Pengantar
Perkiraan dan deteksi anomali pada miliaran deret waktu memerlukan komputasi yang intensif. Sebagian besar sistem yang ada menjalankan perkiraan dan deteksi anomali sebagai tugas batch (misalnya, pipeline risiko, perkiraan traffic, perencanaan permintaan, dan sebagainya). Hal ini sangat membatasi jenis analisis yang dapat Anda lakukan secara online, seperti memutuskan apakah akan mengirim pemberitahuan berdasarkan peningkatan atau penurunan mendadak di seluruh kumpulan dimensi peristiwa.
Tujuan utama Timeseries Insights API adalah:
- Menskalakan ke miliaran deret waktu yang dibuat secara dinamis dari peristiwa mentah dan propertinya, berdasarkan parameter kueri.
- Memberikan hasil prediksi dan deteksi anomali secara real time. Artinya, dalam beberapa detik, deteksi tren dan tren musiman di semua deret waktu dan tentukan apakah ada slice yang melonjak atau menurun secara tidak terduga.
Fungsi API
- Mengelola set data
- Buat indeks dan muat set data yang terdiri dari beberapa sumber data yang disimpan di Cloud Storage. Mengizinkan penambahan peristiwa baru dengan cara streaming.
- Menghapus set data yang tidak lagi diperlukan.
- Meminta status pemrosesan set data.
- Membuat kueri set data
- Mengambil deret waktu yang cocok dengan nilai properti yang diberikan. Deret waktu diperkirakan hingga jangka waktu yang ditentukan. Deret waktu juga dievaluasi untuk menemukan anomali.
- Mendeteksi kombinasi nilai properti secara otomatis untuk menemukan anomali.
- Memperbarui set data
- Serap peristiwa baru yang baru saja terjadi dan gabungkan ke dalam indeks hampir secara real time (jeda beberapa detik hingga menit).
Pemulihan dari bencana
Timeseries Insights API tidak berfungsi sebagai cadangan untuk Cloud Storage atau menampilkan update streaming mentah. Klien bertanggung jawab untuk menyimpan dan mencadangkan data secara terpisah.
Setelah pemadaman layanan regional, layanan akan melakukan pemulihan dengan upaya terbaik. Metadata (informasi tentang set data dan status operasional) serta data pengguna streaming yang diperbarui dalam waktu 24 jam sejak dimulainya pemadaman mungkin tidak dapat dipulihkan.
Selama pemulihan, kueri dan pembaruan streaming ke set data mungkin tidak tersedia.
Data input
Data numerik dan kategoris biasanya dikumpulkan dari waktu ke waktu. Misalnya, gambar berikut menunjukkan penggunaan CPU, penggunaan memori, dan status satu tugas yang berjalan di pusat data setiap menit selama jangka waktu tertentu. Penggunaan CPU dan penggunaan memori adalah nilai numerik, dan statusnya adalah nilai kategoris.
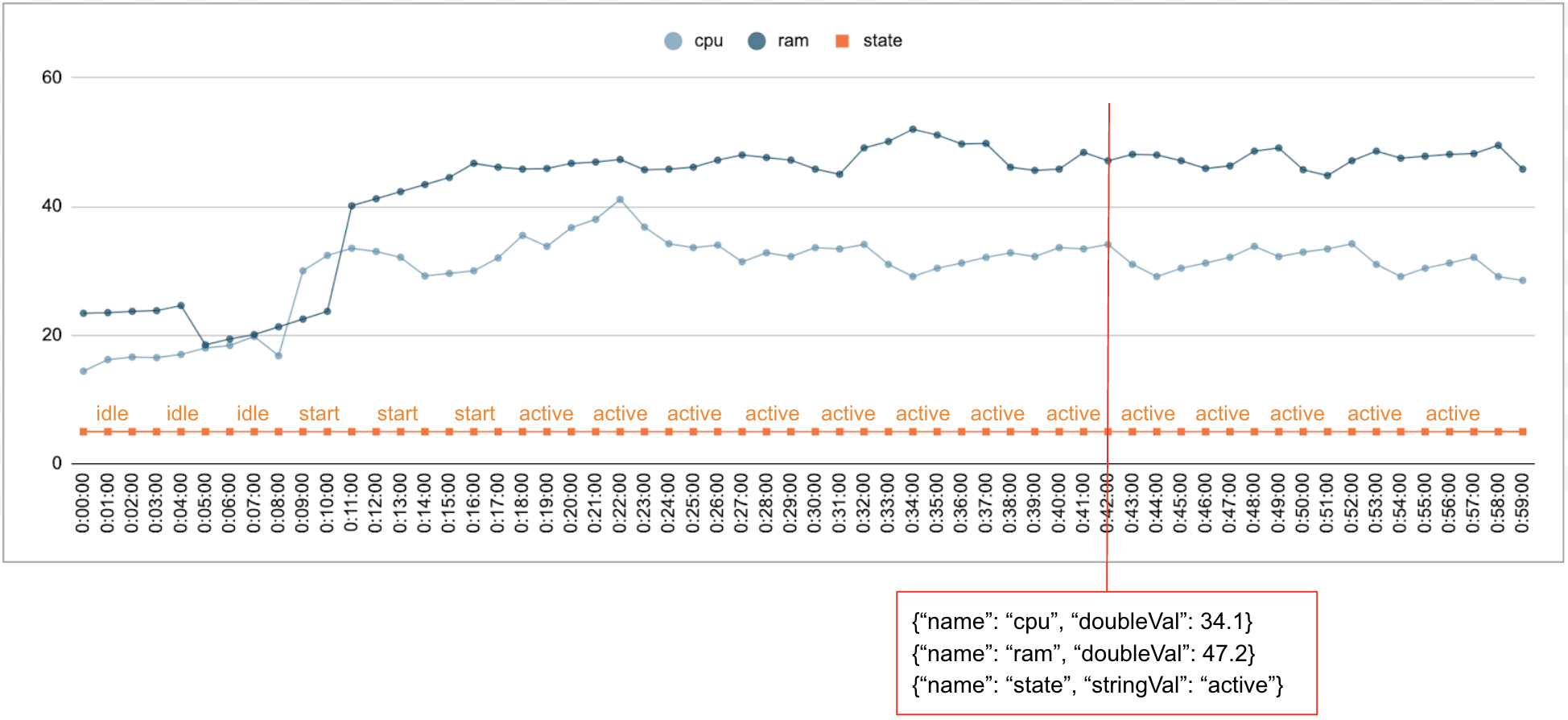
Acara
Timeseries Insights API menggunakan peristiwa sebagai entri data dasar. Setiap peristiwa memiliki stempel waktu dan kumpulan dimensi, yaitu key-value pair dengan kunci adalah nama dimensi. Representasi sederhana ini memungkinkan kita menangani data dalam skala triliunan. Misalnya, pusat data, pengguna, nama tugas, dan nomor tugas disertakan untuk sepenuhnya merepresentasikan satu peristiwa. Gambar di atas menunjukkan serangkaian peristiwa yang dicatat untuk satu tugas yang menggambarkan subset dimensi.
{"name":"user","stringVal":"user_64194"},
{"name":"job","stringVal":"job_45835"},
{"name":"data_center","stringVal":"data_center_30389"},
{"name":"task_num","longVal":19},
{"name":"cpu","doubleVal":3840787.5207877564},
{"name":"ram","doubleVal":1067.01},
{"name":"state","stringVal":"idle"}
DataSet
DataSet adalah kumpulan peristiwa. Kueri dilakukan dalam set data yang sama. Setiap project dapat memiliki beberapa set data.
Set data dibuat dari data batch dan streaming. Build data batch membaca dari beberapa URI Cloud Storage sebagai sumber data. Setelah build batch selesai, set data dapat diperbarui dengan data streaming. Dengan menggunakan build batch untuk data historis, sistem dapat menghindari masalah cold start.
Set data harus dibuat atau diindeks sebelum dapat dikueri atau diperbarui. Pengindeksan dimulai saat set data dibuat, dan biasanya memerlukan waktu beberapa menit hingga beberapa jam untuk diselesaikan, bergantung pada jumlah data. Lebih khusus lagi, sumber data dipindai sekali selama pengindeksan awal. Jika konten URI Cloud Storage berubah setelah pengindeksan awal selesai, konten tersebut tidak akan dipindai lagi. Gunakan update streaming untuk data tambahan. Update streaming diindeks secara berkelanjutan hampir secara real time.
Deret waktu dan deteksi anomali
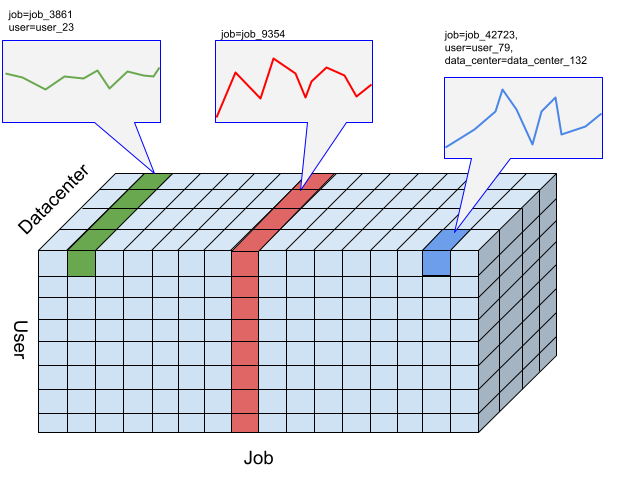
Untuk Timeseries Insights API, slice adalah kumpulan peristiwa dengan kombinasi nilai dimensi tertentu. Kita tertarik dengan pengukuran peristiwa yang masuk ke dalam bagian ini dari waktu ke waktu.
Untuk slice tertentu, peristiwa digabungkan menjadi nilai numerik per resolusi interval waktu yang ditentukan pengguna, yang merupakan deret waktu untuk mendeteksi anomali. Gambar sebelumnya mengilustrasikan berbagai pilihan slice yang dihasilkan dari berbagai kombinasi dimensi "user", "job", dan "data_center".
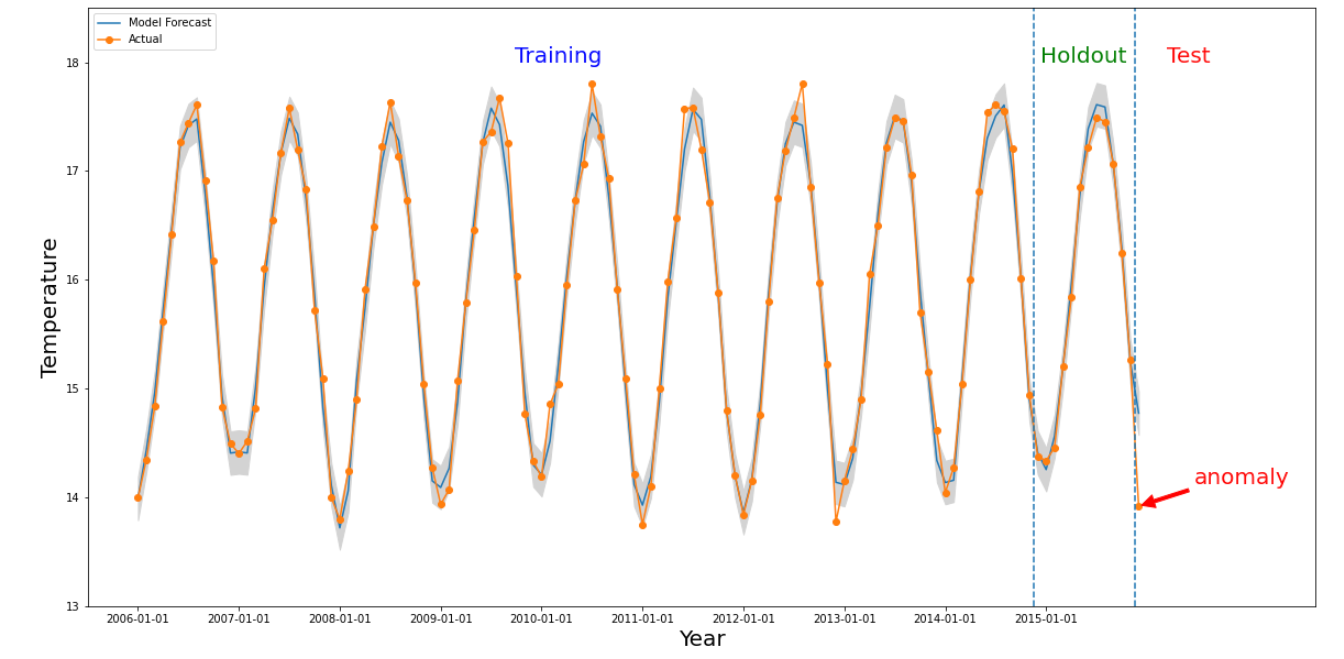
Anomali terjadi untuk slice tertentu jika nilai numerik dari interval waktu yang menarik berbeda secara signifikan dengan nilai di masa lalu. Gambar
di atas mengilustrasikan deret waktu berdasarkan suhu yang diukur di seluruh
dunia selama 10 tahun. Misalkan kita tertarik untuk mengetahui apakah bulan terakhir tahun
2015 merupakan anomali. Kueri ke sistem menentukan waktu yang diinginkan,
detectionTime, menjadi "2015/12/01" dan granularity menjadi "1 bulan". Deret waktu
yang diambil sebelum detectionTime dipartisi ke dalam periode
pelatihan sebelumnya, diikuti dengan periode holdout. Sistem menggunakan data dari
periode pelatihan untuk melatih model, dan menggunakan periode holdout untuk memverifikasi bahwa
model dapat memprediksi nilai berikutnya dengan andal. Untuk contoh ini, periode holdout
adalah 1 tahun. Gambar menunjukkan data aktual dan nilai yang diprediksi dari
model dengan batas atas dan bawah. Suhu untuk 12/2015 ditandai sebagai anomali karena nilai sebenarnya berada di luar batas yang diprediksi.