Créer du contenu audio à partir de texte en utilisant la console
Ce guide de démarrage rapide présente la console Cloud Text-to-Speech. Dans ce guide de démarrage rapide, vous allez créer du contenu audio à partir de texte et apprendre à lire, télécharger et mettre à jour ce contenu audio pour vos propres applications.
Pour en savoir plus sur les concepts fondamentaux de Text-to-Speech, consultez la page Concepts de base de Text-to-Speech.
Avant de commencer
Avant de pouvoir utiliser la console Text-to-Speech, vous devez activer l'API dans la console Google Cloud . Les étapes ci-dessous vous guident à travers les actions suivantes :
- Activez Text-to-Speech sur un projet.
- Vérifiez que la facturation est activée pour Text-to-Speech.
Configurer votre projet Google Cloud
Accédez à la page de sélection du projet
Vous pouvez sélectionner un projet existant ou en créer un. Pour en savoir plus sur la création d'un projet, consultez la documentation Google Cloud Platform.
Si vous créez un projet, vous serez invité à y associer un compte de facturation. Si vous utilisez un projet préexistant, assurez-vous que la facturation est activée.
Découvrez comment vérifier que la facturation est activée pour votre projet.
Une fois que vous avez sélectionné un projet et que vous l'avez associé à un compte de facturation, vous pouvez activer l'API Text-to-Speech. Accédez à la barre Rechercher des produits et des ressources en haut de la page et saisissez "text-to-speech".
Sélectionnez l'API Cloud Text-to-Speech dans la liste des résultats.
Pour essayer Text-to-Speech sans l'associer à votre projet, sélectionnez l'option ESSAYER CETTE API. Pour activer l'API Text-to-Speech afin de l'utiliser avec votre projet, cliquez sur ACTIVER.
Créer du contenu audio à partir de texte
Utilisez la console Google Cloud pour créer du contenu audio à partir de texte :
Saisir du texte ou du SSML
Ouvrez la page Synthèse Text-to-Speech.
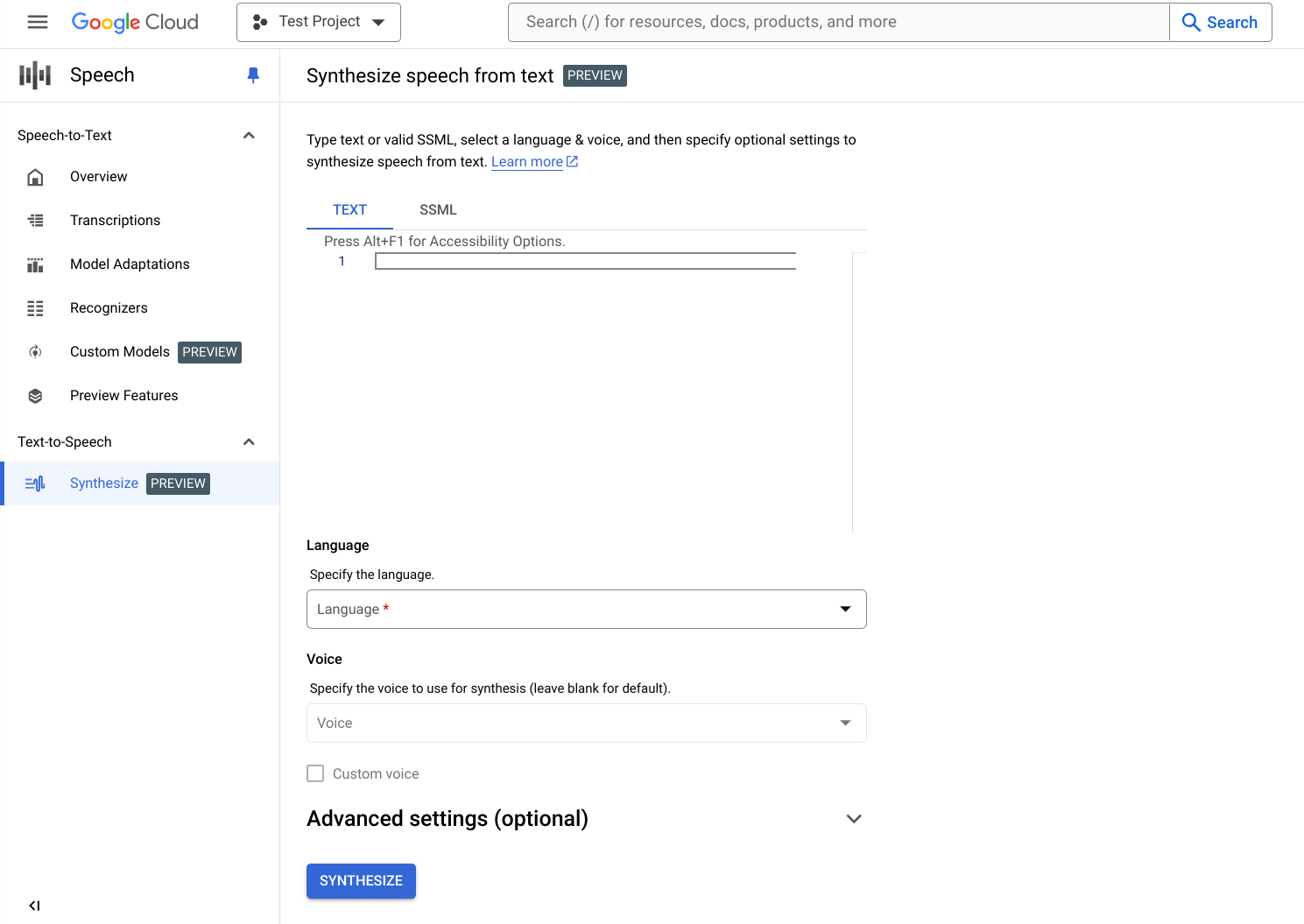
Saisissez votre texte ou SSML. Vous pouvez synthétiser du texte brut ou utiliser le langage de balisage de synthèse vocale (SSML) pour personnaliser davantage votre réponse audio.
Sélectionnez la langue de votre texte ou SSML. Il s'agit de la langue qui sera utilisée pour la synthèse.
Sélectionnez la voix que vous souhaitez utiliser pour la synthèse. Notez que les fonctionnalités, les caractéristiques et les coûts des voix varient.
Paramètres avancés (facultatif)
Vous pouvez si besoin développer la section Paramètres avancés pour configurer d'autres propriétés du contenu audio que vous allez créer.
Spécifiez des caractéristiques supplémentaires de votre contenu audio synthétisé, telles que la vitesse d'élocution et la hauteur.
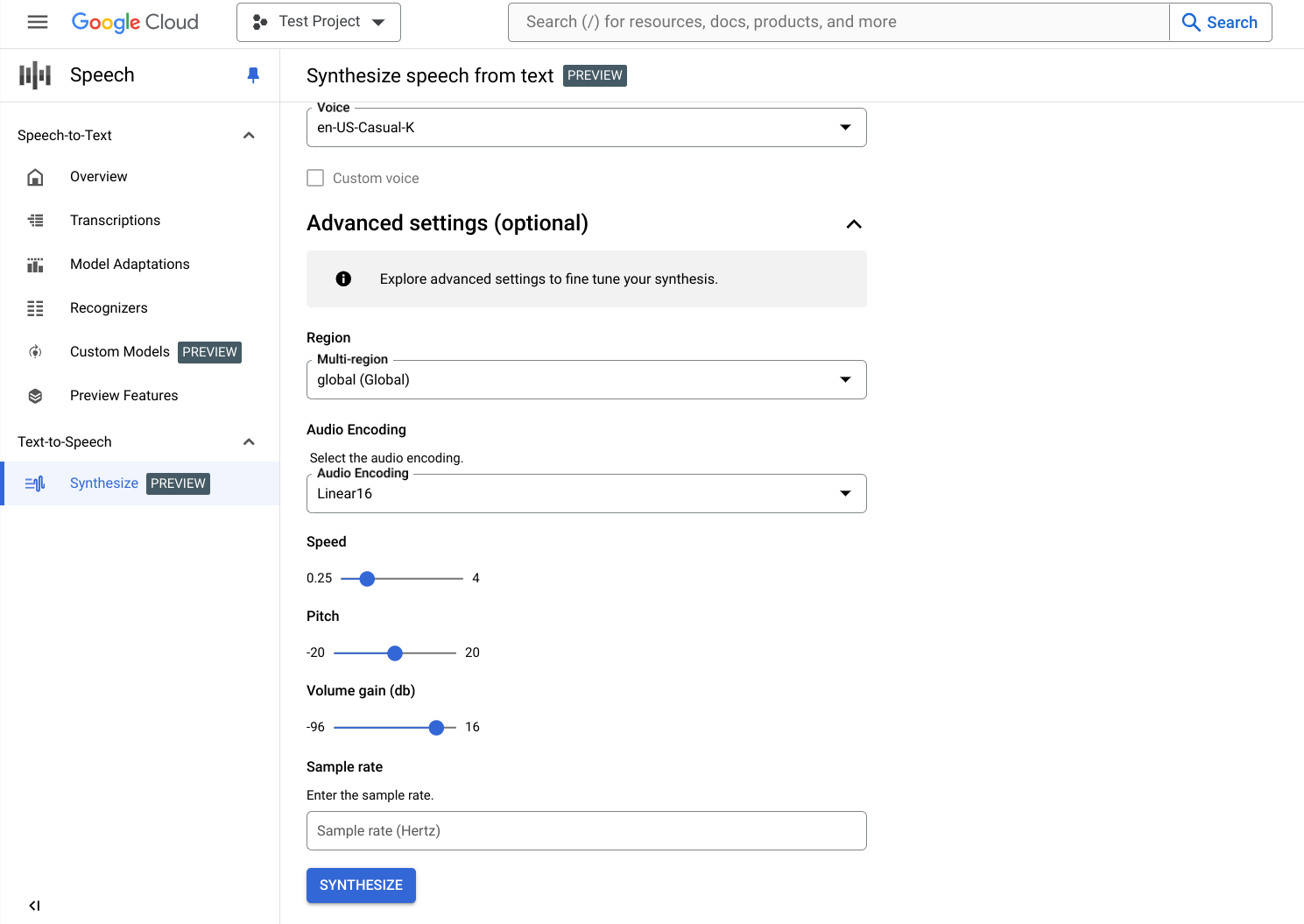
En bas, cliquez sur Synthèse pour créer votre contenu audio synthétisé.
Vérifier le contenu audio
En fonction de votre entrée, la création du contenu audio synthétisé peut prendre de quelques secondes à quelques minutes. Une fois votre contenu audio créé, vous pouvez le vérifier.
Cliquez sur les commandes du lecteur pour lire le contenu audio.
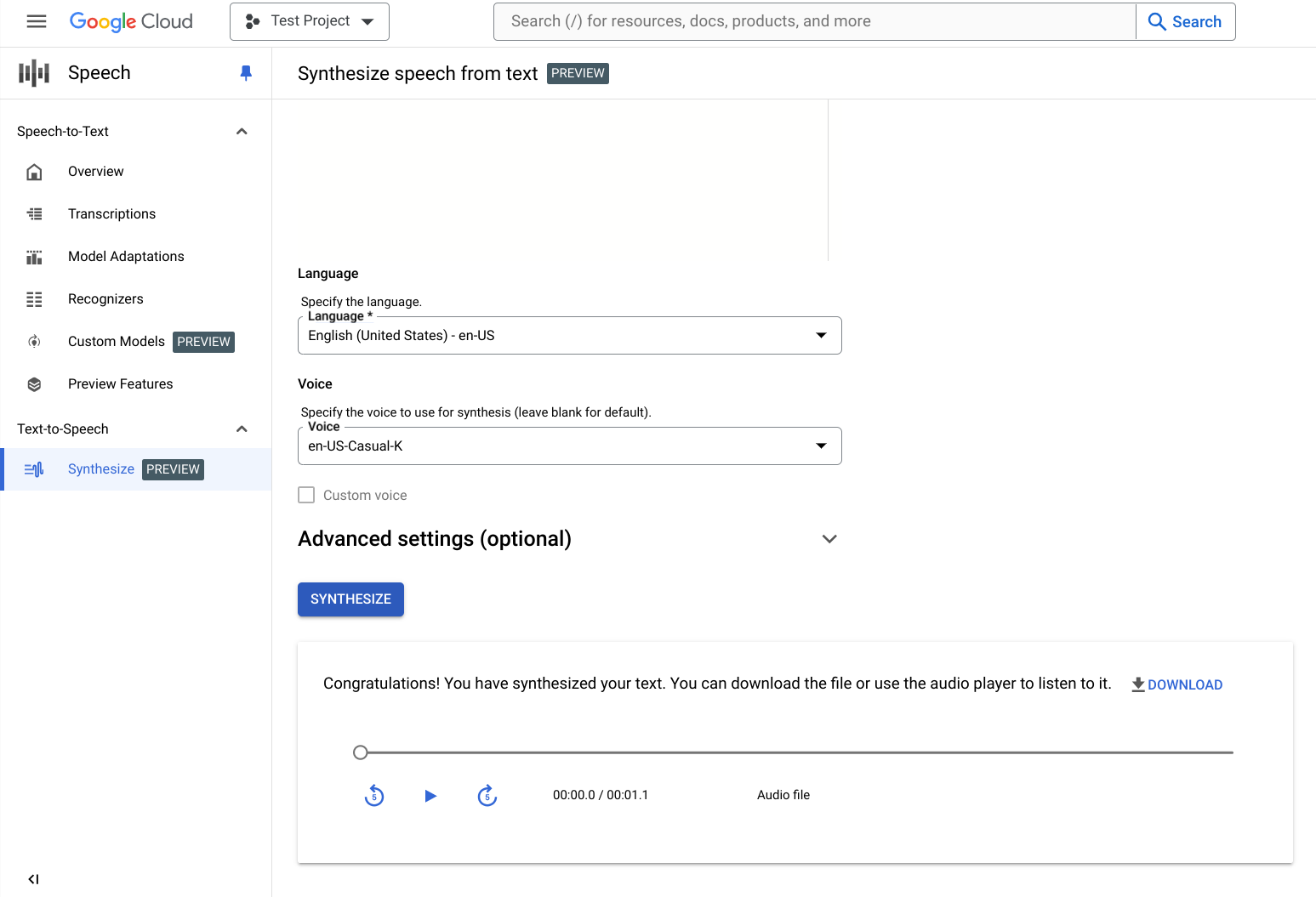
Cliquez sur Télécharger pour télécharger le fichier audio localement.
Effectuer un nettoyage
Pour éviter des frais Google Cloud inutiles, supprimez votre projet à l'aide de Google Cloud console si vous n'en avez plus besoin.
Étapes suivantes
- Pour en savoir plus sur Cloud Text-to-Speech, consultez la page Concepts de base.
- Passez en revue la liste des voix disponibles que vous pouvez utiliser pour la voix synthétique.