Après avoir entraîné un modèle, AutoML Translation évalue sa qualité et sa précision à l'aide des éléments de l'ensemble de TEST. AutoML Translation exprime la qualité du modèle grâce à son score BLEU (Bilingual Evaluation Understudy), qui indique la similitude entre la traduction automatique et les textes de référence. Plus ce score est proche de 1, plus les textes sont similaires.
Le score BLEU fournit une évaluation globale de la qualité du modèle. Vous pouvez également évaluer la sortie du modèle pour des éléments de données spécifiques en exportant l'ensemble de TEST avec les prédictions du modèle. Les données exportées incluent à la fois le texte de référence (issu de l'ensemble de données d'origine) et la traduction automatique du modèle.
Évaluez l'état de préparation de votre modèle à l'aide de ces données. Si vous n'êtes pas satisfait de la qualité, envisagez d'ajouter des paires de phrases d'entraînement supplémentaires (et plus diversifiées). Vous pouvez effectuer cette opération en cliquant sur le lien Ajouter des fichiers dans la barre de titre. Une fois vos fichiers ajoutés, entraînez un nouveau modèle en cliquant sur le bouton Entraîner le nouveau modèle de la page Entraînement. Répétez le processus jusqu'à atteindre un niveau de qualité correct.
Obtenir l'évaluation du modèle
UI Web
Ouvrez la console AutoML Translation, puis cliquez sur l'icône représentant une ampoule à côté de Modèles dans la barre de navigation de gauche. Les modèles disponibles s'affichent. Pour chaque modèle, les informations suivantes sont incluses : l'ensemble de données (à partir duquel le modèle a été entraîné), la (langue) source, la (langue) cible et le modèle de base (utilisé pour entraîner le modèle).
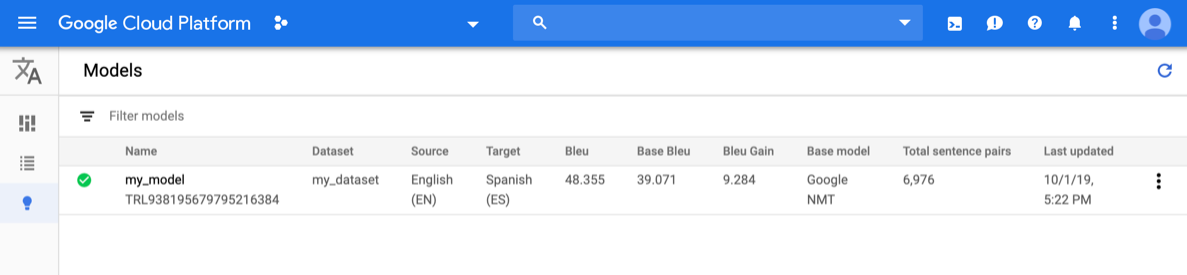
Pour afficher les modèles d'un autre projet, sélectionnez le projet dans la liste déroulante située en haut à droite de la barre de titre.
Cliquez sur la ligne du modèle que vous souhaitez évaluer.
L'onglet Predict (Prédiction) s'ouvre.
Dans cet onglet, vous pouvez tester votre modèle, et consulter les résultats du modèle personnalisé et du modèle de base qui a servi à l'entraînement.
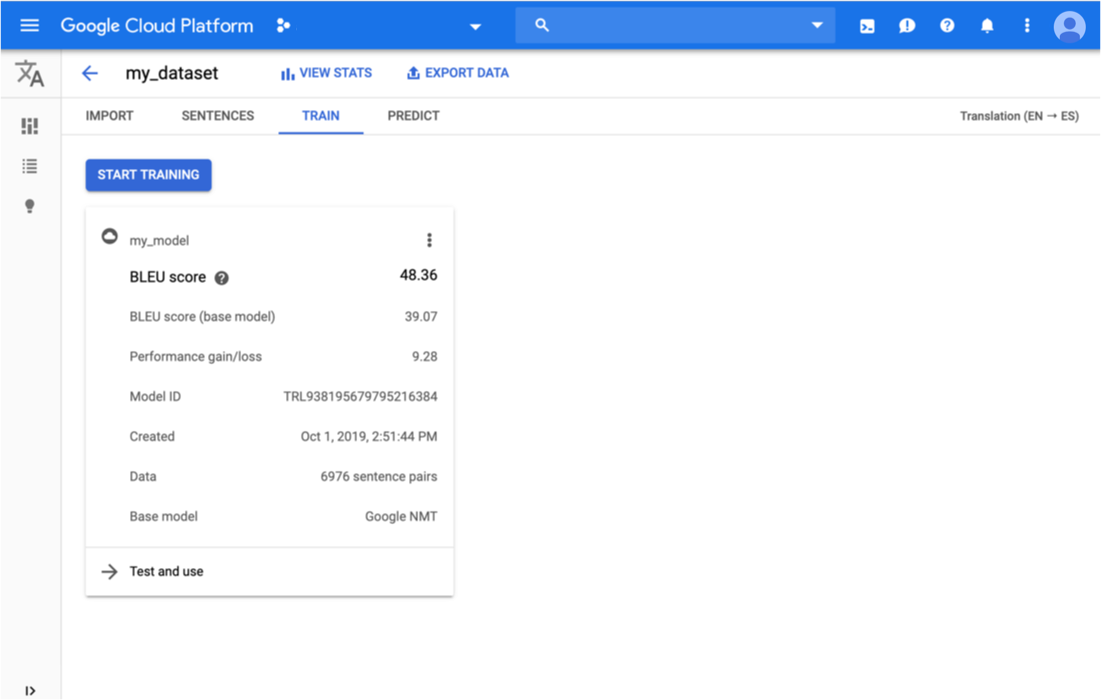
Cliquez sur l'onglet Entraînement situé juste en dessous de la barre de titre.
Une fois l'entraînement du modèle terminé, AutoML Translation affiche ses métriques d'évaluation.
REST
Avant d'utiliser les données de requête ci-dessous, effectuez les remplacements suivants :
- model-name : nom complet de votre modèle qui inclut le nom et l'emplacement de votre projet. Voici un exemple de nom de modèle :
projects/project-id/locations/us-central1/models/model-id. - project-id : ID de votre projet Google Cloud Platform
Méthode HTTP et URL :
GET https://automl.googleapis.com/v1/model-name/modelEvaluations
Pour envoyer votre requête, développez l'une des options suivantes :
Vous devriez recevoir une réponse JSON de ce type :
{
"modelEvaluation": [
{
"name": "projects/project-number/locations/us-central1/models/model-id/modelEvaluations/evaluation-id",
"createTime": "2019-10-02T00:20:30.972732Z",
"evaluatedExampleCount": 872,
"translationEvaluationMetrics": {
"bleuScore": 48.355409502983093,
"baseBleuScore": 39.071375131607056
}
}
]
}
Go
Pour savoir comment installer et utiliser la bibliothèque cliente pour AutoML Translation, consultez la page Bibliothèques clientes AutoML Translation. Pour en savoir plus, consultez la documentation de référence de l'API AutoML Translation en langage Go.
Pour vous authentifier auprès d'AutoML Translation, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Java
Pour savoir comment installer et utiliser la bibliothèque cliente pour AutoML Translation, consultez la page Bibliothèques clientes AutoML Translation. Pour en savoir plus, consultez la documentation de référence de l'API AutoML Translation en langage Java.
Pour vous authentifier auprès d'AutoML Translation, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Node.js
Pour savoir comment installer et utiliser la bibliothèque cliente pour AutoML Translation, consultez la page Bibliothèques clientes AutoML Translation. Pour en savoir plus, consultez la documentation de référence de l'API AutoML Translation en langage Node.js.
Pour vous authentifier auprès d'AutoML Translation, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Python
Pour savoir comment installer et utiliser la bibliothèque cliente pour AutoML Translation, consultez la page Bibliothèques clientes AutoML Translation. Pour en savoir plus, consultez la documentation de référence de l'API AutoML Translation en langage Python.
Pour vous authentifier auprès d'AutoML Translation, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Langages supplémentaires
C# : Veuillez suivre les instructions de configuration de C# sur la page des bibliothèques clientes, puis consultez la documentation de référence sur AutoML Translation pour .NET.
PHP : Veuillez suivre les instructions de configuration de PHP sur la page des bibliothèques clientes, puis consultez la documentation de référence sur AutoML Translation pour PHP.
Ruby : Veuillez suivre les instructions de configuration de Ruby sur la page des bibliothèques clientes, puis consultez la documentation de référence sur AutoML Translation pour Ruby.
Exporter des données de test avec les prédictions d'un modèle
Après avoir entraîné un modèle, AutoML Translation évalue sa qualité et sa précision à l'aide des éléments de l'ensemble de TEST. La console AutoML Translation vous permet d'exporter l'ensemble de TEST afin de comparer la sortie du modèle au texte de référence issu de l'ensemble de données d'origine. AutoML Translation enregistre un fichier TSV dans le bucket Google Cloud Storage, chaque ligne ayant le format suivant :
Source sentence tabulation Reference translation tabulation Model candidate translation
UI Web
Ouvrez la console AutoML Translation, puis cliquez sur l'icône représentant une ampoule à gauche de Models (Modèles) dans la barre de navigation de gauche pour afficher les modèles disponibles.
Pour afficher les modèles d'un autre projet, sélectionnez le projet dans la liste déroulante située en haut à droite de la barre de titre.
Sélectionnez le modèle.
Cliquez sur le bouton Exporter des données dans la barre de titre.
Entrez le chemin d'accès complet au bucket Google Cloud Storage dans lequel vous souhaitez enregistrer le fichier .tsv exporté.
Le bucket doit être associé au projet en cours.
Choisissez le modèle dont vous souhaitez exporter les données de TEST.
La liste déroulante Ensemble de test avec prédictions de modèle répertorie les modèles entraînés à l'aide du même ensemble de données en entrée.
Cliquez sur Exporter.
AutoML Translation écrit un fichier nommé model-name
_evaluated.tsvdans le bucket Google Cloud Storage spécifié.
Évaluer et comparer des modèles à l'aide d'un nouvel ensemble de test
Depuis la console AutoML Translation, vous pouvez réévaluer les modèles existants en utilisant un nouvel ensemble de données de test. Dans une même évaluation, vous pouvez inclure jusqu'à cinq modèles différents, puis comparer leurs résultats.
Importez vos données de test dans Cloud Storage en tant que fichier de valeurs séparées par des tabulations (.tsv) ou en tant que fichier d'Translation Memory eXchange (.tmx).
AutoML Translation évalue vos modèles par rapport à l'ensemble de test, puis génère des scores. Vous pouvez éventuellement enregistrer les résultats pour chaque modèle en tant que fichier .tsv dans un bucket Cloud Storage, chaque ligne ayant le format suivant :
Source sentence tab Model candidate translation tab Reference translation
UI Web
Ouvrez la console AutoML Translation et cliquez sur Models (Modèles) dans le volet de navigation de gauche pour afficher les modèles disponibles.
Pour afficher les modèles d'un autre projet, sélectionnez le projet dans la liste déroulante située en haut à droite de la barre de titre.
Sélectionnez l'un des modèles que vous souhaitez évaluer.
Cliquez sur l'onglet Evaluate (Évaluation) situé juste en dessous de la barre de titre.
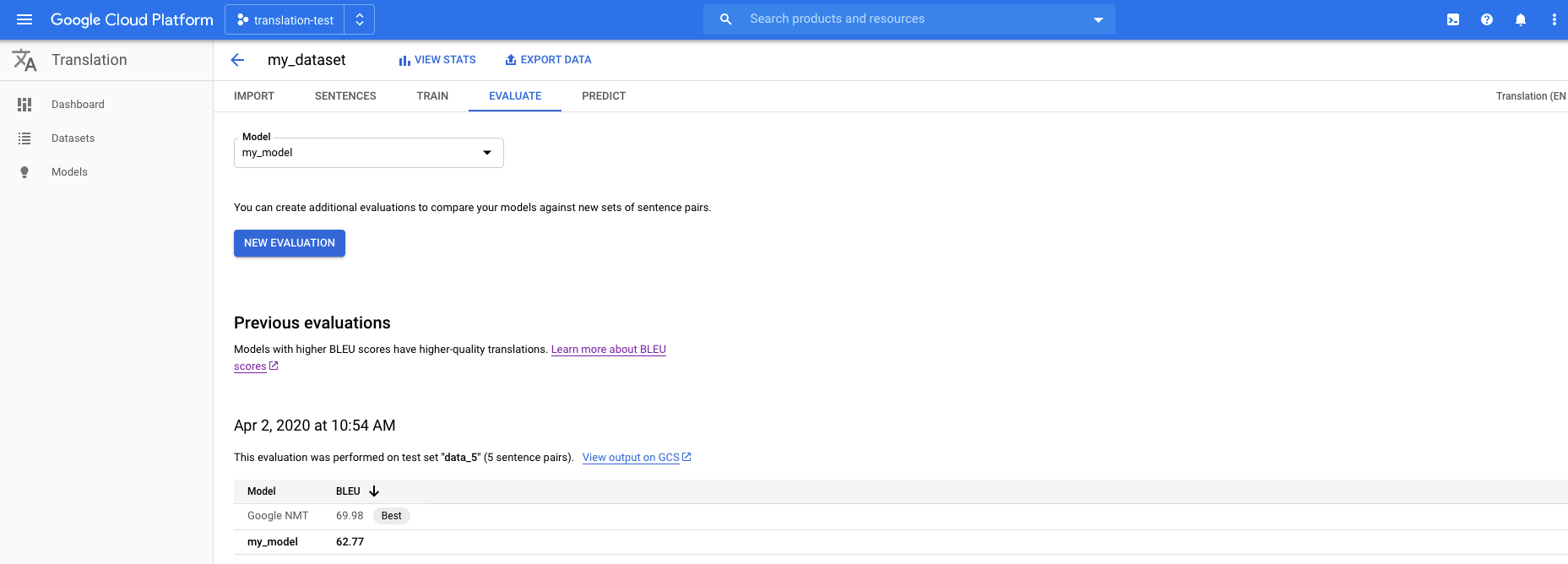
Dans l'onglet Évaluation, cliquez sur Nouvelle évaluation.
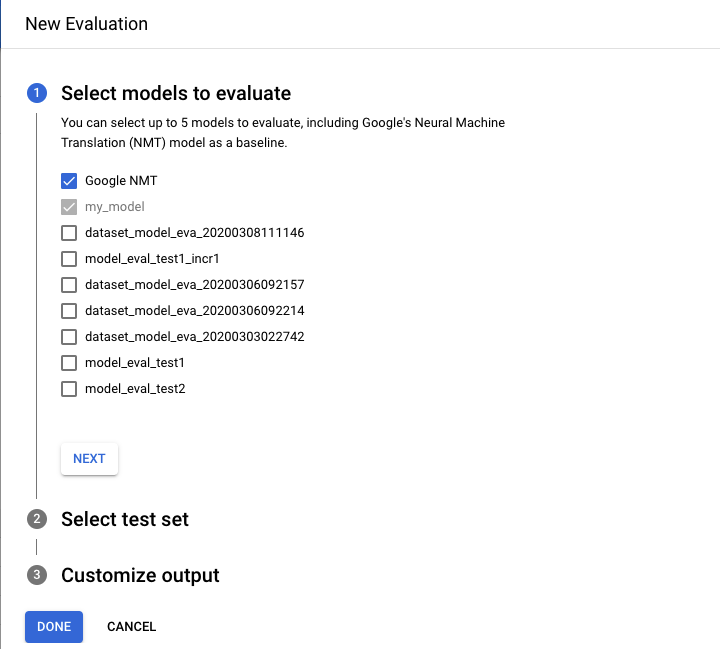
- Sélectionnez les modèles que vous souhaitez évaluer et comparer. Le modèle actuel doit être sélectionné. Google NMT est sélectionné par défaut et vous pouvez retirer cette sélection.
- Indiquez le Nom de l'ensemble de test afin de le distinguer des autres évaluations, puis sélectionnez votre nouvel ensemble de test à partir de Cloud Storage.
- Si vous souhaitez exporter les prédictions basées sur votre ensemble de test, spécifiez un bucket Cloud Storage dans lequel les résultats seront stockés (le tarif standard par caractère s'applique).
Cliquez sur OK.
AutoML Translation présente les scores d'évaluation sous forme de table dans la console une fois l'évaluation terminée. Vous ne pouvez exécuter qu'une seule évaluation à la fois. Si vous avez spécifié un bucket pour stocker les résultats de la prédiction, AutoML Translation écrit des fichiers nommés model-name_test-set-name
.tsvdans le bucket.
Comprendre le score BLEU
La métrique BLEU (BiLingual Evaluation Understudy) permet d'évaluer une traduction automatique. Le score BLEU est représenté par un nombre entre zéro et un, qui mesure la similitude entre un texte traduit automatiquement et un ensemble de traductions de référence de haute qualité. Une valeur égale à 0 indique que la traduction automatique ne correspond en rien à la traduction de référence (mauvaise qualité), tandis qu'une valeur égale à 1 signale une correspondance parfaite avec les traductions de référence (haute qualité).
Il a été démontré que les scores BLEU coïncident fortement avec ce qu'un humain peut penser de la qualité d'une traduction. Notez que même les traducteurs humains n'atteignent pas un score parfait de 1,0.
Plutôt que d'utiliser un nombre décimal compris entre 0 et 1, AutoML exprime les scores BLEU sous forme de pourcentage.
Interprétation
Nous vous déconseillons fortement d'essayer de comparer des scores BLEU entre plusieurs corpus et plusieurs langues. Même si vous comparez des scores BLEU pour un même corpus, mais avec un nombre de traductions de référence différent, le résultat peut se révéler extrêmement trompeur.
Toutefois, l'interprétation suivante des scores BLEU (exprimés en pourcentages et non en décimales) peut s'avérer utile à titre indicatif :
| Score BLEU | Interprétation |
|---|---|
| < 10 | Traductions presque inutiles |
| 10 à 19 | L'idée générale est difficilement compréhensible |
| 20 à 29 | L'idée générale apparaît clairement, mais le texte comporte de nombreuses erreurs grammaticales |
| 30 à 40 | Résultats compréhensibles à traductions correctes |
| 40 à 50 | Traductions de haute qualité |
| 50 à 60 | Traductions de très haute qualité, adéquates et fluides |
| > 60 | Qualité souvent meilleure que celle d'une traduction humaine |
Le dégradé de couleur suivant peut vous servir à interpréter le score BLEU de manière générale :

Explication mathématique
Mathématiquement, le score BLEU est défini de la manière suivante :
avec
\[ precision_i = \dfrac{\sum_{\text{snt}\in\text{Cand-Corpus}}\sum_{i\in\text{snt}}\min(m^i_{cand}, m^i_{ref})} {w_t^i = \sum_{\text{snt'}\in\text{Cand-Corpus}}\sum_{i'\in\text{snt'}} m^{i'}_{cand}} \]
Où :
- \(m_{cand}^i\hphantom{xi}\) est le nombre d'i-grammes dans la traduction automatique qui correspondent à la traduction de référence.
- \(m_{ref}^i\hphantom{xxx}\) est le nombre d'i-grammes dans la traduction de référence.
- \(w_t^i\hphantom{m_{max}}\) est le nombre total d'i-grammes dans la traduction automatique.
La formule se compose de deux parties : la pénalité de concision et la correspondance de n-grammes.
Pénalité de concision
La pénalité de concision pénalise les traductions générées qui sont trop courtes par rapport à la longueur de référence la plus proche, avec une décroissance exponentielle. Cette pénalité compense le fait que le score BLEU ne dispose pas de terme de rappel.Correspondance de n-grammes
La correspondance de n-grammes compte le nombre d'unigrammes, de bigrammes, de trigrammes et de quadrigrammes (i = 1,…,4) qui correspondent à leur équivalent de n-grammes au sein des traductions de référence. Ce terme agit comme une métrique de précision. Les unigrammes rendent compte de l'adéquation, tandis que les n-grammes plus longs rendent compte de la fluidité de la traduction. Pour éviter tout surdénombrement, le nombre de n-grammes est réduit au nombre maximal de n-grammes présents dans la référence (\(m_{ref}^n\)).
Examples
Calcul \(precision_1\)
Prenons cette phrase de référence ainsi que cette traduction automatique :
Référence : the cat is on the mat
Traduction automatique : the the the cat mat
La première étape consiste à compter le nombre d'occurrences de chaque unigramme dans la référence et dans la traduction automatique. Notez que la métrique BLEU est sensible à la casse.
| Unigram | \(m_{cand}^i\hphantom{xi}\) | \(m_{ref}^i\hphantom{xxx}\) | \(\min(m^i_{cand}, m^i_{ref})\) |
|---|---|---|---|
the |
3 | 2 | 2 |
cat |
1 | 1 | 1 |
is |
0 | 1 | 0 |
on |
0 | 1 | 0 |
mat |
1 | 1 | 1 |
Le nombre total d'unigrammes dans la traduction automatique (\(w_t^1\)) est de 5, soit \(precision_1\) = (2 + 1 + 1)/5 = 0,8.
Calculer le score BLEU
Référence :
The NASA Opportunity rover is battling a massive dust storm on Mars .
Traduction automatique 1 :
The Opportunity rover is combating a big sandstorm on Mars .
Traduction automatique 2 :
A NASA rover is fighting a massive storm on Mars .
L'exemple ci-dessus comprend un texte de référence et deux traductions automatiques. Avant que le score BLEU soit calculé tel que décrit ci-dessus, les phrases sont tokenisées. Par exemple, le point final est comptabilisé comme un jeton distinct.
Afin de calculer le score BLEU de chaque traduction, nous calculons les statistiques suivantes :
- Précision des n-grammes
Le tableau suivant indique la précision des n-grammes pour les deux traductions automatiques. - Pénalité de concision
La pénalité de concision est la même pour les traductions automatiques 1 et 2, car les deux phrases se composent de 11 jetons. - Score BLEU
Notez que pour obtenir un score supérieur à 0, les textes doivent posséder au moins un quadrigramme correspondant. Comme aucun quadrigramme ne correspond dans la traduction automatique 1, son score BLEU est de 0.
| Métrique | Traduction automatique 1 | Traduction automatique 2 |
|---|---|---|
| \(precision_1\) (1gram) | 8/11 | 9/11 |
| \(precision_2\) (2gram) | 4/10 | 5/10 |
| \(precision_3\) (3gram) | 2/9 | 2/9 |
| \(precision_4\) (4gram) | 0/8 | 1/8 |
| Pénalité de concision | 0,83 | 0,83 |
| Score BLEU | 0,0 | 0,27 |
Propriétés
La métrique BLEU est basée sur un corpus
La métrique BLEU ne permet pas d'évaluer efficacement des phrases individuelles. Ainsi, bien qu'ils restituent en grande partie le sens d'origine, les deux exemples de phrases présentent des scores BLEU très bas. Comme les statistiques relatives aux n-grammes s'avèrent moins pertinentes pour les phrases individuelles, la métrique BLEU est, par nature, une métrique basée sur un corpus. En d'autres termes, les statistiques sont obtenues à partir d'un corpus entier lors du calcul du score. Notez que la métrique BLEU définie ci-dessus ne peut pas être factorisée pour des phrases individuelles.Aucune distinction n'est faite entre le contenu et les mots-outils
La métrique BLEU ne fait pas la distinction entre le contenu et les mots-outils. Par exemple, la pénalité liée à l'omission d'un mot-outil tel que "un" est identique à la pénalité appliquée en cas de remplacement du terme "NASA" par "ESA".La métrique BLEU restitue mal le sens et la grammaticalité d'une phrase
L'omission d'un seul terme tel que "non" peut inverser le sens d'une phrase. De même, en ne prenant en compte que les n-grammes où n ≤ 4, la métrique BLEU ignore les longues dépendances. Elle n'impose donc souvent qu'une faible pénalité aux phrases non grammaticales.Normalisation et tokenisation
Avant le calcul du score BLEU, les traductions de référence et les traductions automatiques sont normalisées et tokenisées. Le choix des étapes de normalisation et de tokenisation affecte considérablement le score BLEU final.