Questo tutorial mostra come fare lo scale up dell'addestramento del tuo modello da un singolo Cloud TPU (v2-8 o v3-8) a un pod Cloud TPU utilizzando la configurazione del nodo TPU. Gli acceleratori Cloud TPU in un pod TPU sono connessi da interconnessioni ad alta larghezza di banda, il che li rende efficienti nell'ambito dello scale up dei job di addestramento.
Per ulteriori informazioni sulle offerte di pod Cloud TPU, consulta la pagina del prodotto Cloud TPU o questa presentazione Cloud TPU.
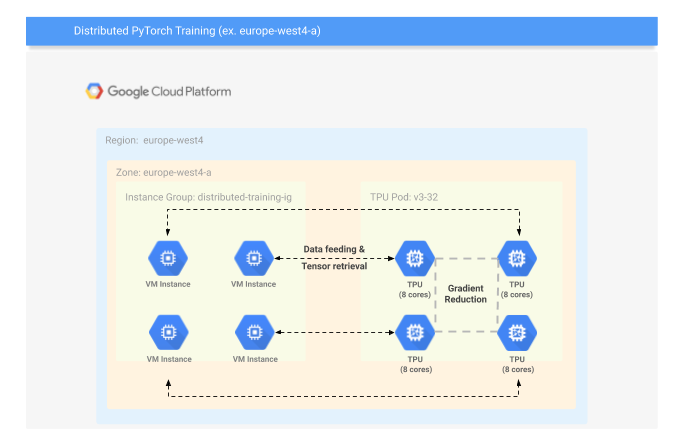
Il seguente diagramma fornisce una panoramica della configurazione del cluster distribuito. Un gruppo di istanze di VM è connesso a un pod TPU. È necessaria una VM per ogni gruppo di 8 core TPU. Le VM alimentano i dati ai core TPU e all'intero addestramento si verifica nel pod TPU.
Obiettivi
- Configurare un gruppo di istanze Compute Engine e un pod Cloud TPU per l'addestramento con PyTorch/XLA
- Esegui l'addestramento PyTorch/XLA su un pod Cloud TPU
Prima di iniziare
Prima di iniziare l'addestramento distribuito sui pod Cloud TPU, verifica che il tuo modello venga addestrato su un singolo dispositivo Cloud TPU v2-8 o v3-8. Se il modello presenta problemi di prestazioni significativi su un singolo dispositivo, consulta le best practice e le guide per la risoluzione dei problemi.
Dopo aver completato l'addestramento del tuo singolo dispositivo TPU, segui questi passaggi per la configurazione e l'addestramento su un pod Cloud TPU:
[Facoltativo] Acquisisci l'immagine di un disco VM in un'immagine VM.
Verifica le regole firewall per consentire la comunicazione tra VM.
Configura il comando gcloud
Configura il tuo progetto Google Cloud con gcloud:
Crea una variabile per l'ID del tuo progetto.
export PROJECT_ID=project-id
Imposta il tuo ID progetto come progetto predefinito in gcloud
gcloud config set project ${PROJECT_ID}
La prima volta che esegui questo comando in una nuova VM di Cloud Shell, viene visualizzata una pagina Authorize Cloud Shell. Fai clic su Authorize in fondo alla pagina per consentire a gcloud di effettuare chiamate API con le tue credenziali.
Configura la zona predefinita con gcloud:
gcloud config set compute/zone europe-west4-a
[Facoltativo] Acquisisci l'immagine di un disco VM
Puoi utilizzare l'immagine disco della VM che hai utilizzato per addestrare la singola TPU (che ha già il set di dati, i pacchetti installati e così via). Prima di creare un'immagine, arresta la VM utilizzando il comando gcloud:
gcloud compute instances stop vm-name
A questo punto, crea un'immagine VM utilizzando il comando gcloud:
gcloud compute images create image-name \ --source-disk instance-name \ --source-disk-zone europe-west4-a \ --family=torch-xla \ --storage-location europe-west4
Crea un modello di istanza da un'immagine VM
Crea un modello di istanza predefinito. Quando crei un modello di istanza, puoi utilizzare l'immagine VM creata nel passaggio precedente OPPURE l'immagine PyTorch/XLA pubblica fornita da Google. Per creare un modello di istanza, utilizza il comando gcloud:
gcloud compute instance-templates create instance-template-name \ --machine-type n1-standard-16 \ --image-project=${PROJECT_ID} \ --image=image-name \ --scopes=https://www.googleapis.com/auth/cloud-platform
Crea un gruppo di istanze dal tuo modello di istanza
gcloud compute instance-groups managed create instance-group-name \ --size 4 \ --template template-name \ --zone europe-west4-a
Accedi tramite SSH alla tua VM di Compute Engine
Dopo aver creato il gruppo di istanze, utilizza SSH per connetterti a una delle istanze (VM) del tuo gruppo di istanze. Utilizza il comando seguente per elencare tutte le istanze dell'istanza che raggruppano il comando gcloud:
gcloud compute instance-groups list-instances instance-group-name
SSH in una delle istanze elencate dal comando list-instances.
gcloud compute ssh instance-name --zone=europe-west4-a
Verifica che le VM nel gruppo di istanze possano comunicare tra loro
Utilizza il comando nmap per verificare le VM nel gruppo di istanze che possono comunicare tra loro. Esegui il comando nmap dalla VM a cui sei connesso, sostituendo instance-name con il nome dell'istanza di un'altra VM nel tuo gruppo di istanze.
(vm)$ nmap -Pn -p 8477 instance-name
Starting Nmap 7.40 ( https://nmap.org ) at 2019-10-02 21:35 UTC Nmap scan report for pytorch-20190923-n4tx.c.jysohntpu.internal (10.164.0.3) Host is up (0.00034s latency). PORT STATE SERVICE 8477/tcp closed unknown
Finché il campo STATE non indica filtrato, le regole firewall sono impostate correttamente.
Crea un pod di Cloud TPU
gcloud compute tpus create tpu-name \ --zone=europe-west4-a \ --network=default \ --accelerator-type=v2-32 \ --version=pytorch-1.13
Eseguire l'addestramento distribuito sul pod
Dalla finestra della sessione VM, esporta il nome Cloud TPU e attiva l'ambiente conda.
(vm)$ export TPU_NAME=tpu-name
(vm)$ conda activate torch-xla-1.13
Esegui lo script di addestramento:
(torch-xla-1.13)$ python -m torch_xla.distributed.xla_dist \ --tpu=$TPU_NAME \ --conda-env=torch-xla-1.13 \ --env XLA_USE_BF16=1 \ --env ANY_OTHER=ENV_VAR \ -- python /usr/share/torch-xla-1.13/pytorch/xla/test/test_train_mp_imagenet.py \ --fake_data
Una volta eseguito il comando precedente, dovresti vedere un output simile al seguente (nota che stai utilizzando --fake_data). L'addestramento richiede circa 1/2 ora su un pod TPU v3-32.
2020-08-06 02:38:29 [] Command to distribute: "python" "/usr/share/torch-xla-nightly/pytorch/xla/test/test_train_mp_imagenet.py" "--fake_data"
2020-08-06 02:38:29 [] Cluster configuration: {client_workers: [{10.164.0.43, n1-standard-96, europe-west4-a, my-instance-group-hm88}, {10.164.0.109, n1-standard-96, europe-west4-a, my-instance-group-n3q2}, {10.164.0.46, n1-standard-96, europe-west4-a, my-instance-group-s0xl}, {10.164.0.49, n1-standard-96, europe-west4-a, my-instance-group-zp14}], service_workers: [{10.131.144.61, 8470, v3-32, europe-west4-a, pytorch-nightly, my-tpu-slice}, {10.131.144.59, 8470, v3-32, europe-west4-a, pytorch-nightly, my-tpu-slice}, {10.131.144.58, 8470, v3-32, europe-west4-a, pytorch-nightly, my-tpu-slice}, {10.131.144.60, 8470, v3-32, europe-west4-a, pytorch-nightly, my-tpu-slice}]}
2020-08-06 02:38:31 10.164.0.43 [0] % Total % Received % Xferd Average Speed Time Time Time Current
2020-08-06 02:38:31 10.164.0.43 [0] Dload Upload Total Spent Left Speed
100 19 100 19 0 0 2757 0 --:--:-- --:--:-- --:--:-- 3166
2020-08-06 02:38:34 10.164.0.43 [0] % Total % Received % Xferd Average Speed Time Time Time Current
2020-08-06 02:38:34 10.164.0.43 [0] Dload Upload Total Spent Left Speed
100 19 100 19 0 0 2623 0 --:--:-- --:--:-- --:--:-- 2714
2020-08-06 02:38:37 10.164.0.46 [2] % Total % Received % Xferd Average Speed Time Time Time Current
2020-08-06 02:38:37 10.164.0.46 [2] Dload Upload Total Spent Left Speed
100 19 100 19 0 0 2583 0 --:--:-- --:--:-- --:--:-- 2714
2020-08-06 02:38:37 10.164.0.49 [3] % Total % Received % Xferd Average Speed Time Time Time Current
2020-08-06 02:38:37 10.164.0.49 [3] Dload Upload Total Spent Left Speed
100 19 100 19 0 0 2530 0 --:--:-- --:--:-- --:--:-- 2714
2020-08-06 02:38:37 10.164.0.109 [1] % Total % Received % Xferd Average Speed Time Time Time Current
2020-08-06 02:38:37 10.164.0.109 [1] Dload Upload Total Spent Left Speed
100 19 100 19 0 0 2317 0 --:--:-- --:--:-- --:--:-- 2375
2020-08-06 02:38:40 10.164.0.46 [2] % Total % Received % Xferd Average Speed Time Time Time Current
2020-08-06 02:38:40 10.164.0.49 [3] % Total % Received % Xferd Average Speed Time Time Time Current
2020-08-06 02:38:40 10.164.0.46 [2] Dload Upload Total Spent Left Speed
2020-08-06 02:38:40 10.164.0.49 [3] Dload Upload Total Spent Left Speed
100 19 100 19 0 0 2748 0 --:--:-- --:--:-- --:--:-- 3166
100 19 100 19 0 0 2584 0 --:--:-- --:--:-- --:--:-- 2714
2020-08-06 02:38:40 10.164.0.109 [1] % Total % Received % Xferd Average Speed Time Time Time Current
2020-08-06 02:38:40 10.164.0.109 [1] Dload Upload Total Spent Left Speed
100 19 100 19 0 0 2495 0 --:--:-- --:--:-- --:--:-- 2714
2020-08-06 02:38:43 10.164.0.49 [3] % Total % Received % Xferd Average Speed Time Time Time Current
2020-08-06 02:38:43 10.164.0.49 [3] Dload Upload Total Spent Left Speed
100 19 100 19 0 0 2654 0 --:--:-- --:--:-- --:--:-- 2714
2020-08-06 02:38:43 10.164.0.43 [0] % Total % Received % Xferd Average Speed Time Time Time Current
2020-08-06 02:38:43 10.164.0.43 [0] Dload Upload Total Spent Left Speed
100 19 100 19 0 0 2784 0 --:--:-- --:--:-- --:--:-- 3166
2020-08-06 02:38:43 10.164.0.46 [2] % Total % Received % Xferd Average Speed Time Time Time Current
2020-08-06 02:38:43 10.164.0.46 [2] Dload Upload Total Spent Left Speed
100 19 100 19 0 0 2691 0 --:--:-- --:--:-- --:--:-- 3166
2020-08-06 02:38:43 10.164.0.109 [1] % Total % Received % Xferd Average Speed Time Time Time Current
2020-08-06 02:38:43 10.164.0.109 [1] Dload Upload Total Spent Left Speed
100 19 100 19 0 0 2589 0 --:--:-- --:--:-- --:--:-- 2714
2020-08-06 02:38:57 10.164.0.109 [1] ==> Preparing data..
2020-08-06 02:38:57 10.164.0.109 [1] | Training Device=xla:0/14 Epoch=1 Step=0 Loss=6.87500 Rate=258.47 GlobalRate=258.47 Time=02:38:57
2020-08-06 02:38:57 10.164.0.109 [1] ==> Preparing data..
2020-08-06 02:38:57 10.164.0.109 [1] | Training Device=xla:0/15 Epoch=1 Step=0 Loss=6.87500 Rate=149.45 GlobalRate=149.45 Time=02:38:57
2020-08-06 02:38:57 10.164.0.43 [0] ==> Preparing data..
2020-08-06 02:38:57 10.164.0.43 [0] Epoch 1 train begin 02:38:52
2020-08-06 02:38:57 10.164.0.43 [0] | Training Device=xla:1/0 Epoch=1 Step=0 Loss=6.87500 Rate=25.72 GlobalRate=25.72 Time=02:38:57
2020-08-06 02:38:57 10.164.0.43 [0] ==> Preparing data..
2020-08-06 02:38:57 10.164.0.43 [0] | Training Device=xla:0/6 Epoch=1 Step=0 Loss=6.87500 Rate=89.01 GlobalRate=89.01 Time=02:38:57
2020-08-06 02:38:57 10.164.0.43 [0] ==> Preparing data..
2020-08-06 02:38:57 10.164.0.43 [0] | Training Device=xla:0/1 Epoch=1 Step=0 Loss=6.87500 Rate=64.15 GlobalRate=64.15 Time=02:38:57
2020-08-06 02:38:57 10.164.0.43 [0] ==> Preparing data..
2020-08-06 02:38:57 10.164.0.43 [0] | Training Device=xla:0/2 Epoch=1 Step=0 Loss=6.87500 Rate=93.19 GlobalRate=93.19 Time=02:38:57
2020-08-06 02:38:57 10.164.0.43 [0] ==> Preparing data..
2020-08-06 02:38:57 10.164.0.43 [0] | Training Device=xla:0/7 Epoch=1 Step=0 Loss=6.87500 Rate=58.78 GlobalRate=58.78 Time=02:38:57
2020-08-06 02:38:57 10.164.0.109 [1] ==> Preparing data..
2020-08-06 02:38:57 10.164.0.109 [1] Epoch 1 train begin 02:38:56
2020-08-06 02:38:57 10.164.0.109 [1] | Training Device=xla:1/8 Epoch=1 Step=0 Loss=6.87500 Rate=100.43 GlobalRate=100.43 Time=02:38:57
2020-08-06 02:38:57 10.164.0.109 [1] ==> Preparing data..
2020-08-06 02:38:57 10.164.0.109 [1] | Training Device=xla:0/13 Epoch=1 Step=0 Loss=6.87500 Rate=66.83 GlobalRate=66.83 Time=02:38:57
2020-08-06 02:38:57 10.164.0.109 [1] ==> Preparing data..
2020-08-06 02:38:57 10.164.0.109 [1] | Training Device=xla:0/11 Epoch=1 Step=0 Loss=6.87500 Rate=64.28 GlobalRate=64.28 Time=02:38:57
2020-08-06 02:38:57 10.164.0.109 [1] ==> Preparing data..
2020-08-06 02:38:57 10.164.0.109 [1] | Training Device=xla:0/10 Epoch=1 Step=0 Loss=6.87500 Rate=73.17 GlobalRate=73.17 Time=02:38:57
2020-08-06 02:38:57 10.164.0.109 [1] ==> Preparing data..
2020-08-06 02:38:57 10.164.0.109 [1] | Training Device=xla:0/9 Epoch=1 Step=0 Loss=6.87500 Rate=27.29 GlobalRate=27.29 Time=02:38:57
2020-08-06 02:38:57 10.164.0.109 [1] ==> Preparing data..
2020-08-06 02:38:57 10.164.0.109 [1] | Training Device=xla:0/12 Epoch=1 Step=0 Loss=6.87500 Rate=110.29 GlobalRate=110.29 Time=02:38:57
2020-08-06 02:38:57 10.164.0.46 [2] ==> Preparing data..
2020-08-06 02:38:57 10.164.0.46 [2] | Training Device=xla:0/20 Epoch=1 Step=0 Loss=6.87500 Rate=100.85 GlobalRate=100.85 Time=02:38:57
2020-08-06 02:38:57 10.164.0.46 [2] ==> Preparing data..
2020-08-06 02:38:57 10.164.0.46 [2] | Training Device=xla:0/22 Epoch=1 Step=0 Loss=6.87500 Rate=93.52 GlobalRate=93.52 Time=02:38:57
2020-08-06 02:38:57 10.164.0.46 [2] ==> Preparing data..
2020-08-06 02:38:57 10.164.0.46 [2] | Training Device=xla:0/23 Epoch=1 Step=0 Loss=6.87500 Rate=165.86 GlobalRate=165.86 Time=02:38:57
Esegui la pulizia
Per evitare che al tuo Account Google Cloud vengano addebitati costi relativi alle risorse utilizzate in questo tutorial, elimina il progetto che contiene le risorse oppure mantieni il progetto ed elimina le singole risorse.
Disconnettiti dalla VM di Compute Engine:
(vm)$ exit
Elimina il gruppo di istanze:
gcloud compute instance-groups managed delete instance-group-name
Elimina il tuo pod TPU:
gcloud compute tpus delete ${TPU_NAME} --zone=europe-west4-a
Elimina il modello di gruppo di istanze:
gcloud compute instance-templates delete instance-template-name
[Facoltativo] Elimina l'immagine disco di VM:
gcloud compute images delete image-name
Passaggi successivi
Prova le collaborazioni di PyTorch:
- Introduzione a PyTorch su Cloud TPU
- Addestramento MNIST sulle TPU
- Addestramento di ResNet18 sulle TPU con set di dati Cifar10
- Inferenza con il modello ResNet50 preaddestrato
- Trasferimento rapido dello stile neurale
- Formazione MultiCore AlexNet su Fashion MNIST
- Addestramento single core alexnet su moda MNIST