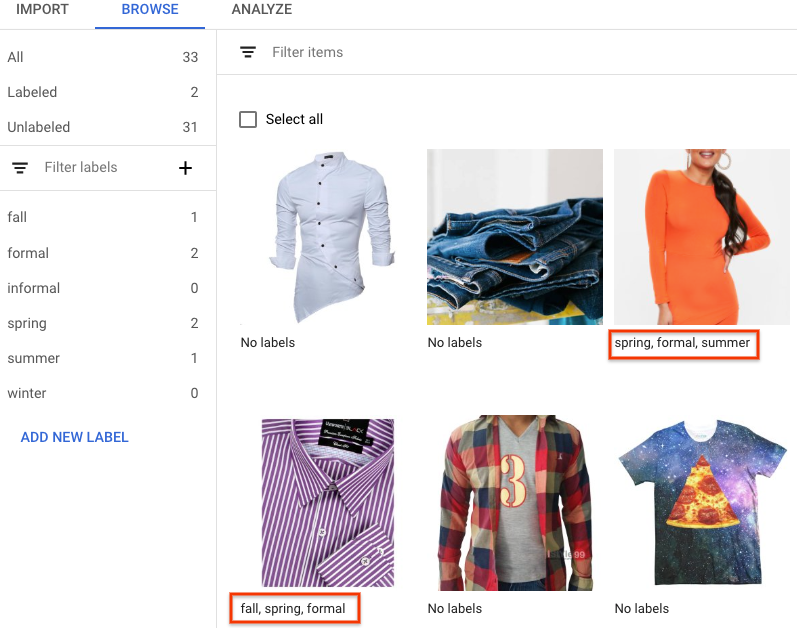
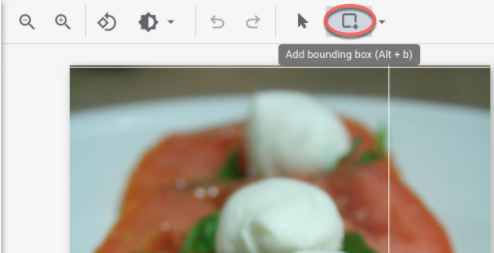
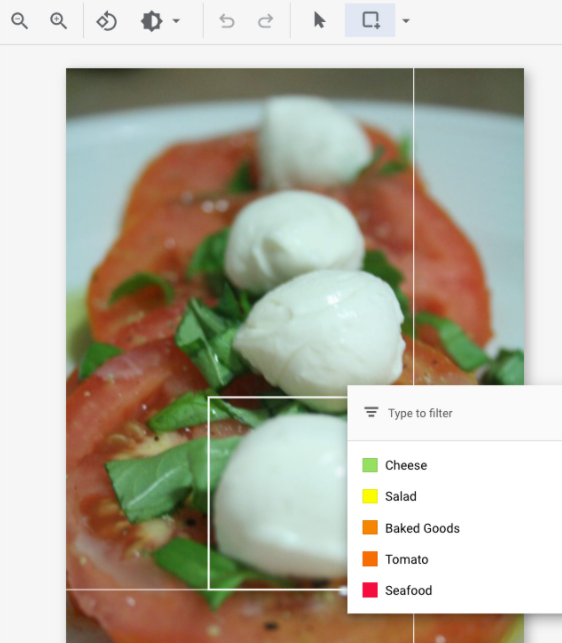
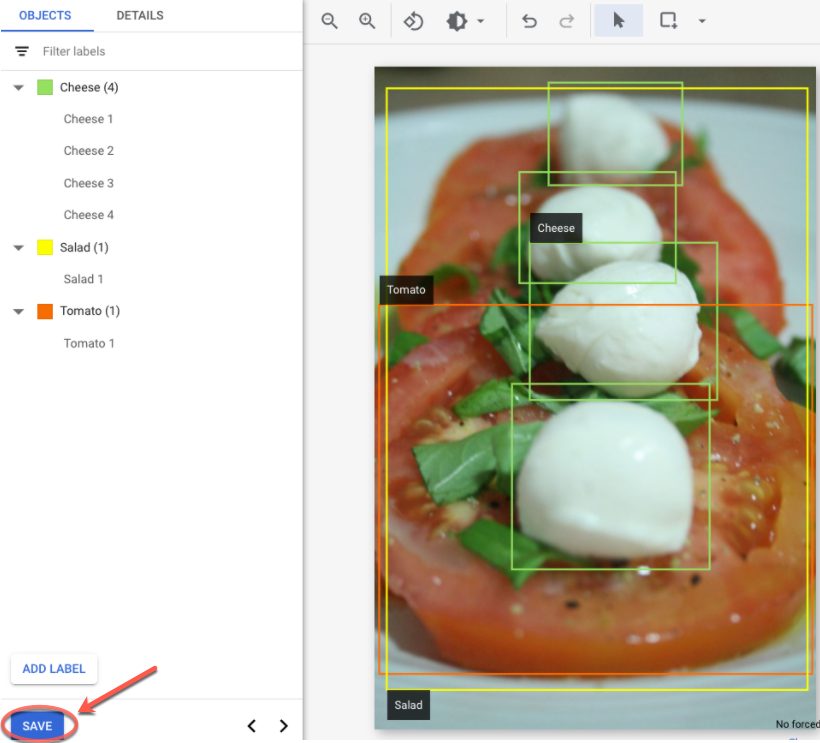
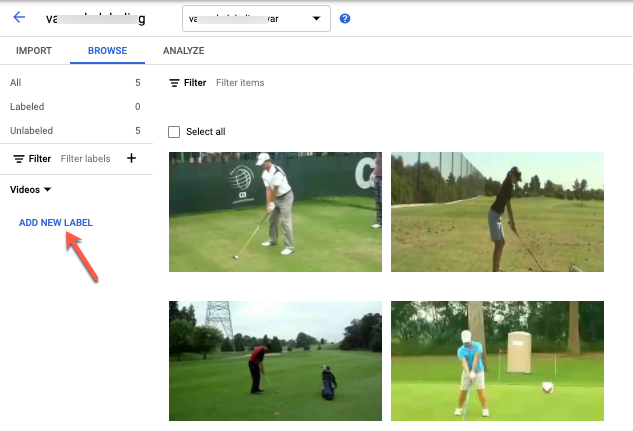
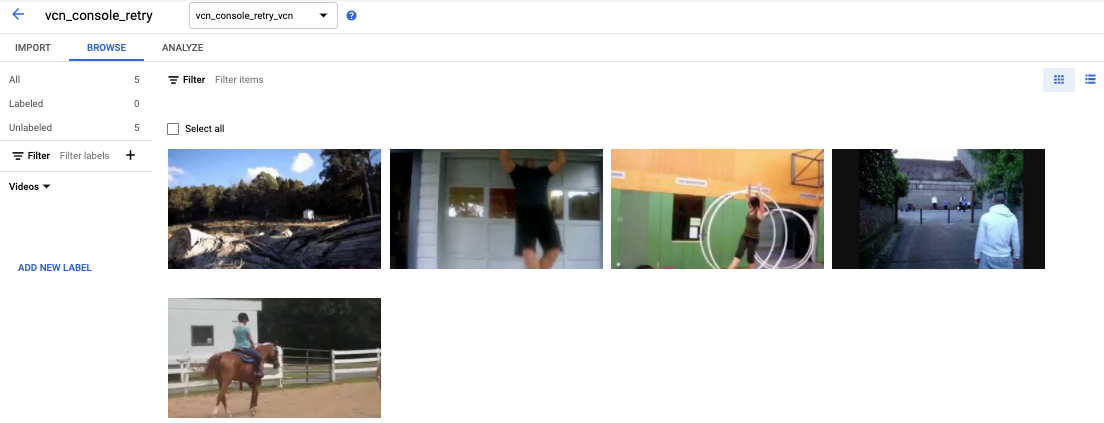
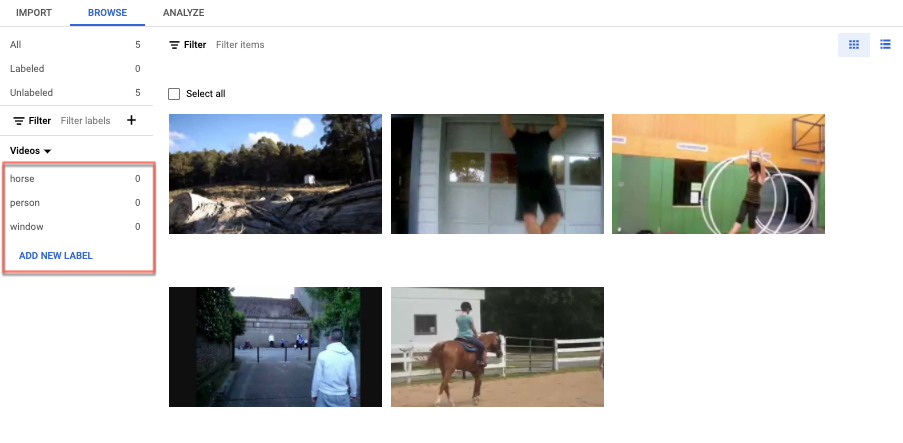
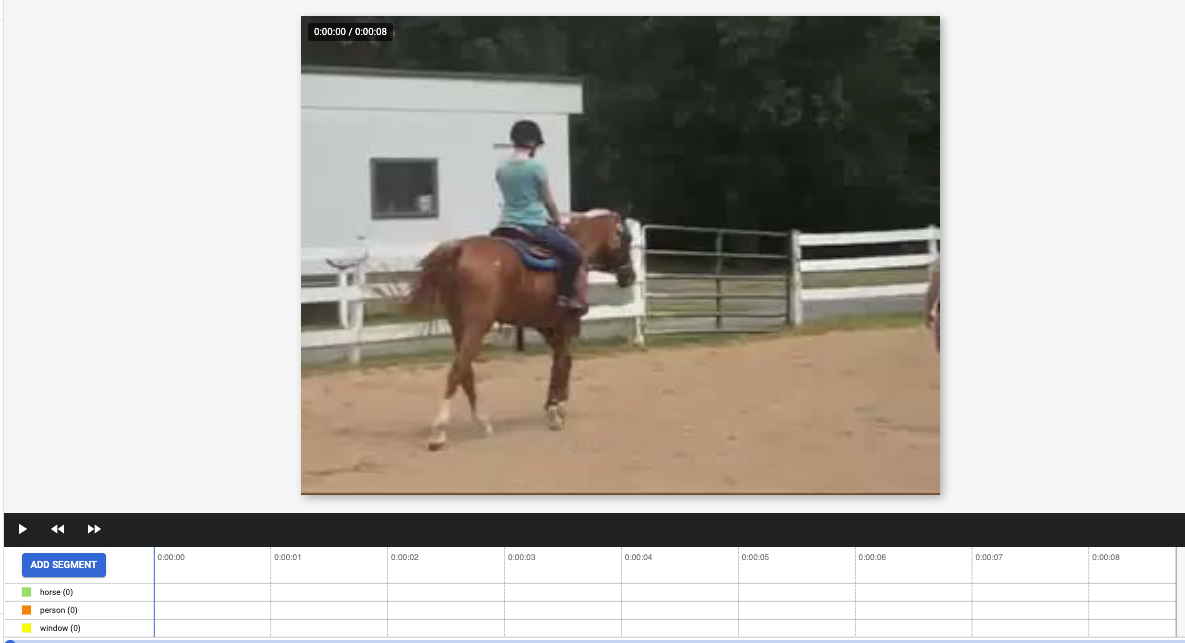
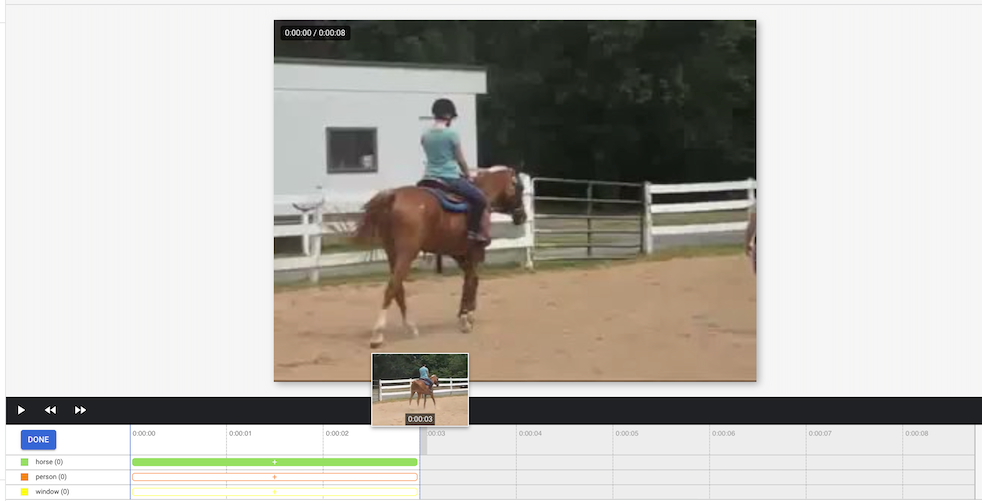
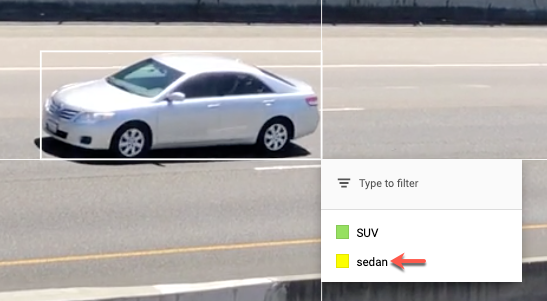
[[["이해하기 쉬움","easyToUnderstand","thumb-up"],["문제가 해결됨","solvedMyProblem","thumb-up"],["기타","otherUp","thumb-up"]],[["이해하기 어려움","hardToUnderstand","thumb-down"],["잘못된 정보 또는 샘플 코드","incorrectInformationOrSampleCode","thumb-down"],["필요한 정보/샘플이 없음","missingTheInformationSamplesINeed","thumb-down"],["번역 문제","translationIssue","thumb-down"],["기타","otherDown","thumb-down"]],["최종 업데이트: 2025-09-04(UTC)"],[],[],null,["# Label data using the Google Cloud console\n\nFor image and video data, you can import labeled or unlabeled data and\nadd labels using the Google Cloud console. You can also delete or add new\nlabels to existing labeled datasets.\n\nTo learn how to import your data, see the *Prepare data* page of the data type\nand objective that you're working with on the\n[Training overview](/vertex-ai/docs/training-overview#data) page. Continue with\nthe respective *Create dataset* page for your data type and objective.\n\nAfter creating the dataset and importing the unlabeled data, you will be in\n**Browse** mode. \n\n\u003cbr /\u003e\n\n\nHow to add labels\n-----------------\n\nInstructions for labeling objectives are provided here for each data type. \n\n### Image\n\n\nThe images you have just imported in the dataset are unlabeled, as expected. \n\n### Classification\n\n\nWhen in Browse mode, and the dataset with the unlabeled images is selected, you can see\nyour uploaded images.\n\n1. Click **Add new label** and enter your new label.\n2. Click **Done** . \n Repeat for each label you want to add.\n3. Select the image you want to label. \n The list of labels appears.\n4. Select the label you want to associate with the image.\n5. Click **Save**.\n\n### Classification\n\n\nWhen in **Browse** mode, and the dataset with the unlabeled images is selected, you\ncan see your uploaded images.\n\n1. Click **Add new label** and enter your new label.\n2. Click **Done** . \n Repeat for each label you want to add.\n3. Select the image you want to label. \n The list of labels appears.\n4. Select the label you want to associate with the image.\n5. Click **Save**.\n6. You can view the labels applied to each image in the **Browse** tab.\n\n### Object detection\n\n\nWhen in **Browse** mode, and the dataset with the unlabeled images is selected, you\ncan see your uploaded images.\n\n1. Click **Add new label** and enter your new label.\n2. Click **Done** . \n Repeat for each label you want to add.\n3. Select the image you want to label.\n4. The list of labels objects appears, if there are any.\n5. In the add annotation window, select the Add bounding box button to add an object bounding box to the image. \n6. After drawing a bounding box, a list of labels to apply to the object will appear. Choose the appropriate label. \n7. After you have added all labels and bounding boxes, click **Save** to update the image's annotations. \n\n### Video\n\n\nThe videos you have imported in the dataset are unlabeled, as expected.\n\n1. To navigate to your new dataset, click \"Datasets\" in the navigation menu. \n2. Select the dataset you want to add labels to. \n Dataset appears. \n\n### Action recognition\n\n\nWhen in **Browse** mode, and the dataset with the unlabeled videos is selected, you\nshould see your videos. \n\n1. Add label(s). \n2. Select a video and start viewing.\n3. When the action starts appearing that you want to identify, slowly progress through till you find the center or the most representative moment of the action using \"Next frame\" option.\n4. Click **Add annotation** . \n Your list of labels appears.\n5. Select the label you want for this video segment.\n6. Click **Save**.\n\n### Classification\n\n\nWhen the dataset with the unlabeled videos is selected, you\nwill see your videos. \n\n\n1. Add labels. \n2. Select the video you want to label. The video appears with your list of color-coded labels below.\n3. Navigate to starting point of segment. Click **Add segment** .\n 1. Select segment. Adjust to designate the segment to be used for training for your particular label: \n 2. Select label. You can select multiple labels for a segment. \n 3. Click **Done** , then **Save**.\n 4. Repeat steps to add another label to the same video with a different time segment. Here's an example of where two more labels were added: \n4. Return to **Datasets** list to repeat.\n\n### Object tracking\n\nWhen in **BROWSE** mode, and the dataset with the unlabeled videos is selected, you\nshould see your videos. \n\n\n1. Click **Add Label** and add the labels you plan to use (for example, \"sedan\", \"pickup\", \"SUV\").\n2. Click **Save** . If you need to add more labels later, click **Add new label** and **Save**.\n3. Select a video and start viewing.\n4. When an object appears that you want to track,\n 1. Stop the video.\n 2. Drag a bounding box from the upper left corner, down to the lower right corner. Be sure to make the box as tight as possible around the object. \n A list of labels appears to the lower right-hand side of the bounding box.\n 3. Select the appropriate label. \n **Note:** Note: You can always add more labels during this process. Be sure to save the added label so it shows up in the list going forward.\n 4. Click **Save**.\n\nWhat's next\n-----------\n\n- [Train your AutoML model using the Google Cloud console](/vertex-ai/docs/training/automl-console).\n- [Train your AutoML Edge model using the Google Cloud console](/vertex-ai/docs/training/automl-edge-console).\n (image and video only)\n\n- [Train your AutoML model using the Vertex AI API](/vertex-ai/docs/training/automl-api).\n\n- [Train your AutoML Edge model using the Vertex AI API](/vertex-ai/docs/training/automl-edge-api).\n (image and video only)"]]



 참고: 참고: 이 과정에서 언제든지 라벨을 추가할 수 있습니다. 앞으로 추가된 라벨이 목록에 표시될 수 있도록 추가된 라벨을 저장하세요.
참고: 참고: 이 과정에서 언제든지 라벨을 추가할 수 있습니다. 앞으로 추가된 라벨이 목록에 표시될 수 있도록 추가된 라벨을 저장하세요.