Profila il modello sui nodi Cloud TPU
La profilazione del modello ti consente di ottimizzare le prestazioni dell'addestramento sulle Cloud TPU. Per eseguire il profiling del modello, utilizza TensorBoard e il plug-in TensorBoard Cloud TPU. Per le istruzioni di installazione, consulta le istruzioni di installazione di TensorBoard.
Per ulteriori informazioni sull'utilizzo di TensorBoard con uno dei framework supportati, consulta i seguenti documenti:
- Guida alle prestazioni di TensorFlow
- Guida al rendimento di PyTorch
- Guida al rendimento della piattaforma JAX
Prerequisiti
TensorBoard è installato come parte di TensorFlow. TensorFlow è installato per impostazione predefinita nei nodi Cloud TPU. Puoi anche installare TensorFlow manualmente. In ogni caso, potrebbero essere necessarie alcune dipendenze aggiuntive. Installa tramite in esecuzione:
(vm)$ pip3 install --user -r /usr/share/models/official/requirements.txt
Installa il plug-in TensorBoard per Cloud TPU
Accedi tramite SSH al nodo TPU:
$ gcloud compute ssh your-vm --zone=your-zone
Esegui questi comandi:
pip3 install --upgrade "cloud-tpu-profiler>=2.3.0" pip3 install --user --upgrade -U "tensorboard>=2.3" pip3 install --user --upgrade -U "tensorflow>=2.3"
Acquisizione di un profilo
Puoi acquisire un profilo utilizzando l'interfaccia utente di TensorBoard o in modo programmatico.
Acquisisci un profilo utilizzando TensorBoard
All'avvio di TensorBoard, viene avviato un server web. Quando apri il browser all'URL TensorBoard, viene visualizzata una pagina web. La pagina web ti consente di acquisire manualmente un profilo e visualizzarne i dati.
Avvia il server di TensorFlow Profiler
tf.profiler.experimental.server.start(6000)
Viene avviato il server di profilazione di TensorFlow sulla VM TPU.
Inizia il tuo script di addestramento
Esegui lo script di addestramento e attendi finché non viene visualizzato un output che indica che il modello è
in fase di addestramento attivo. Il risultato dipende dal codice e dal modello. Cerca
simile a Epoch 1/100. In alternativa, puoi accedere alla pagina di Cloud TPU
Nella console Google Cloud, seleziona la tua TPU e visualizza il grafico di utilizzo della CPU. Mentre
non viene mostrato l'utilizzo della TPU, ma è un buon indicatore del fatto che
durante l'addestramento del modello.
Avvia il server TensorBoard
Apri una nuova finestra del terminale e accedi tramite SSH alla VM TPU con il port forwarding. Questo consente al browser locale di comunicare con il server TensorBoard in esecuzione della VM TPU.
gcloud compute tpus execution-groups ssh your-vm --zone=us-central1-a --ssh-flag="-4 -L 9001:localhost:9001"
Esegui TensorBoard nella finestra del terminale appena aperta e specifica la directory
in cui TensorBoard può scrivere dati di profilazione con il flag --logdir. Ad esempio:
TPU_LOAD_LIBRARY=0 tensorboard --logdir your-model-dir --port 9001
TensorBoard avvia un server web e visualizza il relativo URL:
Serving TensorBoard on localhost; to expose to the network, use a proxy or pass --bind_all TensorBoard 2.3.0 at http://localhost:9001/ (Press CTRL+C to quit)
Apri un browser web e vai all'URL visualizzato nell'output di TensorBoard. Marca Assicurati che TensorBoard abbia caricato completamente i dati di profilazione facendo clic sul pulsante di ricarica nell'angolo in alto a destra della pagina TensorBoard. Per impostazione predefinita, la pagina TensorBoard viene visualizzata con la scheda Scalari selezionata.
Acquisisci un profilo sui nodi TPU
- Seleziona PROFILO dal menu a discesa nella parte superiore dello schermo.
- Seleziona il pulsante ACQUISTA PROFILO
- Seleziona il pulsante di opzione TPU Name (Nome TPU)
- Digita il nome della TPU
- Seleziona il pulsante ACQUISISCI.
Acquisire un profilo in modo programmatico
La modalità di acquisizione di un profilo tramite programmazione dipende dal framework ML utilizzato.
Se usi TensorFlow, puoi avviare e arrestare il profiler utilizzando
tf.profiler.experimental.start() e tf.profiler.experimental.stop()
rispettivamente. Per ulteriori informazioni, consulta la guida al miglioramento delle prestazioni di TensorFlow.
Se usi JAX, usa jax.profiler.start_trace() e jax.profiler.stop_trace()
per avviare e arrestare il profiler. Per ulteriori informazioni, consulta Profilazione dei programmi JAX.
Problemi comuni del profilo di acquisizione
A volte, quando provi a acquisire una traccia, potresti visualizzare messaggi come quelli riportati di seguito:
No trace event is collected after xx attempt(s). Perhaps, you want to try again
(with more attempts?).Tip: increase number of attempts with --num_tracing_attempts.
Failed to capture profile: empty trace result
Questo può accadere se la TPU non sta eseguendo attivamente calcoli, viene il passo sta richiedendo troppo tempo o per altri motivi. Se vedi questo messaggio, prova a procedere nel seguente modo:
- Prova ad acquisire un profilo dopo che sono state eseguite alcune epoche.
- Prova ad aumentare la durata della profilazione nel profilo di acquisizione di TensorBoard . È possibile che un passaggio di addestramento stia richiedendo troppo tempo.
- Assicurati che la VM e la TPU abbiano la stessa versione TF.
Visualizza i dati del profilo con TensorBoard
La scheda Profilo viene visualizzata dopo aver acquisito alcuni dati del modello. Potrebbe essere necessario fare clic sul pulsante di ricarica nell'angolo in alto a destra della pagina di TensorBoard. Una volta che i dati sono disponibili, fai clic sulla scheda Profilo per visualizzare una selezione di strumenti utili per l'analisi del rendimento:
- Pagina Panoramica
- Visualizzatore tracce (solo browser Chrome)
- Visualizzatore traccia streaming (solo browser Chrome)
Visualizzatore di tracce
Il visualizzatore Trace è uno strumento di analisi delle prestazioni di Cloud TPU disponibile in Profilo. Lo strumento utilizza il visualizzatore di profilazione degli eventi di traccia di Chrome in modo che funzioni solo nel browser Chrome.
Nel visualizzatore Trace viene mostrata una sequenza temporale che mostra:
- Durate delle operazioni eseguite dal modello TensorFlow .
- La parte del sistema (TPU o macchina host) che ha eseguito un'operazione. In genere, la macchina host esegue operazioni di Infeed, che vengono pre-elaborate i dati di addestramento e li trasferisce alla TPU, mentre la TPU esegue durante l'addestramento del modello.
Il visualizzatore Trace consente di identificare i problemi di prestazioni del modello, di adottare le misure necessarie per risolverli. Ad esempio, a un livello generale, puoi identificare se l'infeed o l'addestramento del modello occupa la maggior parte del tempo. Se esamini più da vicino, puoi identificare le operazioni TensorFlow che richiedono più tempo per essere eseguite.
Tieni presente che lo strumento di visualizzazione dei tracciati è limitato a 1 milione di eventi per Cloud TPU. Se è necessario valutare più eventi, usa il visualizzatore di tracce di flusso .
Interfaccia di Trace Viewer
Per aprire il visualizzatore tracce, vai a TensorBoard e fai clic sulla scheda Profilo nella parte superiore dello schermo e scegli trace_viewer dal menu a discesa Strumenti. Viene visualizzato il visualizzatore con l'esecuzione più recente:
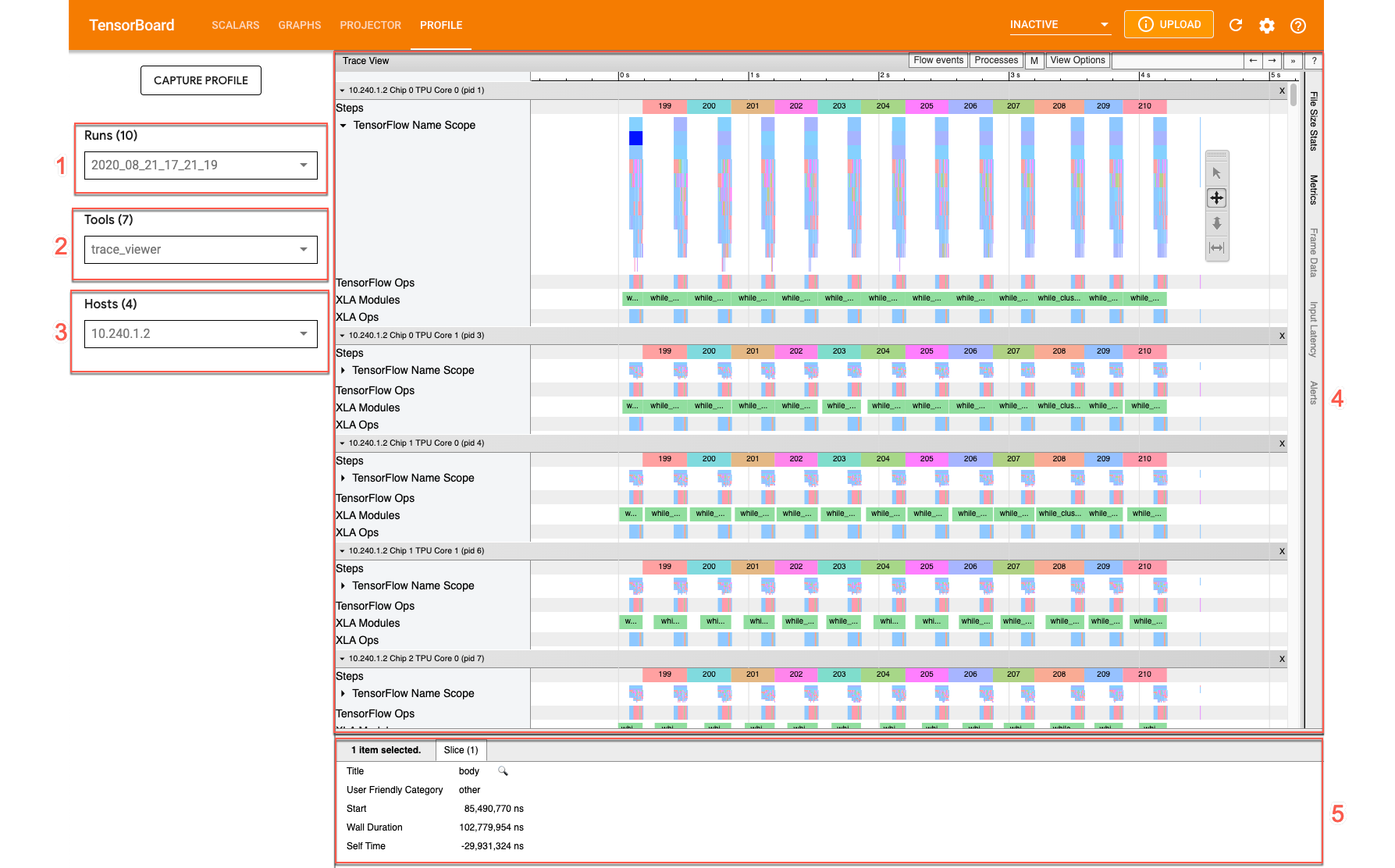
Questa schermata contiene i seguenti elementi principali (contrassegnati da numeri sopra):
- Menu a discesa Esecuzioni. Contiene tutte le esecuzioni per le quali hai le informazioni di traccia acquisite. La visualizzazione predefinita è la più recente ma puoi aprire il menu a discesa per selezionarne un'altra.
- Menu a discesa Strumenti. Seleziona strumenti di profilazione diversi.
- Menu a discesa Host. Consente di selezionare un host contenente un insieme Cloud TPU.
- Riquadro della sequenza temporale. Mostra le operazioni eseguite da Cloud TPU e dalla macchina ospitante nel tempo.
- Riquadro dei dettagli. Mostra informazioni aggiuntive sulle operazioni selezionate nel riquadro Spostamenti.
Di seguito è riportata una panoramica più approfondita del riquadro della sequenza temporale:
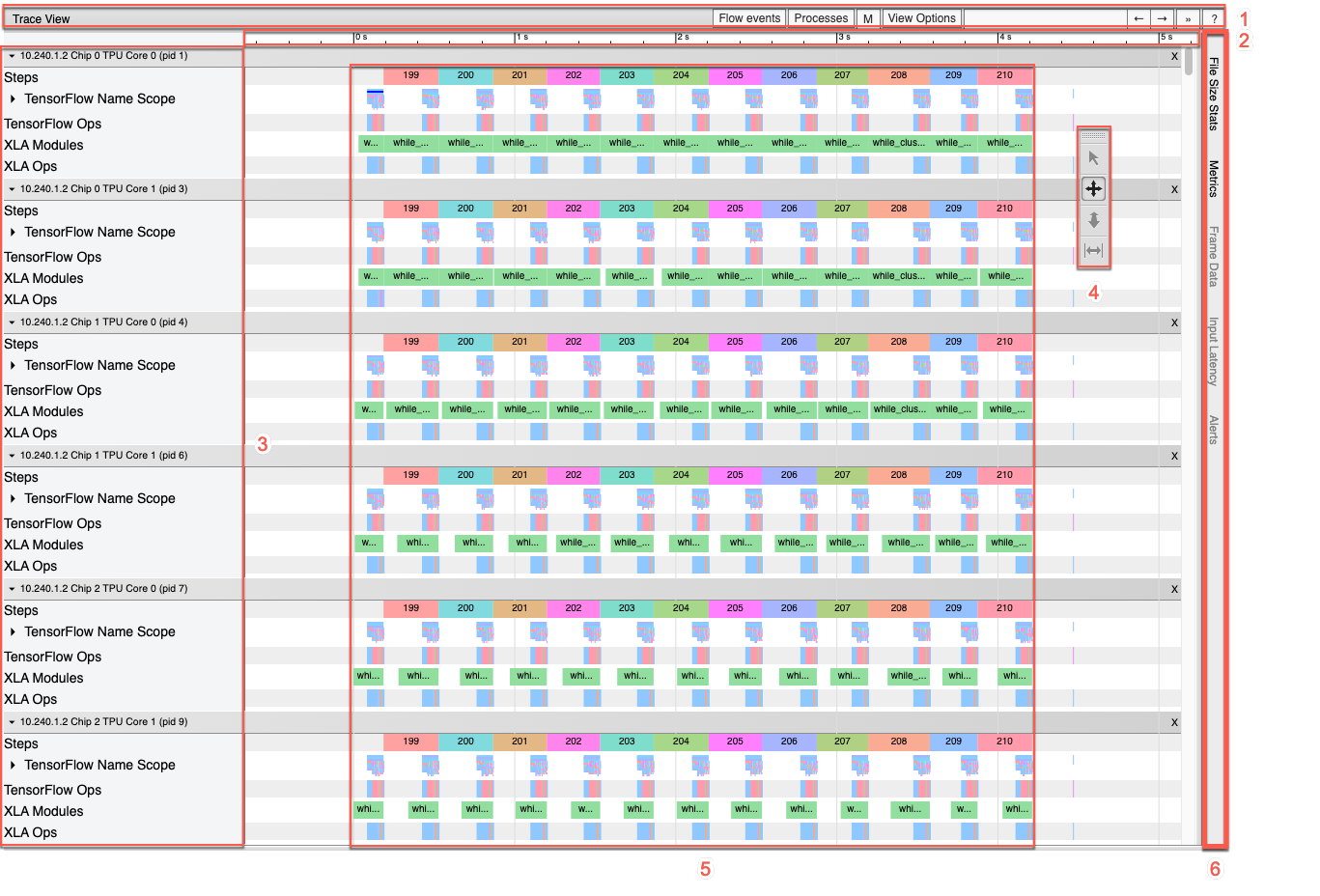
Il riquadro Spostamenti contiene i seguenti elementi:
- Barra superiore. Contiene vari controlli ausiliari.
- Asse temporale. Mostra l'ora relativa all'inizio della traccia.
- Etichette delle sezioni e delle tracce. Ogni sezione contiene più tracce e ha un triangolo a sinistra su cui puoi fare clic per espandere e comprimere la sezione. Esiste una sezione per ogni elemento di elaborazione del sistema.
- Selettore strumenti. Contiene vari strumenti per interagire con il visualizzatore di traccia.
- Eventi. che mostrano l'orario durante il quale è stata eseguita un'operazione la durata dei meta-eventi, come le fasi di addestramento.
- Barra delle schede verticale. Questo non ha uno scopo utile per Cloud TPU. La barra fa parte dello strumento di visualizzazione delle tracce per uso generale fornito da Chrome, che viene utilizzato per una serie di attività di analisi delle prestazioni.
Sezioni e canali
Lo strumento di visualizzazione dei tracciati contiene le seguenti sezioni:
- Una sezione per ogni nodo TPU, etichettata con il numero del chip TPU
e il nodo TPU all'interno del chip (ad esempio, "Chip 2: TPU Core 1"). Ogni sezione del nodo TPU contiene i seguenti canali:
- Passaggio. Mostra la durata dei passaggi di addestramento in esecuzione sulla TPU.
- TensorFlow Ops. Mostra le operazioni TensorFlow eseguite sulla TPU.
- XLA Ops. Mostra le operazioni XLA eseguite sulla TPU. Ogni operazione viene tradotta in una o più operazioni XLA. Il compilatore XLA traduce le operazioni XLA nel codice eseguito sulla TPU.)
- Una sezione per i thread in esecuzione sulla CPU della macchina host, etichettata come "Thread host". La sezione contiene una traccia per ogni CPU . Nota: puoi ignorare le informazioni visualizzate accanto alla sezione etichette.
Selettore strumento Timeline
Puoi interagire con la visualizzazione della cronologia utilizzando il selettore degli strumenti della cronologia in TensorBoard. Puoi fare clic su uno strumento della sequenza temporale o utilizzare scorciatoie da tastiera per attivare ed evidenziare uno strumento. Per spostare il selettore dello strumento della sequenza temporale, fai clic nell'area tratteggiata in alto e poi trascina il selettore dove vuoi.
Utilizza gli strumenti per la cronologia come segue:
|
Strumento di selezione Fai clic su un evento per selezionarlo o trascina per selezionare più eventi. Nel riquadro dei dettagli vengono visualizzate ulteriori informazioni sull'evento o sugli eventi selezionati (nome, ora di inizio e durata). |
|
Strumento di panoramica Trascina per eseguire la panoramica della visualizzazione della cronologia orizzontalmente e verticalmente. |
|
Strumento Zoom Trascina verso l'alto per aumentare lo zoom o verso il basso per diminuire lo zoom lungo l'orizzontale (tempo) . La posizione orizzontale del cursore del mouse determina il centro intorno al quale avviene lo zoom. Nota: lo strumento Zoom presenta un bug noto per cui lo zoom rimane attivo. se rilasci il pulsante del mouse mentre il cursore del mouse si trova fuori dalla sequenza temporale vista. In questo caso, fai clic brevemente sulla visualizzazione della cronologia per interrompere eseguire lo zoom. |
|
Strumento di temporizzazione Trascina in orizzontale per contrassegnare un intervallo di tempo. La lunghezza dell'intervallo apparirà sull'asse del tempo. Per regolare l'intervallo, trascinane le estremità. Per cancellare il valore fai clic in un punto qualsiasi della visualizzazione cronologica. Tieni presente che l'intervallo rimane contrassegnato se selezioni uno degli altri strumenti. |




Grafici
TensorBoard fornisce una serie di visualizzazioni o grafici del modello e delle sue prestazioni. Utilizza i grafici insieme al visualizzatore di traccia o al visualizzatore di traccia in streaming per perfezionare i modelli e migliorare le loro prestazioni su Cloud TPU.
Grafico del modello
Il framework di modellazione potrebbe generare un
grafico dal modello. I dati per il grafico sono archiviati in MODEL_DIR
all'interno del bucket di archiviazione specificato con il token --logdir
. Puoi visualizzare questo grafico senza eseguire capture_tpu_profile.
Per visualizzare il grafico di un modello, seleziona la scheda Grafici in TensorBoard.
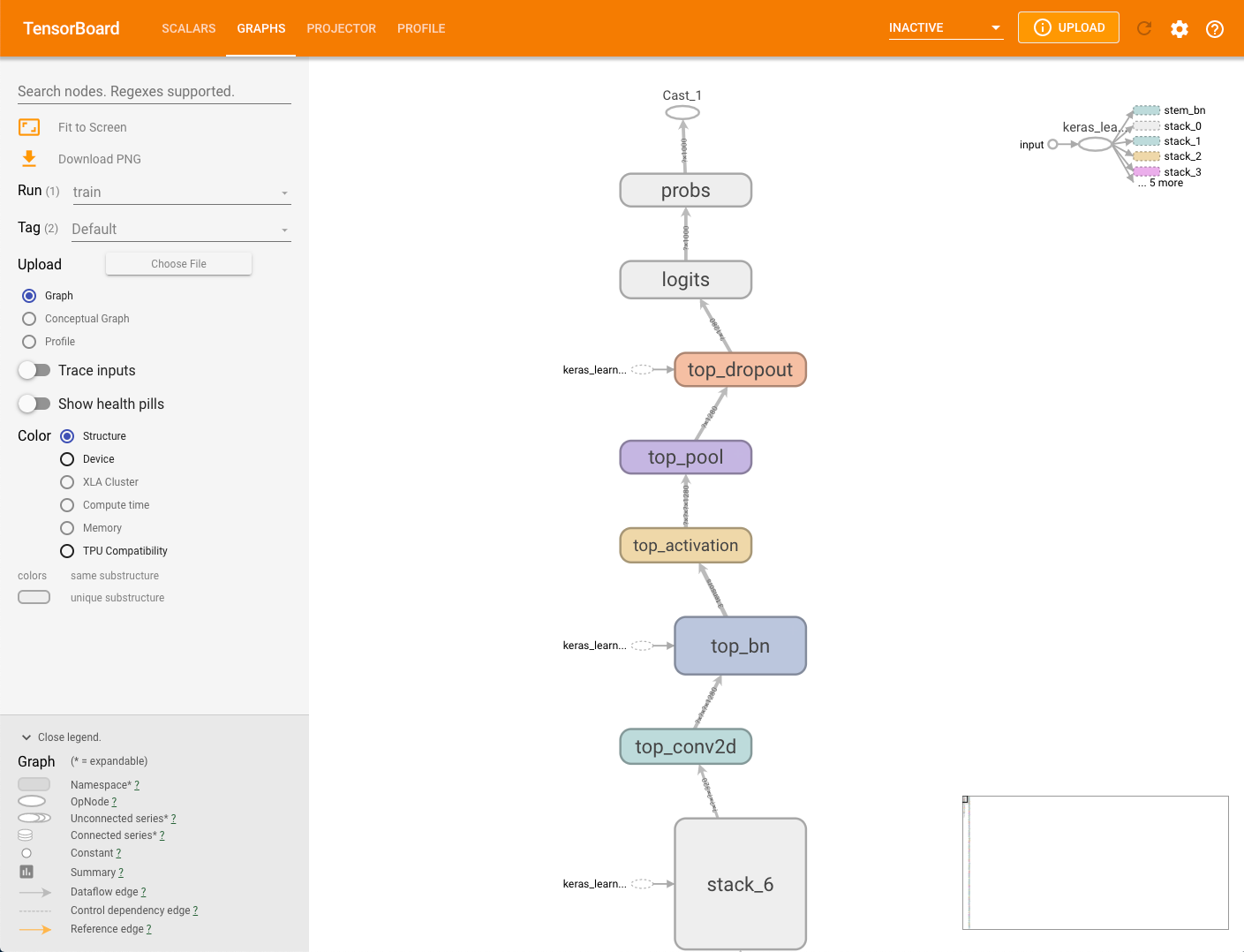
Un singolo nodo nel grafico della struttura rappresenta una singola operazione.
Grafico di compatibilità delle TPU
La scheda Grafici include un modulo di controllo della compatibilità, verifica e mostra le operazioni che possono causare problemi quando un modello viene vengono eseguiti tutti i test delle unità.
Per visualizzare il grafico di compatibilità TPU di un modello, seleziona la scheda Grafici in TensorBoard e poi l'opzione Compatibilità TPU. Il grafico mostra le operazioni compatibili (valide) in verde e quelle incompatibili (non valide) in rosso.
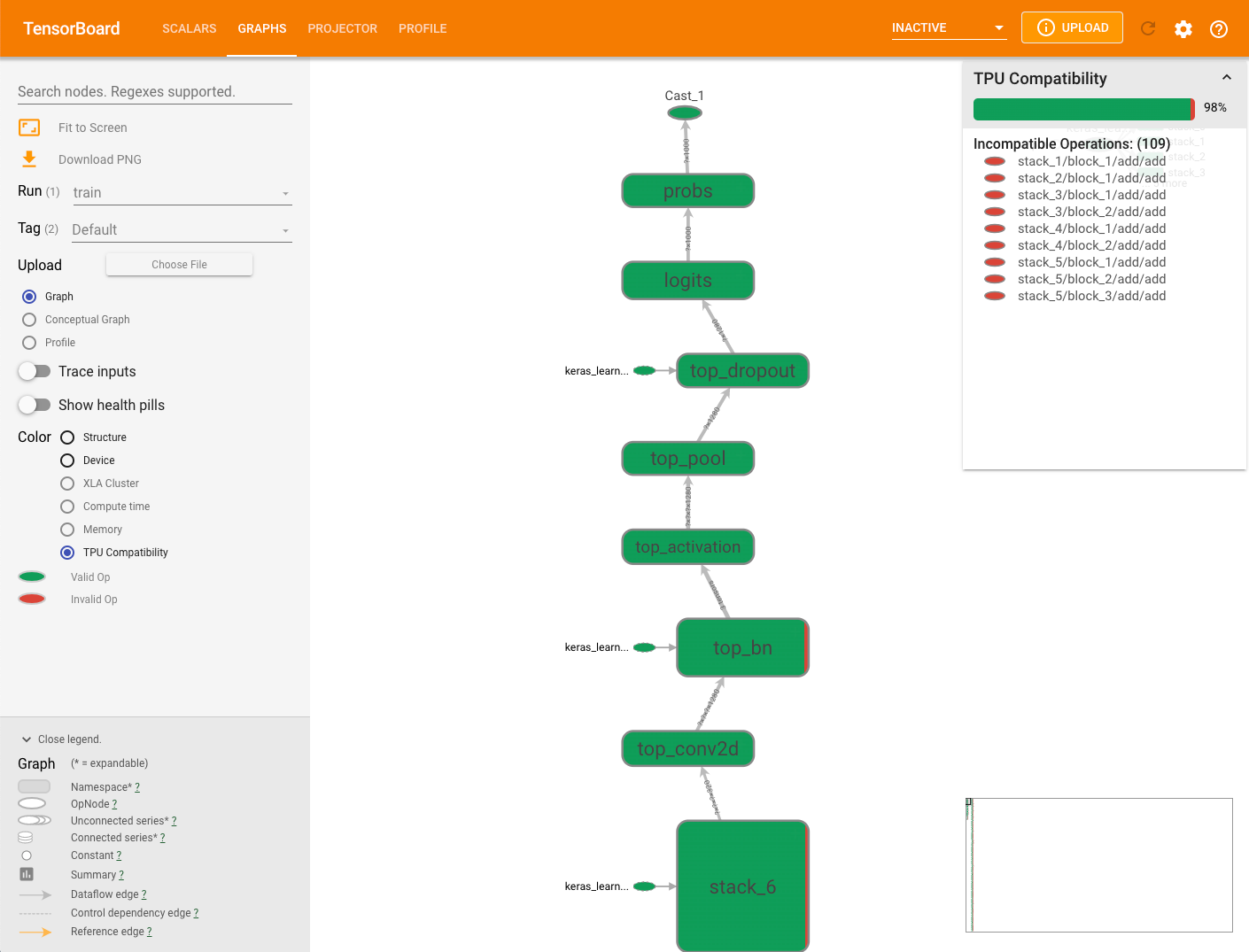
Un determinato nodo può mostrare entrambi i colori, ciascuno come percentuale delle operazioni di compatibilità Cloud TPU per quel nodo. Per un esempio, consulta Interpretazione dei risultati di compatibilità.
Il riquadro di riepilogo della compatibilità visualizzato a destra del grafico mostra la percentuale di tutte le operazioni compatibili con Cloud TPU, i relativi attributi e un elenco di operazioni incompatibili per un nodo selezionato.
Fai clic su un'operazione del grafico per visualizzarne gli attributi nel riepilogo dal riquadro.
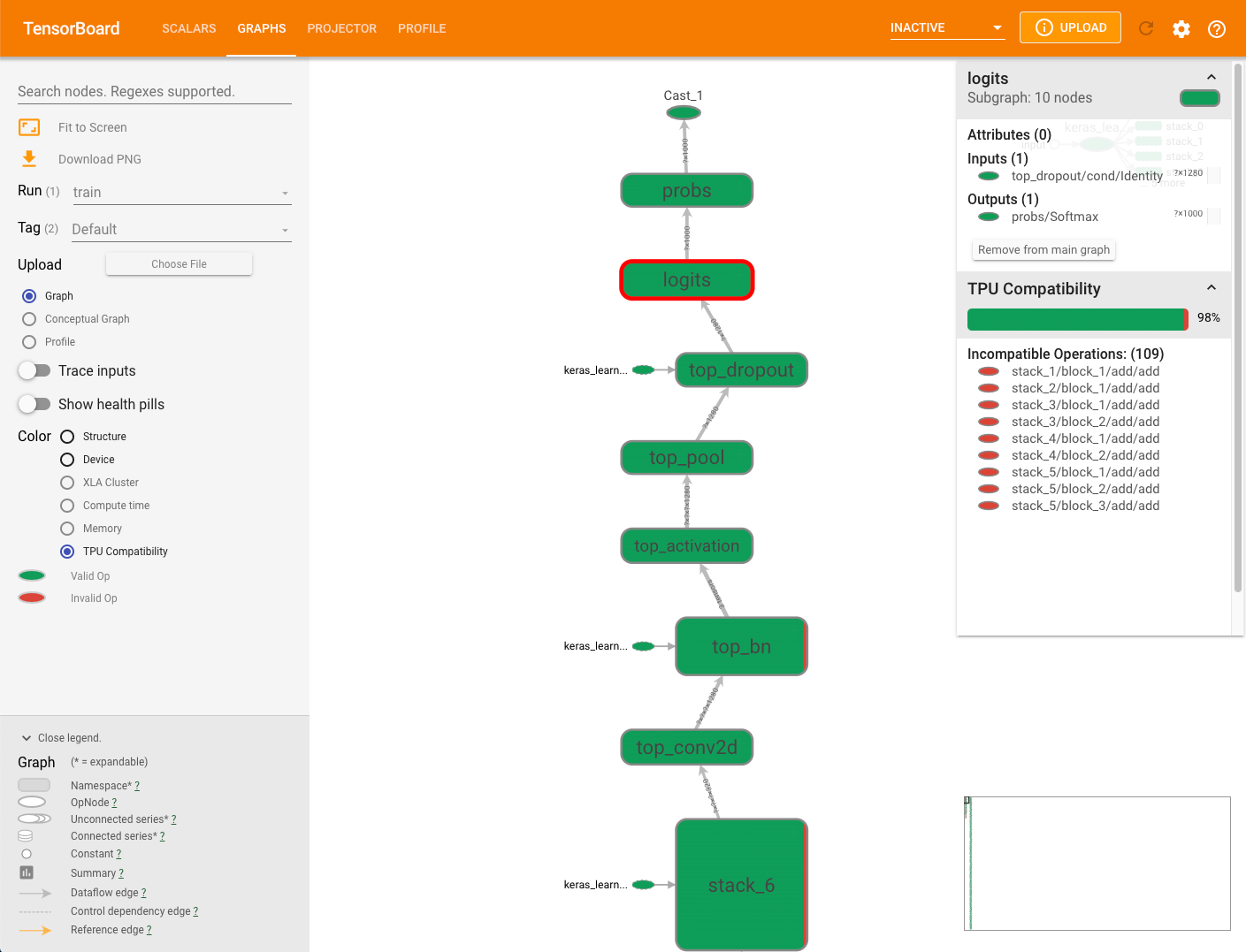
Tieni presente che il controllo di compatibilità non valuta le operazioni che vengono esplicitamente assegnato a un dispositivo non TPU tramite il posizionamento manuale del dispositivo. Inoltre, lo strumento di controllo non compila effettivamente il modello per l'esecuzione, quindi assicurati di interpretare i risultati come una stima della compatibilità.
Interpretazione dei risultati di compatibilità
Profilo
La scheda Profilo viene visualizzata dopo aver acquisito alcuni dati del modello. Tu potrebbe essere necessario fare clic sul pulsante Ricarica nell'angolo in alto a destra della pagina TensorBoard. Una volta che i dati sono disponibili, fai clic sulla scheda Profilo presenta una selezione di strumenti utili per l'analisi del rendimento:
- Pagina Panoramica
- Analizzatore pipeline di input
- Profilo operativo XLA
- Visualizzatore di traccia (solo browser Chrome)
- Visualizzatore memoria
- Visualizzatore pod
- Visualizzatore traccia streaming (solo browser Chrome)
Pagina Panoramica del profilo
La pagina Panoramica (overview_page), disponibile in Profilo, fornisce una panoramica di primo livello sul rendimento del modello durante l'esecuzione di una sessione di acquisizione. La pagina mostra una pagina di panoramica aggregata per tutte le TPU, nonché un'analisi complessiva della pipeline di input. Nel menu a discesa Host è disponibile un'opzione per selezionare singole TPU.
La pagina mostra i dati nei seguenti riquadri:
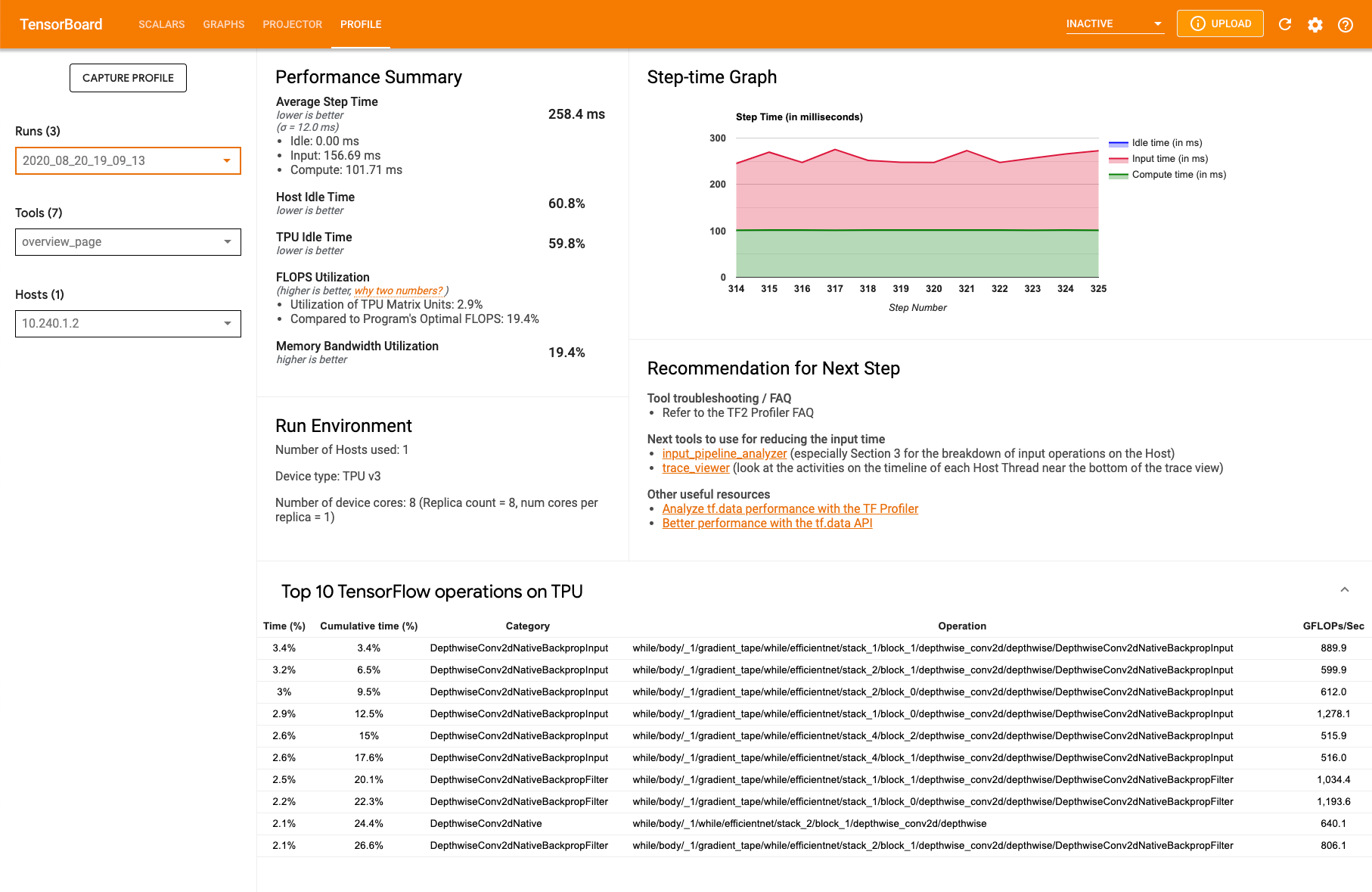
Riepilogo rendimento
- Tempo di passo medio: il tempo di passo medio calcolato su tutti i passi campionati
- Tempo di inattività dell'host: la percentuale di tempo durante la quale l'host è rimasto inattivo
- Tempo di inattività della TPU: la percentuale di tempo di inattività della TPU
- Utilizzo FLOPS: la percentuale di utilizzo delle unità di matrice TPU
- Utilizzo larghezza di banda memoria: la percentuale di larghezza di banda memoria utilizzata
Grafico dei passaggi nel tempo. Mostra un grafico del tempo del passaggio del dispositivo (in millisecondi) su tutti i passaggi campionati. L'area blu corrisponde alla parte le TPU erano inattive e attendono i dati di input dall'host. L'area rossa mostra per quanto tempo Cloud TPU è funziona davvero.
Le 10 principali operazioni di TensorFlow su TPU. Mostra le operazioni TensorFlow che hanno richiesto più tempo:
Ogni riga mostra il tempo di esecuzione di un'operazione (come percentuale del tempo impiegato da tutte le operazioni), il tempo cumulativo, la categoria, il nome e la frequenza FLOPS raggiunta.
Ambiente di esecuzione
- Numero di host utilizzati
- Tipo di TPU utilizzata
- Numero di core TPU
- Dimensione del batch di addestramento
Consiglio per i passaggi successivi. Segnala quando viene inserito un modello e ogni volta che si verificano problemi con Cloud TPU. Suggerisce strumenti che puoi utilizzare per individuare i colli di bottiglia delle prestazioni.
Analizzatore pipeline di input
Lo strumento di analisi della pipeline di input fornisce insight sui risultati delle prestazioni. La
mostra i risultati sul rendimento del file input_pipeline.json
raccolto dallo strumento capture_tpu_profile.
Lo strumento indica immediatamente se il programma è vincolato all'input e può procedere l'analisi lato host e dispositivo per eseguire il debug di qualsiasi fase che creano colli di bottiglia.
Leggi le indicazioni su prestazioni della pipeline di input per insight più approfonditi su come ottimizzare le prestazioni della pipeline.
Pipeline di input
Quando un programma TensorFlow legge i dati da un file, inizia dalla parte superiore del grafico di TensorFlow in modo sequenziale. Il processo di lettura è suddiviso in più fasi di elaborazione dei dati collegate in serie, in cui l'output di è l'input di quella successiva. Questo sistema di lettura è chiamato pipeline di input.
Una pipeline tipica per la lettura dei record dai file prevede le seguenti fasi:
- Lettura di file
- Pre-elaborazione dei file (facoltativa)
- Trasferimento di file dalla macchina host al dispositivo
Una pipeline di input inefficiente può rallentare gravemente l'applicazione. Un l'applicazione è considerata limitata all'input quando spende una parte significativa di tempo nella sua pipeline di input. Utilizza lo strumento di analisi della pipeline di input per capire dove la pipeline di input non è efficiente.
Dashboard della pipeline di input
Per aprire lo strumento di analisi della pipeline di input, seleziona Profilo, quindi input_pipeline_analyzer dal menu a discesa Strumenti.
La dashboard contiene tre sezioni:
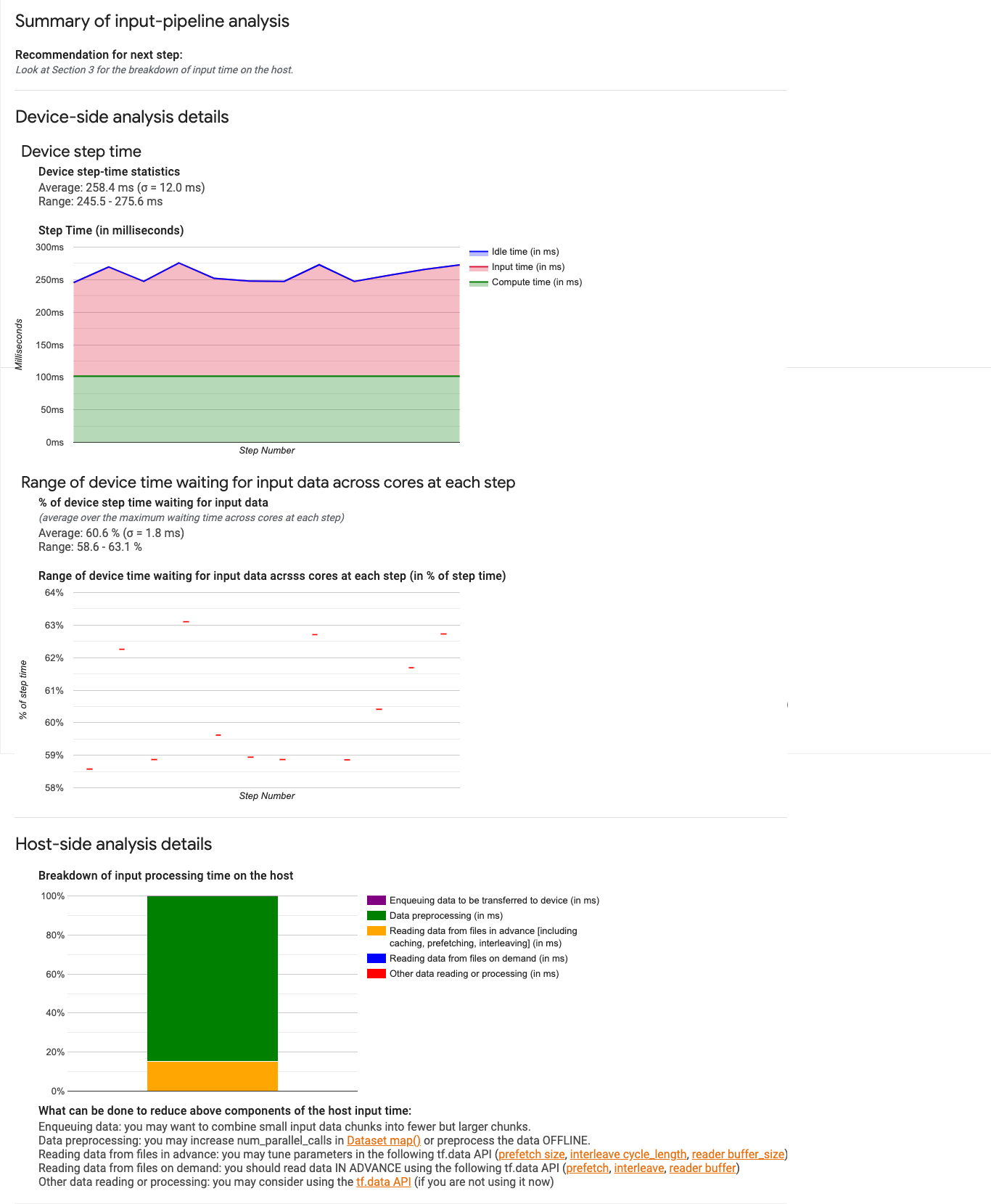
- Riepilogo. Riassume la pipeline di input complessiva con informazioni sull'eventuale limitazione dell'input dell'applicazione e, in tal caso, in base a come molto.
- Analisi lato dispositivo. Mostra dettagli lato dispositivo risultati dell'analisi, tra cui il tempo di percorrenza del dispositivo e l'intervallo tempo trascorso in attesa di dati di input tra i core in ogni passaggio.
- Analisi lato host. Mostra un'analisi dettagliata sul lato dell'host, inclusa una suddivisione del tempo di elaborazione dell'input sull'host.
Riepilogo pipeline di input
La prima sezione indica se il programma è vincolato dall'input mostrando la percentuale di tempo del dispositivo trascorso in attesa di input dall'host. Se utilizzi un pipeline di input standard che è stata strumentata, lo strumento segnala le del tempo di elaborazione dell'input. Ad esempio:

Analisi lato dispositivo
La seconda sezione descrive in dettaglio l'analisi lato dispositivo, fornendo approfondimenti in tempo trascorso sul dispositivo rispetto all'host e tempo trascorso sul dispositivo in attesa di dati di input dall'host.
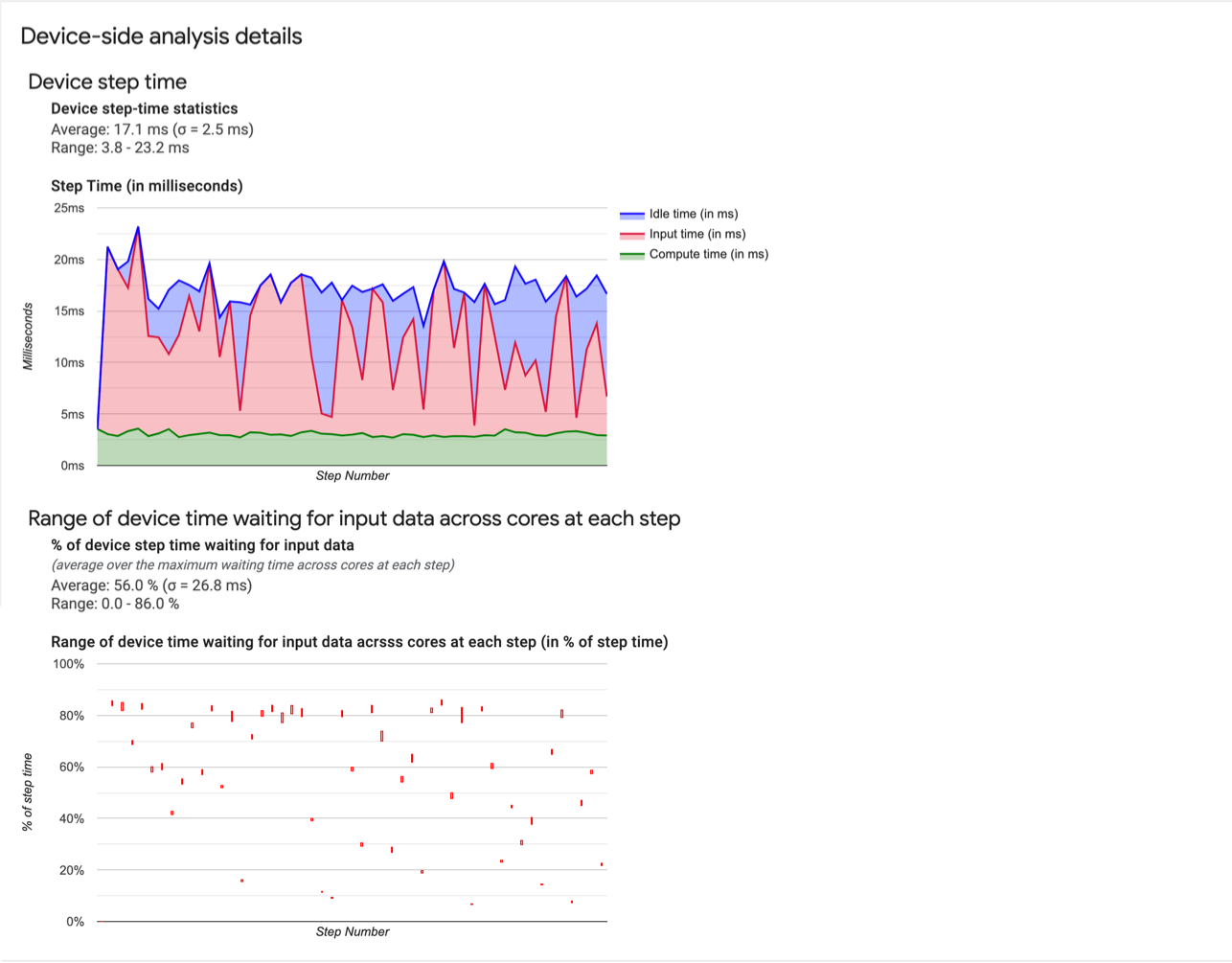
- Statistiche sul tempo di passaggio dei dispositivi. Indica la media, la deviazione standard e l'intervallo (minima, massima) del tempo del passo del dispositivo.
- Tempo del passaggio. Visualizza un grafico del tempo di passaggio del dispositivo (in millisecondi) in tutti i passaggi campionati. L'area blu corrisponde alla parte del passaggio Tempo di inattività delle Cloud TPU in attesa di dati di input dall'host. L'area rossa mostra il tempo effettivo di lavoro di Cloud TPU.
- Percentuale di tempo di attesa per i dati di input. Indica la media, la deviazione standard e l'intervallo (minima, massima) della frazione di tempo trascorsa su un dispositivo in attesa dei dati di input, normalizzata in base al tempo totale del passaggio del dispositivo.
- Intervallo di tempo del dispositivo su tutti i core trascorso in attesa dei dati di input, per numero di passaggio. Mostra un grafico a linee che mostra la quantità di tempo del dispositivo (espresso come percentuale del tempo totale di passi del dispositivo) trascorso in attesa dell'input l'elaborazione dei dati. La frazione di tempo speso varia da core a core, quindi anche l'intervallo di frazioni di ciascun nucleo viene tracciato per ogni passaggio. Poiché il tempo necessario per un passaggio è determinato dal core più lento, l'intervallo deve essere il più piccolo possibile.
Analisi lato host
La sezione 3 mostra i dettagli dell'analisi lato host, con i report sull'input (il tempo impiegato per le operazioni dell'API Dataset) nella host suddiviso in diverse categorie:
- accodamento dei dati da trasferire sul dispositivo Tempo trascorso nell'inserimento dei dati in una in coda prima di trasferire i dati al dispositivo.
- Pre-elaborazione dei dati. Tempo dedicato alle operazioni di pre-elaborazione, ad esempio le operazioni di decompressione.
- Lettura in anticipo dei dati dei file. Tempo trascorso a leggere i file, inclusi cache, pre-caricamento e interlacciamento.
- Lettura dei dati dai file on demand. Tempo impiegato per leggere i dati dai file senza memorizzazione nella cache, precaricamento e interlacciamento.
- Altre letture o elaborazioni dei dati. Tempo impiegato per altre operazioni relative all'input
non utilizzando
tf.data.

Per visualizzare le statistiche per singole operazioni di input e relative categorie suddivisa per tempo di esecuzione, espandi la sezione "Mostra statistiche operazioni di input" .
Viene visualizzata una tabella di dati di origine come la seguente:
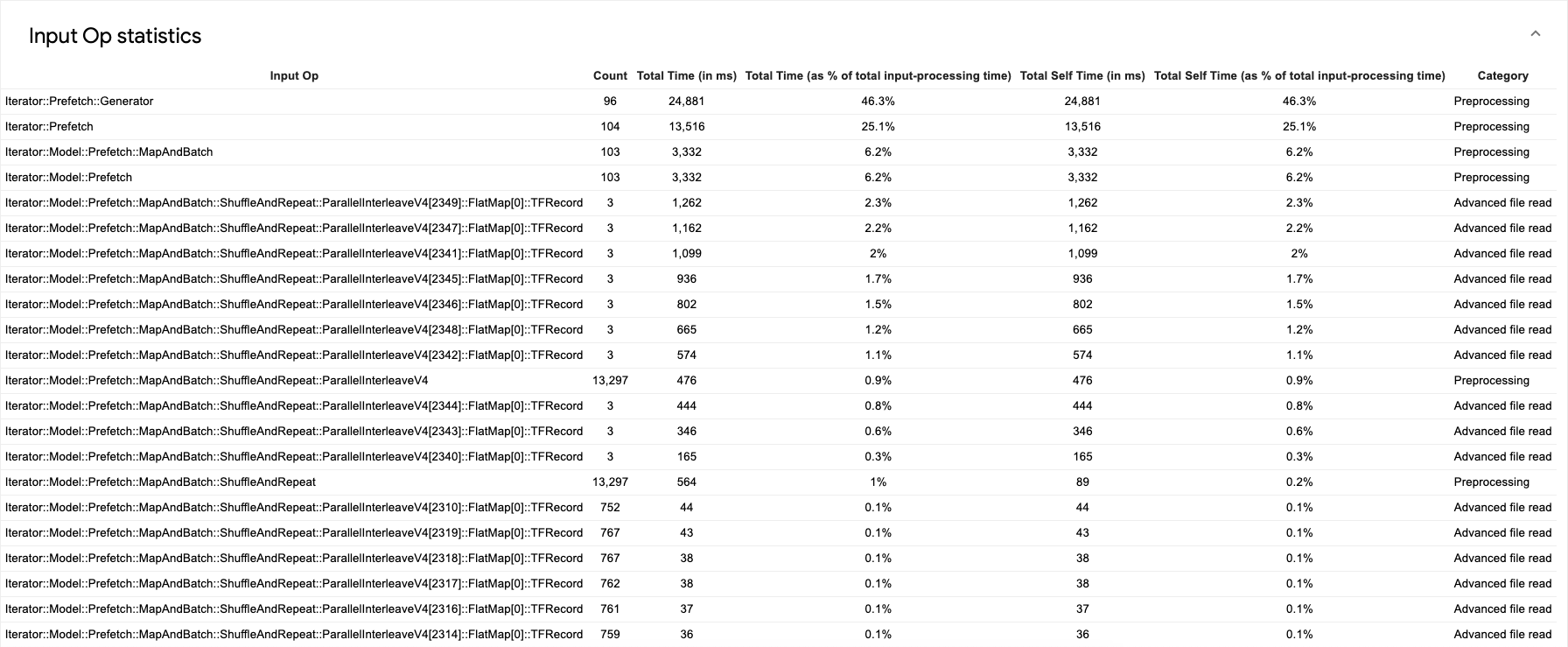
Ogni voce della tabella contiene le seguenti informazioni:
- Operazione di input. Mostra il nome dell'operazione TensorFlow dell'operazione di input.
- Numero. Mostra il numero totale di istanze dell'operazione eseguita durante il periodo di profilazione.
- Tempo totale (in ms). Mostra la somma cumulativa del tempo trascorso in ciascuna delle istanze di operazione.
- % tempo totale. Mostra il tempo totale impiegato per un'operazione come frazione del tempo totale impiegato per l'elaborazione dell'input.
- Tempo totale auto (in ms). Mostra la somma cumulativa del tempo auto
speso in ciascuna di queste istanze. Il tempo self misura il tempo trascorso
all'interno del corpo della funzione, escluso il tempo trascorso nella funzione chiamata.
Ad esempio,
Iterator::PaddedBatch::Filter::ForeverRepeat::Mapè chiamata daIterator::PaddedBatch::Filter, pertanto il suo totale il tempo autonomo è escluso dal tempo totale di quest'ultimo. - % tempo autonomo totale. Mostra il tempo autonomo totale come frazione del tempo totale impiegato per l'elaborazione dell'input.
- Categoria. Mostra la categoria di elaborazione dell'operazione di input.
Profilo operativo
Il profilo operativo è uno strumento Cloud TPU che mostra le prestazioni statistiche delle operazioni XLA eseguite durante un periodo di profilazione. Il profilo operativo mostra:
- L'efficacia con cui l'applicazione utilizza la Cloud TPU come percentuale Tempo dedicato alle operazioni per categoria e all'utilizzo dei FLOPS delle TPU.
- Le operazioni che richiedono più tempo. Queste operazioni sono potenziali bersagli per l'ottimizzazione.
- Dettagli delle singole operazioni, tra cui forma, spaziatura interna ed espressioni che utilizzano l'operazione.
Puoi utilizzare il profilo operativo per trovare buoni target per l'ottimizzazione. Ad esempio, se il tuo modello raggiunge solo il 5% dei FLOPS di picco di TPU, puoi utilizzare lo strumento per identificare le operazioni XLA che richiedono più tempo per l'esecuzione e quanti FLOPS TPU consumano.
Utilizzo del profilo dell'operatore
Durante la raccolta dei profili, capture_tpu_profile crea anche un file op_profile.json contenente le statistiche sul rendimento delle operazioni XLA.
Puoi visualizzare i dati di op_profile in TensorBoard facendo clic sull'icona Scheda Profilo nella parte superiore dello schermo e seleziona op_profile da dal menu a discesa Strumenti. Verrà visualizzata una schermata simile alla seguente:
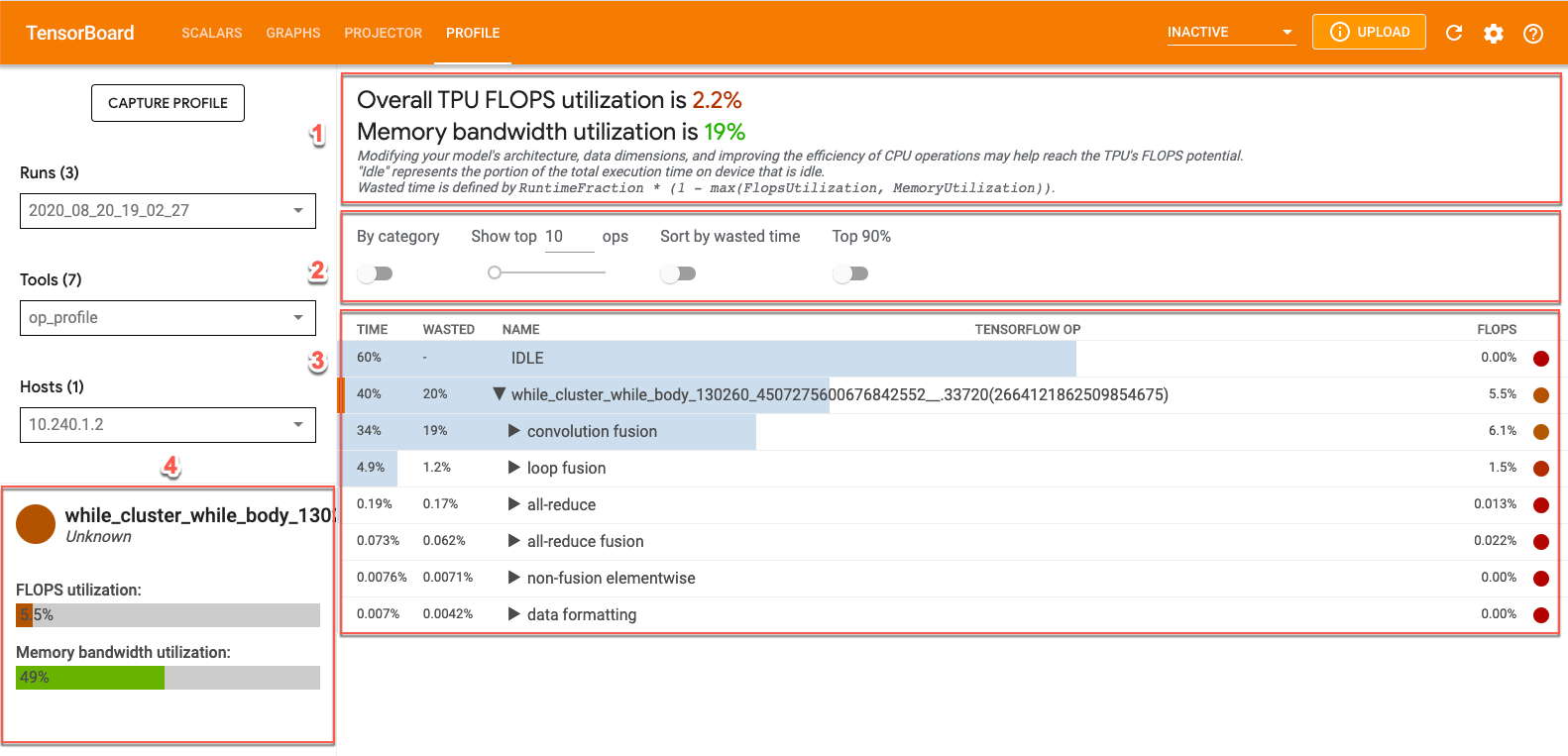
- Sezione Panoramica. Mostra l'utilizzo di Cloud TPU e fornisce suggerimenti per l'ottimizzazione.
- Pannello di controllo. Contiene i controlli che ti consentono di impostare il numero di operazioni visualizzate nella tabella, le operazioni da visualizzare e il relativo ordinamento.
- Tabella Op. Una tabella che elenca le principali categorie di operazioni TensorFlow associate alle operazioni XLA. Queste operazioni sono ordinate per percentuale di utilizzo di Cloud TPU.
- Schede dei dettagli dell'operazione. Dettagli sull'operazione visualizzati quando passi il mouse sopra un'operazione nella tabella. Questi includono l'utilizzo di FLOPS, l'espressione in cui viene usata l'operazione e il layout dell'operazione (fit).
Tabella operative XLA
La tabella Op elenca le categorie di operazioni XLA in ordine dalla percentuale di utilizzo di Cloud TPU più alta a quella più bassa. Inizialmente, la tabella mostra la percentuale di tempo impiegato, il nome della categoria di operazioni, il nome dell'operazione TensorFlow associata e la percentuale di utilizzo dei FLOPS per la categoria. Per visualizzare (o nascondere) le 10 operazioni XLA più dispendiose in termini di tempo per una categoria, fai clic sul triangolo accanto al nome della categoria nella tabella.
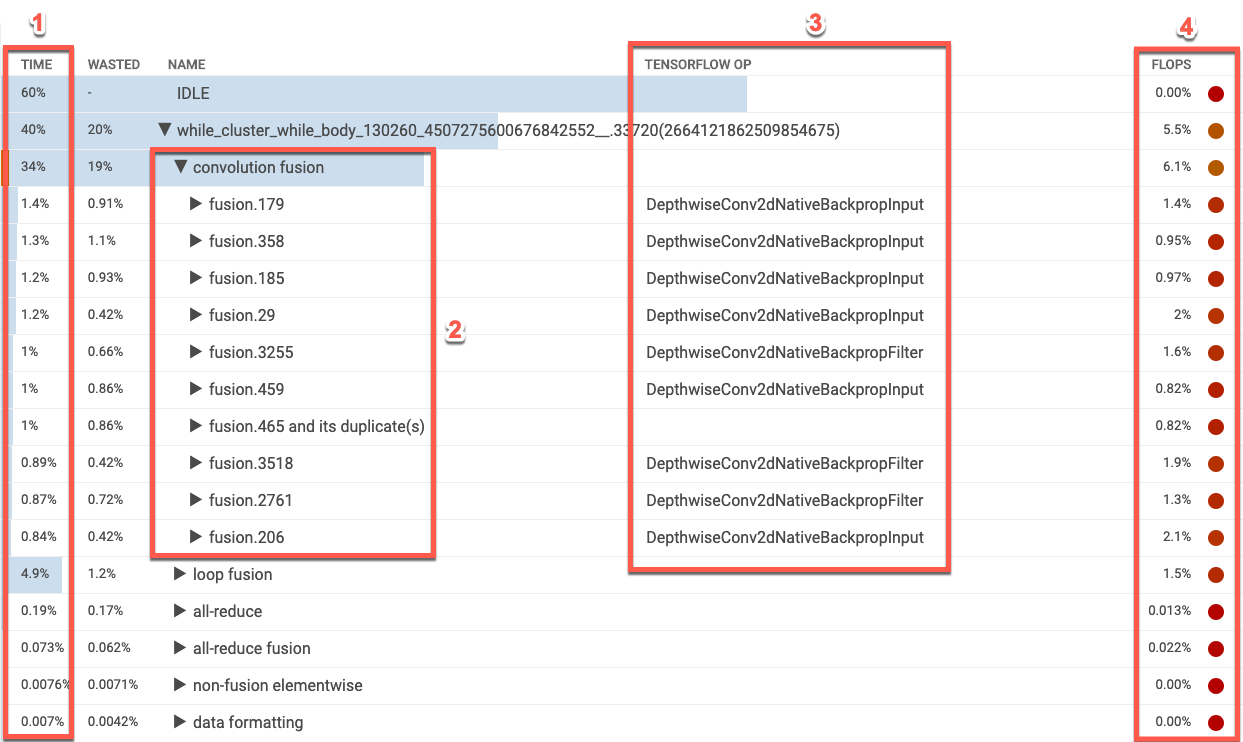
- Ora. Mostra la percentuale totale di tempo trascorso da tutte le operazioni in quella categoria. Puoi fare clic per espandere la voce e visualizzare la suddivisione del tempo impiegato da ogni singola operazione.
- Le 10 operazioni principali. Il pulsante di attivazione/disattivazione accanto al nome di una categoria mostra/nasconde la parte superiore 10 operazioni dispendiose in termini di tempo all'interno della categoria. Se un'operazione di fusione viene visualizzata nell'elenco delle operazioni, puoi espanderla per visualizzare e non fusion, con gli elementi che contiene.
- Operazione TensorFlow. Mostra il nome dell'operazione TensorFlow associata all'operazione XLA.
- FLOPS. Mostra l'utilizzo FLOPS, ovvero il numero misurato di FLOPS espressi come percentuale dei FLOPS dei picchi di Cloud TPU. Maggiore è la percentuale di utilizzo dei FLOPS, più velocemente vengono eseguite le operazioni. La cella della tabella è codificata per colore: verde per un elevato utilizzo di FLOPS (valido) e rosso per un basso utilizzo di FLOPS (non valido).
Schede dei dettagli dell'operazione
Quando selezioni una voce, sulla sinistra viene visualizzata una scheda che mostra i dettagli sull'operazione XLA o sulla categoria delle operazioni. Una tipica carta ha il seguente aspetto: questo:
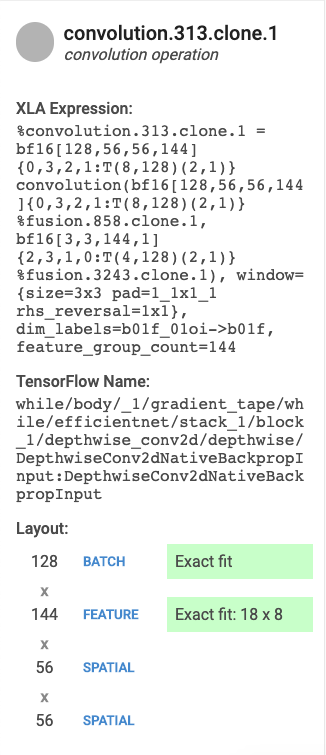
- Nome e Categoria. Mostra il nome e la categoria dell'operazione XLA evidenziati.
- Utilizzo FLOPS. Mostra l'utilizzo dei FLOPS come percentuale del totale di FLOPS possibili.
- Espressione. Mostra l'espressione XLA contenente l'operazione.
- Utilizzo della memoria. Visualizza la percentuale di utilizzo di memoria di picco da parte del tuo .
- Layout (solo operazioni di convoluzione). Mostra la forma e il layout di un tensore, tra cui se la forma del tensore è adatta esattamente alle unità della matrice e come la matrice è riempita.
Interpretazione dei risultati
Per le operazioni di convoluzione, l'utilizzo dei FLOPS della TPU può essere ridotto a causa di uno per entrambi i seguenti motivi:
- padding (le unità della matrice vengono utilizzate parzialmente)
- l'operazione di convoluzione è legata alla memoria
Questa sezione fornisce un'interpretazione di alcuni numeri di un altro modello in cui i FLOP erano bassi. In questo esempio, output fusion e convolution i tempi di esecuzione e c'era una lunga coda o scalari con FLOPS molto bassi.
Una strategia di ottimizzazione per questo tipo di profilo è trasformare le operazioni vettoriali o scalari in operazioni di convoluzione.
Nell'esempio seguente, %convolution.399 mostra FLOPS e rispetto a %convolution.340 nell'esempio precedente.
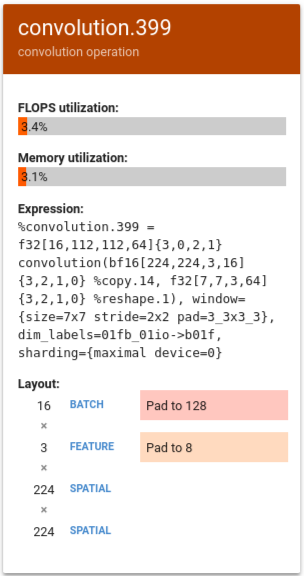
Esamina il layout e tieni presente che la dimensione del batch 16 viene aumentata a 128 e la dimensione della funzionalità 3 viene aumentata a 8, il che indica che solo il 5% delle unità della matrice viene utilizzato in modo efficace. Il calcolo per questa istanza di percentuale di utilizzo è (((batch_time * num_of_features) / padding_size ) / num_of_cores). Confrontare i FLOPS di questo esempio con %convolution.340 dell'esempio precedente esempio che si adatta esattamente alla matrice.
Visualizzatore pod
Lo strumento Visualizzatore pod fornisce visualizzazioni delle prestazioni per ogni core in un pod e visualizza lo stato dei canali di comunicazione in un pod. Pod Viewer può identificare ed evidenziare potenziali colli di bottiglia e aree che richiedono ottimizzazione. Lo strumento funziona per i pod completi e per tutti i sezioni dei pod v2 e v3.
Per visualizzare lo strumento Visualizzatore di pod:
- Seleziona Profilo dal pulsante del menu in alto a destra nella finestra di TensorBoard.
- Fai clic sul menu Strumenti a sinistra della finestra e seleziona pod_viewer.
L'interfaccia utente del visualizzatore pod include:
- Un dispositivo di scorrimento dei passaggi, che consente di selezionare il passaggio da eseguire esaminare.
- Un grafico della topologia che visualizza in modo interattivo i core TPU nell'intero sistema TPU.
- Un grafico dei link di comunicazione, che mostra i canali di invio e ricezione nel grafico della topologia.
- Grafico a barre della latenza dei canali di invio e ricezione. Se passi il mouse sopra una barra in questo grafico, vengono attivati i link di comunicazione nel grafico dei link di comunicazione. Viene visualizzata una scheda con i dettagli del canale barra di sinistra, che fornisce informazioni dettagliate sul canale, come dimensioni dei dati trasferiti, latenza e larghezza di banda.
- Un grafico di analisi dettagliata dei passaggi, che mostra un'analisi dettagliata di un passaggio per tutti i core. Questo può essere utilizzato per monitorare i colli di bottiglia del sistema e verificare se un determinato core sta rallentando il sistema.
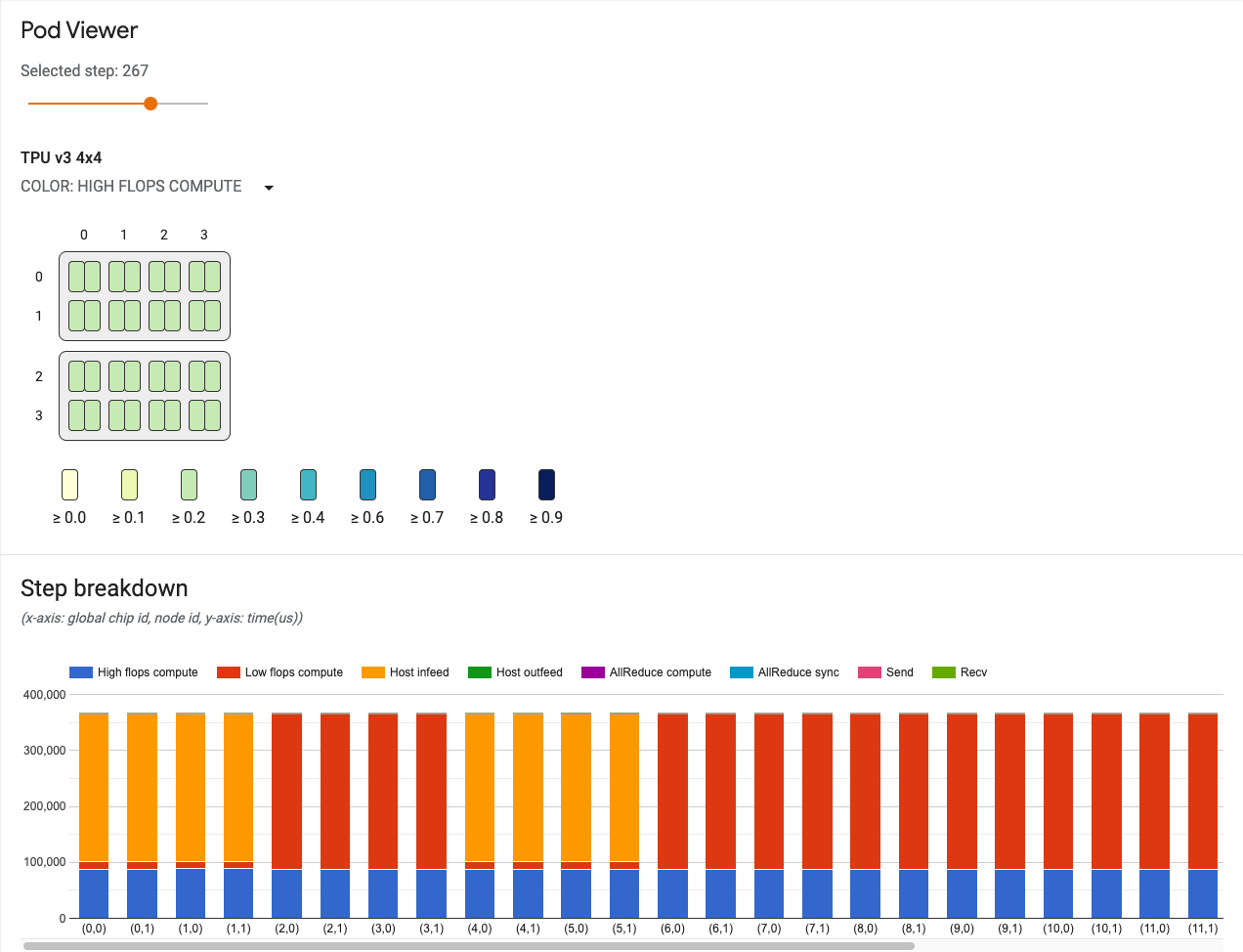
Cursore del passaggio
Utilizza il cursore per selezionare un passaggio. Il resto dello strumento mostra statistiche, come la suddivisione dei passaggi e i link di comunicazione, per quel passaggio.
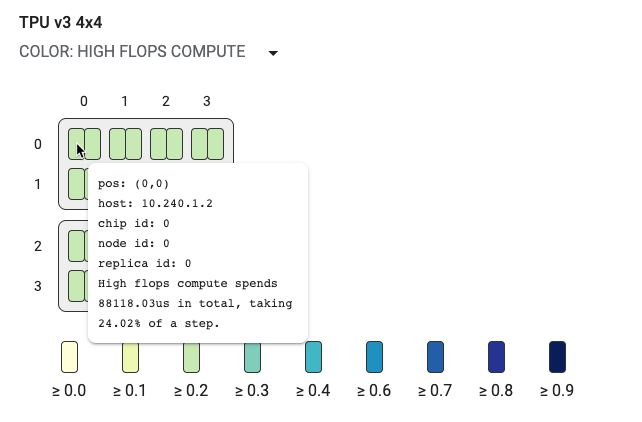
Grafico della topologia
Il grafico della topologia è organizzato in modo gerarchico per host, chip e core. I rettangoli più piccoli sono i core TPU. Due core insieme indicano un chip TPU e quattro chip indicano un host.
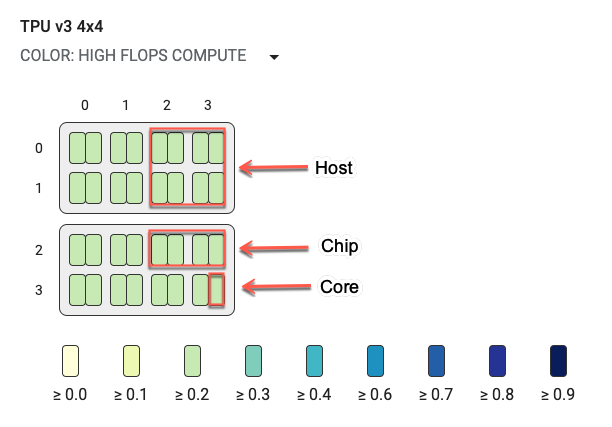
Il grafico della topologia è anche una mappa termica, codificata in base alla percentuale di tempo impiegata da un determinato tipo di suddivisione (ad esempio calcolo con elevato numero di operazioni in virgola mobile, infeed, invio e così via) nel passaggio selezionato. La barra appena sotto il grafico della topologia (mostrato nell'immagine seguente) mostra una codifica a colori per l'utilizzo di core e chip. Il colore dei core indica l'utilizzo che va dal giallo al blu. Per il calcolo con un numero elevato di FLOPS, i numeri più grandi (di colore più scuro) indicano un tempo maggiore impiegato per il calcolo. Per tutte le altre suddivisioni, numeri più piccoli (colori più chiari) indicano tempi di attesa minori. Le potenziali aree problematiche, o hotspot, sono indicate quando un nucleo è più scuro degli altri.
Fai clic sul selettore del menu a discesa accanto al nome del sistema (cerchiato nel diagramma) per scegliere il tipo specifico di suddivisione da esaminare.
Passa il mouse sopra uno dei piccoli rettangoli (singoli core) per visualizzare un suggerimento tecnico che mostra la posizione del core nel sistema, le sue l'ID chip e il nome host. La descrizione tecnica include anche la durata categoria di suddivisione selezionata, ad esempio Alti flop e relative di utilizzo rispetto al passo.
Canali di comunicazione
Questo strumento consente di visualizzare i link di invio e ricezione se il modello utilizza in modo che possano comunicare tra i core. Quando il modello contiene operazioni send e recv, puoi utilizzare un selettore di ID canale per selezionare un ID canale. Un link dal core di origine (src) e dal core di destinazione (dst), rappresenta canale di comunicazione. Viene visualizzato nel grafico della topologia passando il mouse sopra le barre del grafico che mostrano la latenza dei canali send e recv.

Nella barra a sinistra viene visualizzata una scheda con ulteriori dettagli sul canale di comunicazione. Una tipica scheda ha il seguente aspetto:
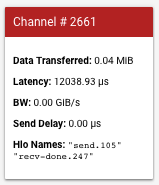
- Data Transfered (Dati trasferiti), che mostra i dati trasferiti tra le richieste di invio e ricezione canale in memibyte (MiB).
- Latenza, che mostra la durata, in microsecondi, dall'inizio della l'evento di invio alla fine dell'evento recv-done.
- BW, che mostra la quantità di dati trasferiti, in gibibyte (GiB), dal core di origine al core di destinazione nel periodo di tempo.
- Send Delay (Ritardo di invio), che indica la durata dall'inizio del recv-done all'inizio dell'invio in microsecondi. Se l'operazione recv-done inizia dopo l'inizio dell'operazione send, il ritardo è zero.
- Hlo names (Nomi Hlo), che mostra i nomi hlo ops XLA associati a questo canale. Questi nomi HLO sono associati alle statistiche visualizzate in altri strumenti TensorBoard, come op_profile e memory_viewer.
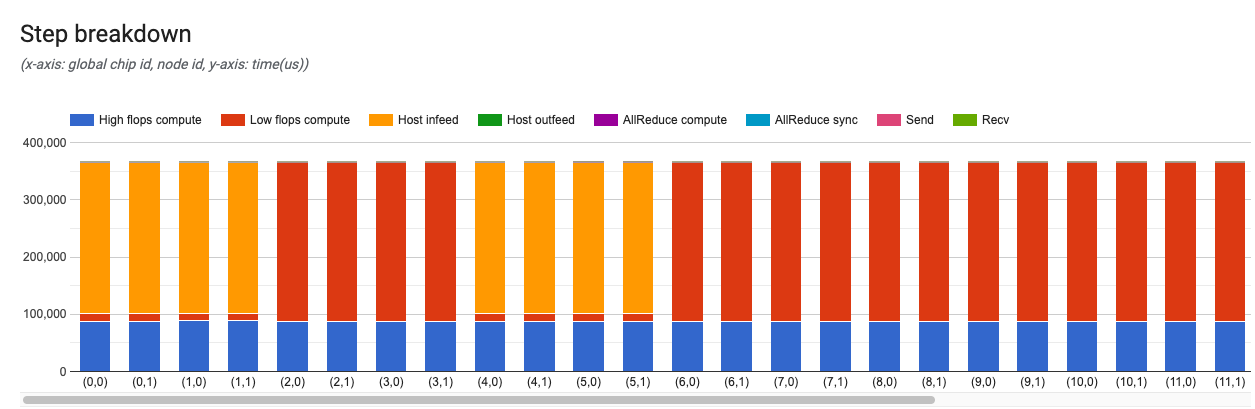
Grafico di distribuzione dei passaggi
Questo grafico fornisce dettagli per ogni passaggio di addestramento o valutazione.
L'asse x è l'ID chip globale e l'asse y è il tempo in microsecondi. In questo grafico puoi vedere dove viene utilizzato il tempo in un determinato passaggio di addestramento, dove si trovano eventuali colli di bottiglia e se è presente un bilanciamento del carico tra tutti i chip.
Nella barra di sinistra viene visualizzata una scheda con ulteriori dettagli sul la suddivisione dei passaggi. Una tipica scheda ha il seguente aspetto:
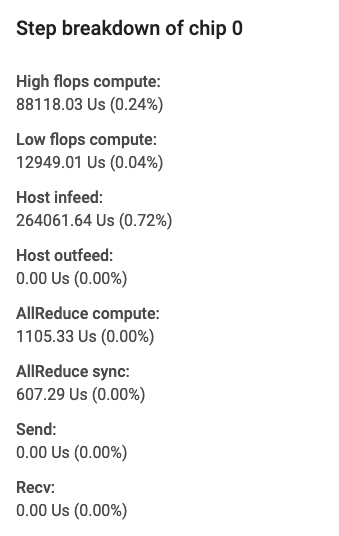
I campi della scheda specificano quanto segue:
- Compute High Flops, ovvero il tempo speso nella convoluzione o nel processo di output operazioni di fusione.
- Calcolo basso flop, calcolato deducendo tutte le altre le suddivisioni della durata totale.
- Infeed, ovvero il tempo di attesa della TPU l'host.
- Outfeed, ovvero il tempo che l'host attende. come output dalla TPU.
- Sincronizzazione AllReduce, ovvero la porzione di tempo dedicata Operazioni CrossReplicaSum in attesa di essere sincronizzato con gli altri core. Le operazioni CrossReplicaSum calcolano la somma tra le repliche.
- AllReduce Compute, ovvero il tempo di calcolo effettivo speso Operazioni CrossReplicaSum.
- Operazioni di invio chip to chip, ovvero il tempo impiegato per le operazioni di invio.
- Operazioni di invio-completamento da chip a chip, ovvero il tempo impiegato per le operazioni di invio.
Visualizzatore di tracce
Il visualizzatore di traccia è uno strumento di analisi delle prestazioni di Cloud TPU disponibile in Profilo. Lo strumento utilizza il Visualizzatore di profili degli eventi traccia di Chrome, pertanto funziona solo nel browser Chrome.
Nel visualizzatore Trace viene mostrata una sequenza temporale che mostra:
- Durate delle operazioni eseguite dal modello TensorFlow .
- La parte del sistema (TPU o macchina host) che ha eseguito un'operazione. In genere, la macchina host esegue operazioni di Infeed, che vengono pre-elaborate i dati di addestramento e li trasferisce alla TPU, mentre la TPU esegue durante l'addestramento del modello.
Il visualizzatore Trace consente di identificare i problemi di prestazioni del modello, di adottare le misure necessarie per risolverli. Ad esempio, a un livello generale, puoi identificare se l'infeed o l'addestramento del modello occupa la maggior parte del tempo. Se esamini più da vicino, puoi identificare le operazioni TensorFlow che richiedono più tempo per essere eseguite.
Tieni presente che il visualizzatore tracce è limitato a 1 milione di eventi per Cloud TPU. Se è necessario valutare più eventi, usa il visualizzatore di tracce di flusso .
Interfaccia del visualizzatore Trace
Per aprire il visualizzatore tracce, vai a TensorBoard e fai clic sulla scheda Profilo nella parte superiore dello schermo e scegli trace_viewer dal menu a discesa Strumenti. Viene visualizzato il visualizzatore con l'esecuzione più recente:
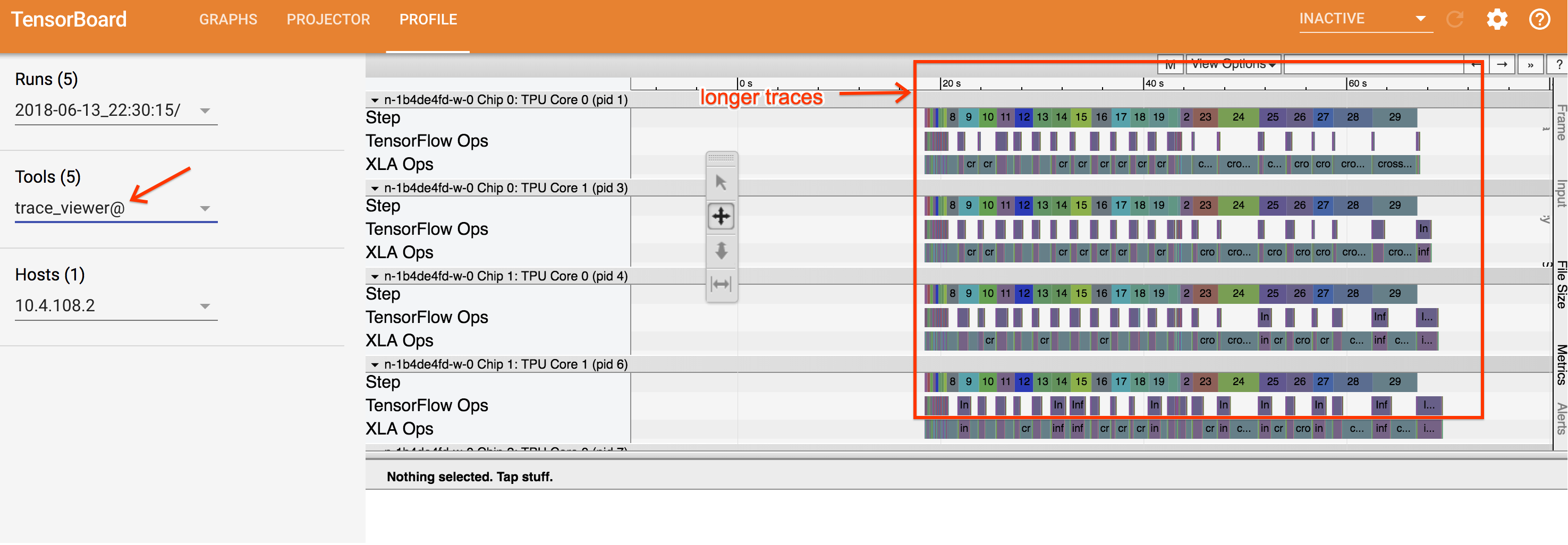
Questa schermata contiene i seguenti elementi principali (contrassegnati da numeri sopra):
- Menu a discesa Esecuzioni. Contiene tutte le esecuzioni per le quali hai le informazioni di traccia acquisite. La visualizzazione predefinita è la più recente ma puoi aprire il menu a discesa per selezionarne un'altra.
- Menu a discesa Strumenti. Seleziona strumenti di profilazione diversi.
- Menu a discesa Host. Consente di selezionare un host contenente un insieme Cloud TPU.
- Riquadro della sequenza temporale. Mostra le operazioni eseguite da Cloud TPU e dalla macchina ospitante nel tempo.
- Riquadro dei dettagli. Mostra informazioni aggiuntive sulle operazioni selezionate nel riquadro Spostamenti.
Di seguito è riportata una panoramica più approfondita del riquadro della sequenza temporale:
Il riquadro Spostamenti contiene i seguenti elementi:
- Barra superiore. Contiene vari controlli ausiliari.
- Asse temporale. Mostra l'ora relativa all'inizio della traccia.
- Etichette delle sezioni e delle tracce. Ogni sezione contiene più tracce e ha un triangolo a sinistra su cui puoi fare clic per espandere e comprimere la sezione. Esiste una sezione per ogni elemento di elaborazione del sistema.
- Selettore strumenti. Contiene vari strumenti per interagire con il visualizzatore di traccia.
- Eventi. che mostrano l'orario durante il quale è stata eseguita un'operazione la durata dei meta-eventi, come le fasi di addestramento.
- Barra delle schede verticale. Questo non ha uno scopo utile per Cloud TPU. La barra fa parte dello strumento di visualizzazione delle tracce per uso generale fornito da Chrome, che viene utilizzato per una serie di attività di analisi delle prestazioni.
Sezioni e canali
Lo strumento di visualizzazione dei tracciati contiene le seguenti sezioni:
- Una sezione per ogni nodo TPU, etichettata con il numero del chip TPU
e il nodo TPU all'interno del chip (ad esempio, "Chip 2: TPU Core 1"). Ogni sezione del nodo TPU contiene i seguenti canali:
- Passaggio. Mostra la durata dei passaggi di addestramento in esecuzione sulla TPU.
- TensorFlow Ops. Mostra le operazioni TensorFlow eseguite sulla TPU.
- XLA Ops. Mostra XLA le operazioni eseguite sulla TPU. Ogni operazione viene tradotta in una o più operazioni XLA. Il compilatore XLA traduce le operazioni XLA nel codice eseguito sulla TPU.)
- Una sezione per i thread in esecuzione sulla CPU della macchina host, etichettata come "Thread host". La sezione contiene una traccia per ogni CPU . Nota: puoi ignorare le informazioni visualizzate accanto alla sezione etichette.
Selettore strumento Timeline
Puoi interagire con la visualizzazione cronologica utilizzando il selettore dello strumento della sequenza temporale in TensorBoard. Puoi fare clic su uno strumento della cronologia o utilizzare le seguenti scorciatoie da tastiera per attivare e evidenziare uno strumento. Per spostare il selettore degli strumenti della sequenza temporale, fai clic nell'area tratteggiata in alto e trascinalo dove preferisci.
Utilizza gli strumenti per la cronologia come segue:
|
Strumento di selezione Fai clic su un evento per selezionarlo o trascina per selezionare più eventi. Nel riquadro dei dettagli vengono visualizzate ulteriori informazioni sull'evento o sugli eventi selezionati (nome, ora di inizio e durata). |
|
Strumento di panoramica Trascina per eseguire la panoramica della visualizzazione della cronologia orizzontalmente e verticalmente. |
|
Strumento Zoom Trascina verso l'alto per aumentare lo zoom o verso il basso per diminuire lo zoom lungo l'orizzontale (tempo) . La posizione orizzontale del cursore del mouse determina il centro intorno al quale avviene lo zoom. Nota: lo strumento Zoom presenta un bug noto per cui lo zoom rimane attivo. se rilasci il pulsante del mouse mentre il cursore del mouse si trova fuori dalla sequenza temporale vista. In questo caso, fai clic brevemente sulla visualizzazione della cronologia per interrompere eseguire lo zoom. |
|
Strumento di monitoraggio Trascina in orizzontale per contrassegnare un intervallo di tempo. La lunghezza dell'intervallo apparirà sull'asse del tempo. Per regolare l'intervallo, trascinane le estremità. Per cancellare il valore fai clic in un punto qualsiasi della visualizzazione cronologica. Tieni presente che l'intervallo rimane contrassegnato se selezioni uno degli altri strumenti. |
Eventi
Gli eventi nella sequenza temporale vengono visualizzati in colori diversi; i colori non hanno un significato specifico.
Barra superiore Timeline
La barra superiore del riquadro Spostamenti contiene diversi controlli ausiliari:

- Visualizzazione dei metadati. Non utilizzato per le TPU.
- Visualizza opzioni. Non utilizzato per le TPU.
- Casella di ricerca. Inserisci il testo da cercare in tutti gli eventi il cui nome contiene il testo. Fai clic sui pulsanti freccia a destra della casella di ricerca per andare avanti e indietro tra gli eventi corrispondenti, selezionandoli uno alla volta.
- Pulsante della console. Non utilizzato per le TPU.
- Pulsante Guida. Fai clic per visualizzare un riepilogo della guida.
Scorciatoie da tastiera
Di seguito sono riportate le scorciatoie da tastiera che puoi utilizzare nel visualizzatore delle tracce. Fai clic sulla guida (?) nella barra superiore per visualizzare altre scorciatoie da tastiera.
w Zoom in
s Zoom out
a Pan left
d Pan right
f Zoom to selected event(s)
m Mark time interval for selected event(s)
1 Activate selection tool
2 Activate pan tool
3 Activate zoom tool
4 Activate timing toolLa scorciatoia f può essere molto utile. Prova a selezionare un passaggio e a premere F per aumentare rapidamente lo zoom.
Eventi caratteristici
Di seguito sono riportati alcuni tipi di eventi che possono essere molto utili durante l'analisi Prestazioni TPU.

InfeedDequeueTuple. Questa operazione TensorFlow viene eseguita su una TPU riceve dati di input dall'host. Se l'infeed richiede molto tempo, può significare che le operazioni di TensorFlow che pre-elaborano i dati sulla macchina host non riescono a tenere il passo con il tasso di consumo dei dati TPU. Puoi vedere gli eventi corrispondenti nelle tracce host chiamate InfeedEnqueueTuple. Per visualizzare un'analisi più dettagliata della pipeline di input, utilizza lo strumento Input Pipeline Analyzer.
CrossReplicaSum. Questa operazione TensorFlow viene eseguita su una TPU e calcola una somma tra le repliche. Poiché ogni replica corrisponde a un nodo TPU diverso, l'operazione deve attendere il completamento di un passaggio per tutti i nodi TPU. Se questa operazione richiede molto tempo, potrebbe non significare che l'operazione di somma sia lenta, ma che un nodo TPU stia aspettando un altro nodo TPU con un infeed dei dati lento.

- Operazioni del set di dati. Il visualizzatore Trace mostra le operazioni del set di dati eseguite quando
I dati vengono caricati utilizzando l'API Dataset.
Iterator::Filter::Batch::ForeverRepeat::Memorynell'esempio è e che corrisponde all'operazionedataset.map(). Utilizza le funzionalità di visualizzatore tracce per esaminare le operazioni di caricamento durante il debug e la mitigazione dei colli di bottiglia della pipeline di input.
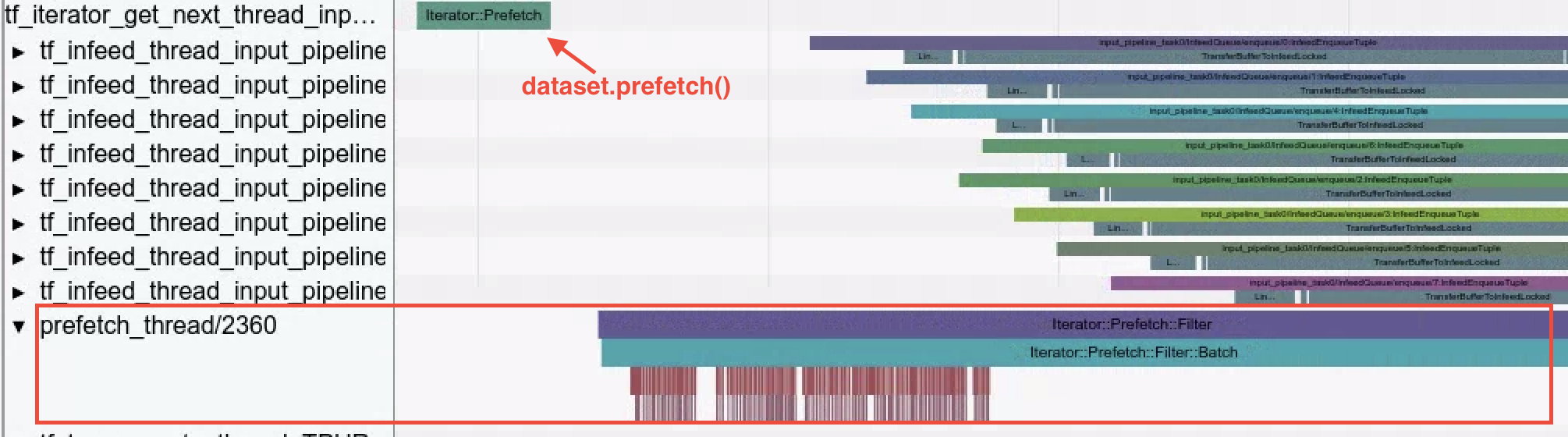
- Precarica i thread. L'utilizzo di
dataset.prefetch()per mettere in buffer i dati di input può evitare rallentamenti sporadici nell'accesso ai file che creano colli di bottiglia nella pipeline di input.
Cosa può andare storto
Di seguito sono riportati alcuni potenziali problemi da tenere presenti quando utilizzi il visualizzatore tracce:
- Limite di visualizzazione degli eventi. Il visualizzatore di tracce mostra un massimo di 1 milione di eventi. Se hai acquisito più eventi, vengono visualizzati solo il primo milione
visualizzati; e quelli successivi vengono eliminati. Per acquisire più eventi TPU, puoi
usa il flag
--include_dataset_ops=Falseper richiedere esplicitamentecapture_tpu_profileper escludere le operazioni del set di dati. - Eventi molto lunghi. Gli eventi che iniziano prima dell'inizio di un rilevamento o che terminano dopo il termine di un rilevamento non sono visibili nel visualizzatore di tracce. Di conseguenza, per gli eventi molto lunghi.
Quando avviare l'acquisizione della traccia. Assicurati di avviare l'acquisizione della traccia dopo aver verificato che Cloud TPU sia in esecuzione. Se inizi prima di allora, potrebbe vedere solo pochi eventi o nessun evento nel visualizzatore tracce. Puoi aumentare il tempo del profilo utilizzando il flag
--duration_mse puoi impostare i tentativi automatici utilizzando il flag--num_tracing_attempts. Ad esempio:(vm)$ capture_tpu_profile --tpu=$TPU_NAME --logdir=${MODEL_DIR} --duration_ms=60000 --num_tracing_attempts=10
Visualizzatore della memoria
Il visualizzatore della memoria ti consente di visualizzare il picco di utilizzo della memoria per il tuo programma, e le tendenze di utilizzo della memoria nel corso del ciclo di vita del programma.
L'interfaccia utente del visualizzatore della memoria ha questo aspetto:
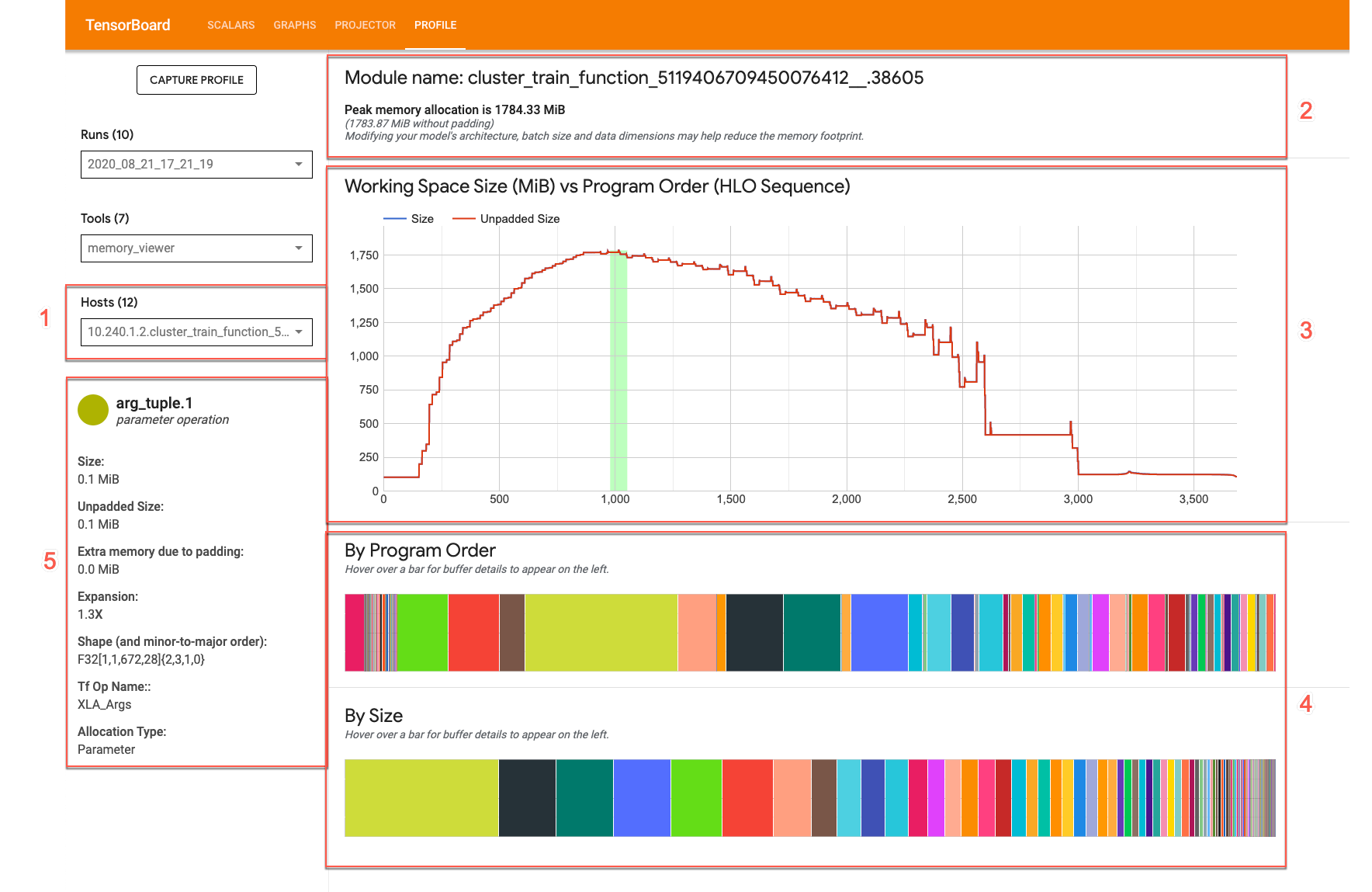
- Menu a discesa Host. Seleziona per un host TPU e un ottimizzatore di alto livello XLA (HLO) da visualizzare.
- Panoramica della memoria. Mostra l'allocazione e le dimensioni di picco della memoria senza spaziatura interna.
- Diagramma dello spazio di lavoro. Visualizza il picco di utilizzo della memoria e un grafico dell'utilizzo della memoria. le tendenze nel corso dell'intero ciclo di vita del programma. Passare il mouse sopra un buffer in uno dei buffer aggiunge un'annotazione per la durata del buffer e la scheda dei dettagli del buffer.
- Grafici di buffer. Due grafici che mostrano l'allocazione del buffer nel punto di picco di utilizzo della memoria, come indicato dalla linea verticale nel grafico dello spazio di lavoro. Se passi il mouse sopra un buffer in uno dei grafici dei buffer, viene visualizzata la barra della durata del buffer nel grafico dello spazio di lavoro e una scheda dei dettagli a sinistra.
- Scheda dei dettagli sull'allocazione del buffer. Mostra i dettagli dell'allocazione per un buffer.
Riquadro panoramica memoria
Il riquadro della panoramica della memoria (in alto) mostra il nome del modulo e il picco di memoria impostata quando la dimensione totale di allocazione del buffer raggiunge il valore massimo. Per il confronto viene mostrata anche la dimensione dell'allocazione di picco non riempita.

Grafico dello spazio di lavoro
Questo grafico mostra il picco di utilizzo della memoria e un grafico delle tendenze di utilizzo della memoria nel corso della vita del programma. La linea tracciata dall'alto verso il basso del grafico indica l'utilizzo massimo della memoria per il programma. Questo punto determina se un può rientrare nello spazio di memoria globale disponibile.
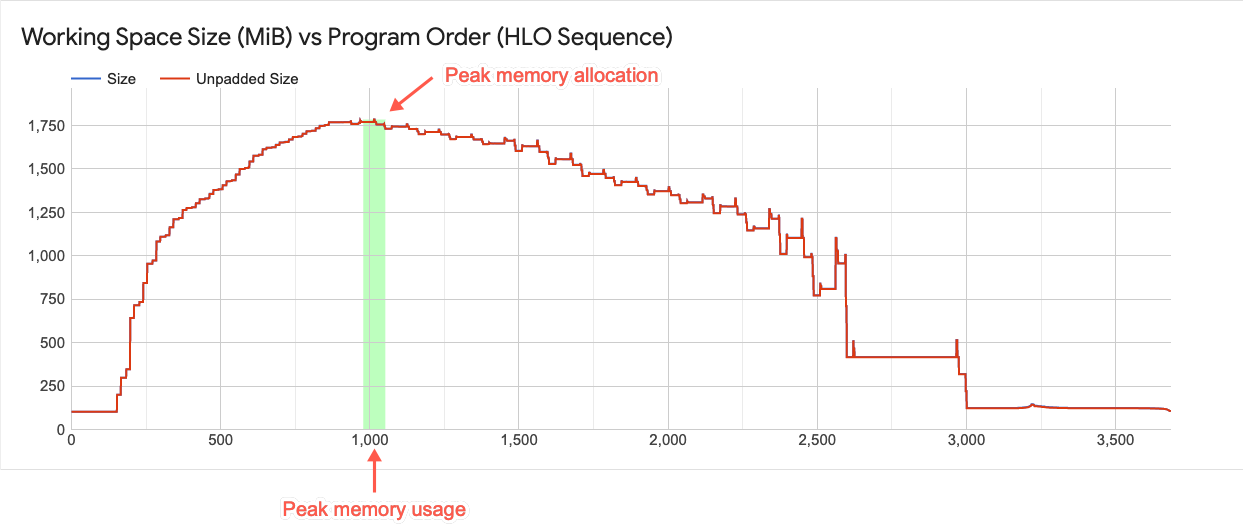
Ogni punto sul grafico a linee sovrapposta rappresenta un "punto di programma" negli XLA programma HLO pianificato dal compilatore. La linea dà l'idea dei picchi di utilizzo durante il picco di utilizzo.
Interazione con gli elementi del grafico buffer
Quando passi il mouse sopra un buffer visualizzato in uno dei grafici dei buffer sotto il grafico dello spazio di lavoro, nel grafico dello spazio di lavoro viene visualizzata una linea orizzontale della durata del buffer. La linea orizzontale è dello stesso colore del buffer evidenziato.
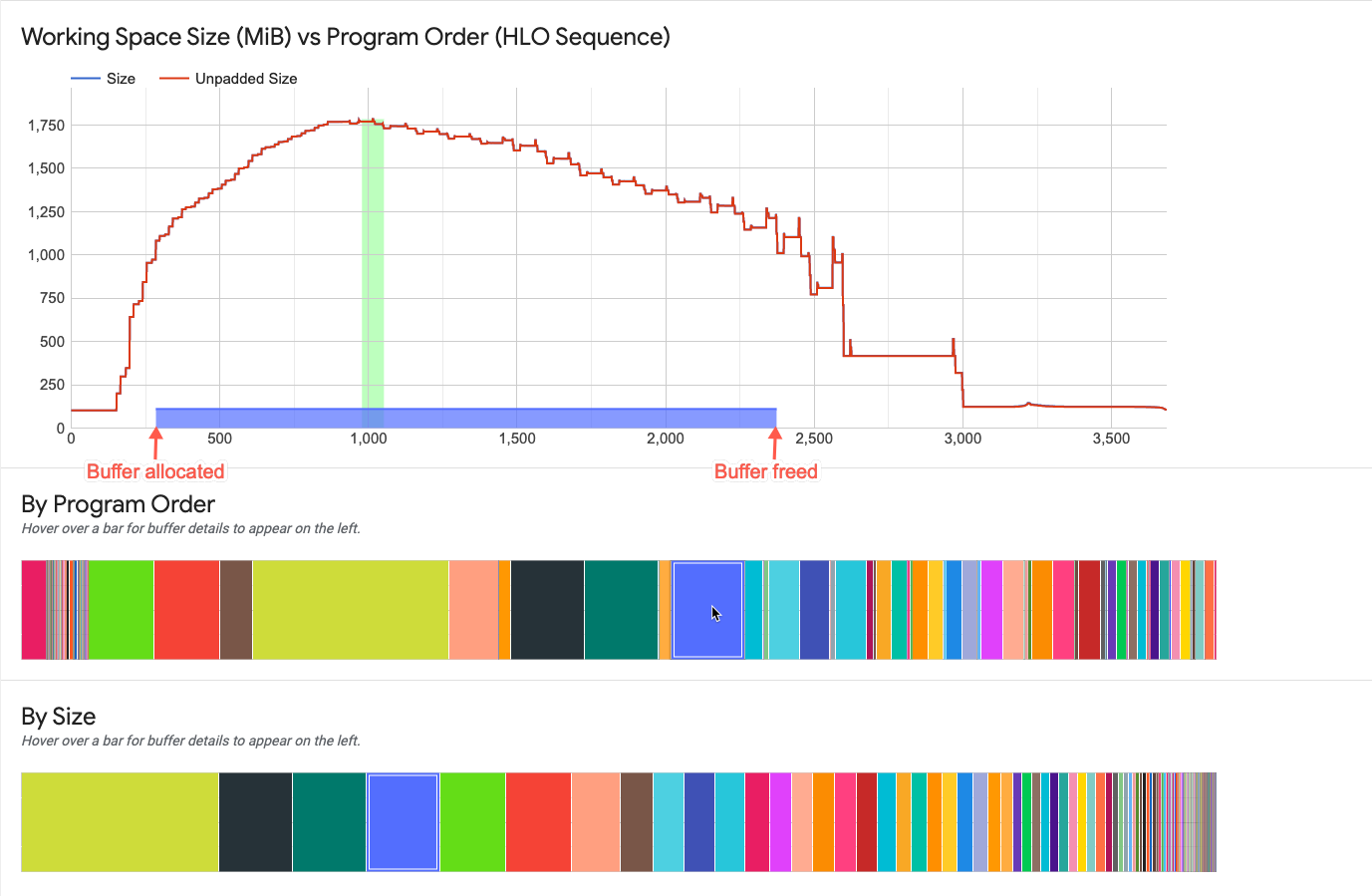
Lo spessore della linea orizzontale indica l'ordine di grandezza relativo della dimensione del buffer rispetto all'allocazione massima della memoria. La lunghezza della riga corrisponde alla vita del buffer, a partire dal punto del programma in cui è stato allocato lo spazio del buffer e fino al punto in cui lo spazio è stato liberato.
Grafici di buffer
Due grafici mostrano la suddivisione dell'utilizzo della memoria nel punto di picco di utilizzo (indicato dalla linea verticale nel grafico sopra i grafici).
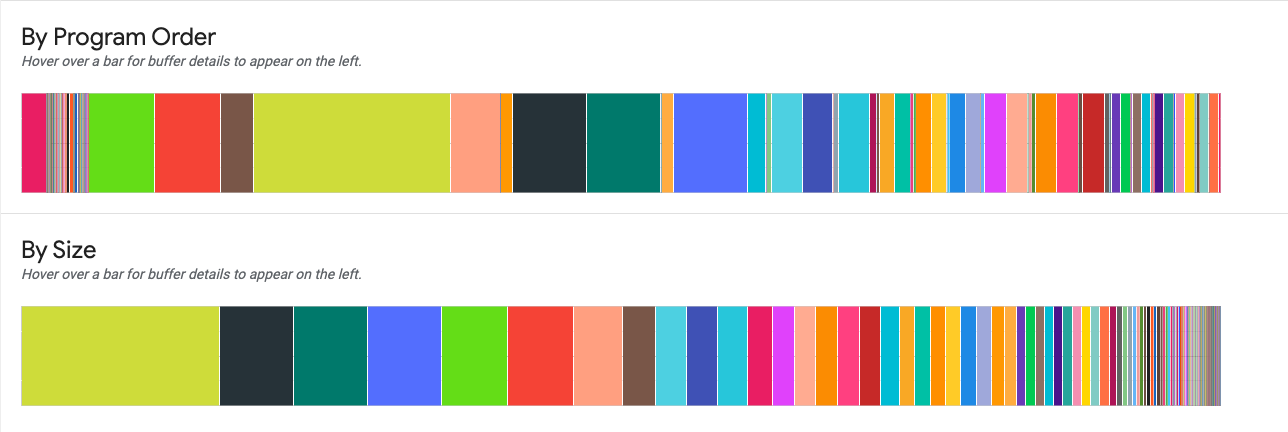
Su richiesta del programma. Visualizza i buffer da sinistra a destra nell'ordine in che erano attivi durante l'esecuzione del programma. I buffer attivi per più tempo si trovano sul lato sinistro del grafico.
Per dimensione. Visualizza i buffer attivi durante l'esecuzione del programma in ordine decrescente delle dimensioni. I buffer che hanno avuto l'impatto maggiore nel punto di picco di utilizzo della memoria si trovano a sinistra.
Scheda dei dettagli dell'allocazione del buffer
Quando passi il mouse sopra un buffer visualizzato in uno dei grafici dei buffer, viene visualizzata una scheda dei dettagli dell'allocazione del buffer (oltre alla linea Lifetime visualizzata nel grafico di lavoro). Una scheda dei dettagli tipica ha il seguente aspetto:
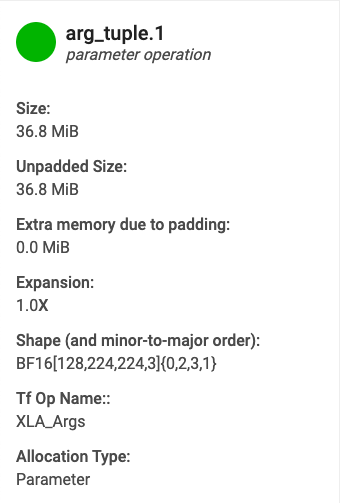
- Nome. Nome dell'operazione XLA.
- Categoria. Categoria dell'operazione.
- Dimensioni. Dimensioni dell'allocazione del buffer (inclusa la spaziatura interna).
- Taglia senza imbottitura. Dimensioni dell'allocazione del buffer senza spaziatura interna.
- Espansione. Grandezza relativa della dimensione del buffer riempito rispetto a quello non riempito dimensioni.
- Memoria aggiuntiva. Indica la quantità di memoria aggiuntiva utilizzata per il riempimento.
- Forma. Descrive il rango, la dimensione e il tipo di dati di un modello n-dimensionale un array di dati.
- Nome operazione TensorFlow. Mostra il nome dell'operazione TensorFlow associata con l'allocazione del buffer.
- Tipo di allocazione. Indica la categoria di allocazione del buffer. I tipi sono: Parametro, Output, Locale per thread e Temporaneo (ad esempio, allocazione del buffer all'interno di una fusione).
Errori "Memoria insufficiente"
Se esegui un modello e ricevi un "errore di esaurimento della memoria", utilizza il seguente comando per acquisire un profilo della memoria e visualizzarlo nel visualizzatore della memoria. Assicurati di impostare durata appropriata_ms in modo che il periodo di profilazione si sovrapponga al programma la data e l'ora della compilazione. L'output può aiutarti a capire cosa ha causato l'errore:
(vm)$ capture_tpu_profile --tpu=$TPU_NAME --logdir=${MODEL_DIR} --duration_ms=60000
Visualizzatore tracce flussi di dati
Lo strumento di visualizzazione delle tracce in streaming (trace_viewer) è uno strumento di analisi delle prestazioni di Cloud TPU, disponibile per TensorFlow 2.17.0 o versioni successive, che fornisce rendering dinamici delle tracce. Lo strumento utilizza il Visualizzatore di profili degli eventi traccia di Chrome, pertanto funziona solo nel browser Chrome.
Quando usi capture_tpu_profile per
acquisire un profilo, un file .tracetable viene salvato nel tuo spazio di archiviazione Google Cloud
di sincronizzare la directory di una VM
con un bucket. Il file contiene un numero elevato di eventi traccia che possono essere visualizzati
sia nel visualizzatore traccia
che nel visualizzatore delle tracce in streaming.
Utilizzo del visualizzatore di tracce di streaming
Per utilizzare il visualizzatore della traccia di streaming, trace_viewer, devi arrestare il
sessione TensorBoard esistente, quindi riavvia TensorBoard utilizzando l'indirizzo IP
della TPU che vuoi esaminare. Lo strumento di visualizzazione delle tracce in streaming richiede che TensorBoard effettui una chiamata di procedura remota (GRPC) di Google a un indirizzo IP per Cloud TPU. Il canale GRPC non è criptato.
Puoi trovare l'indirizzo IP di un host Cloud TPU nella pagina Cloud TPU. Individua la tua Cloud TPU e cerca l'indirizzo IP nella colonna IP interno.
Nella VM, esegui TensorBoard come segue sostituendo tpu-ip con il tuo Indirizzo IP della TPU:
(vm)$ tensorboard --logdir=${MODEL_DIR} \ --master_tpu_unsecure_channel=tpu-ip
Lo strumento TensorBoard viene visualizzato nell'elenco a discesa Strumenti.
Nella sequenza temporale, puoi aumentare e diminuire lo zoom per vedere il caricamento dinamico degli eventi traccia nel browser.
Monitoraggio del job Cloud TPU
Questa sezione descrive come utilizzare capture_tpu_profile per acquisire un singolo profilo o monitorare continuamente il job Cloud TPU sull'interfaccia a riga di comando in tempo reale. Se imposti l'opzione --monitoring_level su 0 (il valore predefinito), 1 o 2, ottieni rispettivamente un singolo profilo, un monitoraggio di base o un monitoraggio dettagliato.
Apri una nuova Cloud Shell e connettiti tramite SSH alla tua VM (sostituisci vm-name nel comando con il nome della VM):
(vm)$ gcloud compute ssh vm-name \ --ssh-flag=-L6006:localhost:6006
Nel nuovo Cloud Shell, esegui capture_tpu_profile con
Flag --monitoring_level impostato su 1 o 2, ad esempio:
(vm)$ capture_tpu_profile --tpu=$TPU_NAME \ --monitoring_level=1
L'impostazione di monitoring_level=1 produce un output simile al seguente:
TPU type: TPU v2
Utilization of TPU Matrix Units is (higher is better): 10.7%L'impostazione monitoring_level=2 mostra informazioni più dettagliate:
TPU type: TPU v2
Number of TPU Cores: 8
TPU idle time (lower is better): 0.091%
Utilization of TPU Matrix Units is (higher is better): 10.7%
Step time: 1.95 kms (avg), 1.90kms (minute), 2.00 kms (max)
Infeed percentage: 87.5% (avg). 87.2% (min), 87.8 (max)Indicatori di monitoraggio
--tpu(obbligatorio) specifica il nome della Cloud TPU che vuoi monitorare.--monitoring_level. Modifica il comportamento dicapture_tpu_profileda produzione di un singolo profilo a monitoraggio continuo di base o dettagliato. Sono disponibili tre livelli: Livello 0 (valore predefinito): genera un singolo profilo, quindi esce. Livello 1: mostra la versione e l'utilizzo della TPU. Livello 2: mostra l'utilizzo della TPU, il tempo di inattività della TPU e il numero di core TPU utilizzati. Fornisce anche i tempi di passaggio minimi, medi e massimi, nonché il contributo percentuale in-feed.--duration_ms(facoltativo, il valore predefinito è 1000 ms) specifica il tempo per eseguire il profiling dell'host TPU durante ogni ciclo. In genere, deve essere lungo sufficiente per acquisire dati per almeno un passaggio di addestramento. 1 secondo acquisisce un passaggio di addestramento nella maggior parte dei modelli, ma se il tempo molto grande, puoi impostare il valore su 2xstep_time(in ms).--num_queriesspecifica il numero di cicli da eseguirecapture_tpu_profile. Per monitorare continuamente il job TPU, imposta il valore su un numero alto. Per controllare rapidamente il tempo del passaggio del modello, imposta il valore su un numero basso.