This page provides a conceptual overview of exporting trace data using Cloud Trace. You might want to export trace data for the following reasons:
- To store trace data for a period longer than the default retention period of 30 days.
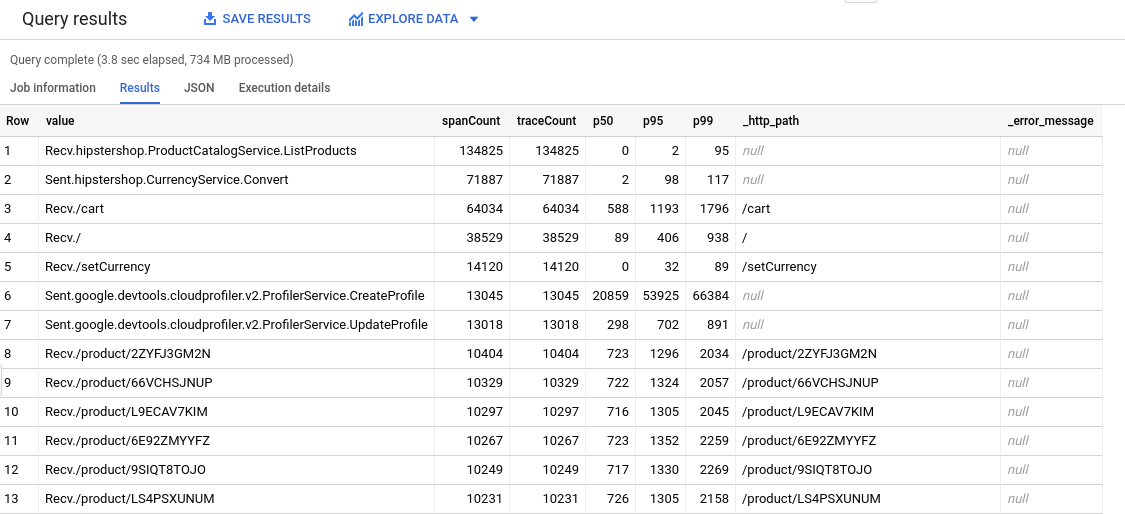
To let you use BigQuery tools to analyze your trace data. For example, using BigQuery, you can identify span counts and quantiles. For information on the query used to generate the following table, see HipsterShop query.
How exports work
Exporting involves creating a sink for a Google Cloud project. A sink defines a BigQuery dataset as the destination.
You can create a sink by using the Cloud Trace API or by using the Google Cloud CLI.
Sink properties and terminology
Sinks are defined for a Google Cloud project and have the following properties:
Name: A name for the sink. For example, a name might be:
"projects/PROJECT_NUMBER/traceSinks/my-sink"
where
PROJECT_NUMBERis the sink's Google Cloud project number andmy-sinkis the sink identifier.Parent: The resource in which you create the sink. The parent must be a Google Cloud project:
"projects/PROJECT_ID"
The
PROJECT_IDcan either be a Google Cloud project identifier or number.Destination: A single place to send trace spans. Trace supports exporting traces to BigQuery. The destination can be sink's Google Cloud project or any other Google Cloud project that is in the same organization.
For example, a valid destination is:
bigquery.googleapis.com/projects/DESTINATION_PROJECT_NUMBER/datasets/DATASET_ID
where
DESTINATION_PROJECT_NUMBERis the Google Cloud project number of the destination, andDATASET_IDis the BigQuery dataset identifier.Writer Identity: A service account name. The export destination's owner must give this service account permissions to write to the export destination. When exporting traces, Trace adopts this identity for authorization. For increased security, new sinks get a unique service account:
export-PROJECT_NUMBER-GENERATED_VALUE@gcp-sa-cloud-trace.iam.gserviceaccount.com
where
PROJECT_NUMBERis your Google Cloud project number, in Hex, andGENERATED_VALUEis a randomly generated value.You don't create, own, or manage the service account that is identified by the writer identity of a sink. When you create a sink, Trace creates the service account that the sink requires. This service account isn't included in the list of service accounts for your project until it has at least one Identity and Access Management binding. You add this binding when you configure a sink destination.
For information on using the writer identity, see destination permissions.
How sinks work
Every time a trace span arrives in a project, Trace exports a copy of the span.
Traces that Trace received before the sink was created cannot be exported.
Access control
To create or modify a sink, you must have one of the following Identity and Access Management roles:
- Trace Admin
- Trace User
- Project Owner
- Project Editor
For more information, see Access control.
To export traces to a destination, the sink's writer service account must be permitted to write to the destination. For more information about writer identities, see Sink properties on this page.
Quotas and limits
Cloud Trace utilizes the BigQuery streaming API to send trace spans to the destination. Cloud Trace batches API calls. Cloud Trace doesn't implement a retry or throttling mechanism. Trace spans might not be exported successfully if the amount of data exceeds the destination quotas.
For details on BigQuery quotas and limits, see Quotas and limits.
Pricing
Exporting traces doesn't incur Cloud Trace charges. However, you might incur BigQuery charges. See BigQuery pricing for more information.
Estimating your costs
BigQuery charges for data ingestion and storage. To estimate your monthly BigQuery costs, do the following:
Estimate the total number of trace spans that are ingested in a month.
For information about how to view usage, see View usage by billing account.
Estimate the streaming requirements based on the number of trace spans ingested.
Each span is written to a table row. Each row in BigQuery requires at least 1024 bytes. Therefore, a lower bound on your BigQuery streaming requirements is to assign 1024 bytes to each span. For example, if your Google Cloud project ingested 200 spans, then those spans require at least 20,400 bytes for the streaming insert.
Use the Pricing calculator to estimate your BigQuery costs due to storage, streaming inserts, and queries.
Viewing and managing your BigQuery usage
You can use Metrics Explorer to view your BigQuery usage. You can also create an alerting policy that notifies you if your BigQuery usage exceeds predefined limits. The following table contains the settings to create an alerting policy. You can use the settings in the target pane table when creating a chart or when using Metrics Explorer.
To create an alerting policy that triggers when the ingested BigQuery metrics exceed a user-defined level, use the following settings.
| New condition Field |
Value |
|---|---|
| Resource and Metric | In the Resources menu, select BigQuery Dataset. In the Metric categories menu, select Storage. Select a metric from the Metrics menu. Metrics specific to usage include Stored bytes, Uploaded bytes,
and Uploaded bytes billed. For a full list of available metrics, see
BigQuery metrics.
|
| Filter | project_id: Your Google Cloud project ID. dataset_id: Your dataset ID. |
| Across time series Time series group by |
dataset_id: Your dataset ID. |
| Across time series Time series aggregation |
sum |
| Rolling window | 1 m |
| Rolling window function | mean |
| Configure alert trigger Field |
Value |
|---|---|
| Condition type | Threshold |
| Alert trigger | Any time series violates |
| Threshold position | Above threshold |
| Threshold value | You determine the acceptable value. |
| Retest window | 1 minute |
What's next
To configure a sink, see Exporting traces.