학습 데이터의 품질은 생성하는 모델의 효율성에 상당한 영향을 주며, 나아가 모델에서 반환한 예측의 품질에도 영향을 줍니다. 고품질 학습 데이터의 핵심은 예측하려는 도메인을 정확하게 표현하는 학습 항목을 확보하고 학습 항목의 라벨을 올바르게 지정하는 것입니다.
학습 데이터 항목에 라벨을 할당하는 방법에는 3가지가 있습니다.
- 라벨이 이미 할당된 데이터 항목을 데이터 세트에 추가(예: 상용 데이터 세트 사용)
- Google Cloud 콘솔을 사용하여 데이터 항목에 라벨 할당
- 수동 라벨러가 데이터 항목에 라벨을 추가하도록 요청
Vertex AI 데이터 라벨링 작업을 사용하면 수동 라벨러와 협력하여 머신러닝 모델 학습에 사용할 수 있는 데이터 모음의 라벨을 매우 정확하게 생성할 수 있습니다.
데이터 라벨링 가격 책정에 대한 자세한 내용은 데이터 라벨링을 참조하세요.
수동 라벨러의 데이터 라벨링을 요청하려면 수동 라벨 지정자에게 다음을 제공하는 데이터 라벨링 작업을 만듭니다.
- 라벨을 지정할 대표 데이터 항목이 포함된 데이터 세트
- 데이터 항목에 적용할 수 있는 모든 라벨 목록
- 수동 라벨러에게 라벨링 태스크를 안내하는 안내가 포함된 PDF 파일
수동 라벨러는 이러한 리소스를 사용하여 데이터 세트에 있는 항목에 주석을 추가합니다. 완료되면 주석 세트를 사용하여 Vertex AI 모델을 학습시키거나 라벨이 지정된 데이터 항목을 내보내 다른 머신러닝 환경에서 사용할 수 있습니다.
데이터세트 만들기
데이터 세트를 만들고 해당 데이터 세트로 데이터 항목을 가져와서 라벨을 지정할 데이터 항목을 수동 라벨러에게 제공합니다. 데이터 항목에 라벨을 지정할 필요가 없습니다. 수동 라벨러가 데이터 항목에 적용하는 주석의 유형은 데이터 유형(이미지, 동영상, 텍스트)과 목표(예: 분류 또는 객체 추적)에 따라 결정됩니다.
라벨 제공
데이터 라벨링 태스크를 만들 때 수동 라벨러가 이미지 라벨 지정에 사용할 라벨 집합을 나열합니다. 예를 들어 개나 고양이 포함 여부에 따라 이미지를 분류하고 싶다면 '개'와 '고양이'라는 두 가지 라벨이 있는 라벨 세트를 만들면 됩니다. 다음 목록에 표시된 대로 'Neither' 및 'Bot'에 대해 라벨을 지정해야 할 수 있습니다.
다음은 고품질의 라벨 세트를 만들기 위한 몇 가지 가이드라인입니다.
- 각 라벨의 표시 이름을 '개', '고양이', '건물' 같은 유의미한 단어로 설정합니다. 'label1', 'label2' 같은 추상적인 이름이나 어려운 약어는 사용해선 안 됩니다. 라벨 이름의 의미가 확실할수록 수동 라벨러가 라벨을 더 정확하고 일관적으로 적용할 수 있습니다.
- 라벨을 다른 라벨과 쉽게 구분할 수 있는지 확인합니다. 각 데이터 항목에 라벨이 하나만 적용되는 분류 태스크라면 의미가 중복되는 라벨을 사용하지 않는 것이 좋습니다. 예를 들어 '스포츠' 및 '야구'라는 라벨을 사용하지 않습니다.
- 분류 태스크에서는 다른 라벨과 일치하지 않는 데이터에 사용할 수 있도록, '기타'나 '없음' 같은 라벨을 포함하는 것이 좋습니다. 예를 들어 사용할 수 있는 라벨이 '개'와 '고양이'뿐이라면 라벨 지정자가 모든 이미지에 '개'나 '고양이' 라벨 중 하나를 선택해 지정해야 하는 상황이 생기게 됩니다. 커스텀 모델은 보통 학습 데이터에 개나 고양이 이외의 이미지가 있을 때 더 강력해집니다.
- 라벨 세트에 정의된 라벨이 20개를 넘지 않을 때 라벨러의 효율성과 정확성이 가장 높다는 점에 유의하세요. 라벨은 100개까지 포함할 수 있습니다.
안내 만들기
안내는 수동 라벨 지정자에게 데이터에 라벨을 적용하는 방법을 알려주는 역할을 합니다. 안내에는 라벨이 지정된 샘플 데이터와 기타 구체적인 지침이 포함되어야 합니다.
안내는 PDF 파일 형식입니다. PDF 안내는 각 사례에 대한 긍정적/부정적 예시나 설명 같은 정교한 지침을 제공할 수 있습니다. 또한 PDF는 이미지 경계 상자나 동영상 객체 추적처럼 복잡한 작업을 위한 안내를 제공하기에 편리한 형식입니다.
안내를 작성하고 PDF 파일을 만들어 Cloud Storage 버킷에 PDF 파일을 저장하세요.
효과적인 안내 제공
효과적인 안내는 양질의 수동 라벨링 결과를 보장하는 데 가장 중요한 요소입니다. 사용 사례에 대해 가장 잘 아는 입장에서 수동 라벨러에게 원하는 작업 방식을 확실하게 알려야 합니다. 다음은 효과적인 안내 작성에 관한 몇 가지 가이드라인입니다.
수동 라벨러는 사용자의 도메인 관련 지식을 보유하고 있지 않습니다. 라벨러에게 전달하는 지침은 사용 사례를 잘 모르는 사람도 쉽게 이해할 수 있어야 합니다.
안내가 너무 길면 안 됩니다. 라벨러가 20분 내에 안내를 검토하고 이해할 수 있는 정도가 가장 좋습니다.
안내는 태스크의 개념과 데이터에 라벨을 지정하는 방법을 모두 설명해야 합니다. 예를 들어 경계 상자 태스크라면 라벨러가 경계 상자를 어떻게 그려야 하는지 설명합니다. 꼭 맞는 상자여야 하나요, 여유를 둔 상자여야 하나요? 객체의 인스턴스가 여러 개라면 경계 상자를 하나로 그려야 하나요, 상자를 여러 개 그려야 하나요?
안내에 대응하는 라벨 세트가 포함되어 있다면 안내는 해당 세트에 있는 모든 라벨에 적용될 수 있어야 합니다. 안내에 있는 라벨 이름은 라벨 세트에 있는 이름과 일치해야 합니다.
일반적으로 이 과정을 몇 번 거쳐야 효과적인 안내가 완성됩니다. 먼저 수동 라벨러가 소규모 데이터 세트에 작업하도록 하고 라벨러의 작업이 예상과 얼마나 일치하는지에 따라 안내를 조정하는 것이 좋습니다.
효과적인 안내에는 다음 항목이 포함되어야 합니다.
- 라벨 목록 및 설명: 사용하려는 모든 라벨 목록 및 각 라벨의 의미.
- 예시: 각 라벨에 긍정 예시를 3개 이상, 부정 예시를 1개 이상 제시합니다. 이러한 예는 다양한 사례에 적용될 수 있어야 합니다.
- 특이 사례 적용: 라벨러가 라벨을 해석해야 할 필요를 줄이기 위해 특이 사례를 가능한 한 많이 적용합니다. 예를 들어 인물 주위에 경계 상자를 그려야 한다면 조건을 명확하게 설명하는 것이 좋습니다.
- 사람이 여러 명 있으면 각 사용자별로 상자가 필요한가요?
- 사람이 가려진 경우 상자가 필요한가요?
- 사람이 이미지에 일부만 표시된 경우 상자가 필요한가요?
- 사람이 사진 또는 그림에 있는 경우 상자가 필요한가요?
- 주석을 추가하는 방법을 설명하세요. 예를 들면 다음과 같습니다.
- 경계 상자는 꼭 맞아야 하나요, 여유가 있어야 하나요?
- 텍스트 항목 추출 작업에서 관심 있는 항목의 시작 지점과 종료 지점은 어디인가요?
- 라벨을 명확하게 설명해야 합니다. 라벨 두 개가 서로 비슷하거나 뒤섞이기 쉽다면 예시를 제시해 차이를 명확하게 설명하세요.
다음 예시는 PDF 안내에 포함될 수 있는 내용을 보여줍니다. 라벨러는 태스크를 시작하기 전에 안내를 검토합니다.

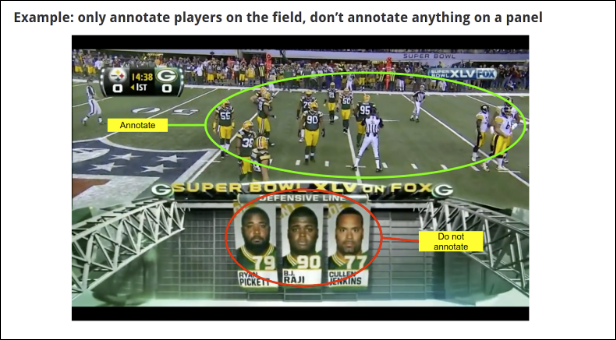
데이터 라벨링 태스크 만들기
웹 UI
Google Cloud 콘솔에서 데이터 라벨링을 요청할 수 있습니다.
Google Cloud 콘솔에서 라벨링 태스크 페이지로 이동합니다.
만들기를 클릭합니다.
새 라벨링 태스크 창이 열립니다.
라벨링 태스크의 이름을 입력합니다.
라벨을 지정할 항목의 데이터 세트를 선택합니다.
데이터 세트 세부정보 화면에서 새 라벨링 태스크 창을 연 경우 다른 데이터 세트를 선택할 수 없습니다.
목표가 올바른지 확인합니다.
목표 상자에는 기본 주석 세트에 따라 선택된 데이터 세트의 목표가 표시됩니다. 목표를 변경하려면 다른 주석 세트를 선택합니다.
라벨이 지정된 데이터에 사용할 주석 세트를 선택합니다.
수동 라벨러가 적용한 라벨이 선택된 주석 세트에 저장됩니다. 기존의 주석 세트를 선택하거나 새 주석 세트를 만듭니다. 새 주석 세트를 만드는 경우 이름을 지정해야 합니다.
능동적 학습 사용 여부를 지정합니다.
능동적 학습은 수동 라벨러가 데이터 세트의 일부에 라벨을 지정하면 머신러닝을 적용해 나머지 데이터에 라벨을 자동으로 지정하여 라벨링 프로세스의 속도를 높입니다.
계속을 클릭합니다.
수동 라벨러가 적용할 라벨을 입력합니다. 고품질 라벨 세트 만들기에 대한 자세한 내용은 라벨 세트 설계를 참조하세요.
계속을 클릭합니다.
수동 라벨러에 대한 안내 경로를 입력합니다. 안내는 Cloud Storage 버킷에 저장된 PDF 파일이어야 합니다. 고품질 안내 만들기에 대한 자세한 내용은 수동 라벨러 안내 설계를 참조하세요.
계속을 클릭합니다.
Google 관리 라벨러 또는 자체 라벨러 제공 중 무엇을 사용할지 선택합니다.
Google 관리 라벨러를 사용하도록 선택한 경우, 체크박스를 클릭하여 라벨 지정 비용을 이해하기 위해 가격 책정 가이드를 읽었음을 확인합니다.
자체 라벨러를 제공하려면 DataCompute 콘솔을 사용하여 라벨러 그룹을 만들고 라벨러의 활동을 관리해야 합니다. 그렇지 않으면 이 라벨링 태스크에 사용할 라벨러 그룹을 선택하세요.
드롭다운 목록에서 기존 라벨러 그룹을 선택하거나 새 라벨러 그룹을 선택하고 드롭다운 목록 아래 텍스트 상자 내 그룹 관리자들의 쉼표로 구분된 이메일 주소 목록과 그룹 이름을 입력합니다. 체크박스를 클릭하여 지정된 관리자에게 데이터 라벨링 정보를 볼 수 있는 권한을 부여합니다.
각 항목을 검토할 라벨러 수를 지정합니다.
기본적으로 한 명의 수동 라벨러가 각 데이터 항목에 주석을 추가합니다. 하지만 여러 라벨러가 각 항목을 주석 처리하고 검토하도록 요청할 수도 있습니다. 데이터 항목당 전문가 상자에서 라벨러 수를 선택합니다.
태스크 시작을 클릭합니다.
태스크 시작을 사용할 수 없는 경우 새 라벨링 태스크 창의 페이지를 검토하여 필수 정보를 모두 입력했는지 확인합니다.
Google Cloud 콘솔의 라벨링 태스크 페이지에서 데이터 라벨링 태스크 진행 상황을 검토할 수 있습니다.
페이지에 요청된 각 라벨링 태스크의 상태가 표시됩니다. 진행률 열에 100%가 표시되면 해당 데이터 세트에 라벨이 지정되고 모델 학습 준비가 완료된 것입니다.
REST
요청 데이터를 사용하기 전에 다음을 바꿉니다.
- PROJECT_ID: 프로젝트 ID
- DISPLAY_NAME: 데이터 라벨링 작업의 이름
- DATASET_ID: 라벨을 지정할 항목이 포함된 데이터 세트의 ID
- LABELERS: 각 데이터 항목을 검토하는 수동 라벨러의 수. 유효한 값은 1, 3, 5입니다.
- INSTRUCTIONS: 수동 라벨러에 대한 안내가 포함된 PDF 파일의 경로입니다. 이 파일은 프로젝트에서 액세스할 수 있는 Cloud Storage 버킷에 있어야 합니다.
- INPUT_SCHEMA_URI: 데이터 항목 유형의 스키마 파일 경로
- 이미지 분류 단일 라벨:
gs://google-cloud-aiplatform/schema/dataset/ioformat/image_classification_single_label_io_format_1.0.0.yaml - 이미지 분류 멀티 라벨:
gs://google-cloud-aiplatform/schema/dataset/ioformat/image_classification_multi_label_io_format_1.0.0.yaml - 이미지 객체 감지:
gs://google-cloud-aiplatform/schema/dataset/ioformat/image_bounding_box_io_format_1.0.0.yaml - 텍스트 분류 단일 라벨:
gs://google-cloud-aiplatform/schema/dataset/ioformat/text_classification_single_label_io_format_1.0.0.yaml - 텍스트 분류 멀티 라벨:
gs://google-cloud-aiplatform/schema/dataset/ioformat/text_classification_multi_label_io_format_1.0.0.yaml - 텍스트 항목 추출:
gs://google-cloud-aiplatform/schema/dataset/ioformat/text_extraction_io_format_1.0.0.yaml - 텍스트 감정 분석:
gs://google-cloud-aiplatform/schema/dataset/ioformat/text_sentiment_io_format_1.0.0.yaml - 동영상 분류:
gs://google-cloud-aiplatform/schema/dataset/ioformat/video_classification_io_format_1.0.0.yaml - 동영상 객체 추적:
gs://google-cloud-aiplatform/schema/dataset/ioformat/video_object_tracking_io_format_1.0.0.yaml
- 이미지 분류 단일 라벨:
- LABEL_LIST: 데이터 항목에 적용할 수 있는 라벨을 열거한 쉼표로 구분된 문자열 목록
- ANNOTATION_SET: 라벨링된 데이터에 대한 주석 세트의 이름
HTTP 메서드 및 URL:
POST https://us-central1-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/dataLabelingJobs
JSON 요청 본문:
{
"displayName":"DISPLAY_NAME",
"datasets":"DATASET_ID",
"labelerCount":LABELERS,
"instructionUri":"INSTRUCTIONS",
"inputsSchemaUri":"INPUT_SCHEMA_URI",
"inputs": {
"annotation_specs": [LABEL_LIST]
},
"annotationLabels": {
"aiplatform.googleapis.com/annotation_set_name": "ANNOTATION_SET"
}
}
요청을 보내려면 다음 옵션 중 하나를 펼칩니다.
다음과 비슷한 JSON 응답이 표시됩니다.
{
"name": "projects/PROJECT_ID/locations/us-central1/dataLabelingJobs/JOB_ID",
"displayName": "DISPLAY_NAME",
"datasets": [
"DATASET_ID"
],
"labelerCount": LABELERS,
"instructionUri": "INSTRUCTIONS",
"inputsSchemaUri": "INPUT_SCHEMA_URI",
"inputs": {
"annotationSpecs": [
LABEL_LIST
]
},
"state": "JOB_STATE_PENDING",
"labelingProgress": "0",
"createTime": "2020-05-30T23:13:49.121133Z",
"updateTime": "2020-05-30T23:13:49.121133Z",
"savedQuery": {
"name": "projects/PROJECT_ID/locations/us-central1/datasets/DATASET_ID/savedQueries/ANNOTATION_SET_ID"
},
"annotationSpecCount": 2
}
DataLabelingJob입니다. 완료율이 값인 "labelingProgress" 요소를 모니터링하여 작업 진행 상태를 확인할 수 있습니다.