Cloud TPU 노드에서 모델 프로파일링
모델을 프로파일링하면 Cloud TPU에서 학습 성능을 최적화할 수 있습니다. 모델을 프로파일링하려면 텐서보드와 Cloud TPU 텐서보드 플러그인을 사용합니다. 설치 안내는 텐서보드 설치 안내를 참조하세요.
지원되는 프레임워크 중 하나에서 텐서보드를 사용하는 방법에 대한 자세한 내용은 다음 문서를 참조하세요.
기본 요건
텐서보드는 TensorFlow의 일부로 설치됩니다. TensorFlow는 기본적으로 Cloud TPU 노드에 설치됩니다. TensorFlow를 수동으로 설치할 수도 있습니다. 어느 쪽이든 추가 종속 항목이 필요할 수 있습니다. 다음을 실행하여 설치합니다.
(vm)$ pip3 install --user -r /usr/share/models/official/requirements.txt
Cloud TPU 텐서보드 플러그인 설치
TPU 노드에 SSH를 통해 연결합니다.
$ gcloud compute ssh your-vm --zone=your-zone
다음 명령어를 실행합니다.
pip3 install --upgrade "cloud-tpu-profiler>=2.3.0" pip3 install --user --upgrade -U "tensorboard>=2.3" pip3 install --user --upgrade -U "tensorflow>=2.3"
프로필 캡처
텐서보드 UI를 사용하거나 프로그래매틱 방식으로 프로필을 캡처할 수 있습니다.
텐서보드를 사용하여 프로필 캡처
텐서보드를 시작하면 웹 서버가 시작됩니다. 브라우저에서 텐서보드 URL을 가리키면 웹페이지가 표시됩니다. 웹페이지를 사용하면 수동으로 프로필을 캡처하고 프로필 데이터를 볼 수 있습니다.
TensorFlow 프로파일러 서버 시작
tf.profiler.experimental.server.start(6000)
그러면 TPU VM에서 TensorFlow 프로파일러 서버가 시작됩니다.
학습 스크립트 시작
학습 스크립트를 실행하고 모델이 적극적으로 학습되고 있음을 나타내는 출력이 나타날 때까지 기다립니다. 코드와 모델에 따라 표시되는 내용이 다릅니다. Epoch 1/100과 같은 출력을 찾습니다. 또는 Google Cloud 콘솔의 Cloud TPU 페이지로 이동하여 TPU를 선택하고 CPU 사용률 그래프를 봅니다. TPU 사용률이 표시되지는 않지만 TPU에서 모델을 학습시키고 있음을 나타내는 것은 좋은 지표입니다.
텐서보드 서버 시작
새 터미널 창을 열고 포트 전달을 사용하여 TPU VM에 SSH를 통해 연결합니다. 이렇게 하면 로컬 브라우저가 TPU VM에서 실행 중인 텐서보드 서버와 통신할 수 있습니다.
gcloud compute tpus execution-groups ssh your-vm --zone=us-central1-a --ssh-flag="-4 -L 9001:localhost:9001"
방금 연 터미널 창에서 텐서보드를 실행하고 텐서보드가 --logdir 플래그를 사용하여 프로파일링 데이터를 쓸 수 있는 디렉터리를 지정합니다. 예를 들면 다음과 같습니다.
TPU_LOAD_LIBRARY=0 tensorboard --logdir your-model-dir --port 9001
텐서보드에서 웹 서버를 시작하고 URL을 표시합니다.
Serving TensorBoard on localhost; to expose to the network, use a proxy or pass --bind_all TensorBoard 2.3.0 at http://localhost:9001/ (Press CTRL+C to quit)
웹브라우저를 열고 텐서보드 출력에 표시된 URL로 이동합니다. 텐서보드 페이지의 오른쪽 상단에 있는 새로고침 버튼을 클릭하여 텐서보드가 프로파일링 데이터를 완전히 로드했는지 확인합니다. 기본적으로 텐서보드 페이지에 스칼라 탭이 표시됩니다.
TPU 노드에서 프로필 캡처
- 화면 상단에 있는 드롭다운 메뉴에서 프로필을 선택합니다.
- 프로필 캡처 버튼을 선택합니다.
- TPU 이름 라디오 버튼을 선택합니다.
- TPU 이름을 입력합니다.
- 캡처 버튼을 선택합니다.
프로그래매틱 방식으로 프로필 캡처
프로그래매틱 방식으로 프로필을 캡처하는 방법은 사용하고 있는 ML 프레임워크에 따라 다릅니다.
TensorFlow를 사용하는 경우 각각 tf.profiler.experimental.start() 및 tf.profiler.experimental.stop()을 사용하여 프로파일러를 시작하고 중지합니다. 자세한 내용은 TensorFlow 성능 가이드를 참조하세요.
JAX를 사용하는 경우 jax.profiler.start_trace() 및 jax.profiler.stop_trace()를 사용하여 각각 프로파일러를 시작하고 중지합니다. 자세한 내용은 JAX 프로그램 프로파일링을 참조하세요
프로필 일반 문제 캡처
trace를 캡처하려고 할 때 다음과 같은 메시지가 표시되는 경우가 있습니다.
No trace event is collected after xx attempt(s). Perhaps, you want to try again
(with more attempts?).Tip: increase number of attempts with --num_tracing_attempts.
Failed to capture profile: empty trace result
TPU가 계산을 활발히 수행하고 있지 않거나 학습 단계에 시간이 너무 오래 걸리는 경우 또는 다른 이유로 발생할 수 있습니다. 이 메시지가 표시되면 다음을 수행합니다.
- 몇 세대 실행 후에 프로필을 캡처해 보세요.
- 텐서보드 캡처 프로필 대화상자에서 프로파일링 기간을 늘려봅니다. 학습 단계에 시간이 너무 오래 걸릴 수 있습니다.
- VM과 TPU 모두에서 TF 버전이 동일한지 확인합니다.
텐서보드로 프로필 데이터 보기
일부 모델 데이터를 캡처한 후 프로필 탭이 표시됩니다. 텐서보드 페이지의 오른쪽 상단에 있는 새로고침 버튼을 클릭해야 할 수도 있습니다. 데이터를 사용할 수 있게 되면 프로필 탭을 클릭할 때 성능 분석에 유용한 몇 가지 도구가 제공됩니다.
- 개요 페이지
- Trace 뷰어(Chrome 브라우저만 해당)
- 스트리밍 trace 뷰어(Chrome 브라우저만 해당)
Trace 뷰어
trace 뷰어는 프로필 아래에서 사용할 수 있는 Cloud TPU 성능 분석 도구입니다. 이 도구는 Chrome trace 이벤트 프로파일링 뷰어를 사용하므로 Chrome 브라우저에서만 작동합니다.
trace 뷰어에 표시되는 타임라인은 다음과 같은 정보를 제공합니다.
- TensorFlow 모델에 의해 실행된 작업의 기간
- 작업을 실행한 시스템의 부분(TPU 또는 호스트 머신). 일반적으로 호스트 머신은 학습 데이터를 사전 처리하여 TPU로 전송하는 인피드 작업을 실행하고, TPU는 실제 모델 학습을 실행합니다.
trace 뷰어를 사용하면 모델의 성능 문제를 파악한 후 해결을 위한 조치를 취할 수 있습니다. 예를 들어 대부분의 시간을 소비하는 부분이 인피드인지, 모델 학습인지 대략적으로 파악할 수 있습니다. 자세히 살펴보면 가장 오랜 시간 실행된 TensorFlow 작업을 파악할 수 있습니다.
trace 뷰어는 Cloud TPU당 1M개의 이벤트로 제한됩니다. 더 많은 이벤트에 액세스해야 하는 경우 스트리밍 trace 뷰어를 대신 사용하세요.
trace 뷰어 인터페이스
trace 뷰어를 열려면 텐서보드로 이동하여 화면 상단의 프로필 탭을 클릭하고 도구 드롭다운에서 trace_viewer를 선택합니다. 뷰어에 가장 최근의 실행 정보가 표시됩니다.
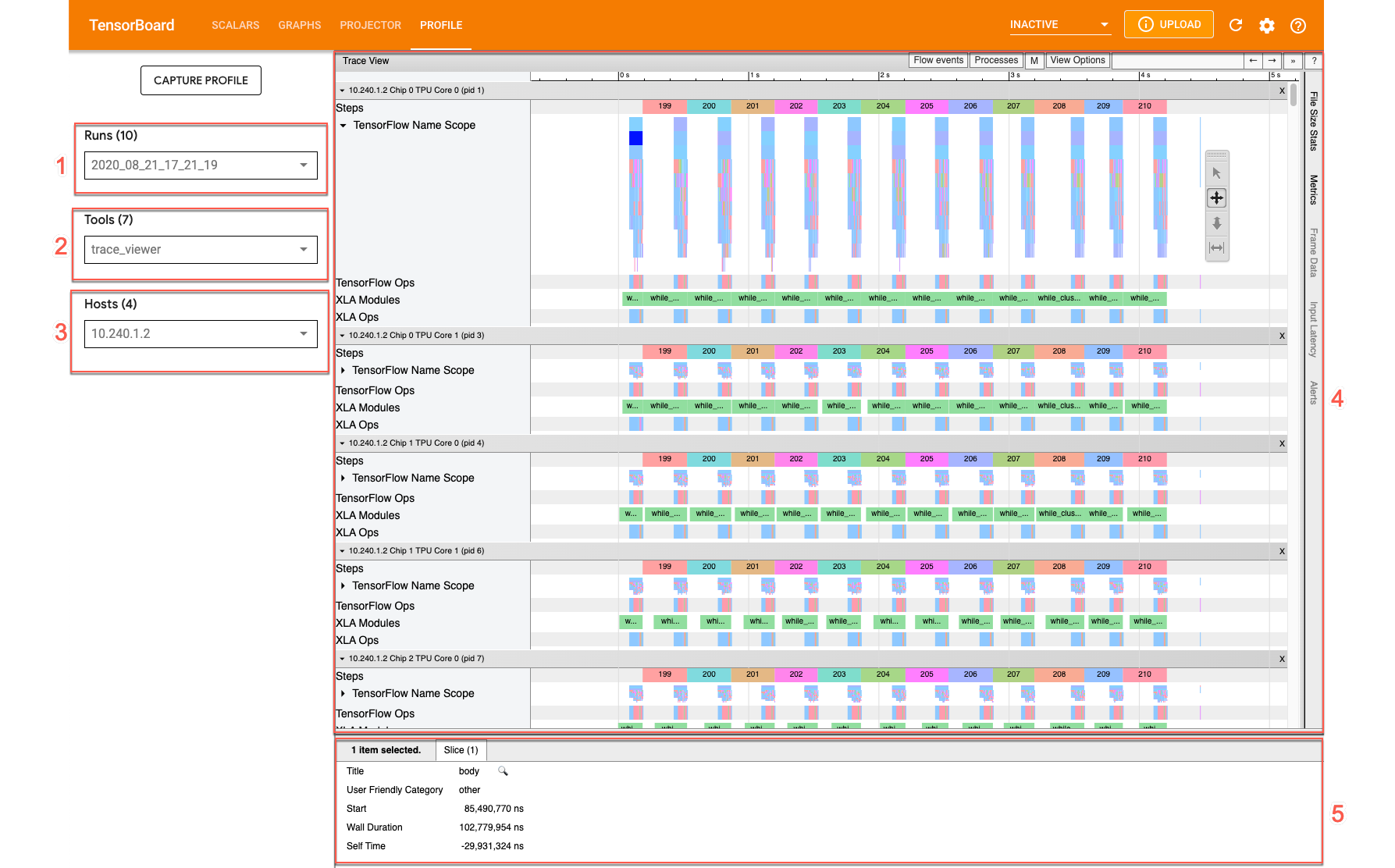
이 화면에는 다음과 같은 주요 요소가 포함되어 있습니다(위에 표시된 숫자 참고).
- 실행 드롭다운. trace 정보를 캡처한 모든 실행이 포함됩니다. 기본 보기는 가장 최근의 실행이지만 드롭다운을 열어 다른 실행을 선택할 수 있습니다.
- 도구 드롭다운. 다양한 프로파일링 도구를 선택합니다.
- 호스트 드롭다운. Cloud TPU 세트가 포함된 호스트를 선택합니다.
- 타임라인 창. Cloud TPU와 호스트 머신이 일정한 시간 동안 실행한 작업이 표시됩니다.
- 세부정보 창. 타임라인 창에서 선택한 작업의 추가 정보를 표시합니다.
타임라인 창을 자세히 보면 다음과 같습니다.
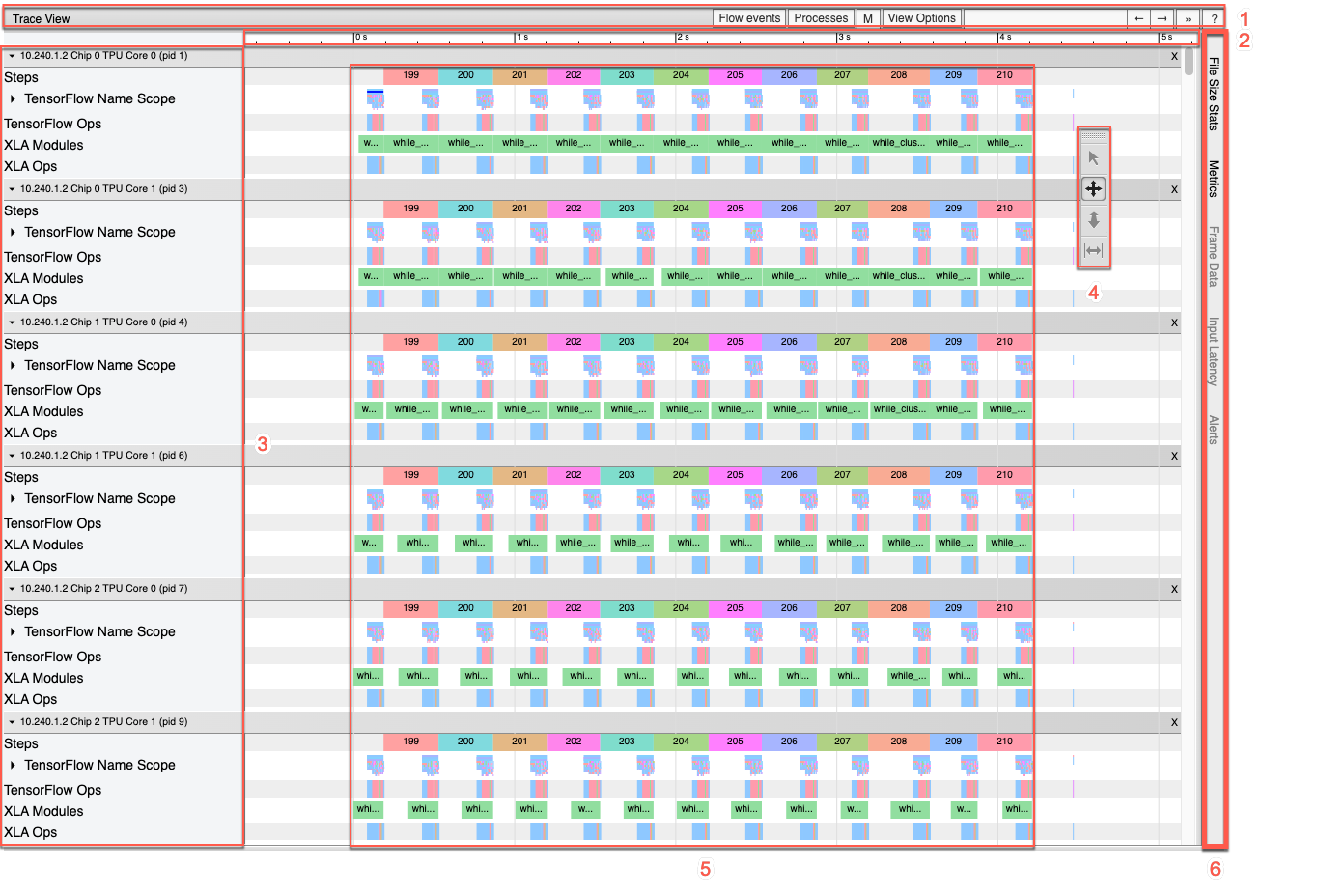
타임라인 창에는 다음과 같은 요소가 포함되어 있습니다.
- 상단 막대. 다양한 보조 제어 도구가 포함되어 있습니다.
- 시간 축. trace의 시작을 기준으로 한 상대 시간이 표시됩니다.
- 섹션 및 추적 라벨. 섹션마다 여러 트랙이 포함되어 있으며 왼쪽의 삼각형을 클릭하면 섹션을 펼치거나 접을 수 있습니다. 시스템의 모든 처리 요소마다 섹션이 하나씩 있습니다.
- 도구 선택기. trace 뷰어와 연동되는 여러 도구가 포함되어 있습니다.
- 이벤트. 이 영역은 작업이 실행된 시간 또는 학습 단계와 같은 메타 이벤트 기간을 표시합니다.
- 세로 탭 막대. Cloud TPU에서는 별다른 용도가 없습니다. 이 막대는 다양한 성능 분석 작업에 사용되는 Chrome이 제공하는 범용 trace 뷰어 도구의 일부입니다.
섹션 및 트랙
trace 뷰어에는 다음과 같은 섹션이 포함되어 있습니다.
- 각 TPU 노드에 대한 하나의 섹션. TPU 칩 번호와 칩 내의 TPU 노드 라벨이 지정됩니댜(예: 'Chip 2: TPU Core 1'). 각 TPU 노드 섹션에는 다음과 같은 트랙이 포함됩니다.
- 단계. TPU에서 실행 중이었던 학습 단계의 지속 시간을 나타냅니다.
- TensorFlow 작업. TPU에서 실행된 TensorFlow 작업을 표시합니다.
- XLA 작업. TPU에서 실행된 XLA 작업을 보여줍니다. 각 작업은 하나 이상의 XLA 작업으로 해석됩니다. XLA 컴파일러는 XLA 작업을 TPU에서 실행되는 코드로 변환합니다.)
- 호스트 머신의 CPU에서 실행되는 스레드에 대한 하나의 섹션. '호스트 스레드' 라벨이 지정됩니다. 섹션에는 각 CPU 스레드마다 하나의 트랙이 포함됩니다. 참고: 섹션 라벨 옆에 표시되는 정보는 무시해도 됩니다.
타임라인 도구 선택기
텐서보드의 타임라인 도구 선택기를 사용하여 타임라인 보기를 조작할 수 있습니다. 타임라인 도구를 클릭하거나 다음 단축키를 사용하여 도구를 활성화하고 강조표시할 수 있습니다. 타임라인 도구 선택기를 옮기려면 상단의 점으로 영역을 클릭한 다음 원하는 곳으로 선택기를 드래그합니다.
타임라인 도구를 다음과 같이 사용합니다.
|
선택 도구 이벤트를 클릭하여 선택하거나 드래그하여 여러 이벤트를 선택합니다. 선택한 이벤트에 관한 자세한 정보(이름, 시작 시간, 지속 시간)가 세부정보 창에 표시됩니다. |
|
화면 이동 도구 드래그하여 타임라인 보기를 가로와 세로 방향으로 이동합니다. |
|
확대/축소 도구 세로축(시간)을 따라 드래그하면 확대하거나 축소할 수 있습니다. 마우스 커서의 수평 위치가 확대/축소의 중심점을 결정합니다. 참고: 확대/축소 도구에는 마우스 커서가 타임라인 보기 밖에 있는 상태에서 마우스 버튼을 놓아도 이 기능이 계속 작동되는 알려진 버그가 있습니다. 이 문제가 발생하는 경우 타임라인 보기를 짧게 클릭하면 확대/축소 기능이 중지됩니다. |
|
타이밍 도구 가로 방향으로 드래그하여 시간 간격을 표시합니다. 시간 축에 간격 길이가 나타납니다. 간격을 조정하려면 가장자리를 드래그하면 됩니다. 간격을 삭제하려면 타임라인 보기의 아무 곳이나 클릭하세요. 다른 도구를 선택해도 간격은 표시된 상태로 유지됩니다. |




그래프
텐서보드는 모델 및 성능에 관한 여러 시각화 또는 그래프를 제공합니다. 그래프와 trace 뷰어 또는 스트리밍 trace 뷰어를 함께 사용하면 모델을 미세 조정하고 Cloud TPU의 성능을 개선할 수 있습니다.
모델 그래프
모델링 프레임워크는 모델에서 그래프를 생성할 수 있습니다. 이 그래프의 데이터는 개발자가 --logdir 매개변수로 지정하는 스토리지 버킷의 MODEL_DIR 디렉터리에 저장됩니다. capture_tpu_profile을 실행하지 않고 이 그래프를 볼 수 있습니다.
모델의 그래프를 보려면 텐서보드에서 그래프 탭을 선택합니다.
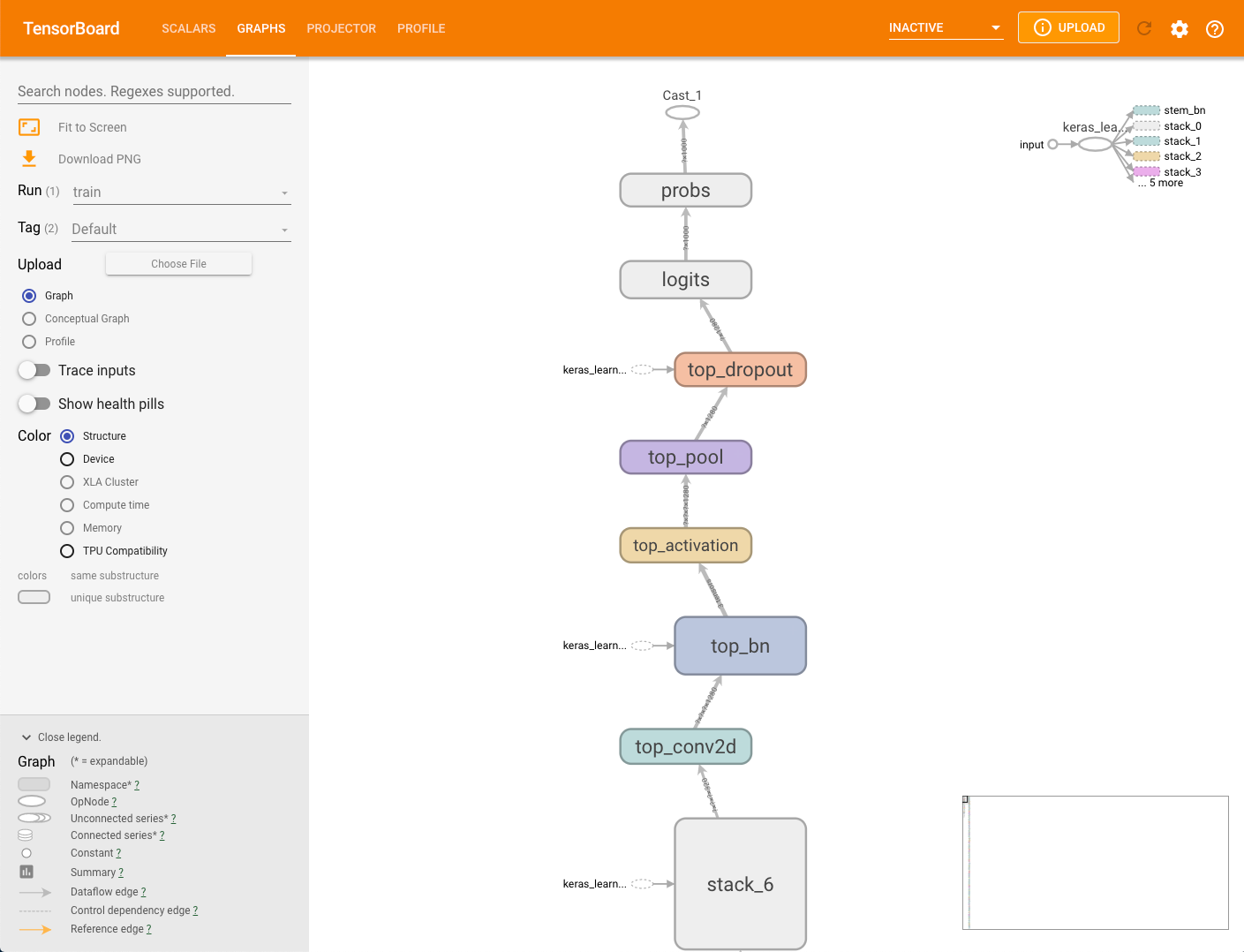
구조 그래프에서 하나의 노드는 작업 하나를 나타냅니다.
TPU 호환성 그래프
그래프 탭에는 모델이 실행될 때 문제를 일으킬 가능성이 있는 작업을 확인하고 표시하는 호환성 검사기 모듈이 있습니다.
모델의 TPU 호환성 그래프를 보려면 텐서보드에서 그래프 탭을 선택한 다음 TPU Compatibility(TPU 호환성) 옵션을 선택합니다. 그래프에서 호환되는(유효한) 작업은 녹색으로, 호환되지 않는(무효한) 작업은 빨간색으로 표시됩니다.
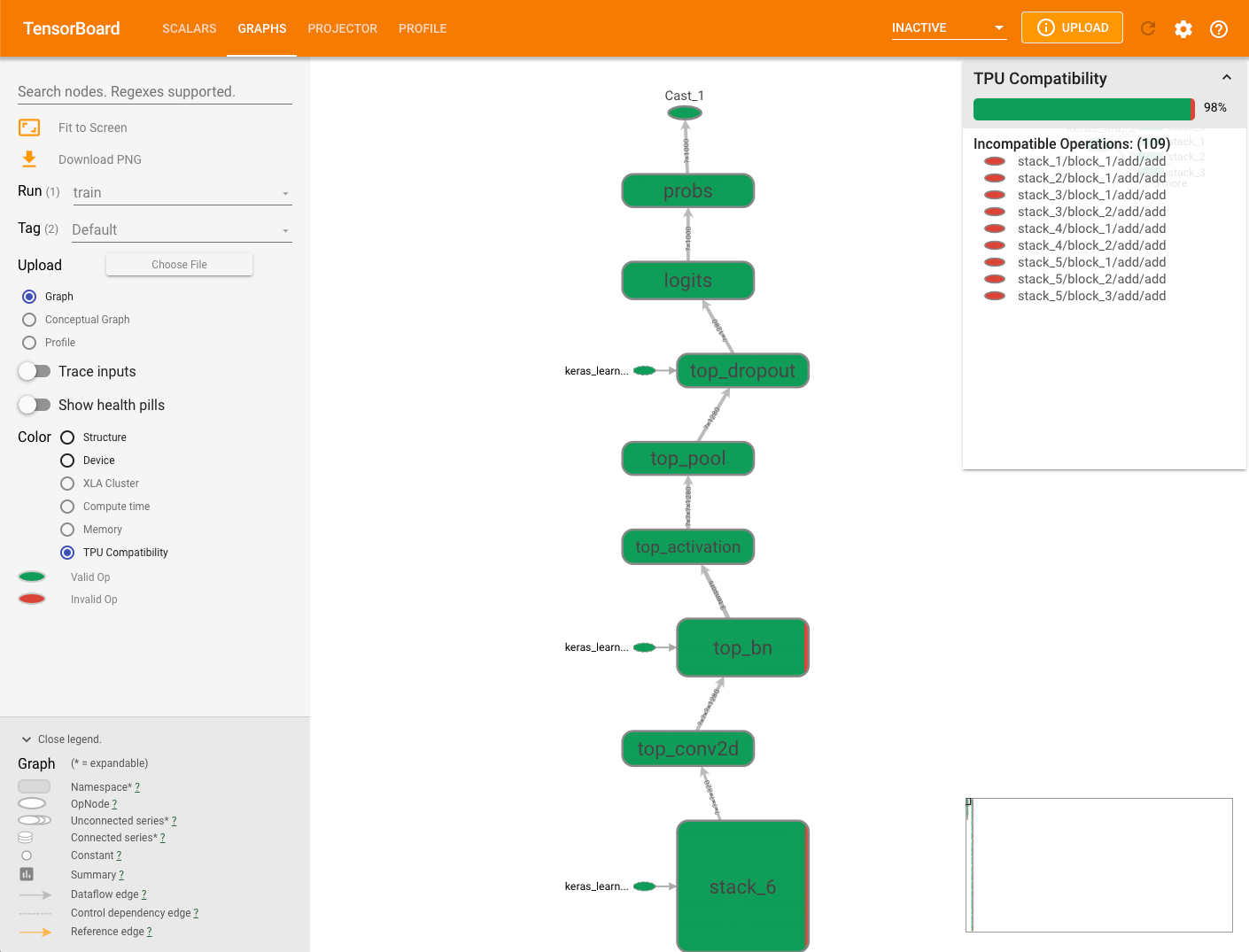
특정 노드에서 두 가지 색상이 각각 해당 노드에 대한 Cloud TPU 호환성 작업의 비율로 모두 표시될 수 있습니다. 호환성 결과 해석의 예시를 참조하세요.
그래프 오른쪽에 표시되는 호환성 요약 패널에는 모든 Cloud TPU 호환 작업의 비율, 해당 속성, 선택된 노드의 호환되지 않는 작업 목록이 표시됩니다.
그래프의 작업을 클릭하면 요약 패널에 해당 속성이 표시됩니다.
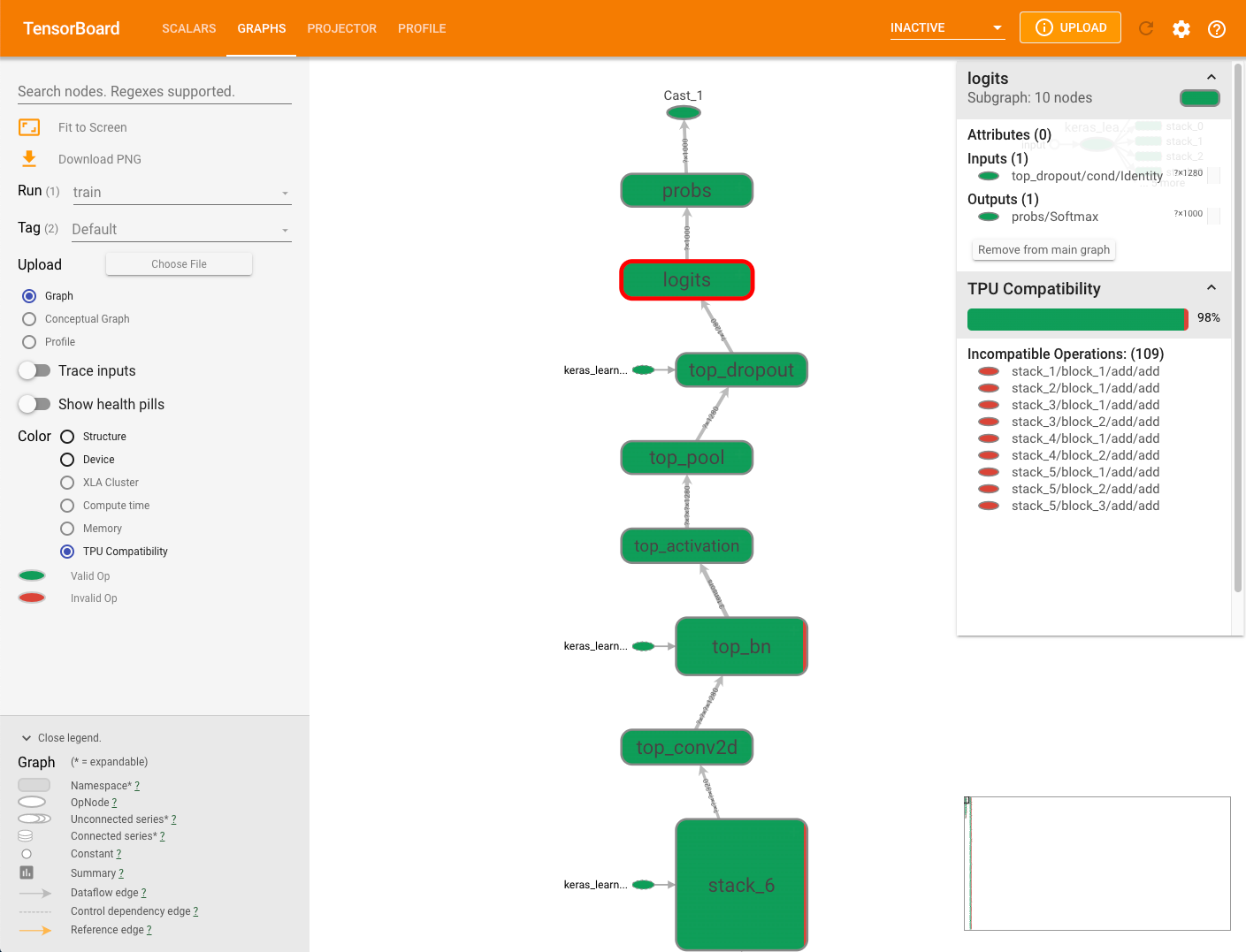
호환성 검사기는 수동 기기 배치를 사용하여 TPU 이외의 기기에 명시적으로 할당된 작업은 평가하지 않습니다. 또한 검사기는 실행을 위해 실제로 모델을 컴파일하지는 않으므로 결과를 호환성의 추정치로 해석해야 합니다.
호환성 결과 해석
프로필
일부 모델 데이터를 캡처한 후 프로필 탭이 표시됩니다. 텐서보드 페이지의 오른쪽 상단에 있는 새로고침 버튼을 클릭해야 할 수도 있습니다. 데이터를 사용할 수 있게 되면 프로필 탭을 클릭할 때 성능 분석에 유용한 몇 가지 도구가 제공됩니다.
- 개요 페이지
- 입력 파이프라인 분석기
- XLA 작업 프로필
- Trace 뷰어(Chrome 브라우저만 해당)
- 메모리 뷰어
- 포드 뷰어
- 스트리밍 trace 뷰어(Chrome 브라우저만 해당)
프로필 개요 페이지
프로필 아래에 있는 개요 페이지(overview_page)는 캡처 실행 동안의 모델 성능에 대한 최상위 보기를 제공합니다. 이 페이지에는 모든 TPU에 대한 집계된 개요 페이지와 전체적인 입력 파이프라인 분석이 표시됩니다. 호스트 드롭다운에는 개별 TPU 선택을 위한 옵션이 있습니다.
페이지의 다음 패널에 데이터가 표시됩니다.
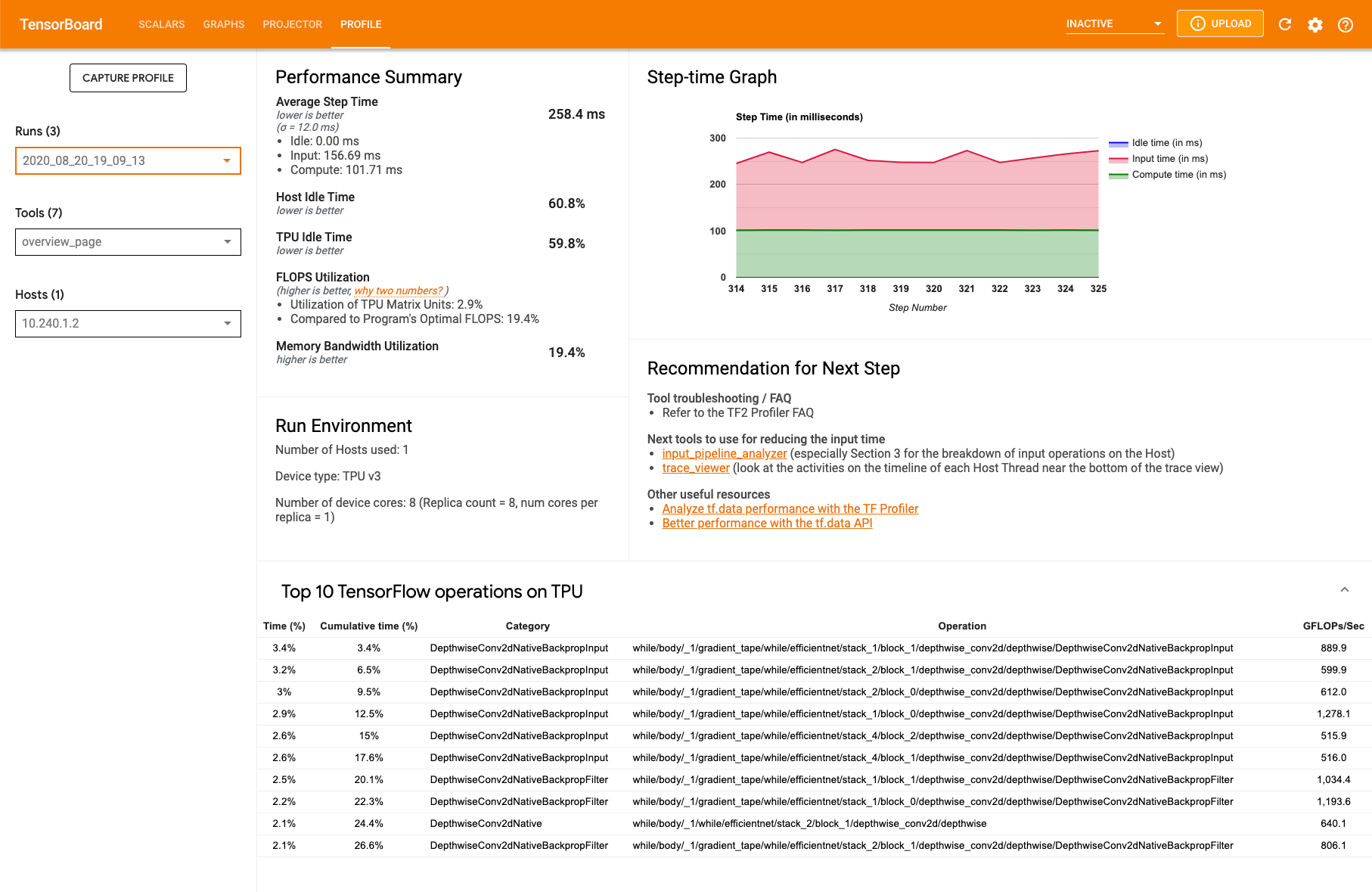
Performance summary(성능 요약)
- 평균 단계 시간 - 샘플링된 모든 단계에서 평균화한 단계 시간
- 호스트 유휴 시간 - 호스트가 유휴 상태였던 시간의 비율
- TPU 유휴 시간 - TPU가 유휴 상태였던 시간의 비율
- FLOPS 사용률 - TPU 행렬 단위의 사용 비율
- 메모리 대역폭 사용률 - 사용한 메모리 대역폭 비율
Step-time graph(단계-시간 그래프). 샘플링된 모든 단계에서 기기 단계 시간 그래프를 밀리초 단위로 표시합니다. 파란색 영역은 TPU가 호스트로부터 입력 데이터를 대기하며 유휴 상태였던 단계 시간에 해당합니다. 빨간색 영역은 Cloud TPU가 실제로 작업한 시간이 얼만큼인지를 보여줍니다.
Top 10 TensorFlow operations on TPU(TPU의 상위 10개 TensorFlow 작업). 가장 많은 시간을 소비한 TensorFlow 작업을 표시합니다.
각 행은 작업의 자체 시간(모든 작업에 소비된 시간의 비율로), 누적 시간, 카테고리, 이름, 달성한 FLOPS 등급을 표시합니다.
Run environment(실행 환경)
- 사용된 호스트 수
- 사용된 TPU 유형
- TPU 코어 수
- 학습 배치 크기
Recommendation for next steps(다음 단계를 위한 권장사항). 모델이 입력 제약적일 때와 Cloud TPU에서 문제가 발생할 때마다 보고합니다. 성능 병목 지점을 찾는데 사용할 수 있는 도구를 제안합니다.
입력 파이프라인 분석기
입력 파이프라인 분석기는 성능 결과에 대한 유용한 정보를 제공합니다. 도구는 capture_tpu_profile 도구에서 수집한 input_pipeline.json 파일의 성능 결과를 표시합니다.
도구는 프로그램이 입력 제약적인지 여부를 즉시 알려주며, 병목 현상을 일으키는 파이프라인의 단계를 디버깅할 수 있도록 기기 및 호스트 측 분석으로 안내합니다.
파이프라인 성능 최적화에 대한 자세한 내용은 입력 파이프라인 성능에 대한 안내를 참조하세요.
입력 파이프라인
TensorFlow 프로그램은 파일에서 데이터를 읽을 때 파이프라인 방식으로 TensorFlow 그래프의 맨 위부터 시작합니다. 읽기 프로세스는 직렬로 연결된 여러 데이터 처리 단계로 나뉘며, 한 단계의 출력이 다음 단계의 입력이 되는 방식입니다. 이 읽기 시스템을 입력 파이프라인이라고 합니다.
일반적으로 파일의 레코드를 읽는 파이프라인은 다음 단계를 거칩니다.
- 파일 읽기
- 파일 사전 처리(선택 사항)
- 호스트 머신에서 기기로 파일 전송
입력 파이프라인이 비효율적이면 애플리케이션 속도가 현저히 떨어질 수 있습니다. 애플리케이션이 입력 파이프라인에 많은 시간을 소요하는 경우 입력 제약적인 것으로 간주됩니다. 입력 파이프라인 분석기를 사용하여 입력 파이프라인에서 비효율적인 부분을 파악합니다.
입력 파이프라인 대시보드
입력 파이프라인 분석기를 열려면 프로필을 선택한 다음 도구 드롭다운에서 input_pipeline_analyzer를 선택합니다.
대시보드에는 섹션이 3개 있습니다.
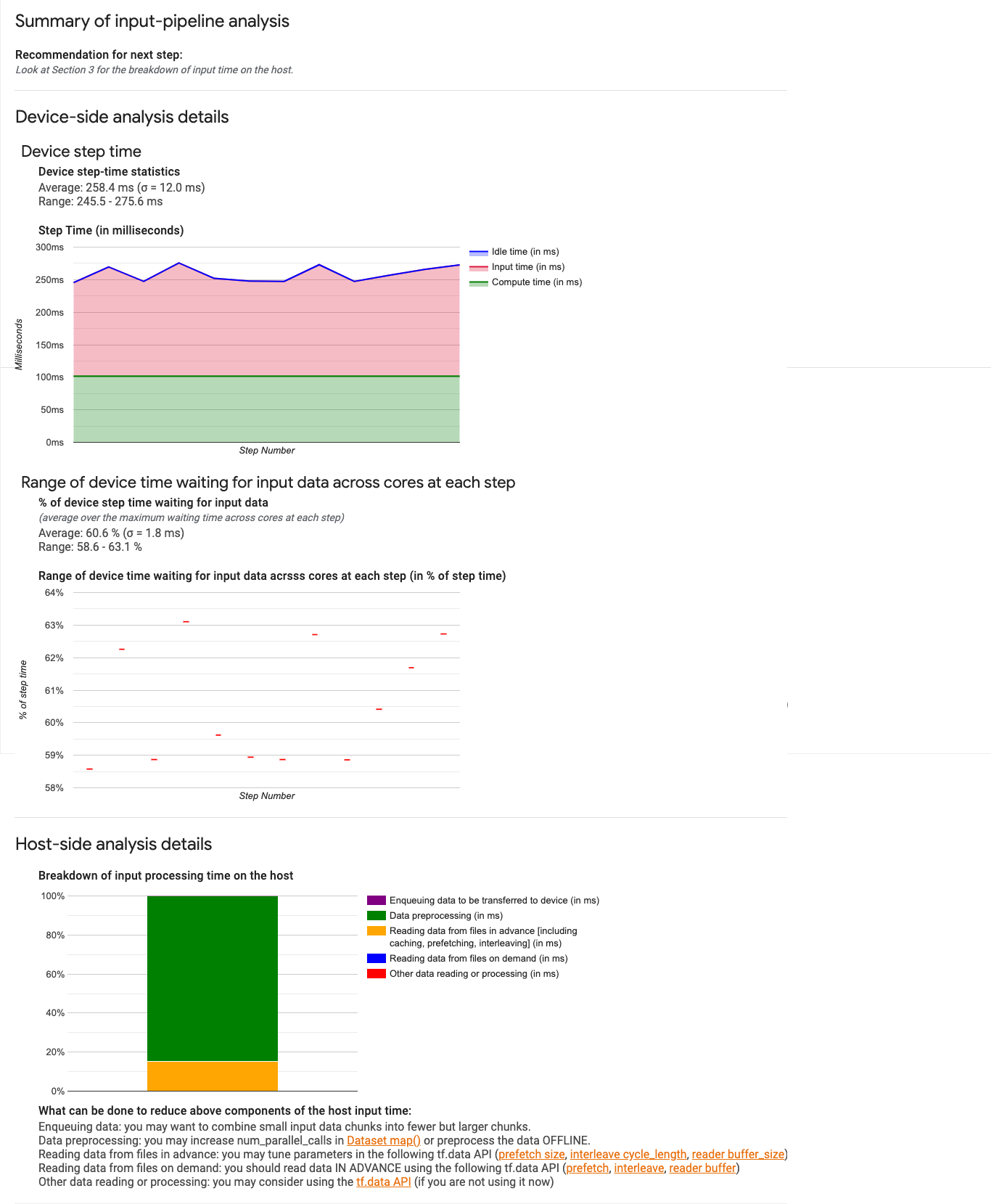
- 요약. 전체적인 입력 파이프라인을 요약하며, 애플리케이션이 입력 제약적인지 여부와 그렇다면 얼만큼 입력 제약적인지에 관한 정보를 제공합니다.
- 기기측 분석. 각 단계에서 코어에 걸쳐 기기가 입력 데이터를 대기하는 데 소비한 시간 범위와 기기 단계-시간을 포함한 세부적인 기기측 분석 결과를 표시합니다.
- 호스트측 분석. 호스트에서의 입력 처리 시간 세부 내역을 포함한 세부적인 호스트측 분석을 표시합니다.
입력 파이프라인 요약
첫 번째 섹션은 호스트의 입력을 대기하는 데 소비한 기기 시간의 비율을 제공하여 프로그램이 입력 제약적인지 여부를 보고합니다. 계측된 표준 입력 파이프라인을 사용하는 경우 도구는 입력 처리 시간이 가장 많이 소비된 부분을 보고합니다. 예를 들면 다음과 같습니다.

기기측 분석
두 번째 섹션에서는 기기측 분석을 세분화하여 기기에서 소비한 시간과 호스트에서 소비한 시간, 호스트의 입력 데이터를 대기하면서 소비한 기기 시간에 대한 유용한 정보를 제공합니다.
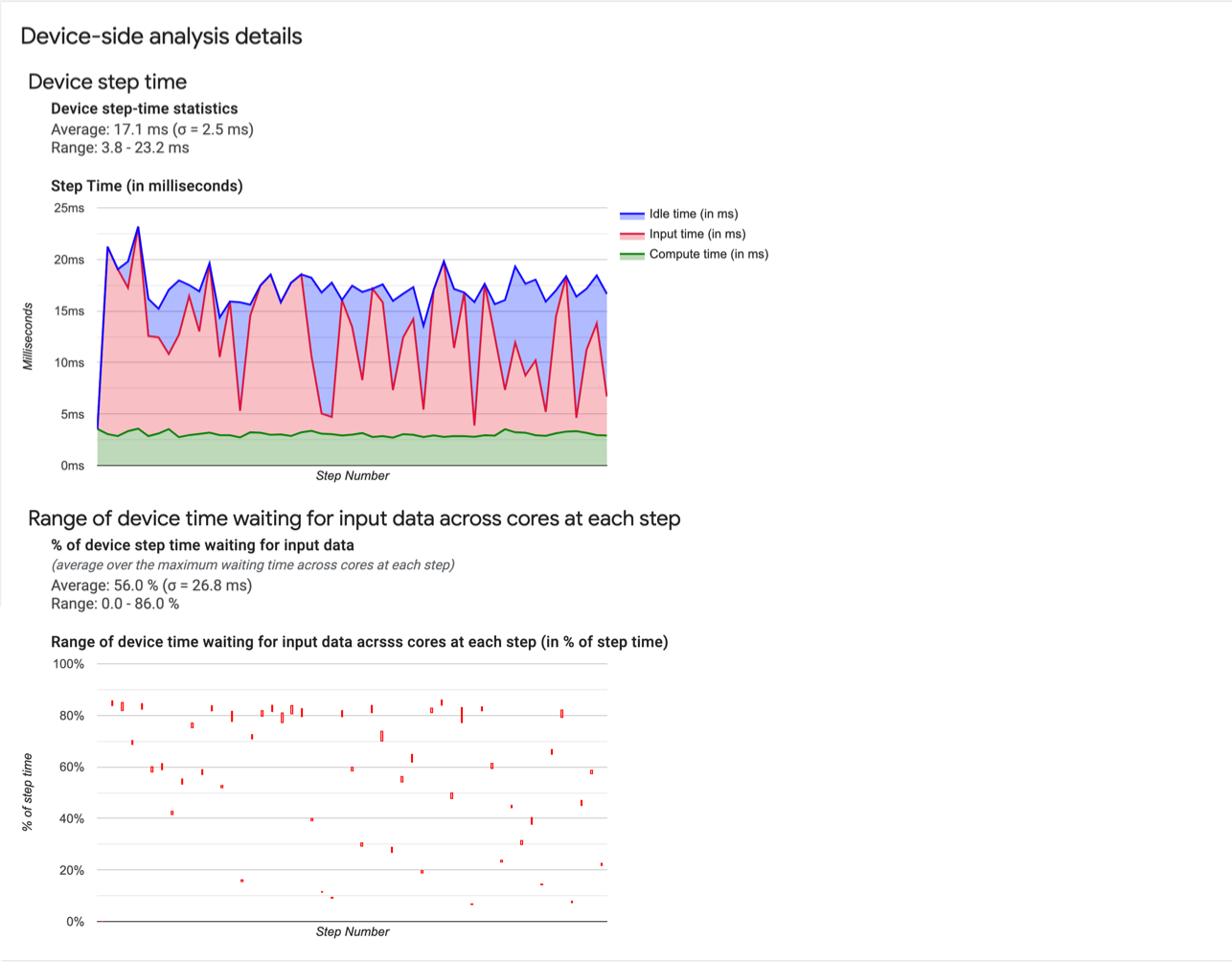
- 기기 단계 시간 통계 기기 단계 시간의 평균, 표준편차, 범위(최솟값, 최댓값)를 보고합니다.
- 단계 시간 샘플링된 모든 단계에서 기기 단계 시간 그래프를 밀리초 단위로 표시합니다. 파란색 영역은 TPU가 호스트로부터 입력 데이터를 대기하며 유휴 상태였던 단계 시간에 해당합니다. 빨간색 영역은 Cloud TPU가 실제로 작업한 시간이 얼만큼인지를 보여줍니다.
- 입력 데이터를 대기하면서 소비한 시간 비율. 총 기기 단계 시간 대비, 정규화된 입력 데이터를 대기하는 데 기기에서 소비한 시간 비율의 평균, 표준 편차, 범위(최솟값, 최댓값)를 보고합니다.
- 코어에 걸쳐 입력 데이터를 대기하는 데 소비한 기기 시간의 범위(단계 번호별). 입력 데이터 처리를 대기하면서 소비한 기기 시간의 양(총 기기 단계 시간의 비율로 표현)을 보여주는 선 차트를 표시합니다. 소비한 시간의 비율은 코어마다 다르므로 각 단계에 대해 각 코어의 비율 범위도 차트에 표시됩니다. 단계에 소비된 시간은 가장 느린 코어에 의해 결정되므로 범위는 최대한 작은 것이 좋습니다.
호스트측 분석
섹션 3은 호스트의 입력 처리 시간(Dataset API 작업 소요 시간)을 여러 카테고리로 나누어 보고하는 호스트측 분석 세부정보를 보여줍니다.
- 기기로 전송될 데이터 큐에 추가 데이터를 기기에 전송하기 전에 인피드 큐에 넣는 데 소비한 시간
- 데이터 사전 처리. 이미지 압축 해제와 같은 사전 처리 작업에 소비한 시간
- 사전에 파일에서 데이터 읽기. 캐싱, 미리 가져오기, 인터리브를 포함하여 파일을 읽는 데 소비한 시간
- 주문에 따라 파일에서 데이터 읽기. 캐싱, 미리 가져오기, 인터리브 없이 파일에서 데이터를 읽는 데 소비한 시간
- 기타 데이터 읽기 또는 처리
tf.data를 사용하지 않는 다른 입력 관련 작업에서 소비한 시간

개별 입력 작업의 통계와 각 카테고리를 실행 시간별로 세분화해서 보려면 'Show Input Op statistics(입력 작업 통계 보기)' 섹션을 펼칩니다.
다음과 같은 소스 데이터 테이블이 표시됩니다.
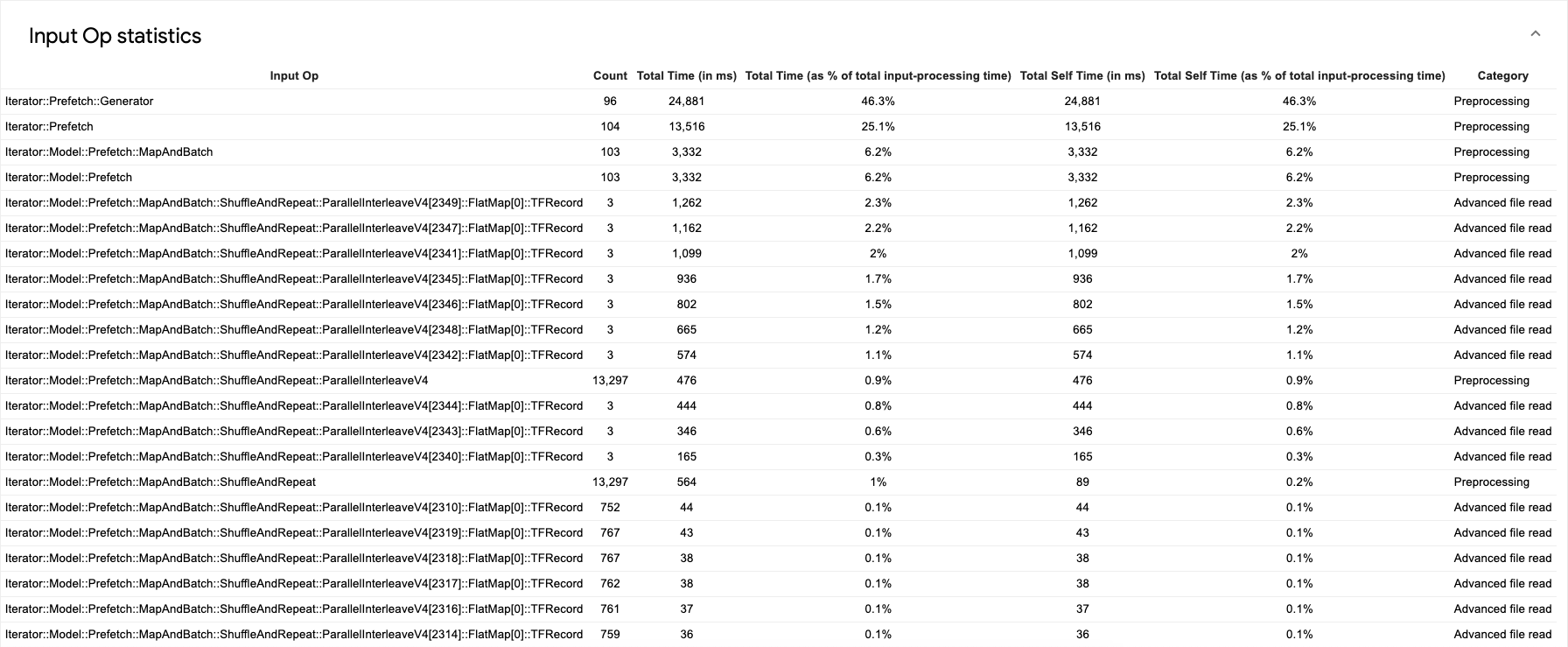
각 표 항목에는 다음과 같은 정보가 포함되어 있습니다.
- Input Op(입력 작업). 입력 작업의 TensorFlow 작업 이름을 표시합니다.
- Count(개수). 프로파일링 기간 동안 실행된 작업 인스턴스의 총 수를 표시합니다.
- Total Time (in ms)(총 시간(밀리초)). 각 작업 인스턴스에 소요된 시간의 누적 합계를 표시합니다.
- Total Time %(총 시간 비율). 입력 처리에 소요된 총 시간 비율로 해당 작업에 소요된 총 시간을 표시합니다.
- Total Self Time (in ms)(총 자체 시간(밀리초)). 각 인스턴스에 소요된 자체 소요 시간의 누적 합계를 표시합니다. 자체 소요 시간은 호출 대상 함수에 소요된 시간을 제외하고 함수 본문 내에 소요된 시간을 측정합니다.
예를 들어
Iterator::PaddedBatch::Filter::ForeverRepeat::Map는Iterator::PaddedBatch::Filter에 의해 호출되므로 총 자체 시간은 후자의 총 자체 시간에서 제외됩니다. - Total Self Time %(총 자체 소요 시간 비율). 입력 처리에 소요된 총 시간의 비율로 총 자체 시간을 표시합니다.
- Category(카테고리). 입력 작업의 처리 카테고리를 표시합니다.
작업 프로필
작업 프로필은 프로파일링 기간 동안 실행된 XLA 작업의 성능 통계를 표시하는 Cloud TPU 도구입니다. 작업 프로필에 표시되는 내용은 다음과 같습니다.
- 애플리케이션에서 Cloud TPU를 얼마나 잘 사용하는가(카테고리별로 작업에 소요된 시간의 비율 및 TPU FLOPS 사용률)
- 가장 많은 시간을 소비하는 작업. 이러한 작업은 잠재적 최적화 대상입니다.
- 작업을 사용하는 형태, 패딩, 표현식을 포함한 각 작업의 세부정보
작업 프로필을 사용하여 적절한 최적화 대상을 찾을 수 있습니다. 예를 들어 모델의 TPU 최고 FLOPS가 5%에 불과한 경우 이 도구를 사용하여 실행에 가장 많은 시간이 소비되는 XLA 작업과 이러한 작업이 소비하는 TPU FLOPS가 얼만큼인지를 식별할 수 있습니다.
작업 프로필 사용
프로필을 수집하는 동안 capture_tpu_profile은 XLA 작업의 성능 통계가 포함된 op_profile.json 파일도 생성합니다.
화면 상단의 프로필 탭을 클릭한 다음 도구 드롭다운에서 op_profile을 선택하여 텐서보드에서 op_profile의 데이터를 볼 수 있습니다. 표시되는 화면은 다음과 같습니다.
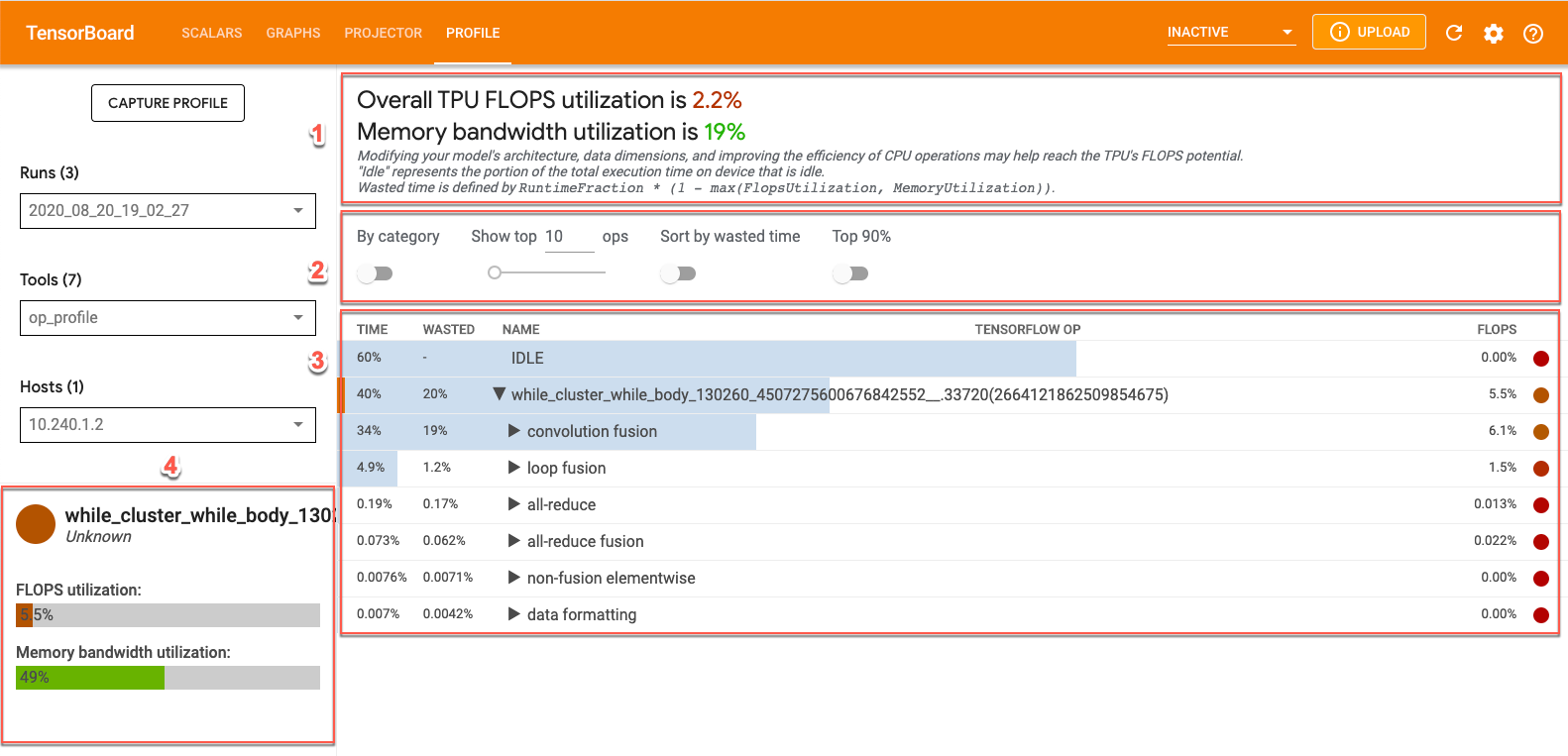
- 개요 섹션. Cloud TPU 사용률을 표시하고 최적화 방안을 제안합니다.
- 제어판. 테이블에 표시되는 작업 수, 표시되는 작업, 정렬 방법을 설정할 수 있는 컨트롤을 포함합니다.
- 작업 테이블. XLA 작업과 관련된 상위 TensorFlow 작업 카테고리를 나열하는 테이블입니다. Cloud TPU 사용량 비율에 따라 작업이 정렬됩니다.
- 작업 세부정보 카드. 테이블의 작업으로 마우스를 가져갈 때 표시되는 작업에 대한 세부정보. 여기에는 FLOPS 사용률, 작업이 사용된 표현식, 작업 레이아웃(핏)이 포함됩니다.
XLA 작업 테이블
작업 테이블에는 XLA 작업 카테고리가 Cloud TPU 사용량 비율 내림차순으로 나열됩니다. 처음에는 소비된 시간 비율, 작업 카테고리 이름, 연결된 TensorFlow 작업 이름, 해당 카테고리의 FLOPS 사용량 비율이 테이블에 표시됩니다. 카테고리에서 가장 많은 시간을 소비하는 상위 10개 XLA 작업을 표시하거나 숨기려면 테이블에서 카테고리 이름 옆의 삼각형을 클릭합니다.
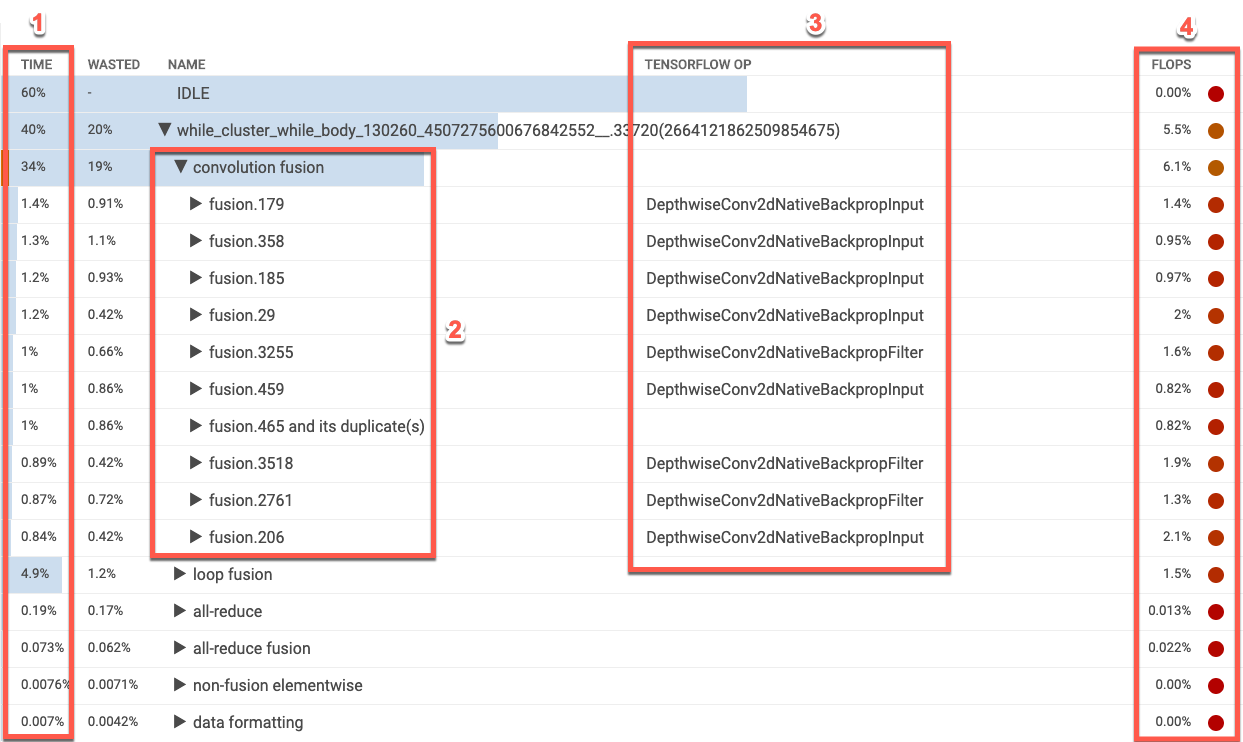
- 시간. 이 카테고리의 모든 작업에서 소요된 시간의 총 비율을 보여줍니다. 항목을 클릭하여 펼치면 개별 작업에 소요된 시간의 세부 내역을 확인할 수 있습니다.
- 상위 10개 작업: 카테고리 이름 옆의 토글은 카테고리 내에서 가장 많은 시간을 소비하는 상위 10개 작업을 표시하거나 숨깁니다. 작업 목록에 fusion 작업 항목이 표시되면 이를 확장하여 포함된 fusion 이외의 요소별 작업을 볼 수 있습니다.
- TensorFlow 작업: XLA 작업과 관련된 TensorFlow 작업 이름을 표시합니다.
- FLOPS. FLOPS 사용률을 표시합니다. FLOPS 사용률은 측정된 FLOPS 수이며, Cloud TPU 최고 FLOPS의 비율로 표현됩니다. FLOPS 사용률 비율이 높을수록 작업은 더 빠르게 실행됩니다. 테이블의 셀 색상은 FLOPS 사용률이 높으면 녹색으로(좋음), 사용률이 낮으면 빨간색으로(나쁨) 표시됩니다.
작업 세부정보 카드
테이블 항목을 선택하면 왼쪽에 카드가 나타나면서 XLA 작업 또는 작업 카테고리의 세부정보가 표시됩니다. 일반적인 카드의 모습은 다음과 같습니다.
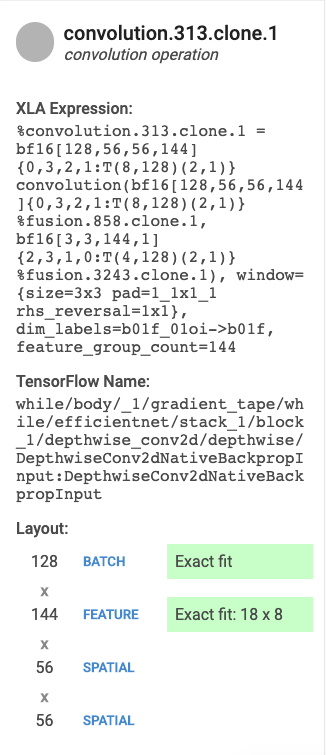
- 이름과 카테고리. 강조표시된 XLA 작업 이름과 카테고리를 표시합니다.
- FLOPS utilization(FLOPS 사용률). FLOPS 사용률을 가능한 총 FLOPS의 비율로 표시합니다.
- Expression(표현식). 작업이 포함된 XLA 표현식을 표시합니다.
- Memory Utilization(메모리 사용률). 프로그램의 최대 메모리 사용량 비율을 표시합니다.
- Layout(레이아웃)(컨볼루션 작업에만 해당) 텐서의 형태가 행렬 단위에 완전 적합인지 여부와 행렬의 패딩 방식을 포함한 텐서의 형태 및 레이아웃을 표시합니다.
결과 해석
컨볼루션 작업의 경우 다음 이유 중 하나 또는 두 가지 모두로 인해 TPU FLOPS 사용률이 낮을 수 있습니다.
- 패딩(행렬 단위가 부분적으로 사용됨)
- 컨볼루션 작업이 메모리 제약적
이 섹션에서는 FLOPS가 낮았던 다양한 모델의 몇 가지 수치를 해석합니다. 이 예시에서 출력 fusion과 컨볼루션이 실행 시간의 대부분을 점유했으며 FLOPS가 매우 낮은 벡터 또는 스칼라 작업의 롱테일이 있습니다.
이 프로필 유형을 위한 최적화 전략 중 하나는 벡터 또는 스칼라 작업을 컨볼루션 작업으로 변환하는 것입니다.
다음 예시에서 %convolution.399는 이전 예시의 %convolution.340에 비해 FLOPS와 메모리 사용률이 낮습니다.
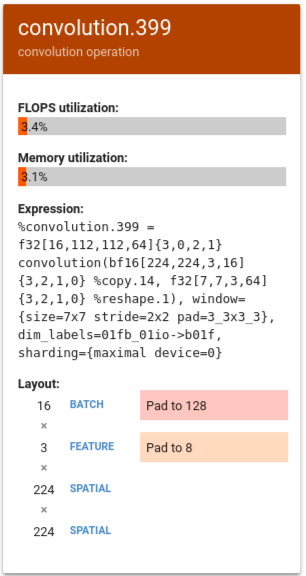
레이아웃을 살펴보면 배치 크기 16이 128로 패딩되고 특징 크기 3이 8로 패딩되는 것을 볼 수 있습니다. 이는 행렬 단위의 5%만 효과적으로 사용된다는 것을 나타냅니다. (이 비율 사용률 인스턴스의 계산은 (((batch_time * num_of_features) / padding_size ) / num_of_cores입니다.) 이 예시의 FLOPS를 행렬에 딱 맞는 이전 예시의 %convolution.340과 비교합니다.
포드 뷰어
포드 뷰어 도구는 포드의 모든 코어에 대한 성능 시각화를 제공하며 포드의 여러 코어에 걸쳐 통신 채널의 상태를 표시합니다. 포드 뷰어는 잠재적인 병목 지점과 최적화가 필요한 영역을 찾아서 강조표시할 수 있습니다. 이 도구는 전체 포드 및 모든 v2와 v3 포드 슬라이스에서 작동합니다.
포드 뷰어 도구를 표시하려면 다음 안내를 따르세요.
- 텐서보드 창의 오른쪽 상단에 있는 메뉴 버튼에서 프로필을 선택합니다.
- 창 왼쪽의 도구 메뉴를 클릭하고 pod_viewer를 선택합니다.
포드 뷰어 사용자 인터페이스에는 다음이 포함됩니다.
- 단계 슬라이더: 살펴볼 단계를 선택할 수 있습니다.
- 토폴로지 그래프: 전체 TPU 시스템의 TPU 코어를 대화형으로 시각화합니다.
- 통신 링크 차트: 토폴로지 그래프의 송신 및 수신(recv) 채널을 시각화합니다.
- 송신 및 recv 채널의 지연 막대 그래프. 마우스로 이 그래프의 막대를 가리키면 통신 링크 차트의 통신 링크가 활성화됩니다. 채널 세부정보 카드가 왼쪽 막대에 표시되어 전송된 데이터의 크기, 지연, 대역폭과 같은 채널에 대한 자세한 정보를 제공합니다.
- 단계 구분 차트: 모든 코어에 대해 단계의 구분을 시각화합니다. 시스템 병목 지점을 추적하고 특정 코어가 시스템 속도를 저하시키는지 여부를 확인하는 데 사용할 수 있습니다.
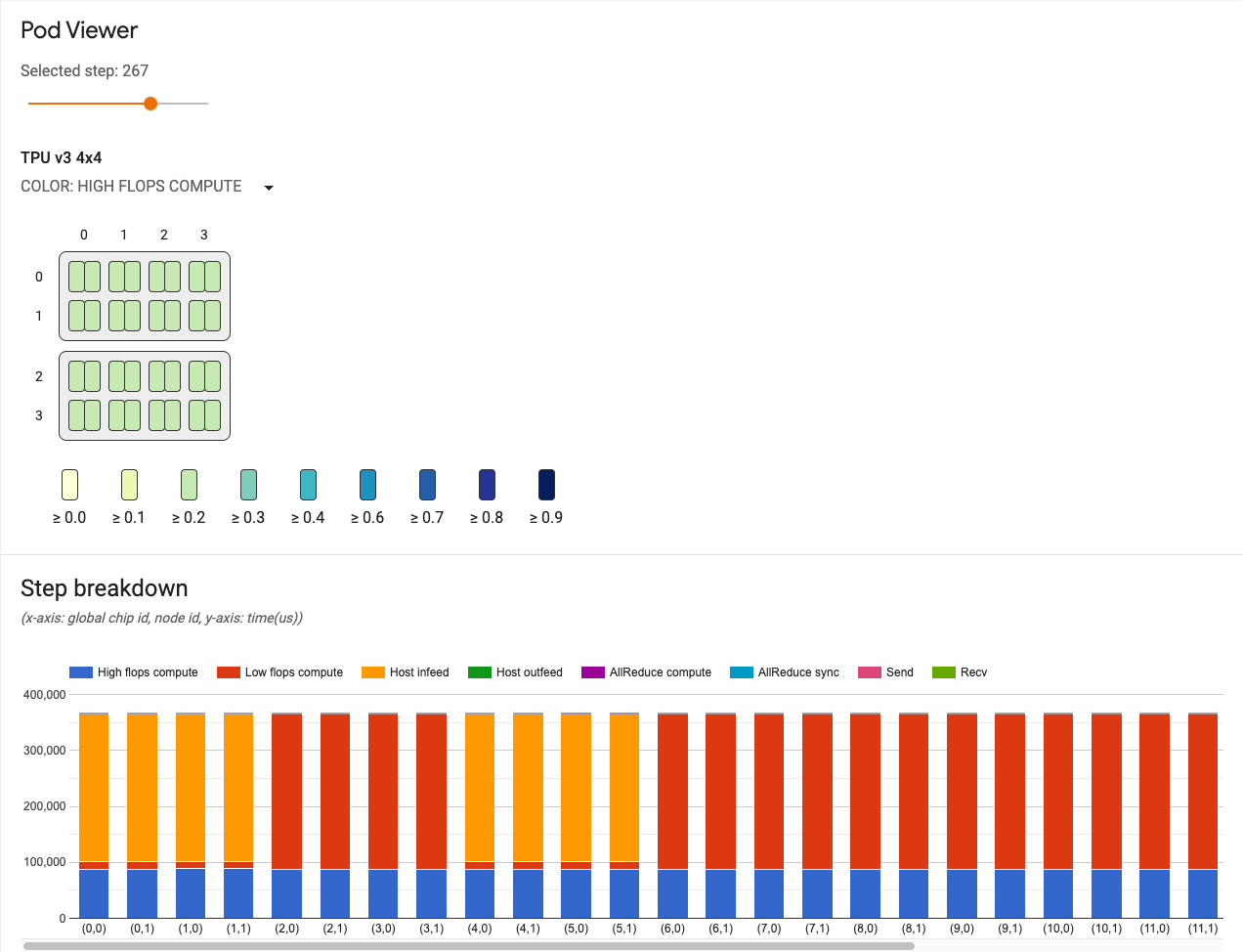
단계 슬라이더
슬라이더를 사용하여 단계를 선택합니다. 도구의 나머지 부분에 단계 구분, 통신 링크와 같은 해당 단계의 통계가 표시됩니다.
토폴로지 그래프
토폴로지 그래프는 호스트, 칩, 코어별로 계층적으로 구성됩니다. 가장 작은 직사각형이 TPU 코어입니다. 두 개의 코어는 하나의 TPU 칩을, 4개의 칩은 하나의 호스트를 나타냅니다.
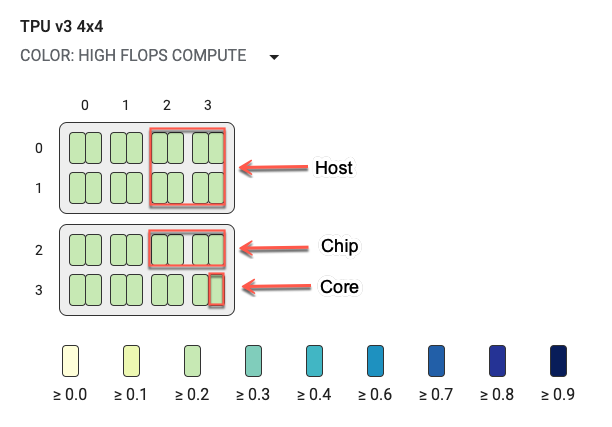
토폴로지 그래프는 특정 구분(예를 들어 FLOPS가 높은 연산, 인피드, 송신 등)이 선택된 단계에서 소비한 시간의 비율별로 색상이 지정되는 히트맵이기도 합니다. 토폴로지 그래프 바로 아래의 막대는(다음 그래픽에 표시됨) 코어와 칩 사용량에 대한 색상 지정을 보여줍니다. 코어의 색상은 노란색부터 파란색까지 사용률을 표시합니다. FLOPS가 높은 연산, 더 많은 수(더 어두운 색상)는 연산에 더 많은 시간이 소요되었음을 나타냅니다. 다른 모든 구분에서 작은 수(더 밝은 색상)는 대기 시간이 더 짧음을 나타냅니다. 코어가 다른 코어에 비해 어둡게 표시되는 경우 잠재적인 문제 영역 또는 핫스팟을 나타냅니다.
시스템 이름 옆의 풀다운 메뉴 선택기를 클릭해서(다이어그램에서 원으로 그려진 부분) 살펴볼 특정 구분 유형을 선택합니다.
작은 직사각형(단일 코어) 위로 마우스를 가져가면 시스템에서 코어의 위치, 전역 칩 ID, 호스트 이름이 나오는 테크팁이 표시됩니다. 테크팁에는 예를 들어 높은 FLOPS와 같은 선택된 구분 카테고리의 지속 시간과 단계의 사용률도 포함됩니다.
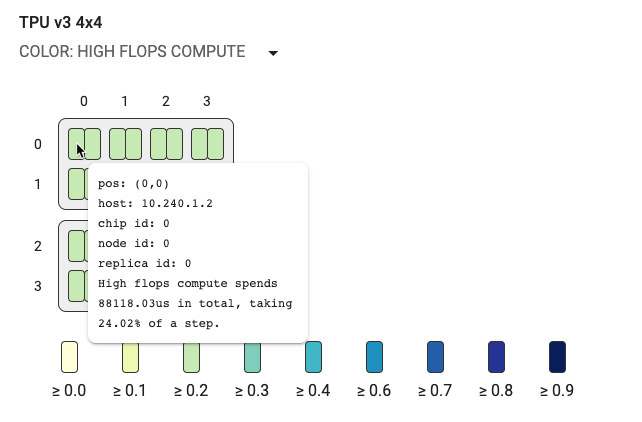
통신 채널
이 도구는 모델이 코어 간에 송신 및 수신 링크를 사용하여 통신하는 경우 이러한 링크를 시각화하는 데 유용합니다. 모델에 송신 및 수신 작업이 포함된 경우 채널 ID 선택기를 사용하여 채널 ID를 선택할 수 있습니다. 소스(src) 코어와 대상(dst) 코어의 링크는 통신 채널을 나타냅니다. 송신 및 수신 채널의 지연이 표시되는 차트의 막대 위로 마우스를 가져가면 토폴로지 그래프 위에 렌더링됩니다.

왼쪽 막대에 표시되는 카드는 통신 채널에 대한 더 많은 세부정보를 제공합니다. 일반적인 카드의 모습은 다음과 같습니다.
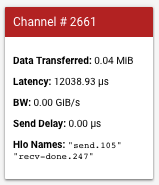
- Data Transferred(전송된 데이터): 송수신 채널에 의해 전송된 데이터를 메비바이트(MiB)로 표시합니다.
- Latency(지연): 송신 이벤트의 시작부터 수신 완료 이벤트의 끝까지 지속 시간을 마이크로초 단위로 표시합니다.
- BW: 해당 기간 동안 소스 코어에서 대상 코어로 전송된 데이터 양을 기비바이트(GiB) 단위로 표시합니다.
- Send Delay(송신 지연): 수신 완료부터 송신 시작까지의 기간을 마이크로초 단위로 표시합니다. 수신 완료 작업이 송신 작업 시작 이후에 시작되는 경우 지연은 0입니다.
- Hlo Names(Hlo 이름): 이 채널과 연결된 XLA hlo 작업 이름을 표시합니다. 이러한 hlo 이름은 op_profile, memory_viewer와 같은 다른 텐서보드 도구에 표시되는 통계와 연결됩니다.
단계 구분 차트
이 차트는 각 학습 또는 평가 단계의 세부정보를 제공합니다.
x축은 전역 칩 ID이며 y축은 마이크로초 단위의 시간입니다. 이 차트를 통해 특정 학습 단계에서 시간이 사용된 지점과 병목 지점이 어디인지와 모든 칩에 걸쳐 부하의 불균형이 있는지 여부를 볼 수 있습니다.
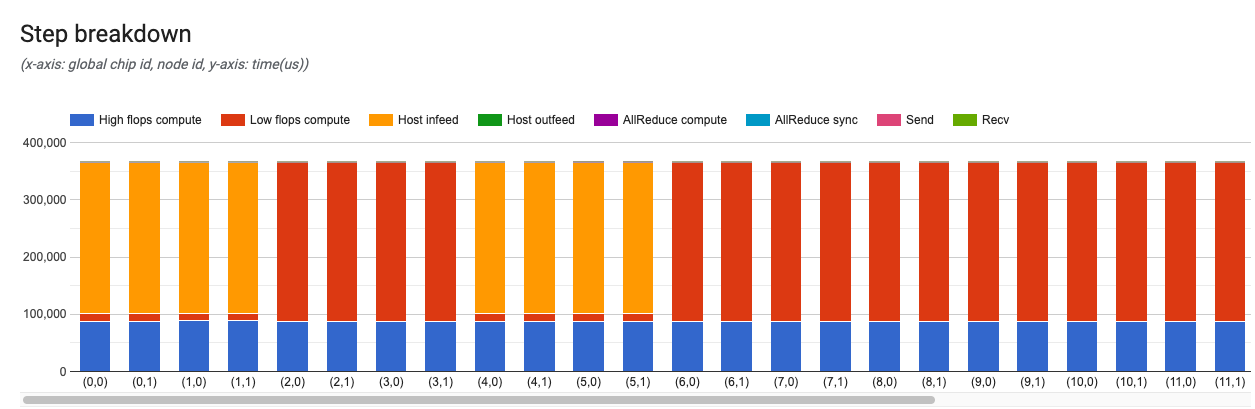
왼쪽 막대에 표시되는 카드는 단계 구분에 대한 더 많은 세부정보를 제공합니다. 일반적인 카드의 모습은 다음과 같습니다.
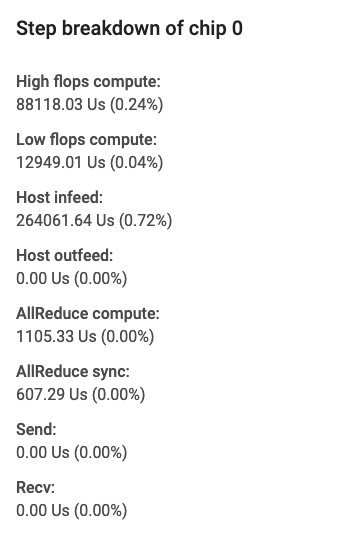
카드의 필드는 다음 요소를 지정합니다.
- High Flops Compute(FLOPS가 높은 연산): 컨볼루션 또는 출력 fusion 작업(ops)에 소비된 시간입니다.
- Low flops compute(FLOPS가 낮은 연산): 총 기간에서 다른 모든 구분을 빼는 방법으로 계산됩니다.
- Infeed(인피드): TPU가 호스트를 대기하면서 소비한 시간입니다.
- Outfeed(아웃피드): 호스트가 TPU의 출력을 대기하면서 소비한 시간입니다.
- AllReduce sync(AllReduce 동기화): 다른 코어와의 동기화를 대기하는 CrossReplicaSum 작업에 소비된 시간입니다. CrossReplicaSum 작업은 본제본 전반의 합계를 계산합니다.
- AllReduce compute(AllReduce 연산): CrossReplicaSum 작업에 소비된 실제 연산 시간입니다.
- Chip to chip send ops(칩 대 칩 송신 작업): 송신 작업에 소비된 시간입니다.
- Chip to chip recv-done ops(칩 대 칩 수신 완료 작업): 수신 작업에 소비된 시간입니다.
Trace 뷰어
trace 뷰어는 프로필 아래에서 사용할 수 있는 Cloud TPU 성능 분석 도구입니다. 이 도구는 Chrome trace 이벤트 프로파일링 뷰어를 사용하므로 Chrome 브라우저에서만 작동합니다.
trace 뷰어에 표시되는 타임라인은 다음과 같은 정보를 제공합니다.
- TensorFlow 모델에 의해 실행된 작업의 기간
- 작업을 실행한 시스템의 부분(TPU 또는 호스트 머신). 일반적으로 호스트 머신은 학습 데이터를 사전 처리하여 TPU로 전송하는 인피드 작업을 실행하고, TPU는 실제 모델 학습을 실행합니다.
trace 뷰어를 사용하면 모델의 성능 문제를 파악한 후 해결을 위한 조치를 취할 수 있습니다. 예를 들어 대부분의 시간을 소비하는 부분이 인피드인지, 모델 학습인지 대략적으로 파악할 수 있습니다. 자세히 살펴보면 가장 오랜 시간 실행된 TensorFlow 작업을 파악할 수 있습니다.
trace 뷰어는 Cloud TPU당 1M개의 이벤트로 제한됩니다. 더 많은 이벤트에 액세스해야 하는 경우 스트리밍 trace 뷰어를 대신 사용하세요.
trace 뷰어 인터페이스
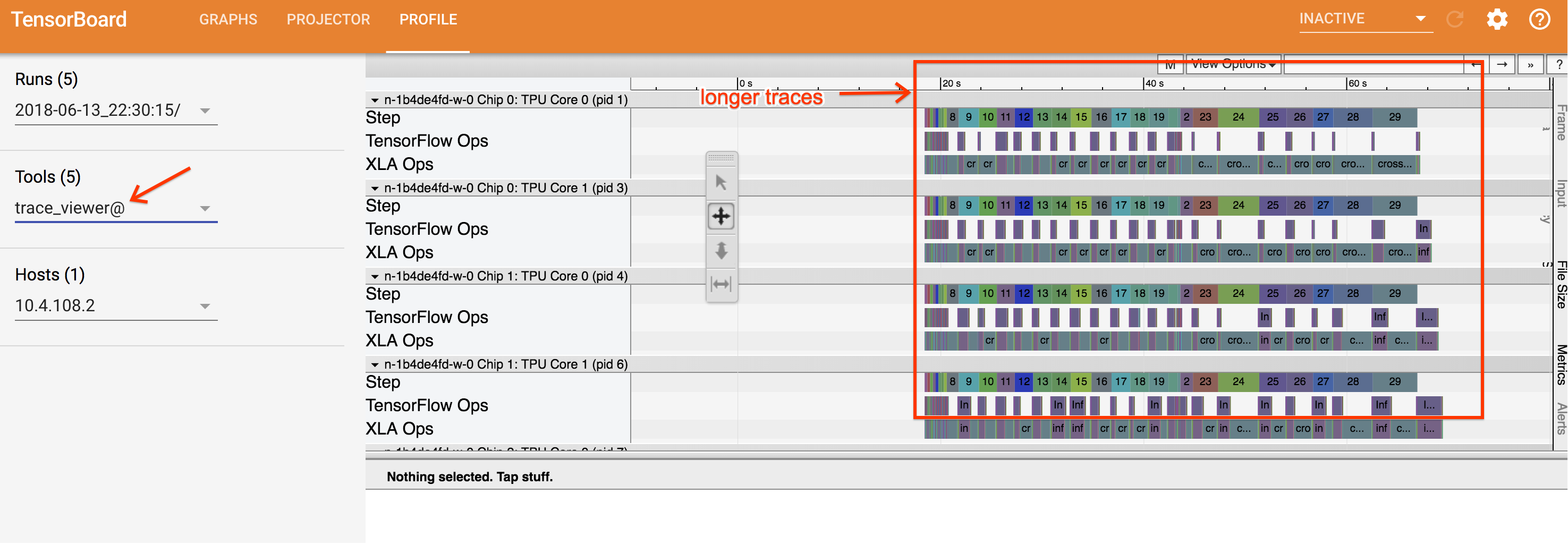
trace 뷰어를 열려면 텐서보드로 이동하여 화면 상단의 프로필 탭을 클릭하고 도구 드롭다운에서 trace_viewer를 선택합니다. 뷰어에 가장 최근의 실행 정보가 표시됩니다.
이 화면에는 다음과 같은 주요 요소가 포함되어 있습니다(위에 표시된 숫자 참고).
- 실행 드롭다운. trace 정보를 캡처한 모든 실행이 포함됩니다. 기본 보기는 가장 최근의 실행이지만 드롭다운을 열어 다른 실행을 선택할 수 있습니다.
- 도구 드롭다운. 다양한 프로파일링 도구를 선택합니다.
- 호스트 드롭다운. Cloud TPU 세트가 포함된 호스트를 선택합니다.
- 타임라인 창. Cloud TPU와 호스트 머신이 일정한 시간 동안 실행한 작업이 표시됩니다.
- 세부정보 창. 타임라인 창에서 선택한 작업의 추가 정보를 표시합니다.
타임라인 창을 자세히 보면 다음과 같습니다.
타임라인 창에는 다음과 같은 요소가 포함되어 있습니다.
- 상단 막대. 다양한 보조 제어 도구가 포함되어 있습니다.
- 시간 축. trace의 시작을 기준으로 한 상대 시간이 표시됩니다.
- 섹션 및 추적 라벨. 섹션마다 여러 트랙이 포함되어 있으며 왼쪽의 삼각형을 클릭하면 섹션을 펼치거나 접을 수 있습니다. 시스템의 모든 처리 요소마다 섹션이 하나씩 있습니다.
- 도구 선택기. trace 뷰어와 연동되는 여러 도구가 포함되어 있습니다.
- 이벤트. 이 영역은 작업이 실행된 시간 또는 학습 단계와 같은 메타 이벤트 기간을 표시합니다.
- 세로 탭 막대. Cloud TPU에서는 별다른 용도가 없습니다. 이 막대는 다양한 성능 분석 작업에 사용되는 Chrome이 제공하는 범용 trace 뷰어 도구의 일부입니다.
섹션 및 트랙
trace 뷰어에는 다음과 같은 섹션이 포함되어 있습니다.
- 각 TPU 노드에 대한 하나의 섹션. TPU 칩 번호와 칩 내의 TPU 노드 라벨이 지정됩니댜(예: 'Chip 2: TPU Core 1'). 각 TPU 노드 섹션에는 다음과 같은 트랙이 포함됩니다.
- 단계. TPU에서 실행 중이었던 학습 단계의 지속 시간을 나타냅니다.
- TensorFlow 작업. TPU에서 실행된 TensorFlow 작업을 표시합니다.
- XLA 작업. TPU에서 실행된 XLA 작업을 보여줍니다. 각 작업은 하나 이상의 XLA 작업으로 해석됩니다. XLA 컴파일러는 XLA 작업을 TPU에서 실행되는 코드로 변환합니다.)
- 호스트 머신의 CPU에서 실행되는 스레드에 대한 하나의 섹션. '호스트 스레드' 라벨이 지정됩니다. 섹션에는 각 CPU 스레드마다 하나의 트랙이 포함됩니다. 참고: 섹션 라벨 옆에 표시되는 정보는 무시해도 됩니다.
타임라인 도구 선택기
텐서보드의 타임라인 도구 선택기를 사용하여 타임라인 보기를 조작할 수 있습니다. 타임라인 도구를 클릭하거나 다음 단축키를 사용하여 도구를 활성화하고 강조표시할 수 있습니다. 타임라인 도구 선택기를 옮기려면 상단의 점으로 영역을 클릭한 다음 원하는 곳으로 선택기를 드래그합니다.
타임라인 도구를 다음과 같이 사용합니다.
|
선택 도구 이벤트를 클릭하여 선택하거나 드래그하여 여러 이벤트를 선택합니다. 선택한 이벤트에 관한 자세한 정보(이름, 시작 시간, 지속 시간)가 세부정보 창에 표시됩니다. |
|
화면 이동 도구 드래그하여 타임라인 보기를 가로와 세로 방향으로 이동합니다. |
|
확대/축소 도구 세로축(시간)을 따라 드래그하면 확대하거나 축소할 수 있습니다. 마우스 커서의 수평 위치가 확대/축소의 중심점을 결정합니다. 참고: 확대/축소 도구에는 마우스 커서가 타임라인 보기 밖에 있는 상태에서 마우스 버튼을 놓아도 이 기능이 계속 작동되는 알려진 버그가 있습니다. 이 문제가 발생하는 경우 타임라인 보기를 짧게 클릭하면 확대/축소 기능이 중지됩니다. |
|
타이밍 도구 가로 방향으로 드래그하여 시간 간격을 표시합니다. 시간 축에 간격 길이가 나타납니다. 간격을 조정하려면 가장자리를 드래그하면 됩니다. 간격을 삭제하려면 타임라인 보기의 아무 곳이나 클릭하세요. 다른 도구를 선택해도 간격은 표시된 상태로 유지됩니다. |
이벤트
타임라인 내의 이벤트는 다양한 색상으로 표시됩니다. 색상 자체에 특별한 의미는 없습니다.
타임라인 상단 표시줄
타임라인 창의 상단 표시줄에는 여러 보조 제어 도구가 포함되어 있습니다.

- 메타데이터 표시. TPU에는 사용되지 않습니다.
- 보기 옵션. TPU에는 사용되지 않습니다.
- 검색창. 검색어가 이름에 포함된 모든 이벤트를 검색합니다. 검색창의 오른쪽에 있는 화살표 버튼을 클릭하면 일치하는 이벤트를 앞뒤 방향으로 이동해 가며 차례로 각 이벤트를 선택할 수 있습니다.
- Console 버튼. TPU에는 사용되지 않습니다.
- 도움말 버튼. 클릭하면 간단한 도움말 요약이 표시됩니다.
단축키
다음은 trace 뷰어에서 사용할 수 있는 단축키입니다. 상단 표시줄의 도움말 버튼(?)을 클릭하면 더 많은 단축키를 확인할 수 있습니다.
w Zoom in
s Zoom out
a Pan left
d Pan right
f Zoom to selected event(s)
m Mark time interval for selected event(s)
1 Activate selection tool
2 Activate pan tool
3 Activate zoom tool
4 Activate timing tool
f 단축키를 매우 유용하게 사용할 수 있습니다. 단계를 선택하고 f를 눌러 신속하게 단계를 확대해보세요.
특징적인 이벤트
다음은 TPU 성능을 분석할 때 매우 유용할 수 있는 몇 가지 이벤트 유형입니다.

InfeedDequeueTuple. 이 TensorFlow 작업은 TPU에서 실행되며 호스트에서 발생하는 입력 데이터를 받습니다. 인피드에 많은 시간이 소요되는 경우 호스트 머신에서 데이터를 사전 처리하는 TensorFlow 작업이 TPU 데이터 소비 속도를 따라잡지 못한다는 의미일 수 있습니다. 호스트 trace에서 InfeedEnqueueTuple이라는 이벤트를 확인할 수 있습니다. 더 세부적인 입력 파이프라인 분석을 보려면 입력 파이프라인 분석기 도구를 사용하세요.
CrossReplicaSum. 이 TensorFlow 작업은 TPU에서 실행되며 복제본의 총합을 계산합니다. 각 복제본은 서로 다른 TPU 노드에 해당되기 때문에 이 작업을 수행하려면 모든 TPU 노드에서 단계가 완료되길 기다려야 합니다. 이 작업에 많은 시간이 소요되는 경우 합계를 구하는 작업 자체가 느린 것이 아니라 TPU 노드가 데이터 인피드가 느린 다른 TPU 노드를 기다린다는 의미일 수 있습니다.

- 데이터 세트 작업 trace 뷰어는 Dataset API를 사용하여 데이터가 로드될 때 수행된 데이터 세트 작업을 시각화합니다.
예시의
Iterator::Filter::Batch::ForeverRepeat::Memory는 컴파일되며dataset.map()작업에 해당합니다. 디버깅을 진행하면서 입력 파이프라인 병목 현상을 완화할 때 trace 뷰어를 사용하여 로딩 작업을 살펴볼 수 있습니다.
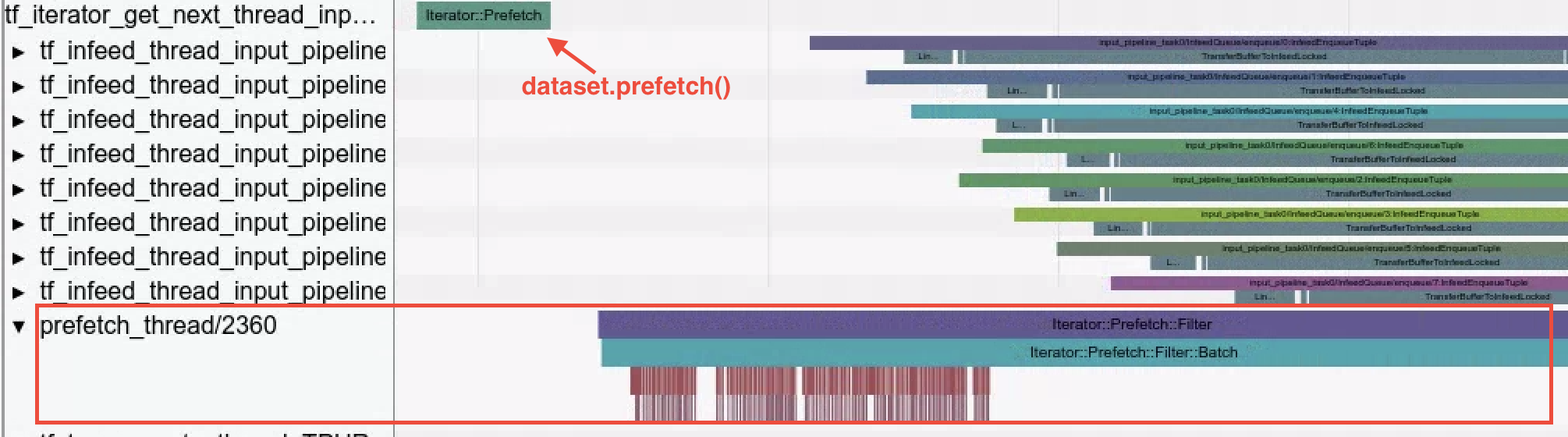
- 프리페치 스레드.
dataset.prefetch()를 사용하여 입력 데이터를 버퍼링하면 입력 파이프라인에서 병목 현상을 일으키는 파일 액세스의 간헐적인 속도 저하를 방지할 수 있습니다.
유의사항
trace 뷰어를 사용할 때 주의해야 할 몇 가지 잠재적인 문제점은 다음과 같습니다.
- 이벤트 표시 제한. trace 뷰어는 최대 100만 개의 이벤트를 표시합니다. 그 이상의 이벤트를 캡처한 경우 먼저 캡처된 100만 개의 이벤트만 표시되며 그 후의 이벤트는 제외됩니다. 더 많은 TPU 이벤트를 캡처하려면
--include_dataset_ops=False플래그를 사용하여capture_tpu_profile이 데이터 세트 작업을 제외하도록 명시적으로 요구할 수 있습니다. - 매우 긴 이벤트. 캡처가 시작되기 전에 시작된 이벤트 또는 캡처가 끝난 후의 이벤트는 trace 뷰어에서 볼 수 없습니다. 따라서 매우 긴 이벤트가 누락될 수 있습니다.
trace 캡처를 시작할 때. Cloud TPU가 실행 중임을 확인한 후 trace 캡처를 시작해야 합니다. 그 전에 시작하는 경우 trace 뷰어에 소수의 이벤트만 표시되거나 아예 이벤트가 표시되지 않을 수 있습니다.
--duration_ms플래그를 사용하여 프로필 시간을 늘리고--num_tracing_attempts플래그를 사용하여 자동 재시도를 설정할 수 있습니다. 예를 들면 다음과 같습니다.(vm)$ capture_tpu_profile --tpu=$TPU_NAME --logdir=${MODEL_DIR} --duration_ms=60000 --num_tracing_attempts=10
메모리 뷰어
메모리 뷰어를 사용하면 프로그램의 최고 메모리 사용량과 프로그램 전체 기간 동안의 사용량 트렌드를 시각화할 수 있습니다.
메모리 뷰어 UI는 다음과 같습니다.
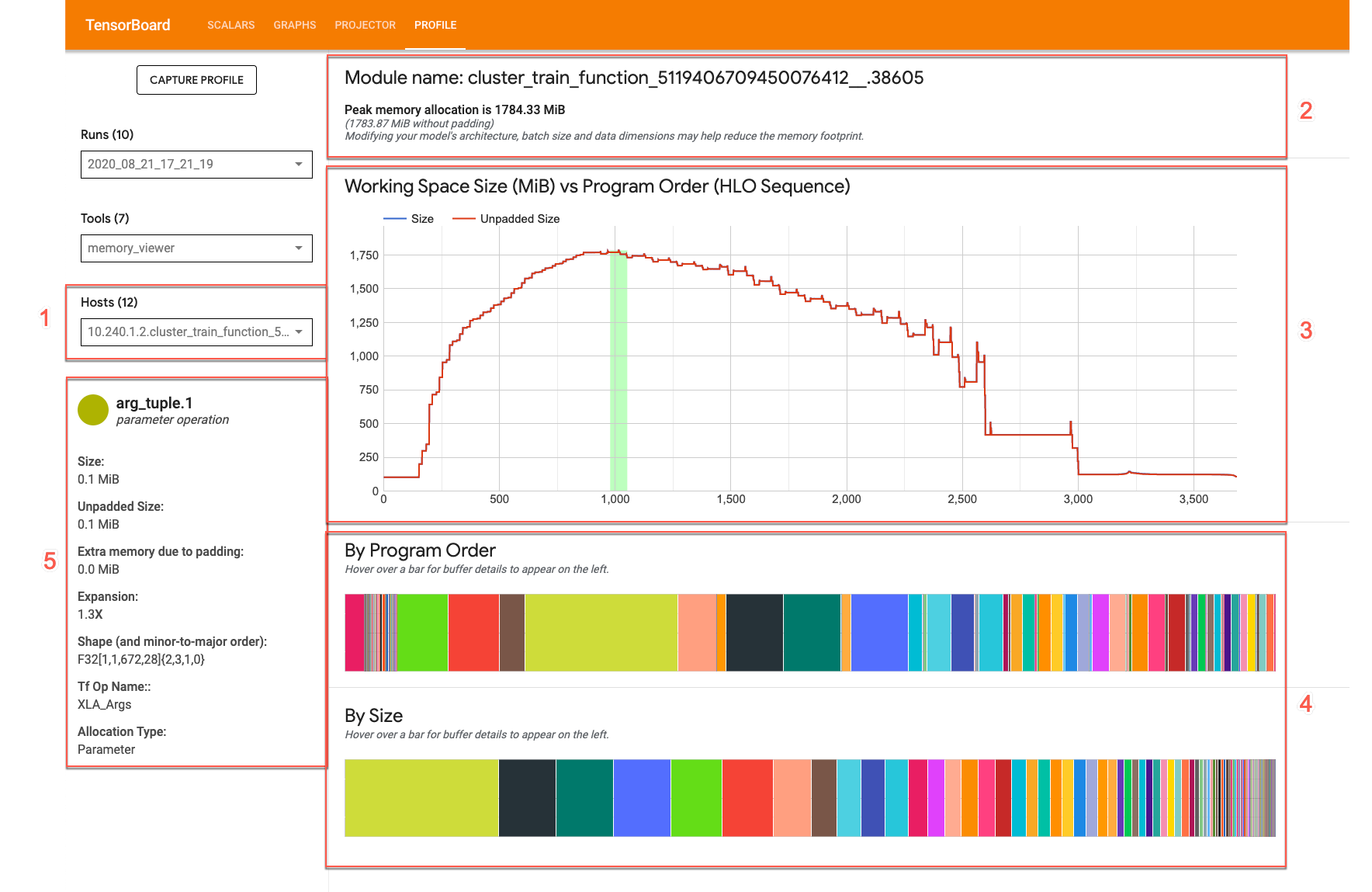
- 호스트 드롭다운. 시각화할 TPU 호스트와 XLA High Level Optimizer(HLO) 모듈을 선택합니다.
- 메모리 개요. 패딩 없이 최고 메모리 할당 및 크기를 표시합니다.
- 작업 영역 차트. 최고 메모리 사용량과 프로그램 전체 기간 동안의 메모리 사용 트렌드를 표시합니다. 버퍼 차트 중 하나의 버퍼 위로 마우스를 가져가면 버퍼 전체 기간에 대한 주석과 버퍼 세부정보 카드가 추가됩니다.
- 버퍼 차트. 작업 영역 플롯에서 세로 선으로 표시되는 최고 메모리 사용량 시점의 버퍼 할당량을 표시하는 두 개의 차트입니다. 버퍼 차트 중 하나의 버퍼 위로 마우스를 가져가면 작업 영역 차트에 버퍼의 전체 기간 막대가 표시되고 왼쪽에 세부정보 카드가 표시됩니다.
- 버퍼 할당량 세부정보 카드. 버퍼의 할당량 세부정보가 표시됩니다.
메모리 개요 패널
메모리 개요(상단) 패널에는 총 버퍼 할당량 크기가 최댓값에 도달할 때의 모듈 이름과 최고 메모리 할당량 세트가 표시됩니다. 패딩되지 않은 최고 할당량 크기도 비교를 위해 표시됩니다.

작업 영역 차트
이 차트는 최고 메모리 사용량과 프로그램 전체 기간에 걸친 메모리 사용량 트렌트 플롯을 표시합니다. 플롯에서 위에서 아래로 이어진 선은 프로그램의 최고 메모리 사용량을 나타냅니다. 이 지점에 따라 프로그램이 가용 전역 메모리 공간에 들어갈 수 있는지 여부가 결정됩니다.
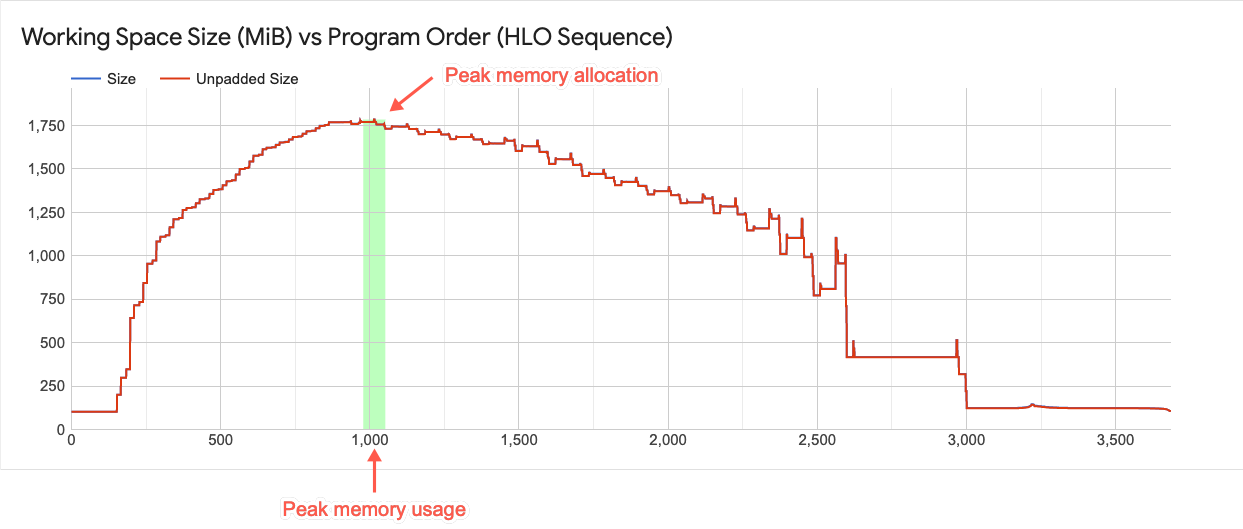
표시되는 선 플롯 위의 각 지점은 컴파일러에 의해 예약된 XLA HLO 프로그램의 '프로그램 지점'을 나타냅니다. 선은 최고 사용량 전후의 돌출부에 대한 감을 제공합니다.
버퍼 차트 요소와의 상호작용
작업 영역 차트 아래의 버퍼 차트 중 하나에 표시되는 버퍼 위로 마우스를 가져가면 해당 버퍼의 가로 전체 기간 선이 작업 영역 차트에 나타납니다. 가로 선의 색상은 강조표시된 버퍼의 색상과 동일합니다.
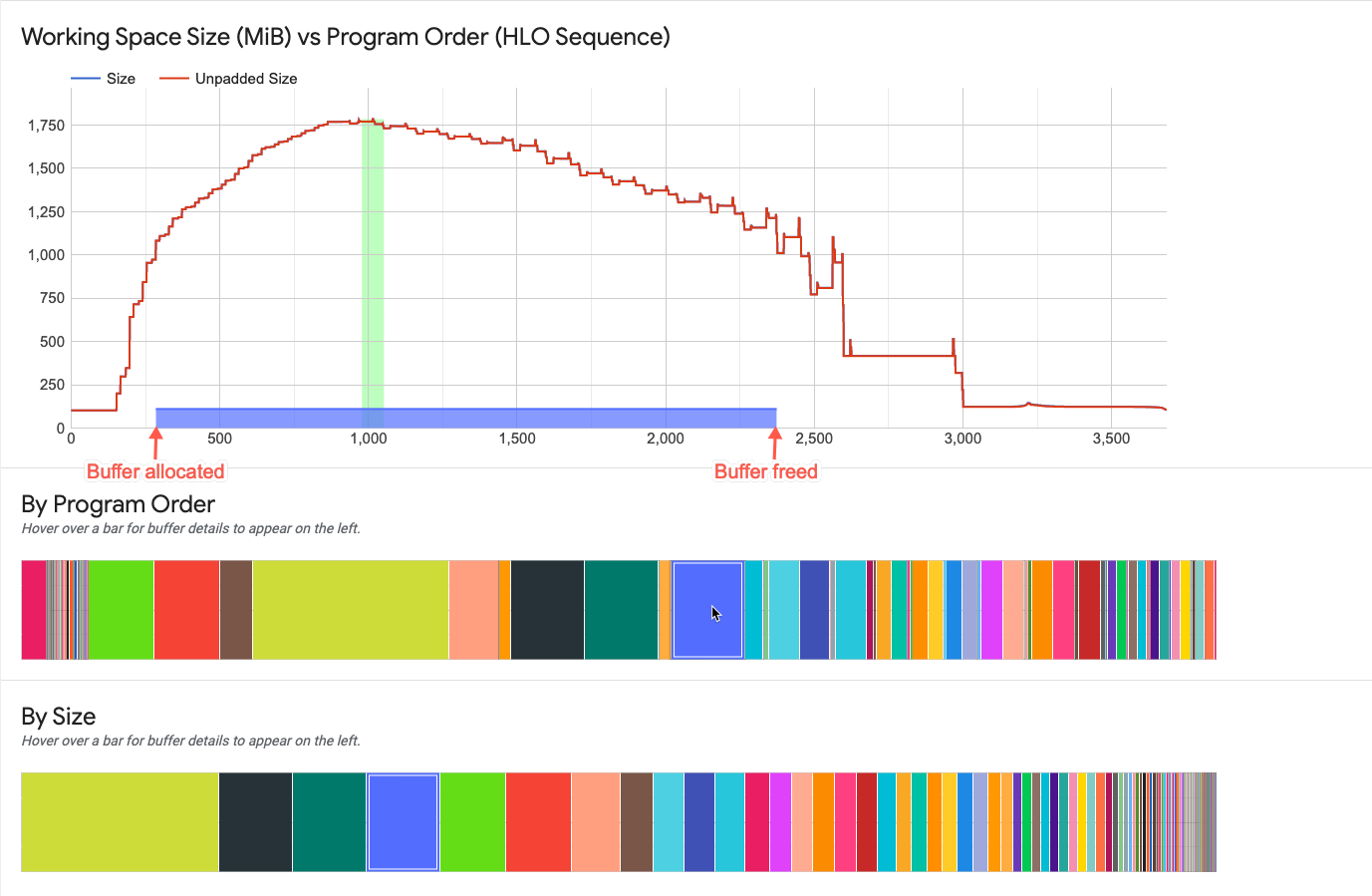
가로 선의 두께는 최고 메모리 할당량 대비 버퍼의 상대적인 크기를 나타냅니다. 선 길이는 버퍼의 수명에 해당하며 버퍼 공간이 할당된 프로그램 지점에서 시작되어 공간이 해제된 지점에서 끝납니다.
버퍼 차트
두 차트는 최고 사용량 지점에서의 메모리 사용량 상세 내역을 표시합니다(차트 위의 플롯에서 세로선으로 표시).
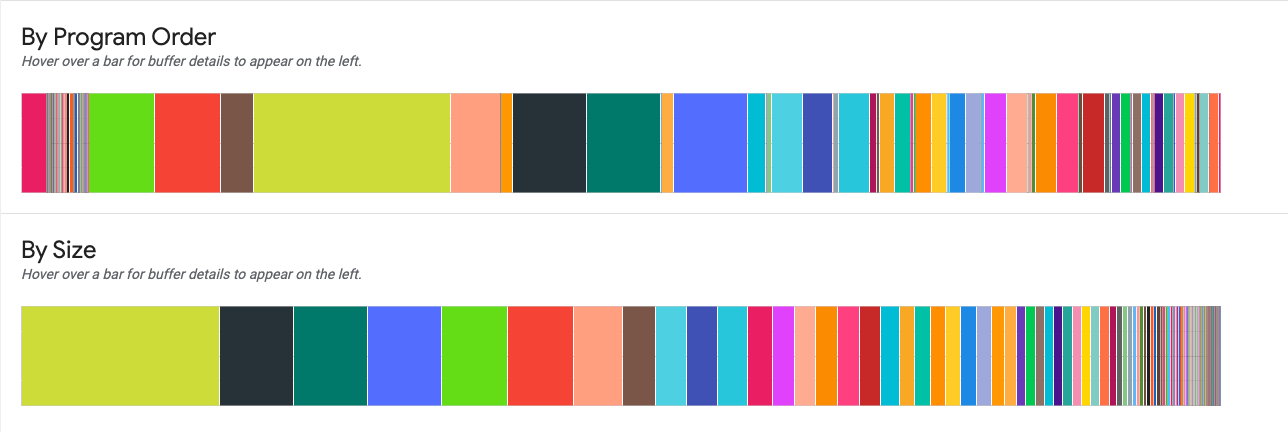
By Program Order(프로그램 순서별). 프로그램 실행 도중 활성화된 순서에 따라 왼쪽에서 오른쪽으로 버퍼를 표시합니다. 가장 오랜 시간 활성인 버퍼가 차트의 왼쪽에 위치합니다.
By Size(크기별). 프로그램 실행 동안 활성 상태였던 버퍼를 크기 내림차순으로 표시합니다. 최고 메모리 사용량 지점에서 가장 큰 영향을 미친 버퍼가 왼쪽에 위치합니다.
버퍼 할당량 세부정보 카드
버퍼 차트 중 하나에 표시되는 버퍼 위로 마우스를 가져가면 버퍼 할당량 세부정보 카드가 표시됩니다(작업 차트에 전체 기간 선도 표시됨). 일반적인 세부정보 카드의 모습은 다음과 같습니다.
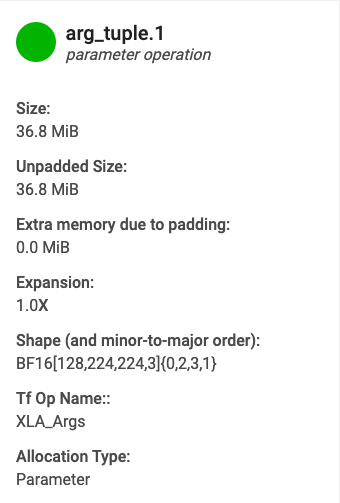
- 이름. XLA 작업의 이름
- Category(카테고리). 작업 카테고리
- Size(크기). 버퍼 할당량의 크기(패딩 포함)
- Unpadded size(패딩되지 않은 크기). 패딩 없는 버퍼 할당량의 크기
- Expansion(확장). 패딩되지 않은 크기 대비 패딩된 버퍼의 상대적인 크기
- Extra memory(부가 메모리). 패딩에 사용된 부가 메모리 용량을 나타냅니다.
- Shape(모양). N 차원 배열의 순위, 크기, 데이터 유형을 설명합니다.
- TensorFlow op name(TensorFlow 작업 이름). 버퍼 할당과 연결된 TensorFlow 작업의 이름을 표시합니다.
- Allocation type(할당 유형). 버퍼 할당 카테고리를 나타냅니다. 유형은 Parameter(매개변수), Output(출력), Thread-local(스레드 로컬), Temporary(임시, 예: fusion 내 버퍼 할당)입니다.
'메모리 부족' 오류
모델을 실행한 후 '메모리 부족' 오류가 발생하는 경우 다음 명령어를 사용하여 메모리 프로필을 캡처하고 메모리 뷰어에서 확인하세요. 프로파일링 기간이 프로그램 컴파일 시간과 겹치도록 적절한 duration_ms를 설정해야 합니다. 출력은 오류 발생 원인을 파악하는 데 도움이 될 수 있습니다.
(vm)$ capture_tpu_profile --tpu=$TPU_NAME --logdir=${MODEL_DIR} --duration_ms=60000
스트리밍 trace 뷰어
스트리밍 trace 뷰어(trace_viewer)는 TensorFlow 2.16.1 이상에서 사용할 수 있는 Cloud TPU 성능 분석 도구로, 동적 trace 렌더링 기능을 제공합니다. 이 도구는 Chrome trace 이벤트 프로파일링 뷰어를 사용하므로 Chrome 브라우저에서만 작동합니다.
capture_tpu_profile을 사용하여 프로필을 캡처하면 .tracetable 파일이 Google Cloud Storage 버킷에 저장됩니다. 이 파일에는 trace 뷰어 및 스트리밍 trace 뷰어에서 볼 수 있는 많은 trace 이벤트가 포함되어 있습니다.
스트리밍 trace 뷰어 사용
스트리밍 trace 뷰어 trace_viewer를 사용하려면 기존 텐서보드 세션을 종료한 다음 검사할 TPU의 IP 주소를 사용하여 텐서보드를 다시 시작해야 합니다. 스트리밍 trace 뷰어를 사용하려면 Google Cloud TPU의 IP 주소로 리모트 프로시져 콜(GRPC)을 만들기 위해 텐서보드가 필요합니다. GRPC 채널은 암호화되어 있지 않습니다.
Cloud TPU 페이지에서 Cloud TPU 호스트의 IP 주소를 확인할 수 있습니다. Cloud TPU를 찾고 내부 IP 열에서 IP 주소를 확인합니다.
VM에서 다음과 같이 텐서보드를 실행하여 tpu-ip를 TPU IP 주소로 바꿉니다.
(vm)$ tensorboard --logdir=${MODEL_DIR} \
--master_tpu_unsecure_channel=tpu-ip
텐서보드 도구는 도구 드롭다운 목록에 표시됩니다.
타임라인에서 확대 및 축소하여 trace 이벤트가 브라우저로 동적으로 로드되는 것을 볼 수 있습니다.
Cloud TPU 작업 모니터링
이 섹션에서는 capture_tpu_profile을 사용하여 단일 프로필을 캡처하거나 명령줄 인터페이스에서 Cloud TPU 작업을 실시간으로 계속 모니터링하는 방법을 설명합니다. --monitoring_level 옵션을 0(기본값), 1, 2로 설정하면 각각 단일 프로필, 기본 모니터링, 세부적인 모니터링이 설정됩니다.
새 Cloud Shell을 열고 VM에 SSH로 연결합니다(명령어의 vm-name을 해당하는VM 이름으로 바꿈).
(vm)$ gcloud compute ssh vm-name \
--ssh-flag=-L6006:localhost:6006
새 Cloud Shell에서 --monitoring_level 플래그를 1 또는 2로 설정하여 capture_tpu_profile을 실행합니다. 예를 들면 다음과 같습니다.
(vm)$ capture_tpu_profile --tpu=$TPU_NAME \
--monitoring_level=1
monitoring_level=1을 설정하면 다음과 비슷한 출력이 생성됩니다.
TPU type: TPU v2
Utilization of TPU Matrix Units is (higher is better): 10.7%
monitoring_level=2를 설정하면 다음과 같은 세부정보가 표시됩니다.
TPU type: TPU v2
Number of TPU Cores: 8
TPU idle time (lower is better): 0.091%
Utilization of TPU Matrix Units is (higher is better): 10.7%
Step time: 1.95 kms (avg), 1.90kms (minute), 2.00 kms (max)
Infeed percentage: 87.5% (avg). 87.2% (min), 87.8 (max)
모니터링 플래그
--tpu(필수)는 모니터링할 Cloud TPU의 이름을 지정합니다.--monitoring_level. 단일 프로필 생성에서 기본 또는 세부 지속적 모니터링으로capture_tpu_profile의 동작을 변경합니다. 사용 가능한 수준은 세 가지입니다. 수준 0(기본값): 단일 프로필을 생성하고 종료됩니다. 수준 1: TPU 버전과 TPU 사용률을 표시합니다. 수준 2: TPU 사용률, TPU 유휴 시간, 사용된 TPU 코어의 수를 표시합니다. 또한 최소, 평균, 최대 단계 시간과 함께 인피드 비율 기여도도 제공합니다.--duration_ms(선택사항. 기본값은 1000ms) 각 주기 동안 TPU 호스트를 프로파일링할 시간을 지정합니다. 일반적으로 최소 하나의 학습 단계에 해당하는 데이터를 캡처하는 데 충분할 만큼 길어야 합니다. 1초는 대부분의 모듈에서 학습 단계 하나를 캡처하지만 모델 단계 시간이 매우 큰 경우 값을 2xstep_time(ms 단위)으로 설정할 수 있습니다.--num_queries는capture_tpu_profile을 실행할 주기 수를 지정합니다. TPU 작업을 지속적으로 모니터링하려면 이 값을 높게 설정하세요. 모델의 단계 시간을 신속하게 확인하려면 이 값을 낮게 설정하세요.