Depois de treinar um modelo, o AutoML Translation usa itens do conjunto TEST para avaliar a qualidade e a acurácia do novo modelo. O AutoML Translation expressa a qualidade do modelo por meio da pontuação Bilingua Evaluation Understudy (BLEU). Ela indica como o texto candidato é parecido com os de referência, com valores mais próximos ao que representa textos mais similares.
A pontuação BLEU fornece uma avaliação geral da qualidade do modelo. Você também pode avaliar a saída do modelo para itens de dados específicos exportando o conjunto TEST com as previsões do modelo. Os dados exportados incluem o texto de referência (do conjunto de dados original) e o texto candidato do modelo.
Use esses dados para avaliar a prontidão do seu modelo. Se você não está satisfeito com o nível de qualidade, convém adicionar outros pares de frases de treinamento (mais diversificados). Uma opção é adicionar outros pares de frases. Use o link Adicionar arquivos na barra de título. Depois de adicionar arquivos, treine o novo modelo. Basta clicar no botão Treinar novo modelo na página Treinar. Repita esse processo até atingir o nível suficiente de alta qualidade.
Como acessar a avaliação do modelo
IU da Web
Abra o console do AutoML Translation e clique no ícone de lâmpada ao lado de Modelos na barra de navegação à esquerda. Os modelos disponíveis são exibidos. Em cada modelo, as informações a seguir estão incluídas: conjunto de dados (em que o treinamento do modelo se baseia), origem e chegada (idioma) e modelo base (usado para treinar o modelo).
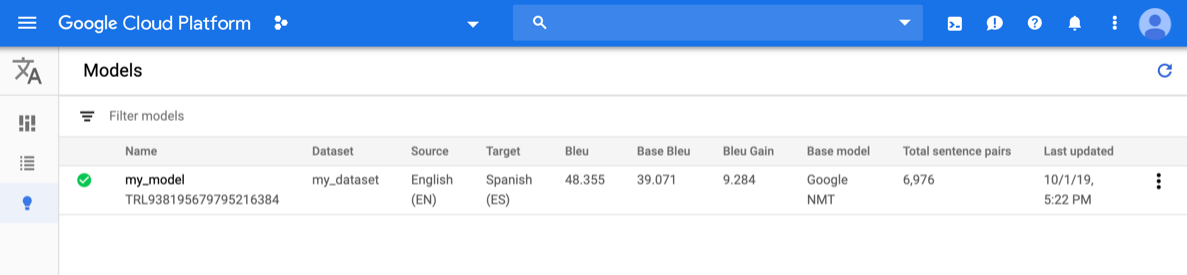
Para ver os modelos de outro projeto, selecione o projeto na lista suspensa na parte superior direita da barra de título.
Clique na linha do modelo que você quer avaliar.
A guia Prever será aberta.
Nela, você testa o modelo e vê os resultados dos modelos personalizado e do básico usados no treinamento.
Clique na guia Treinar logo abaixo da barra de título.
Quando o treinamento for concluído no modelo, o AutoML Translation mostrará as métricas de avaliação dele.
REST
Antes de usar os dados da solicitação abaixo, faça as substituições a seguir:
- model-name: pelo nome completo do modelo. Ele inclui o nome e o local do projeto e é semelhante a
projects/project-id/locations/us-central1/models/model-id. - project-id: pelo código do projeto do Google Cloud Platform
Método HTTP e URL:
GET https://automl.googleapis.com/v1/model-name/modelEvaluations
Para enviar a solicitação, expanda uma destas opções:
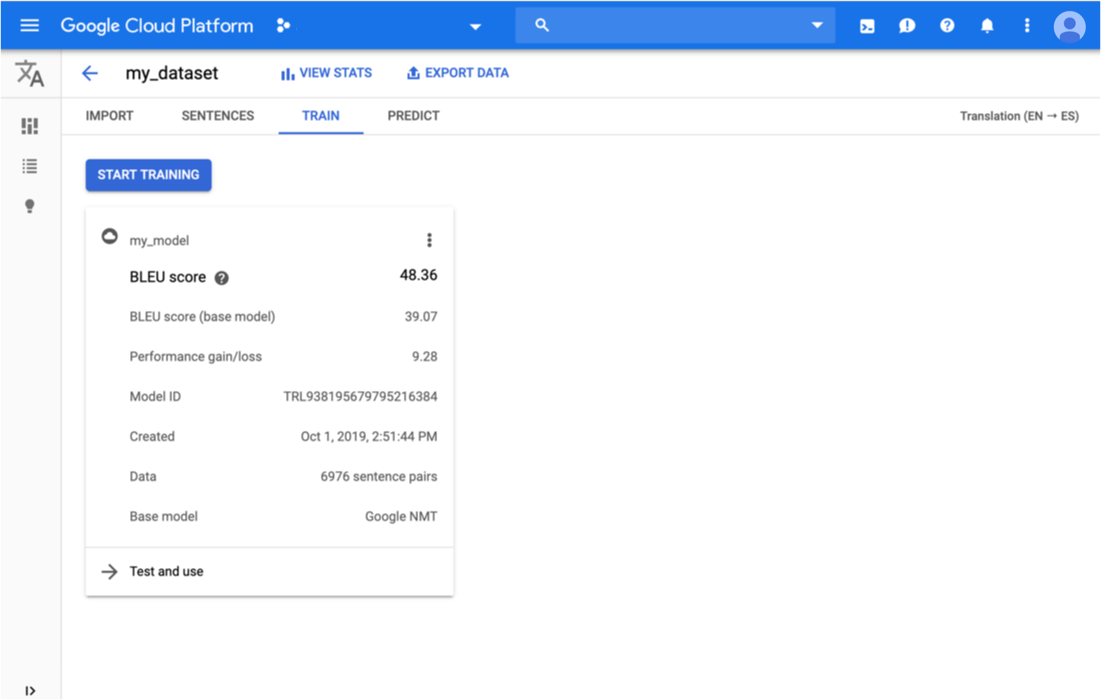
Você receberá uma resposta JSON semelhante a esta:
{
"modelEvaluation": [
{
"name": "projects/project-number/locations/us-central1/models/model-id/modelEvaluations/evaluation-id",
"createTime": "2019-10-02T00:20:30.972732Z",
"evaluatedExampleCount": 872,
"translationEvaluationMetrics": {
"bleuScore": 48.355409502983093,
"baseBleuScore": 39.071375131607056
}
}
]
}
Go
Para saber como instalar e usar a biblioteca de cliente da AutoML Translation, consulte Bibliotecas de cliente da AutoML Translation. Para mais informações, consulte a documentação de referência da API AutoML Translation em Go.
Para autenticar no AutoML Translation, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Java
Para saber como instalar e usar a biblioteca de cliente da AutoML Translation, consulte Bibliotecas de cliente da AutoML Translation. Para mais informações, consulte a documentação de referência da API AutoML Translation em Java.
Para autenticar no AutoML Translation, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Node.js
Para saber como instalar e usar a biblioteca de cliente da AutoML Translation, consulte Bibliotecas de cliente da AutoML Translation. Para mais informações, consulte a documentação de referência da API AutoML Translation em Node.js.
Para autenticar no AutoML Translation, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Python
Para saber como instalar e usar a biblioteca de cliente da AutoML Translation, consulte Bibliotecas de cliente da AutoML Translation. Para mais informações, consulte a documentação de referência da API AutoML Translation em Python.
Para autenticar no AutoML Translation, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Outras linguagens
C#: Siga as Instruções de configuração do C# na página das bibliotecas de cliente e acesse a Documentação de referência do AutoML Translation para .NET.
PHP : Siga as Instruções de configuração do PHP na página das bibliotecas de cliente e acesse Documentação de referência do AutoML Translation para PHP.
Ruby Siga as Instruções de configuração do Ruby na página das bibliotecas de cliente e acesse Documentação de referência do AutoML Translation para Ruby.
Como exportar dados de teste com previsões de modelo
Depois de treinar um modelo, o AutoML Translation usa itens do conjunto TEST para avaliar a qualidade e a acurácia desse modelo. No console do AutoML Translation, é possível exportar o conjunto TEST para ver como a saída do modelo se compara ao texto de referência do conjunto de dados original. O AutoML Translation salva um arquivo TSV no bucket do Google Cloud Storage, em que cada linha tem este formato:
Source sentence tab Reference translation tab Model candidate translation
IU da Web
Abra o Console do AutoML Translation e clique no ícone de lâmpada à esquerda de ModelsModelos", na barra de navegação à esquerda, para exibir os modelos disponíveis.
Para ver os modelos de outro projeto, selecione o projeto na lista suspensa na parte superior direita da barra de título.
Selecione o modelo.
Clique no botão Exportar dados na barra de título.
Insira o caminho completo do bucket do Google Cloud Storage em que você quer salvar o arquivo .tsv exportado.
É preciso usar um bucket associado ao projeto atual.
Escolha o modelo cujos dados de teste você quer exportar.
A lista suspensa Conjunto de testes com previsões do modelo lista os modelos treinados usando o mesmo conjunto de dados de entrada.
Clique em Exportar.
O AutoML Translation grava um arquivo chamado model-name
_evaluated.tsvno bucket especificado do Google Cloud Storage.
Avaliar e comparar modelos usando um novo conjunto de testes
No console do AutoML Translation, você pode reavaliar modelos existentes usando um novo conjunto de dados de teste. Em uma única avaliação, inclua até cinco modelos diferentes e compare os resultados.
Fazer upload dos dados de teste para o Cloud Storage valores
separados por tabulação (.tsv )
ou como uma apresentação eXchange de
memória de tradução
(.tmx).
O AutoML Translation avalia seus modelos em relação ao conjunto de testes e produz
pontuações de avaliação. É possível salvar os resultados para cada modelo como um arquivo
.tsv em um bucket do Cloud Storage, em que cada linha tem o seguinte
formato:
Source sentence tab Model candidate translation tab Reference translation
IU da Web
Abra o Console do AutoML Translation e clique em Modelos no painel de navegação à esquerda para exibir os modelos disponíveis.
Para ver os modelos de outro projeto, selecione o projeto na lista suspensa na parte superior direita da barra de título.
Selecione um dos modelos que você quer avaliar.
Clique na guia Avaliar logo abaixo da barra de título.
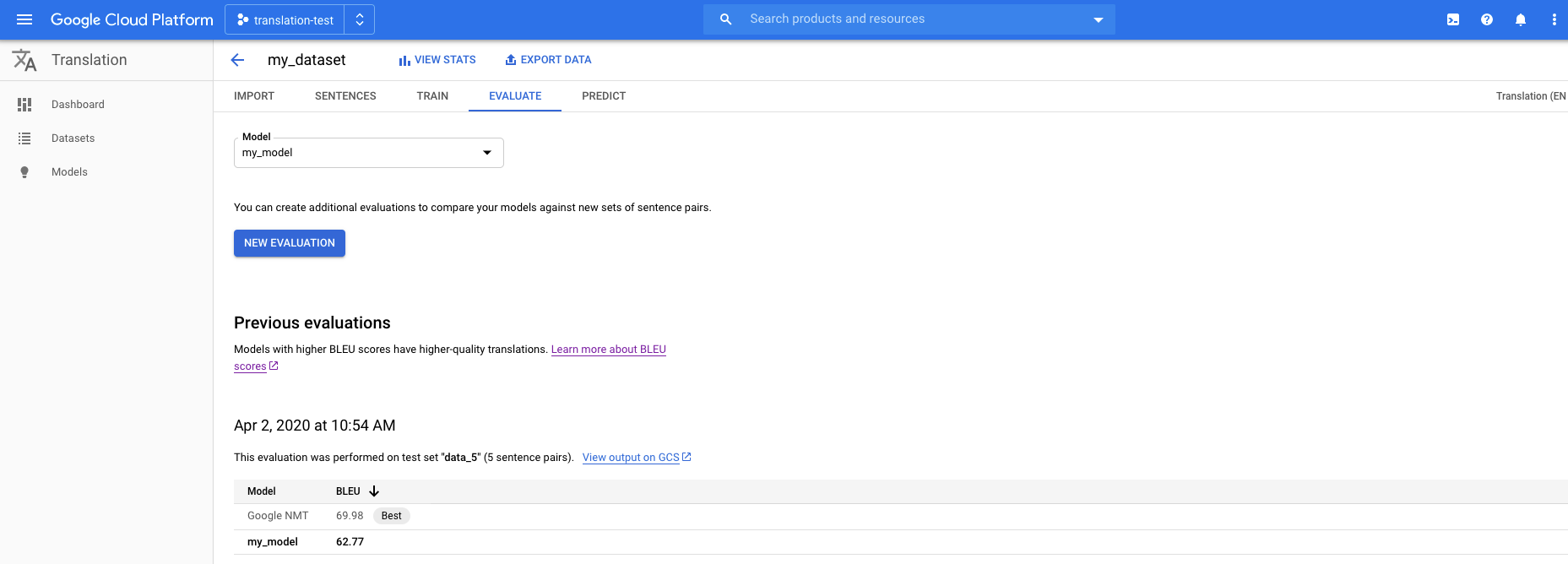
Na guia Avaliar, clique em Nova avaliação.
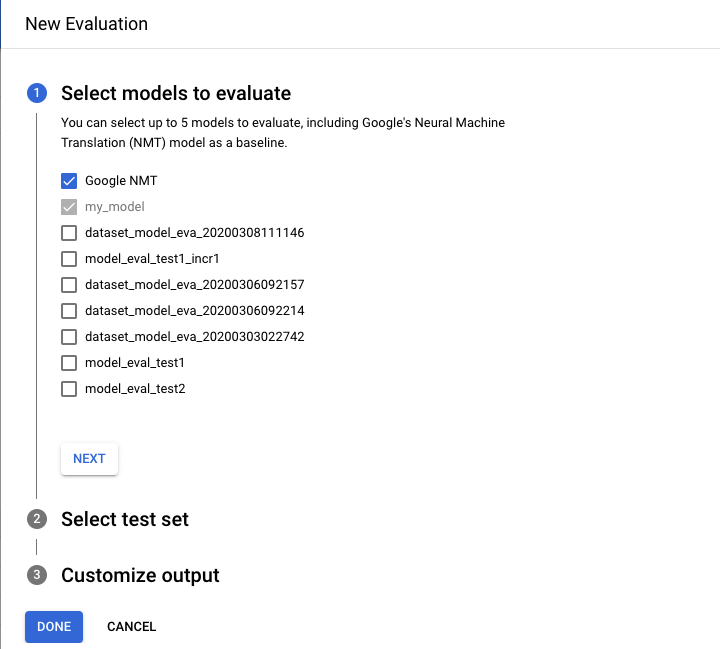
- Selecione os modelos que você quer avaliar e comparar. O modelo atual precisa ser selecionado, e o Google NMT é selecionado por padrão, que pode ser desmarcado.
- Especifique um nome para o nome do conjunto de teste para ajudá-lo a diferenciá-lo de outras avaliações e, em seguida, selecione seu novo conjunto de teste do Cloud Storage.
- Se você quiser exportar as previsões baseadas no seu conjunto de testes, especifique um intervalo do Cloud Storage em que os resultados serão armazenados (padrão por taxa de caracteres preços aplicáveis).
Clique em Concluído.
O AutoML Translation apresenta pontuações de avaliação em um formato de tabela no console após a conclusão da avaliação. É possível executar apenas uma avaliação por vez. Se você especificou um intervalo para armazenar os resultados da previsão, o AutoML Translation gravará arquivos chamados model-name_test-set-name
.tsvno bucket.
Como entender a pontuação BLEU
BLEU (BiLingual Evaluation Understudy) [em inglês] é uma métrica de avaliação automática do texto traduzido por máquina. A pontuação BLEU é um número entre zero e um que compara a similaridade do texto traduzido por máquina com um conjunto de traduções de referência de alta qualidade. O valor 0 significa que a saída da tradução de máquina não coincide com a tradução de referência (baixa qualidade). O valor 1 significa perfeita correspondência com as traduções de referência (alta qualidade).
As pontuações BLEU têm demonstrado boa correlação com a avaliação humana da qualidade das traduções. Mesmo tradutores humanos não atingem a pontuação perfeita de 1.
O AutoML expressa as pontuações BLEU em porcentagem, e não em decimal entre 0 e 1.
Interpretação
Não recomendamos tentar comparar as pontuações BLEU entre corpora e idiomas diferentes. Mesmo a comparação das pontuações BLEU para o mesmo corpus, mas números diferentes de traduções de referência, pode ser extremamente confusa.
No entanto, como orientação geral, a seguinte interpretação das pontuações BLEU (indicadas como porcentagens em vez de decimais) pode ser útil.
| Pontuação BLEU | Interpretação |
|---|---|
| < 10 | Praticamente inútil |
| 10 - 19 | Difícil de compreender o sentido |
| 20 - 29 | O sentido está claro, mas há erros gramaticais graves |
| 30 - 40 | Pode ser entendido como boas traduções |
| 40 - 50 | Traduções de alta qualidade |
| 50 - 60 | Traduções de qualidade muito alta, adequadas e fluentes |
| > 60 | Em geral, qualidade superior à humana |
É possível usar o gradiente de cor a seguir como escala geral para interpretação da pontuação BLEU:

Detalhes matemáticos
Em termos matemáticos, a pontuação BLEU é definida como:
com
\[ precision_i = \dfrac{\sum_{\text{snt}\in\text{Cand-Corpus}}\sum_{i\in\text{snt}}\min(m^i_{cand}, m^i_{ref})} {w_t^i = \sum_{\text{snt'}\in\text{Cand-Corpus}}\sum_{i'\in\text{snt'}} m^{i'}_{cand}} \]
onde
- \(m_{cand}^i\hphantom{xi}\) é a contagem de i-gram no candidato correspondente a tradução de referência
- \(m_{ref}^i\hphantom{xxx}\) é a contagem de i-gram na tradução de referência
- \(w_t^i\hphantom{m_{max}}\) é o número total de i-grams na tradução candidata
A fórmula consiste em duas partes: brevity penalty e n-gram overlap.
Brevity penalty
Penaliza com um decaimento exponencial as traduções geradas que são muito menores do que o tamanho da referência mais próxima. Ela compensa o fato de que a pontuação BLEU não tem um termo de recall.N-gram overlap
Conta quantos unigramas, bigramas, trigramas e quadrigramas (i=1,...,4) correspondem ao equivalente de "n-gram" nas traduções de referência. Esse termo funciona como uma métrica de precisão. Os unigramas consideram a adequação da tradução. Já os "n-grams" mais longos consideram a fluência. Para evitar contagem excessiva, as contagens de n-gram são recortadas para o valor máximo de n-gram que ocorre na referência (\(m_{ref}^n\)).
Exemplos
Calculando \(precision_1\)
Considere esta frase de referência e possível tradução:
Referência: the cat is on the mat
Tradução: the the the cat mat
A primeira etapa é contar as ocorrências de cada unigrama na referência e na possível tradução. Observe que a métrica BLEU faz distinção entre maiúsculas e minúsculas.
| Unigrama | \(m_{cand}^i\hphantom{xi}\) | \(m_{ref}^i\hphantom{xxx}\) | \(\min(m^i_{cand}, m^i_{ref})\) |
|---|---|---|---|
the |
3 | 2 | 2 |
cat |
1 | 1 | 1 |
is |
0 | 1 | 0 |
on |
0 | 1 | 0 |
mat |
1 | 1 | 1 |
O número total de unigramas no candidato (\(w_t^1\)) é 5, portanto, \(precision_1\) = (2 + 1 + 1)/5 = 0,8.
Como calcular a pontuação BLEU
Referência:
The NASA Opportunity rover is battling a massive dust storm on Mars .
Tradução 1:
The Opportunity rover is combating a big sandstorm on Mars .
Tradução 2:
A NASA rover is fighting a massive storm on Mars .
O exemplo acima é formado por uma única referência e duas possíveis traduções. As frases são tokenizadas antes de calcular a pontuação BLEU, conforme representado acima. Por exemplo, o ponto final é contado como um token separado.
Para calcular a pontuação BLEU de cada tradução, calculamos as estatísticas a seguir.
- N-gram precisions
A tabela a seguir contém as n-gram precisions de ambas as possíveis traduções. - Brevity penalty
É a mesma para os candidatos 1 e 2, já que as duas frases são formadas por 11 tokens. - Pontuação BLEU
Pelo menos um quadrigrama correspondente é necessário para atingir uma pontuação BLEU maior que 0. Como a possível tradução 1 não tem um quadrigrama correspondente, a pontuação BLEU dela é 0.
| Métrica | Candidato 1 | Candidato 2 |
|---|---|---|
| \(precision_1\) (1gram) | 11/8 | 9/11 |
| \(precision_2\) (2gram) | 4/10 | 5/10 |
| \(precision_3\) (3gram) | 2/9 | 2/9 |
| \(precision_4\) (4gram) | 0/8 | 1/8 |
| Brevity-Penalty | 0,83 | 0,83 |
| Pontuação BLEU | 0 | 0,27 |
Propriedades
A BLEU é uma métrica baseada em corpus
A métrica BLEU não apresenta bons resultados quando usada para avaliar frases individuais. No exemplo dado, as duas frases atingem pontuações BLEU muito baixas mesmo capturando grande parte do significado. Como as estatísticas de "n-gram" das frases individuais apresentam menor significado, por concepção, a pontuação BLEU é uma métrica com base no corpus. Ou seja, as estatísticas são acumuladas em um corpus inteiro na hora de calcular a pontuação. Não é possível fatorar a métrica BLEU definida acima em frases individuais.Não há distinção entre palavras de conteúdo e função
A métrica BLEU não distingue as palavras de conteúdo e função, ou seja, uma palavra de função solta, como "um", recebe a mesma penalidade de um nome "NASA" que é incorretamente substituído por "ESA".Baixa qualidade na captura de significado e gramática de uma frase
Uma única palavra solta, como "não", pode mudar a polaridade de uma frase. Além disso, o fato de considerar apenas "n-grams" menores que quadrigramas ignora as dependências de longo alcance. Portanto, a BLEU costuma impor somente uma pequena penalidade para frases gramaticalmente incorretas.Normalização e tokenização
Antes de calcular a pontuação BLEU, as possíveis traduções e as de referência são normalizadas e tokenizadas. A escolha das etapas de normalização e tokenização afeta consideravelmente a pontuação BLEU final.