범용 음성 모델(USM)은 Google의 차세대 Speech-to-Text 모델입니다. 이러한 모델은 Google의 리서치팀에서 수년간 작업한 결과물입니다. 이제 USM의 첫 번째 반복을 사용할 수 있게 되었습니다. 그러나 현재 모델은 계속해서 새로운 기능을 활용할 흥미로운 새로운 모델과 연구의 시작에 불과합니다. 제공되는 서비스에 따라 USM 관련 모델 업데이트 및 추가 모델 식별자가 표시될 수 있습니다.
범용 음성 모델은 현재 음성 모델과 다른 아키텍처로 학습됩니다. 단일 모델에는 서로 다른 여러 언어의 데이터가 포함되어 있습니다. 학습 데이터와 모델의 통합에도 불구하고 모델이 음성 인식을 시도해야 하는 언어를 지정해야 합니다. USM에서는 다른 모델의 Google Speech 기능 중 일부를 지원하지 않습니다. 전체 목록은 아래를 참조하세요. 이 모델은 다른 Google Speech 모델과 다르게 출력을 생성할 수도 있습니다.
모델 식별자
USM은 Cloud Speech-to-Text API v2에서 사용할 수 있습니다. 다른 모델과 마찬가지로 활용할 수 있습니다.
USM 모델의 모델 식별자는 usm입니다.
인식기를 생성하면서 이 모델을 지정하여 범용 음성 모델(USM)을 활용할 수 있습니다.
가격 책정
비공개 미리보기 중에는 USM을 무료로 사용할 수 있습니다. 모델 가격 책정은 추후 공지됩니다.
사용 가능한 API 메서드
범용 음성 모델은 훨씬 큰 배치에서 음성을 처리합니다. 즉, 다른 Google Speech-to-Text 모델과 마찬가지로 실제 '실시간' 사용에 적합하지 않을 수 있습니다. USM은 다음 API 메서드를 통해 사용할 수 있습니다.
v2Speech.Recognize(1분 미만의 짧은 오디오에 적합)v2Speech.BatchRecognize(1분 ~ 8시간의 긴 오디오에 적합)
범용 음성 모델은 다음 API 메서드에서는 사용할 수 없습니다.
v2Speech.StreamingRecognizev1Speech.StreamingRecognizev1Speech.Recognizev1Speech.LongRunningRecognizev1p1beta1Speech.StreamingRecognizev1p1beta1Speech.Recognizev1p1beta1Speech.LongRunningRecognize
언어
다음 언어 코드를 전달할 수 있습니다.
af-ZAam-ETar-EGaz-AZbe-BYbg-BGbn-BDca-ESzh-Hans-CNcs-CZda-DKde-DEel-GRen-AUen-GBen-INen-USes-USet-EEeu-ESfa-IRfi-FIfil-PHfr-CAfr-FRgl-ESgu-INiw-ILhi-INhu-HUhy-AMid-IDis-ISit-ITja-JPjv-IDka-GEkk-KZkm-KHkn-INko-KRlo-LAlt-LTlv-LVmk-MKml-INmn-MNmr-INms-MYmy-MMno-NOne-NPnl-NLpa-Guru-INpl-PLpt-BRro-ROru-RUsi-LKsk-SKsl-SIsq-ALsr-RSsu-IDsv-SEswta-INte-INth-THtr-TRuk-UAur-PKuz-UZvi-VNyue-Hant-HKzu-ZAas-INast-ESbs-BAceb-PHckb-IQcy-GBha-NGhr-HRkam-KEkea-CVky-KGlb-LUln-CDluo-KEmi-NZmt-MTnso-ZAny-MWoc-FRor-INps-AFsd-INsn-ZWso-SOtg-TJwo-SNyo-NG
기능 지원 및 제한 사항
범용 음성 모델은 현재 많은 STT API 기능을 지원하지 않습니다. 아래에서 구체적인 제한사항을 참조하세요.
- 신뢰도 점수 - API가 값을 반환하지만 진정한 신뢰도 점수는 아닙니다.
- 음성 적응 - 지원되는 적응 기능이 없습니다.
- 분할 - 자동 분할은 지원되지 않습니다. 채널 분리는 지원되지 않습니다.
- 구두점 - 음성 구두점은 지원되지 않습니다. 자동 구두점은 지원되지 않습니다.
- 강제 정규화 - 지원되지 않습니다.
- 단어 수준의 신뢰도 - 지원되지 않습니다.
- 언어 감지 - 지원되지 않습니다.
- 단어 시간 - 지원되지 않습니다.
구두점 참고사항
비공개 미리보기에서 사용 가능한 USM은 어떤 종류의 구두점도 생성하지 않습니다. 평가 과정에서 이를 고려해야 합니다. Google에서는 USM이 적합한 여러 사용 사례에 자동 구두점이 중요하다는 것을 알고 있기 때문에 가능한 한 빨리 자동 구두점을 추가하기 위해 노력하고 있습니다.
Cloud 콘솔 UI 시작하기
- Google Cloud 계정에 가입하고 프로젝트를 만들었는지 확인합니다. USM에 대해 허용된 프로젝트 및 계정을 사용해야 합니다.
- Google Cloud 콘솔에서 음성으로 이동합니다.
- API가 아직 사용 설정되지 않았으면 사용 설정합니다.
범용 음성 모델을 사용하는 STT 인식기를 만듭니다.
인식기 탭으로 이동하여 '만들기'를 클릭합니다.
인식기 만들기 페이지에서 USM에 필요한 필드를 입력합니다.
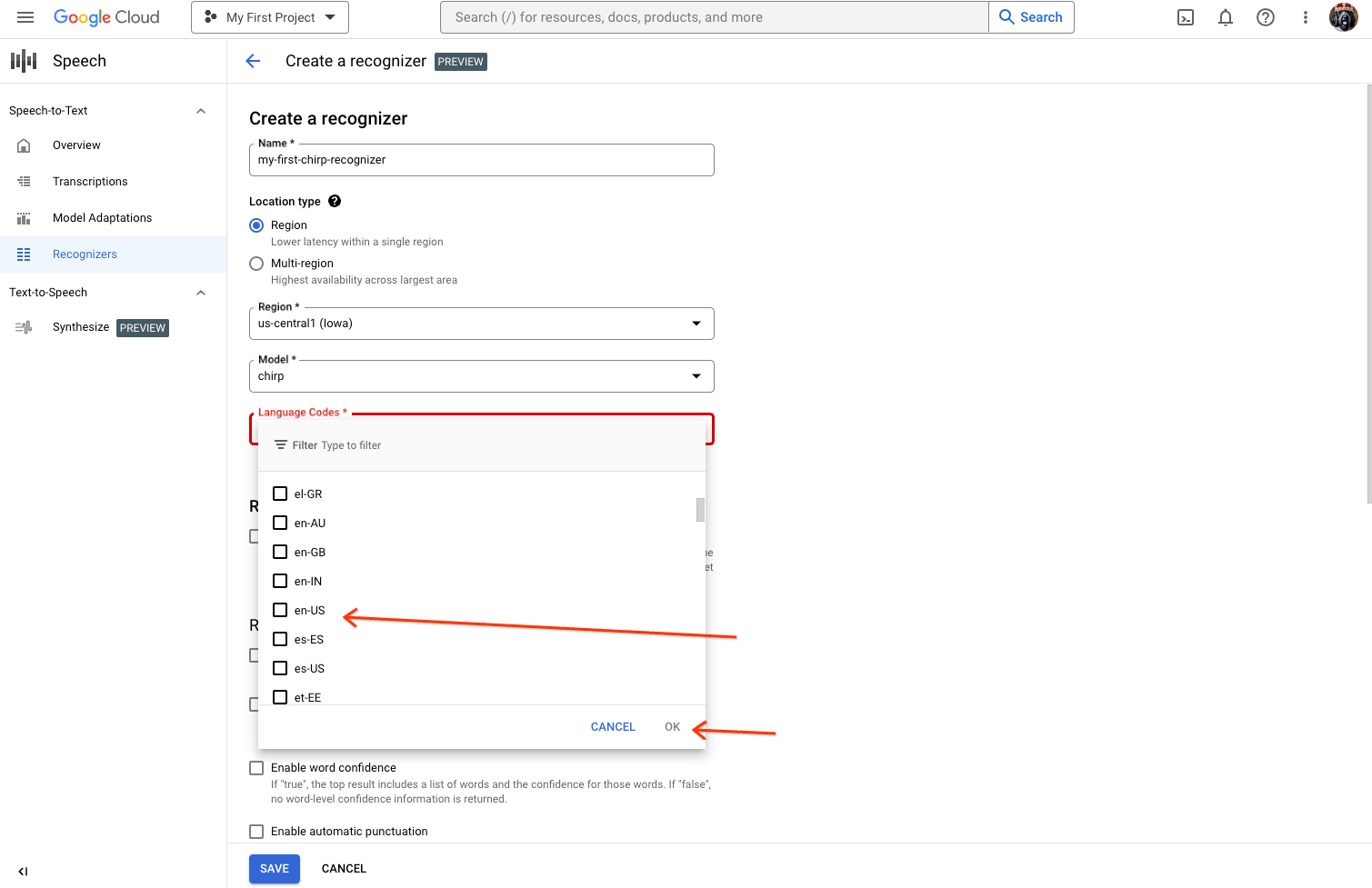
- 인식기의 이름을 지정합니다.
- USM은 현재 us-central1 리전에서만 사용할 수 있습니다.
region을 선택한 다음us-central1선택합니다. - 모델로 'usm'을 선택합니다. 모델 목록에 'usm'이 표시되지 않으면 프로젝트가 허용되지 않은 것입니다.
- 사용할 언어를 선택합니다. 테스트하려는 언어당 하나의 인식기가 필요합니다.
- 다른 기능은 선택하지 마세요.
us-central1리전에 STT UI 작업공간이 있는지 확인합니다. 새 작업공간을 만들어야 할 수도 있습니다.- console.cloud.google.com/speech/scriptions에서 텍스트 변환 페이지를 방문합니다.
- 텍스트 변환 페이지에서 새 텍스트 변환을 클릭합니다.
Workspace드롭다운을 열고 '새 작업공간'을 클릭하여 텍스트 변환용 작업공간을 만듭니다.Create a new workspace측면 탐색 메뉴에서Browse를 클릭합니다.- 새 버킷 아이콘을 클릭하여 작업공간을 나타내는 Cloud Storage 버킷을 만듭니다.
- 버킷 이름을 입력하고 '계속'을 클릭합니다.
- [중요] 드롭다운에서
region및us-central1을 선택하여 범용 음성 모델이 오디오를 처리할 수 있는지 확인합니다. create를 클릭하여 Cloud Storage 버킷을 만듭니다.- 버킷을 만든 후
select를 클릭하여 사용할 버킷을 선택합니다. create를 클릭하여 음성 텍스트 변환 UI의 작업공간 만들기를 완료합니다.
실제 오디오에서 텍스트 변환을 수행합니다.
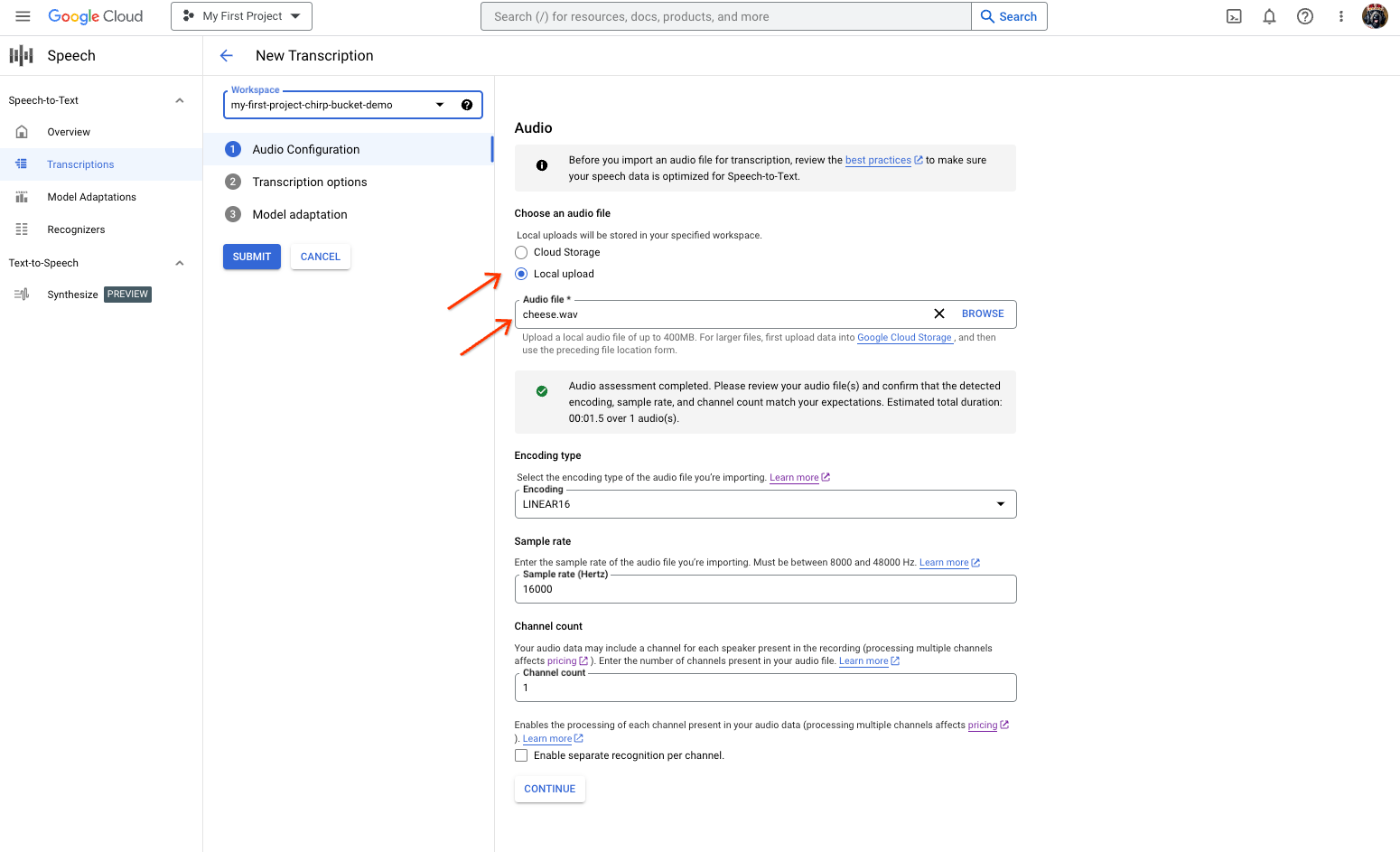
- '새 텍스트 변환' 페이지에서 업로드('로컬 업로드') 또는 기존 Cloud Storage 파일('Cloud Storage') 지을 통해 오디오 파일을 선택합니다. UI는 오디오 파일 매개변수를 자동으로 평가하려고 시도합니다.
- '계속'을 클릭하여 '텍스트 변환 옵션'으로 이동합니다.

- 이전에 만든 인식기에서 범용 음성 모델을 사용하여 인식하는 데 사용할 '음성 언어'를 선택합니다.
- 모델 드롭다운에서 '범용 음성 모델'을 선택합니다.
- '인식기' 드롭다운에서 새로 만든 인식기를 선택합니다.
- 범용 음성 모델을 사용하여 첫 번째 인식 요청을 실행하려면
submit을 클릭합니다.
범용 음성 모델 텍스트 변환 결과를 확인합니다.
- '텍스트 변환' 페이지에서 텍스트 변환 이름을 클릭하여 결과를 확인합니다.
- '텍스트 변환 세부정보' 페이지에서 텍스트 변환 결과를 확인하고 브라우저에서 선택적으로 오디오를 재생합니다.
Python 노트북 시작하기
이 가이드는 Python 노트북을 사용하여 STT API v2에서 USM을 시작하는 데 도움이 됩니다.
- Google Cloud 계정에 가입하고 프로젝트를 만들었는지 확인합니다. USM에 대해 허용된 프로젝트 및 계정을 사용해야 합니다.
- 작동 중인 Python 노트북 환경이 있는지 확인합니다.
- 여기에서 노트북을 확인하고 직접 사본을 만듭니다.
- 원하는 실행 환경에서 노트북을 실행합니다. 인증 및 인식기를 설정한 후 텍스트 변환 요청을 실행하는 데 도움이 되는 노트북의 안내를 따릅니다.