ENDPOINT_ID}:predict -d @instances.jsonCloud Shell의
private-clientVM(탭 3)에서 PSC 엔드포인트 IP 주소(100.100.10.10)를 사용해 Vertex AI API에 액세스했는지 확인합니다.Cloud Shell 탭 3의
private-clienttcpdump터미널에서us-central1-aiplatform.googleapis.com에 대한 DNS 조회가 필요 없음을 알 수 있습니다./etc/hosts파일에 추가한 줄이 우선 적용되고 PSC IP 주소100.100.10.10이 데이터 경로에 사용되기 때문입니다.
삭제
이 튜토리얼에서 사용된 리소스 비용이 Google Cloud 계정에 청구되지 않도록 하려면 리소스가 포함된 프로젝트를 삭제하거나 프로젝트는 유지하되 개별 리소스를 삭제하세요.
다음과 같이 프로젝트에서 개별 리소스를 삭제할 수 있습니다.
다음과 같이 Vertex AI Workbench 인스턴스를 삭제합니다.
Google Cloud 콘솔의 Vertex AI 섹션에서 Workbench 페이지에 있는 인스턴스 탭으로 이동합니다.
workbench-tutorialVertex AI Workbench 인스턴스를 선택하고 삭제를 클릭합니다.
다음과 같이 컨테이너 이미지를 삭제합니다.
Google Cloud 콘솔에서 Artifact Registry 페이지로 이동합니다.
diamondsDocker 컨테이너를 선택하고 삭제를 클릭합니다.
다음과 같이 스토리지 버킷을 삭제합니다.
Google Cloud 콘솔에서 Cloud Storage 페이지로 이동합니다.
스토리지 버킷을 선택하고 삭제를 클릭합니다.
다음과 같이 엔드포인트에서 모델 배포를 취소합니다.
Google Cloud 콘솔의 Vertex AI 섹션에서 엔드포인트 페이지로 이동합니다.
diamonds-cpr_endpoint을 클릭하여 엔드포인트 세부정보 페이지로 이동합니다.diamonds-cpr모델 행에서 모델 배포 취소를 클릭합니다.엔드포인트에서 모델 배포 취소 대화상자에서 배포 취소를 클릭합니다.
다음과 같이 모델을 삭제합니다.
Google Cloud 콘솔의 Vertex AI 섹션에서 Model Registry 페이지로 이동합니다.
diamonds-cpr모델을 선택합니다.모델을 삭제하려면 작업을 클릭한 다음 모델 삭제를 클릭합니다.
다음과 같이 온라인 예측 엔드포인트를 삭제합니다.
Google Cloud 콘솔의 Vertex AI 섹션에서 온라인 예측 페이지로 이동합니다.
diamonds-cpr_endpoint엔드포인트를 선택합니다.엔드포인트를 삭제하려면 작업을 클릭한 다음 엔드포인트 삭제를 클릭합니다.
Cloud Shell에서 다음 명령어를 실행하여 나머지 리소스를 삭제합니다.
projectid=PROJECT_ID gcloud config set project ${projectid}gcloud compute forwarding-rules delete pscvertex \ --global \ --quietgcloud compute addresses delete psc-ip \ --global \ --quietgcloud compute networks subnets delete workbench-subnet \ --region=us-central1 \ --quietgcloud compute vpn-tunnels delete aiml-vpc-tunnel0 aiml-vpc-tunnel1 on-prem-tunnel0 on-prem-tunnel1 \ --region=us-central1 \ --quietgcloud compute vpn-gateways delete aiml-vpn-gw on-prem-vpn-gw \ --region=us-central1 \ --quietgcloud compute routers nats delete cloud-nat-us-central1 \ --router=cloud-router-us-central1-aiml-nat \ --region=us-central1 \ --quietgcloud compute routers delete aiml-cr-us-central1 cloud-router-us-central1-aiml-nat \ --region=us-central1 \ --quietgcloud compute routers delete cloud-router-us-central1-on-prem-nat on-prem-cr-us-central1 \ --region=us-central1 \ --quietgcloud compute instances delete nat-client private-client \ --zone=us-central1-a \ --quietgcloud compute firewall-rules delete ssh-iap-on-prem-vpc \ --quietgcloud compute networks subnets delete nat-subnet private-ip-subnet \ --region=us-central1 \ --quietgcloud compute networks delete on-prem-vpc \ --quietgcloud compute networks delete aiml-vpc \ --quietgcloud iam service-accounts delete gce-vertex-sa@$projectid.iam.gserviceaccount.com \ --quietgcloud iam service-accounts delete workbench-sa@$projectid.iam.gserviceaccount.com \ --quiet
다음 단계
- Vertex AI 엔드포인트 및 서비스에 액세스하기 위한 엔터프라이즈 네트워킹 옵션을 알아보세요.
- Private Service Connect 작동 방식과 상당한 성능상의 이점을 제공하는 이유를 알아보세요.
- VPC 서비스 제어를 사용하여 보안 경계를 만들어 온라인 예측 엔드포인트에서 Vertex AI 및 기타 Google API에 대한 액세스를 허용하거나 거부하는 방법을 알아보세요.
- 대규모 및 프로덕션 환경에서
/etc/hosts파일을 업데이트하는 대신 DNS 전달 영역을 사용하는 방법과 이유를 알아보세요.