本页面介绍了 Cloud TPU 如何与 Google Kubernetes Engine (GKE) 搭配使用,包括术语、张量处理单元 (TPU) 的优势以及工作负载调度注意事项。TPU 是 Google 定制开发的应用专用集成电路 (ASIC),用于加速使用 TensorFlow、PyTorch 和 JAX 等框架的机器学习工作负载。
本页面适用于平台管理员和运维人员,以及运行机器学习 (ML) 模型(具有大规模、长时间运行或由矩阵计算主导等特征)的数据和 AI 专家。如需详细了解我们在 Google Cloud内容中提及的常见角色和示例任务,请参阅常见的 GKE Enterprise 用户角色和任务。
在阅读本页面之前,请确保您熟悉机器学习加速器的工作原理。如需了解详情,请参阅 Cloud TPU 简介。
使用 GKE 中 TPU 的优势
GKE 为 TPU 节点和节点池生命周期管理提供全面支持,包括创建、配置和删除 TPU 虚拟机。GKE 还支持 Spot 虚拟机和使用预留 Cloud TPU。如需了解详情,请参阅 Cloud TPU 使用选项。使用 GKE 中的 TPU 的优势包括:
- 一致的运行环境:您可以将单一平台用于所有机器学习和其他工作负载。
- 自动升级:GKE 会自动更新版本,从而减少运营开销。
- 负载均衡:GKE 会分发负载,从而缩短延迟时间并提高可靠性。
- 响应式扩缩:GKE 会自动扩缩 TPU 资源,以满足工作负载的需求。
- 资源管理:使用 Kueue(Kubernetes 原生作业排队系统),您可以使用排队、抢占、优先级和公平共享来管理组织内多个租户的资源。
- 沙盒选项:GKE Sandbox 可帮助您使用 gVisor 保护工作负载。如需了解详情,请参阅 GKE Sandbox。
使用 TPU Trillium 的优势
Trillium 是 Google 的第六代 TPU。Trillium 具有以下优势:
- 与 TPU v5e 相比,Trillium 提高了每个芯片的计算性能。
- Trillium 增加了高带宽内存 (HBM) 容量和带宽,并相对于 TPU v5e 提高了芯片间互连 (ICI) 带宽。
- Trillium 配备第三代 SparseCore,这是一种专用加速器,用于处理高级排名和推荐工作负载中常见的超大嵌入。
- Trillium 的能效比 TPU v5e 高出 67% 以上。
- Trillium 可以在单个高带宽、低延迟的 TPU 切片中扩容到多达 256 个 TPU。
- Trillium 支持集合调度。借助集合调度,您可以声明一组 TPU(单主机和多主机 TPU 切片节点池),以确保实现高可用性来满足推理工作负载的需求。
在所有技术界面(例如 API 和日志)以及 GKE 文档的特定部分中,我们使用 v6e 或 TPU Trillium (v6e) 来引用 Trillium TPU。如需详细了解 Trillium 的优势,请参阅 Trillium 公告博文。如需开始设置 TPU,请参阅规划 GKE 中的 TPU。
与 GKE 中的 TPU 相关的术语
本页面使用以下与 TPU 相关的术语:
- TPU 类型:Cloud TPU 类型,例如 v5e。
- TPU 切片节点:由具有一个或多个互连 TPU 芯片的单个虚拟机表示的 Kubernetes 节点。
- TPU 切片节点池:集群内一组具有相同 TPU 配置的 Kubernetes 节点。
- TPU 拓扑:TPU 切片中 TPU 芯片的数量和物理排列方式。
- 原子性:GKE 将所有互连的节点视为一个单元。在扩缩操作期间,GKE 会将整个节点组缩减为 0 并创建新节点。如果节点组中的机器发生故障或终止,GKE 会作为一个新单元重新创建整个节点组。
- Immutable:您无法手动向一组互连的节点添加新节点。 不过,您可以创建具有所需 TPU 拓扑的新节点池,并在新节点池上调度工作负载。
TPU 切片节点池的类型
GKE 支持两种类型的 TPU 节点池:
TPU 类型和拓扑决定了 TPU 切片节点可以是多主机还是单主机。我们建议:
- 对于大规模模型,请使用多主机 TPU 切片节点
- 对于小规模模型,请使用单主机 TPU 切片节点
- 对于大规模训练或推理,请使用 Pathways。Pathways 通过使单个 JAX 客户端能够跨多个大型 TPU 切片编排工作负载,简化了大规模机器学习计算。如需了解详情,请参阅 Pathways。
多主机 TPU 切片节点池
多主机 TPU 切片节点池是包含两个或更多互连 TPU 虚拟机的节点池。每个虚拟机都有一个与之连接的 TPU 设备。多主机 TPU 切片中的 TPU 通过高速互连 (ICI) 进行连接。创建多主机 TPU 切片节点池后,您无法向其添加节点。例如,您无法创建 v4-32 节点池,然后再向该节点池添加其他 Kubernetes 节点(TPU 虚拟机)。如需向 GKE 集群添加额外的 TPU 切片,您必须创建新的节点池。
多主机 TPU 切片节点池中的虚拟机会被视为单个原子单元。如果 GKE 无法部署切片中的某个节点,则不会部署 TPU 切片节点中的任何节点。
如果多主机 TPU 切片中的节点需要维修,GKE 会关闭 TPU 切片中的所有虚拟机,从而强制逐出工作负载中的所有 Kubernetes Pod。当 TPU 切片中的所有虚拟机都已启动并运行后,Kubernetes Pod 便可以在新 TPU 切片中的虚拟机上进行调度。
下图显示了 v5litepod-16 (v5e) 多主机 TPU 切片。此 TPU 切片有四个虚拟机。TPU 切片中的每个虚拟机都有四个通过高速互连 (ICI) 连接的 TPU v5e 芯片,并且每个 TPU v5e 芯片都有一个 TensorCore。
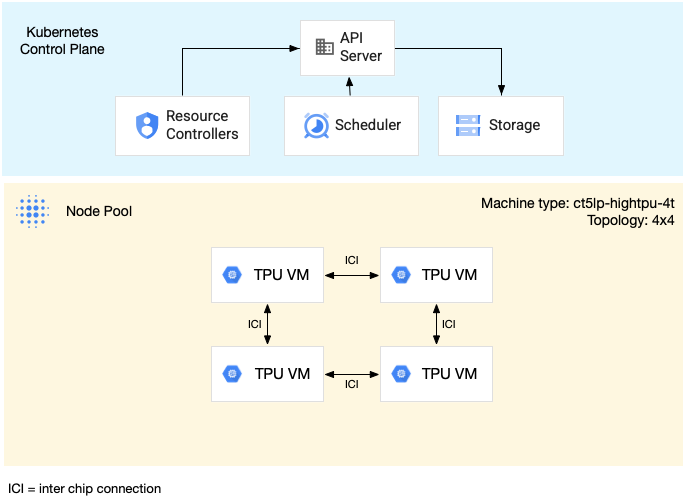
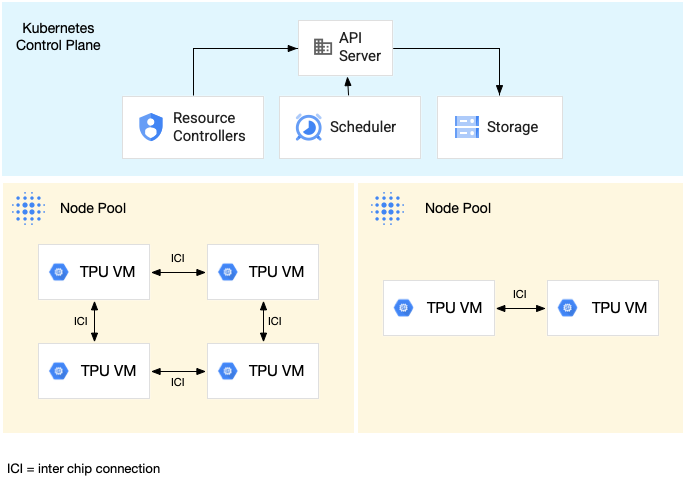
下图显示了一个 GKE 集群,其中包含一个 TPU v5litepod-16 (v5e) TPU 切片(拓扑:4x4)和一个 TPU v5litepod-8 (v5e) 切片(拓扑:2x4):
单主机 TPU 切片节点池
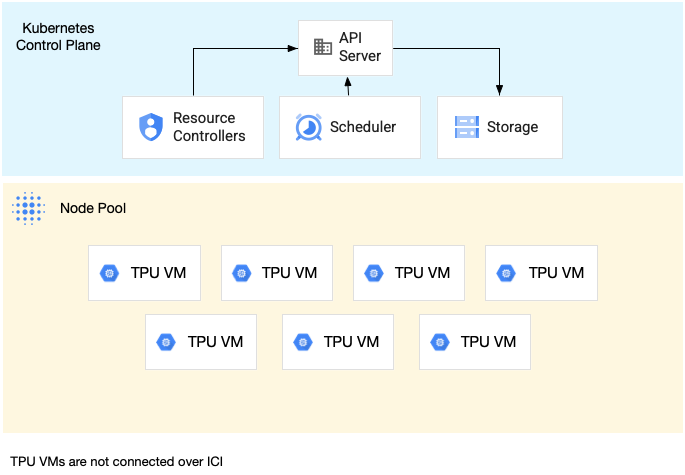
单主机切片节点池是包含一个或多个独立 TPU 虚拟机的节点池。每个虚拟机都有一个与之连接的 TPU 设备。虽然单主机切片节点池中的虚拟机可以通过数据中心网络 (DCN) 进行通信,但连接到虚拟机的 TPU 不会互连。
下图显示了一个包含 7 台 v4-8 机器的单主机 TPU 切片示例:
GKE 中的 TPU 特性
TPU 具有独特的特性,需要特殊规划和配置。
拓扑
拓扑定义了 TPU 切片内 TPU 的物理排列方式。GKE 会在二维或三维拓扑中配置 TPU 切片,具体取决于 TPU 版本。您可以采用每个维度中的 TPU 芯片数量的形式指定拓扑,如下所示:
对于在多主机 TPU 切片节点池中调度的 TPU v4 和 v5p,您可以使用 3 元组 ({A}x{B}x{C}) 来定义拓扑,例如 4x4x4。{A}x{B}x{C} 的乘积定义了节点池中的 TPU 芯片数量。例如,您可以使用 2x2x2、2x2x4 或 2x4x4 等拓扑形式定义少于 64 个 TPU 芯片的小型拓扑。如果您使用的是具有超过 64 个 TPU 芯片的较大拓扑,则分配给 {A}、{B} 和 {C} 的值必须满足以下条件:
- {A}、{B} 和 {C} 必须是四的倍数。
- v4 支持的最大拓扑为
12x16x16,v5p 支持的最大拓扑为16x16x24。 - 分配的值必须保持 A ≤ B ≤ C 模式。例如
4x4x8或8x8x8。
机器类型
支持 TPU 资源的机器类型遵循以下命名惯例:其中包含 TPU 版本和每个节点切片的 TPU 芯片数量,例如 ct<version>-hightpu-<node-chip-count>t。例如,机器类型 ct5lp-hightpu-1t 支持 TPU v5e,且仅包含一个 TPU 芯片。
特权模式
如果您使用的是早于 1.28 版的 GKE 版本,则必须配置具有特殊功能的容器才能访问 TPU。在 Standard 模式集群中,您可以使用特权模式来授予此访问权限。特权模式会替换 securityContext 中的许多其他安全设置。如需了解详情,请参阅在不使用特权模式的情况下运行容器。
1.28 版及更高版本不需要特权模式或特殊功能。
GKE 中 TPU 的工作原理
Kubernetes 资源管理和优先级处理 TPU 上的虚拟机的方式与其他类型的虚拟机相同。如需请求 TPU 芯片,请使用资源名称 google.com/tpu:
resources:
requests:
google.com/tpu: 4
limits:
google.com/tpu: 4
使用 GKE 中的 TPU 时,请考虑以下 TPU 特性:
- 一个虚拟机最多可以访问 8 个 TPU 芯片。
- TPU 切片包含固定数量的 TPU 芯片,具体数量取决于您选择的 TPU 机器类型。
- 请求的
google.com/tpu数量必须等于 TPU 切片节点上的可用 TPU 芯片总数。GKE Pod 中请求 TPU 的任何容器都必须使用节点中的所有 TPU 芯片。否则,您的 Deployment 会失败,因为 GKE 无法使用部分 TPU 资源。以下面几种情况为例:- 具有
2x4拓扑的机器类型ct5lp-hightpu-4t包含两个 TPU 切片节点,每个节点包含 4 个 TPU 芯片,共包含 8 个 TPU 芯片。使用此机器类型时,您:- 无法在此节点池中的节点上部署需要 8 个 TPU 芯片的 GKE Pod。
- 可以部署两个各自需要 4 个 TPU 芯片的 Pod,每个 Pod 部署在此节点池中的两个节点之一上。
- 采用拓扑 4x4 的 TPU v5e 在 4 个节点中有 16 个 TPU 芯片。选择此配置的 GKE Autopilot 工作负载必须在每个副本(1 到 4 个副本)中请求 4 个 TPU 芯片。
- 具有
- 在 Standard 集群中,一个虚拟机上可以调度多个 Kubernetes Pod,但每个 Pod 中只有一个容器可以访问 TPU 芯片。
- 如需创建 kube-system Pod(例如 kube-dns),每个 Standard 集群必须至少有一个非 TPU 切片节点池。
- 默认情况下,TPU 切片节点具有
google.com/tpu污点,以防止非 TPU 工作负载被调度到 TPU 切片节点上。 不使用 TPU 的工作负载会在非 TPU 节点上运行,从而为使用 TPU 的代码释放 TPU 切片节点上的计算资源。请注意,污点并不能保证 TPU 资源得到充分利用。 - GKE 会收集 TPU 切片节点上运行的容器发出的日志。如需了解详情,请参阅日志记录。
- Cloud Monitoring 提供 TPU 利用率指标(例如运行时性能)。如需了解详情,请参阅可观测性和指标。
- 您可以使用 GKE Sandbox 对 TPU 工作负载进行沙盒处理。GKE Sandbox 适用于 TPU v4 及更高版本的模型。如需了解详情,请参阅 GKE Sandbox。
集合调度的运作方式
在 TPU Trillium 中,您可以使用集合调度来对 TPU 切片节点进行分组。对这些 TPU 切片节点进行分组后,您可以更轻松地调整副本数量,以满足工作负载需求。 Google Cloud 会控制软件更新,以确保集合中的切片充足,始终可用于处理流量。
TPU Trillium 支持为运行推理工作负载的单主机和多主机节点池提供集合调度。以下内容介绍了集合调度行为如何取决于您使用的 TPU 切片类型:
- 多主机 TPU 切片:GKE 会将多主机 TPU 切片分组以形成集合。每个 GKE 节点池都是此集合中的副本。如需定义集合,请创建多主机 TPU 切片并为集合分配唯一名称。如需向集合中添加更多 TPU 切片,请创建另一个具有相同集合名称和工作负载类型的多主机 TPU 切片节点池。
- 单主机 TPU 切片:GKE 会将整个单主机 TPU 切片节点池视为一个集合。如需向集合中添加更多 TPU 切片,您可以调整单主机 TPU 切片节点池的大小。
集合调度具有以下限制:
- 您只能为 TPU Trillium 调度集合。
- 您只能在创建节点池时定义集合。
- 不支持 Spot 虚拟机。
- 包含多主机 TPU 切片节点池的集合必须为集合中的所有节点池使用相同的机器类型、拓扑和版本。
您可以在以下情况下配置集合调度:
后续步骤
如需了解如何设置 GKE 中的 Cloud TPU,请参阅以下页面:
- 规划 GKE 中的 TPU,以开始设置 TPU
- 在 GKE Autopilot 中部署 TPU 工作负载
- 在 GKE Standard 中部署 TPU 工作负载
- 了解将 Cloud TPU 用于机器学习任务的最佳做法。
- 视频:利用 GKE 在 Cloud TPU 上构建大规模的机器学习服务。
- 在 TPU 上使用 KubeRay 提供大语言模型
- 了解如何使用 GKE Sandbox 对 GPU 工作负载进行沙盒处理