La qualité de vos données d'entraînement influe fortement sur l'efficacité du modèle que vous créez et, par extension, sur la qualité des prédictions renvoyées par ce modèle. La clé des données d'entraînement de haute qualité consiste à vous assurer que vous disposez d'éléments d'entraînement qui représentent avec précision le domaine sur lequel vous souhaitez faire des prédictions, et que les éléments sont correctement étiquetés.
Pour attribuer des étiquettes à vos éléments de données d'entraînement, trois possibilités s'offrent à vous :
- Ajoutez les éléments de données à votre ensemble de données avec les étiquettes déjà attribuées, par exemple en utilisant un ensemble de données disponible dans le commerce.
- Attribuez des étiquettes aux éléments de données à l'aide de la console Google Cloud.
- Demandez à des étiqueteurs humains d'ajouter des étiquettes aux éléments de données.
Les tâches d'étiquetage de données Vertex AI vous permettent de travailler avec des étiqueteurs humains afin de générer des étiquettes très précises pour un ensemble de données que vous pouvez utiliser pour entraîner vos modèles de machine learning.
Pour en savoir plus sur les tarifs d'étiquetage de données, consultez la section Ajout d'étiquettes aux données.
Pour demander l'ajout d'étiquettes aux données par des étiqueteurs humains, vous devez créer une tâche d'étiquetage de données qui fournit aux étiqueteurs humains les éléments suivants :
- L'ensemble de données contenant les éléments de données représentatifs à étiqueter.
- La liste de toutes les étiquettes possibles à appliquer aux éléments de données.
- Un fichier PDF contenant des instructions pour guider les étiqueteurs humains dans leurs tâches d'étiquetage.
À l'aide de ces ressources, les étiqueteurs humains annotent les éléments de l'ensemble de données en fonction de vos instructions. Lorsqu'ils ont terminé, vous pouvez utiliser l'ensemble d'annotations pour entraîner un modèle Vertex AI, ou exporter les éléments de données étiquetés à utiliser dans un autre environnement de machine learning.
Créer un ensemble de données
Pour fournir aux étiqueteurs les éléments de données à étiqueter, créez un ensemble de données et importez-y des éléments de données. Les éléments de données n'ont pas besoin d'être associés à une étiquette. Le type de données (image, vidéo ou texte) et l'objectif (par exemple, classification ou suivi des objets) déterminent le type d'annotations que les étiqueteurs humains appliquent aux éléments de données.
Fournir des étiquettes
Lorsque vous créez une tâche d'étiquetage de données, vous répertoriez l'ensemble des étiquettes que les étiqueteurs humains doivent utiliser. Par exemple, si vous souhaitez classer des images selon qu'elles contiennent un chien ou un chat, vous devez créer un ensemble contenant deux étiquettes : "chien" et "chat". Comme indiqué dans la liste suivante, vous pouvez également décider d'utiliser des étiquettes "aucun" et "les deux".
Voici quelques consignes qui vous aideront à créer un ensemble d'étiquettes de haute qualité.
- Utilisez un mot explicite pour chaque nom d'étiquette, tel que "chien", "chat" ou "bâtiment". N'utilisez pas de noms abstraits tels que "étiquette1" et "étiquette2", ou des acronymes peu courants. Plus les noms des étiquettes seront explicites, plus il sera facile pour les étiqueteurs humains de les appliquer avec précision et cohérence.
- Assurez-vous que les étiquettes se distinguent facilement les unes des autres. Pour les tâches de classification où une seule étiquette est appliquée par élément de données, essayez de ne pas utiliser d'étiquettes ayant des significations similaires. Par exemple, n'utilisez pas d'étiquette pour "Sport" et "Baseball".
- Pour les tâches de classification, il est généralement judicieux d'inclure une étiquette nommée "autre" ou "aucune" que vous utiliserez pour les données ne correspondant à aucune autre étiquette. Par exemple, si les étiquettes "chien" et "chat" "sont les seules disponibles, les étiqueteurs doivent étiqueter chaque image avec l'une de ces deux étiquettes. Votre modèle personnalisé sera généralement plus robuste si vous incluez des images autres que des chiens ou des chats dans ses données d'entraînement.
- Rappelez-vous que le travail des étiqueteurs est plus efficace et plus précis si vous définissez un maximum de 20 étiquettes dans l'ensemble d'étiquettes. Vous pouvez inclure jusqu'à 100 étiquettes.
Créer des instructions
Les instructions donnent des informations aux étiqueteurs humains quant à la façon dont les étiquettes doivent être appliquées à vos données. Les instructions doivent inclure des exemples de données étiquetées et d'autres instructions explicites.
Les instructions sont des fichiers PDF. Les instructions PDF peuvent fournir des instructions sophistiquées, telles que des descriptions ou exemples positifs et négatifs pour chaque cas. Le format PDF est également pratique, car il permet d'obtenir des instructions sur les tâches complexes telles que les cadres de délimitation d'images ou le suivi d'objets vidéo.
Rédigez les instructions, créez un fichier PDF et enregistrez-le dans votre bucket Cloud Storage.
Fournir des instructions de bonne qualité
Si vous espérez que votre tâche d'ajout d'étiquettes renvoie de bons résultats, vos instructions doivent être de bonne qualité. Personne d'autre que vous ne connaît mieux votre cas d'utilisation : vous devez donc informer les étiqueteurs humains vous-même de ce que vous attendez d'eux. Voici quelques consignes pour créer des instructions de bonne qualité :
Les étiqueteurs humains n'ont pas votre connaissance du domaine. Lorsque vous leur demandez de faire certaines distinctions, assurez-vous qu'elles soient faciles à comprendre pour une personne qui ne connaît pas votre cas d'utilisation.
Évitez de formuler des instructions trop longues. Il est préférable qu'un étiqueteur puisse examiner et comprendre les instructions dans les 20 minutes.
Les instructions doivent décrire le concept de la tâche et donner des détails sur la manière d'étiqueter les données. Par exemple, pour une tâche de cadre de délimitation, décrivez comment vous souhaitez que les étiqueteurs tracent le cadre de délimitation. Le cadre doit-il être restreint ou relativement large ? S'il existe plusieurs instances du même objet, faut-il tracer un ou plusieurs cadres de délimitation ?
Si vos instructions comportent un ensemble d'étiquettes correspondant, elles doivent couvrir toutes les étiquettes de cet ensemble. Le nom d'étiquette donné dans les instructions doit correspondre à celui donné dans l'ensemble d'étiquettes.
Il faut souvent plusieurs itérations avant d'arriver à créer des instructions de bonne qualité. Nous vous recommandons de faire en sorte que les étiqueteurs humains travaillent sur un petit ensemble de données, puis d'ajuster vos instructions en fonction du degré de correspondance du travail des étiqueteurs à vos attentes.
Un fichier d'instructions de bonne qualité comprend les sections suivantes :
- Liste et description des étiquettes : liste de toutes les étiquettes que vous souhaitez utiliser et description de chaque étiquette.
- Exemples : pour chaque étiquette, donnez au moins trois exemples positifs et un exemple négatif. Ces exemples doivent couvrir différents cas.
- Couvrez les cas spéciaux. Pour que l'étiqueteur ait à interpréter l'étiquette au minimum, étiquetez autant de cas spéciaux que possible. Par exemple, si vous devez dessiner un cadre de délimitation pour une personne, il est préférable de préciser les points suivants :
- S'il y a plusieurs personnes, avez-vous besoin d'un cadre pour chacune d'entre elles ?
- Si une personne est cachée, avez-vous besoin d'un cadre ?
- Si une personne est partiellement visible dans l'image, avez-vous besoin d'un cadre ?
- Si une personne figure dans une photo ou un tableau, avez-vous besoin d'un cadre ?
- Indiquez comment ajouter des annotations. Exemple :
- Dans le cas d'un cadre de délimitation, avez-vous besoin d'un cadre restreint ou relativement large ?
- Dans le cas d'une extraction d'entité de texte, où doit commencer et finir l'entité en question ?
- Clarification concernant les étiquettes. Si deux étiquettes sont similaires ou faciles à confondre, donnez des exemples pour clarifier la différence.
Les exemples suivants montrent ce que peuvent inclure les instructions PDF. Les étiqueteurs examineront les instructions avant de commencer la tâche.

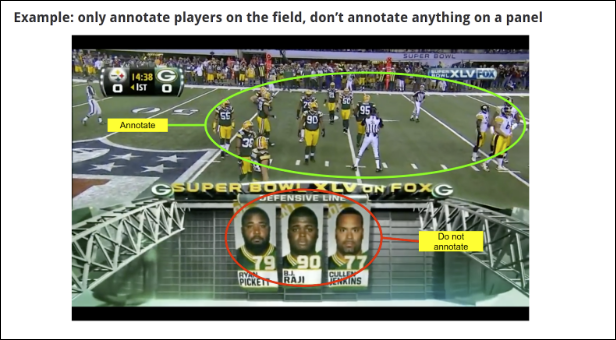
Créer une tâche d'étiquetage de données
UI Web
Vous pouvez demander un étiquetage de données à partir de la console Google Cloud.
Dans la console Google Cloud, accédez à la page Tâches d'étiquetage.
Cliquez sur Créer.
Le volet Nouvelle tâche d'étiquetage s'ouvre.
Attribuez un nom à la tâche d'étiquetage.
Sélectionnez l'ensemble de données dont vous souhaitez étiqueter les éléments.
Si vous avez ouvert le volet Nouvelle tâche d'étiquetage à partir de l'écran des informations concernant l'ensemble de données, vous ne pouvez pas sélectionner un autre ensemble de données.
Vérifiez que l'objectif est correct.
La zone Objectif affiche l'objectif de l'ensemble de données sélectionné, tel que déterminé par son ensemble d'annotations par défaut. Pour modifier l'objectif, sélectionnez un autre ensemble d'annotations.
Choisissez l'ensemble d'annotations à utiliser pour les données étiquetées.
Les étiquettes appliquées par les étiqueteurs humains sont enregistrées dans l'ensemble d'annotations sélectionné. Vous pouvez choisir un ensemble d'annotations existant ou en créer un. Si vous en créez un, vous devez lui attribuer un nom.
Indiquez si vous souhaitez utiliser l'apprentissage actif.
L'apprentissage actif accélère le processus d'étiquetage en utilisant une partie de l'étiquetage manuel de votre ensemble de données, puis en appliquant le machine learning pour étiqueter automatiquement le reste.
Cliquez sur Continuer.
Saisissez les étiquettes que les étiqueteurs humains devront appliquer. Pour savoir comment créer un ensemble d'étiquettes de haute qualité, consultez la section Concevoir un ensemble d'étiquettes.
Cliquez sur Continuer.
Saisissez le chemin d'accès aux instructions destinées aux étiqueteurs humains. Les instructions doivent être contenues dans un fichier PDF stocké dans un bucket Cloud Storage. Pour en savoir plus sur la création d'instructions de haute qualité, consultez la section Créer des instructions pour les étiqueteurs humains.
Cliquez sur Continuer.
Indiquez si vous souhaitez utiliser des étiqueteurs gérés par Google ou opter pour vos propres étiqueteurs.
Si vous avez choisi d'utiliser des étiqueteurs gérés par Google, cochez la case pour confirmer que vous avez lu le guide des tarifs visant la compréhension du coût de l'étiquetage.
Si vous faites appel à vos propres étiqueteurs, vous devez créer des groupes d'étiqueteurs et gérer leurs activités à l'aide de la console DataCompute. Sinon, choisissez le groupe d'étiqueteurs à utiliser pour cette tâche d'étiquetage.
Choisissez un groupe d'étiqueteurs existant dans la liste déroulante, ou sélectionnez Nouveau groupe d'étiqueteurs, puis saisissez le nom et les adresses e-mail des gestionnaires du groupe, séparés par des virgules dans la zone de texte sous la liste déroulante. Cochez la case pour autoriser les gestionnaires spécifiés à consulter vos informations d'étiquetage de données.
Indiquez le nombre d'étiqueteurs qui devront réviser chaque élément.
Par défaut, un étiqueteur humain annote chaque élément de données. Toutefois, vous pouvez demander à plusieurs étiqueteurs d'annoter et d'examiner chaque élément. Sélectionnez le nombre d'étiqueteurs dans la zone Spécialistes par élément de données.
Cliquez sur Démarrer une tâche.
Si Démarrer une tâche n'est pas disponible, consultez les pages du volet Nouvelle tâche d'ajout d'étiquettes pour vous assurer que vous avez saisi toutes les informations requises.
Vous pouvez suivre la progression de la tâche d'étiquetage de données dans la console Google Cloud depuis la page Tâches d'étiquetage.
Accéder à la page "Tâches d'étiquetage"
La page affiche l'état de chaque tâche d'étiquetage demandée. Lorsque la colonne Progression indique 100 %, l'ensemble de données correspondant est étiqueté et prêt à être utilisé pour entraîner un modèle.
REST
Avant d'utiliser les données de requête ci-dessous, effectuez les remplacements suivants :
- PROJECT_ID : ID de votre projet
- DISPLAY_NAME : nom de la tâche d'étiquetage des données
- DATASET_ID : ID de l'ensemble de données contenant les éléments à étiqueter
- LABELERS : nombre d'étiqueteurs humains souhaité pour examiner chaque élément de données. Les valeurs valides sont 1, 3 et 5.
- INSTRUCTIONS : chemin d'accès au fichier PDF contenant les instructions destinées aux étiqueteurs humains. Le fichier doit se trouver dans un bucket Cloud Storage accessible à partir de votre projet.
- INPUT_SCHEMA_URI : chemin d'accès au fichier de schéma pour le type d'élément de données :
- Classification d'images à étiquette unique :
gs://google-cloud-aiplatform/schema/dataset/ioformat/image_classification_single_label_io_format_1.0.0.yaml - Classification d'images multi-étiquette :
gs://google-cloud-aiplatform/schema/dataset/ioformat/image_classification_multi_label_io_format_1.0.0.yaml - Détection d'objets au sein d'images :
gs://google-cloud-aiplatform/schema/dataset/ioformat/image_bounding_box_io_format_1.0.0.yaml - Classification de texte à étiquette unique :
gs://google-cloud-aiplatform/schema/dataset/ioformat/text_classification_single_label_io_format_1.0.0.yaml - Classification de texte multi-étiquette :
gs://google-cloud-aiplatform/schema/dataset/ioformat/text_classification_multi_label_io_format_1.0.0.yaml - Extraction d'entités textuelles :
gs://google-cloud-aiplatform/schema/dataset/ioformat/text_extraction_io_format_1.0.0.yaml - Analyse des sentiments d'après un texte :
gs://google-cloud-aiplatform/schema/dataset/ioformat/text_sentiment_io_format_1.0.0.yaml - Classification de vidéos :
gs://google-cloud-aiplatform/schema/dataset/ioformat/video_classification_io_format_1.0.0.yaml - Suivi des objets vidéo :
gs://google-cloud-aiplatform/schema/dataset/ioformat/video_object_tracking_io_format_1.0.0.yaml
- Classification d'images à étiquette unique :
- LABEL_LIST : liste de chaînes séparées par une virgule, qui répertorient les étiquettes pouvant être appliqués à un élément de données
- ANNOTATION_SET : nom de l'ensemble d'annotations pour les données étiquetées
Méthode HTTP et URL :
POST https://us-central1-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/dataLabelingJobs
Corps JSON de la requête :
{
"displayName":"DISPLAY_NAME",
"datasets":"DATASET_ID",
"labelerCount":LABELERS,
"instructionUri":"INSTRUCTIONS",
"inputsSchemaUri":"INPUT_SCHEMA_URI",
"inputs": {
"annotation_specs": [LABEL_LIST]
},
"annotationLabels": {
"aiplatform.googleapis.com/annotation_set_name": "ANNOTATION_SET"
}
}
Pour envoyer votre requête, développez l'une des options suivantes :
Vous devriez recevoir une réponse JSON de ce type :
{
"name": "projects/PROJECT_ID/locations/us-central1/dataLabelingJobs/JOB_ID",
"displayName": "DISPLAY_NAME",
"datasets": [
"DATASET_ID"
],
"labelerCount": LABELERS,
"instructionUri": "INSTRUCTIONS",
"inputsSchemaUri": "INPUT_SCHEMA_URI",
"inputs": {
"annotationSpecs": [
LABEL_LIST
]
},
"state": "JOB_STATE_PENDING",
"labelingProgress": "0",
"createTime": "2020-05-30T23:13:49.121133Z",
"updateTime": "2020-05-30T23:13:49.121133Z",
"savedQuery": {
"name": "projects/PROJECT_ID/locations/us-central1/datasets/DATASET_ID/savedQueries/ANNOTATION_SET_ID"
},
"annotationSpecCount": 2
}
DataLabelingJob. Vous pouvez vérifier la progression du job en surveillant l'élément "labelingProgress", dont la valeur correspond au pourcentage terminé.
Java
Autres exemples de code :Utilisez l'apprentissage actif
Utilisez un pool d'étiqueteurs personnalisés
Python
Autres exemples de code :Utilisez l'apprentissage actif
Utilisez un pool d'étiqueteurs personnalisés
Étapes suivantes
- Entraînez un modèle à l'aide d'AutoML.
- Entraînez un modèle à l'aide de votre code d'entraînement personnalisé.